📖标题:Entropy-Guided Token Dropout: Training Autoregressive Language Models with Limited Domain Data
🌐来源:arXiv, 2512.23422v1
🌟摘要
随着对高质量、特定领域的数据的日益稀缺,多时期训练已成为适应大型语言模型 (LLM) 的实用策略。然而,自回归模型在重复数据暴露下往往会遭受性能下降,其中过拟合导致模型能力显着下降。通过实证分析,我们将这种退化追溯到学习动态的不平衡:可预测的、低熵的标记被快速学习并主导优化,而模型在高熵标记上进行泛化的能力随着持续训练而恶化。为了解决这个问题,我们引入了 EntrDrop,这是一种熵引导的令牌 dropout 方法,它充当结构化数据正则化。EntrDrop 在训练期间选择性地屏蔽低熵标记,并使用课程计划来调整正则化强度与训练进度对齐。在从 0.6B 到 8B 参数的模型尺度上的实验表明,EntroDrop 始终优于标准正则化基线,并在扩展的多 epoch 训练期间保持稳健的性能。这些发现强调了在有限数据上训练时将正则化与令牌级学习动态对齐的重要性。我们的方法为在数据约束域中更有效地适应 LLM 提供了一种有前途的途径。
🛎️文章简介
🔸研究问题:如何在有限领域数据下有效训练自回归语言模型,从而避免多轮训练导致的性能退化?
🔸主要贡献:论文提出了基于熵引导的token dropout方法(EntroDrop),旨在改善在稀缺数据条件下的训练效果。
📝重点思路
🔸探讨了在多轮训练中,低熵和高熵token对模型表现的影响。
🔸采用熵引导的token目标策略,选择性地压制低熵token,以减少高可信区的冗余监督。
🔸引入基于课程的调度策略,动态调整dropout比例,使模型在早期阶段高效学习,在后期阶段增强正则化以对抗过拟合。
🔸通过理论分析证明,熵引导的token dropout能够有效降低训练梯度的方差,从而提高模型稳定性和泛化能力。
🔎分析总结
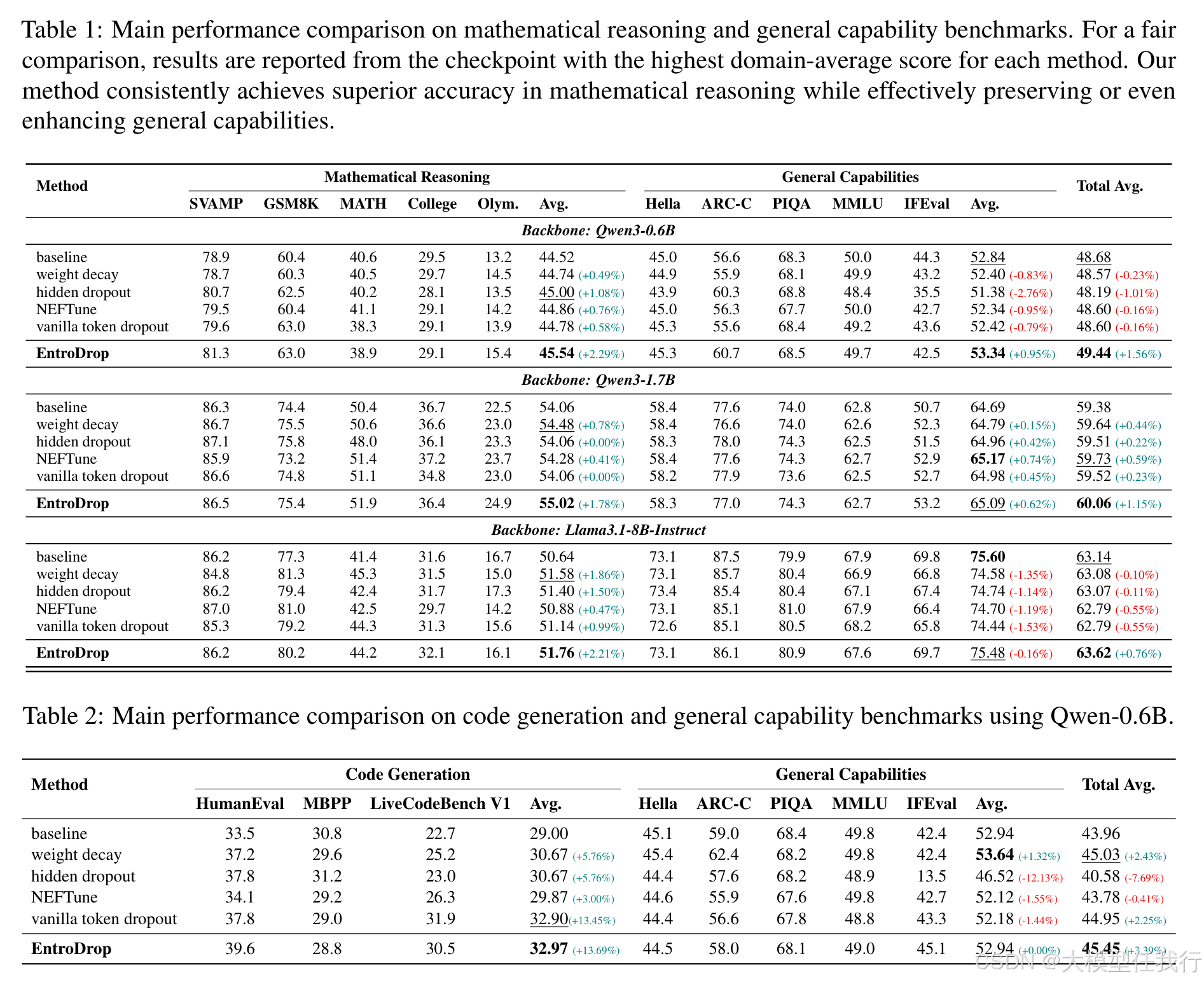
🔸实验结果表明,增加领域特定数据的重复训练确实能提高模型性能,特别是在有限的数据情况下。
🔸EntroDrop相比于传统的正则化方法(如权重衰减和隐藏dropout),在数学推理和代码生成等基准上,稳定延长了有效的训练窗口。
🔸模型在高熵token的表现随着训练的进行而逐渐恶化,强调了token在训练过程中信息密度对学习动态的重要性。
🔸通过选择性掩蔽低熵token,EntroDrop在保持模型泛化能力的同时,提升了领域适应性。
💡个人观点
论文通过熵引导提供了一种选择性正则化的方法,能在模型训练中有效利用稀缺数据,减缓过拟合,同时保持模型的泛化能力。
🧩附录