精确的空间理解是机器人与物理世界交互的基础。然而,现有方法常面临困境:基于点云的方法因稀疏采样损失细粒度语义;基于图像的方法将语义与几何特征纠缠,在真实世界常见的深度噪声干扰下,其性能会显著下降。此外,这些方法大多关注高层几何结构,忽略了对精确操控至关重要的低层空间线索。为解决这些问题,我们提出 SpatialActor,一个为机器人操控设计的解耦表示框架。SpatialActor 的核心思想是将语义和几何信息彻底分离,并进一步将几何信息分解为高层结构与低层线索。其主要包含两个创新模块:
- 语义引导的几何模块 (Semantic-guided Geometric Module, SGM): 该模块通过门控机制,自适应地融合来自深度先验专家(稳健但粗糙)和原始深度图(精细但带噪)的两种互补几何信息,生成一个既鲁棒又精确的高层几何表征。
- 空间变换器 (Spatial Transformer, SPT): 该模块利用相机内外参显式地构建低层空间编码,为每个视觉特征赋予确切的 3D 空间坐标,并促进空间特征的有效交互。
我们在超过 50 个模拟与真实世界任务中对 SpatialActor 进行了评估。结果表明,它在 RLBench 基准上取得了 87.4% 的最优成功率,并在不同程度的噪声下性能提升 13.9% 至 19.4%,展现出卓越的鲁棒性。同时,它在少样本泛化和真实机器人部署中也表现出色。

• 论文标题: SpatialActor: Exploring Disentangled Spatial Representationsfor Robust Robotic Manipulation
1. 引言:机器人空间理解的挑战
当前的机器人操控策略在利用 3D 空间信息方面存在明显的两难。
- 基于点云的方法 (如 PointNet++) 虽然能显式表达 3D 几何,但其稀疏采样特性常导致关键的语义信息丢失,并且高昂的 3D 标注成本也限制了其在大规模预训练中的应用。
- 基于图像的方法 (如 RVT-2) 通过将多视角 RGB 图像与深度图(RGB-D)输入到共享的 2D 骨干网络中,试图统一建模语义与几何。这类方法受益于强大的 2D 预训练模型,能获得密集的语义信息。然而,其核心缺陷在于"语义-几何纠缠"------当深度图因传感器、光照或物体表面反光而产生噪声时,被污染的几何特征会严重干扰语义理解,导致整个系统性能急剧下降。
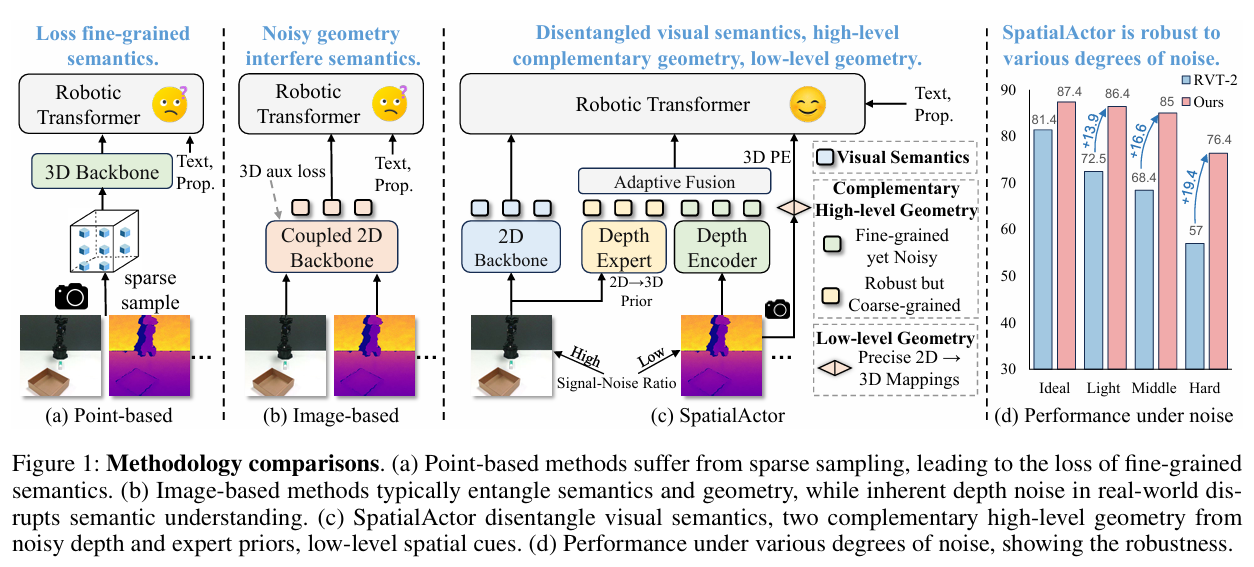
(a) 基于点云的方法:因稀疏采样丢失细粒度语义。
(b) 基于图像的方法:语义与几何纠缠,噪声深度会污染语义判断。
© SpatialActor :将视觉语义、高层互补几何、低层空间线索彻底解耦。
(d) 噪声下的性能对比:SpatialActor 在不同强度的噪声下始终保持高稳定性。
因此,一个理想的机器人操控模型需要具备三大能力:精细的空间理解 、对传感器噪声的鲁棒性 以及 可靠的低层空间交互。为实现这一目标,我们提出了 SpatialActor。
2. 方法:解构与重组空间表征
SpatialActor 的整体框架如下图所示,其核心在于对输入信息进行彻底的解耦与分层处理。
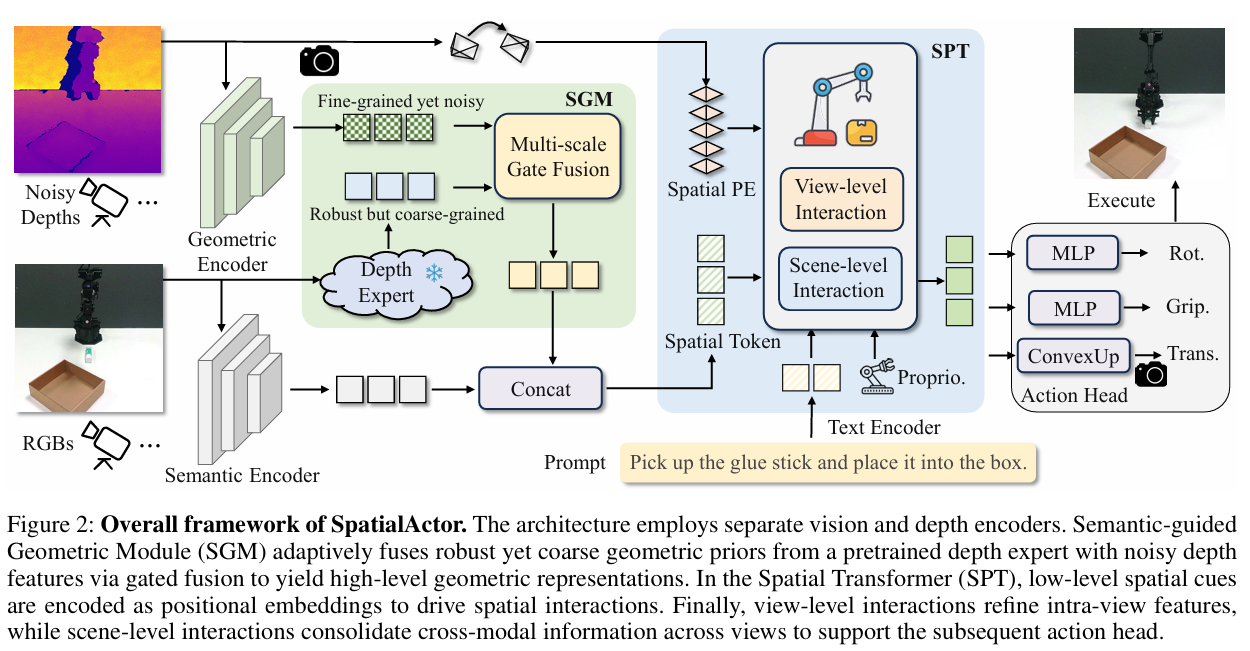
模型分别对 RGB 与深度图进行独立编码。SGM 通过门控机制将深度专家提供的"稳健粗几何"与原始深度的"精细噪几何"自适应融合,得到高层几何表征。SPT 则利用相机参数与深度构建低层空间编码,通过视角级与场景级交互,使空间特征充分融合。最终,模型基于融合后的空间表征预测三维动作。
2.1 语义-几何解耦
我们首先将语义和几何信息的处理路径完全分开。
- 语义路径 : RGB 图像 (IvI^vIv) 和语言指令 (LLL) 通过一个强大的视觉语言模型 (如 CLIP) 提取高质量的语义特征 (FsemvF_{sem}^vFsemv),该过程完全不受深度噪声的影响,确保了语义理解的稳定性。
- 几何路径 : 原始深度图 (DvD^vDv) 被送入一个独立的深度编码器,以提取几何特征。
2.2 语义引导的几何模块 (SGM)
我们进一步将几何信息分解为两个互补的层级,并通过 SGM 模块进行智能融合。
- 稳健但粗糙的几何先验 : 利用一个冻结的大规模预训练深度估计专家模型(如 Depth Anything v2),从高质量的 RGB 图像中直接推断出深度,生成一个稳健但细节可能不足的几何先验 F^geov\hat{F}{geo}^vF^geov。
F^geov=Eexpert(Iv) \hat{F}{geo}^v = E_{\text{expert}}(I^v) F^geov=Eexpert(Iv) - 精细但带噪的几何细节 : 通过一个标准深度编码器(如 ResNet)处理原始深度图,得到保留了像素级细节但可能包含噪声的几何特征 FgeovF_{geo}^vFgeov。
Fgeov=Eraw(Dv) F_{geo}^v = E_{\text{raw}}(D^v) Fgeov=Eraw(Dv) - 门控融合 (Gated Fusion) : 使用一个门控机制自适应地决定在每个空间位置上是更相信"专家"还是"原始数据",从而生成一个既稳健又精细的高层几何表征 Ffuse−geovF_{fuse-geo}^vFfuse−geov。
Gv=σ(MLP(Concat(F^geov,Fgeov))) G^v = \sigma(\text{MLP}(\text{Concat}(\hat{F}{geo}^v, F{geo}^v))) Gv=σ(MLP(Concat(F^geov,Fgeov)))
Ffuse−geov=Gv⊙Fgeov+(1−Gv)⊙F^geov F_{fuse-geo}^v = G^v \odot F_{geo}^v + (1 - G^v) \odot \hat{F}_{geo}^v Ffuse−geov=Gv⊙Fgeov+(1−Gv)⊙F^geov
其中 σ\sigmaσ 是 Sigmoid 激活函数,⊙\odot⊙ 是逐元素乘法。
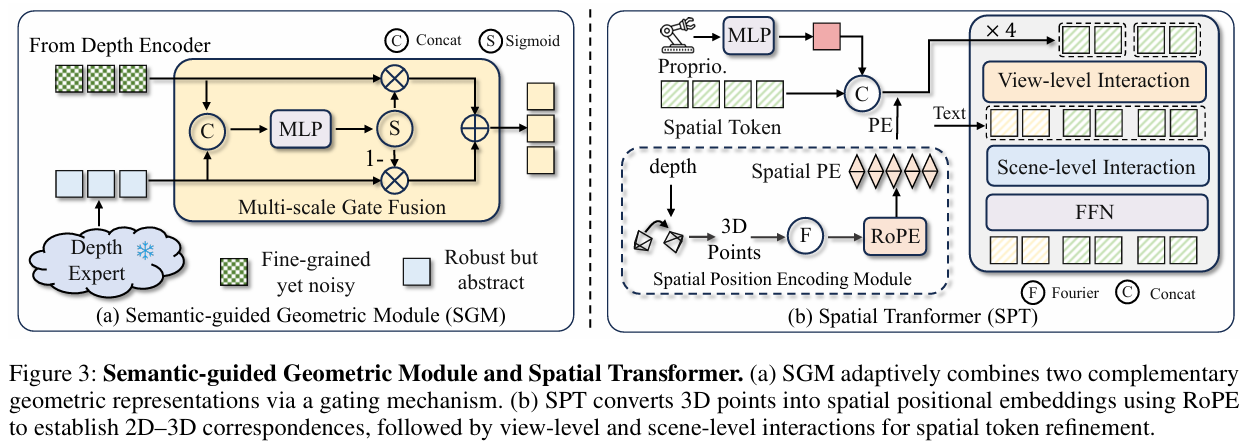
(a) SGM 通过门控机制自适应融合两种互补的几何表征。
(b) SPT 将像素投影到 3D 空间,通过旋转位置编码 (RoPE) 构建空间位置,并进行多层级交互。
2.3 空间变换器 (SPT)
为实现毫米级精度的操作,机器人必须知道每个视觉特征在 3D 物理世界中的确切位置。SPT 模块通过显式建模低层空间线索来解决此问题。
- 构建 3D 空间坐标 : 对于每个像素,利用其深度值 ddd 和相机内外参数(Kv,EvK^v, E^vKv,Ev),通过透视投影公式将其转换为机器人基座坐标系下的真实 3D 点 (x,y,z)(x, y, z)(x,y,z)。
x,y,z,1T=Ev(d⋅(Kv)−1x′,y′,1T1) x, y, z, 1^T = E^v \begin{pmatrix} d \cdot (K^v)^{-1} x', y', 1^T \\ 1 \end{pmatrix} x,y,z,1T=Ev(d⋅(Kv)−1x′,y′,1T1) - 赋予空间位置编码 : 利用 旋转位置编码 (Rotary Positional Encoding, RoPE) 将计算出的 3D 坐标 (x,y,z)(x, y, z)(x,y,z) 编码,并应用到每个视觉特征 token 上。这使得每个 token 都拥有了独一无二的 3D 空间身份。
- 多层级空间交互 :
- 视角级交互 (View-level Interaction): 在每个视角内部,通过自注意力机制整合上下文信息。
- 场景级交互 (Scene-level Interaction): 跨越所有视角,将各视角的特征、语言指令和机器人本体状态进行融合,实现全局空间信息的充分交互。
最终,经过 SPT 处理的特征被送入动作头,预测末端执行器的 3D 平移、旋转和抓取状态。
3. 实验结果
3.1 与 SOTA 方法的比较
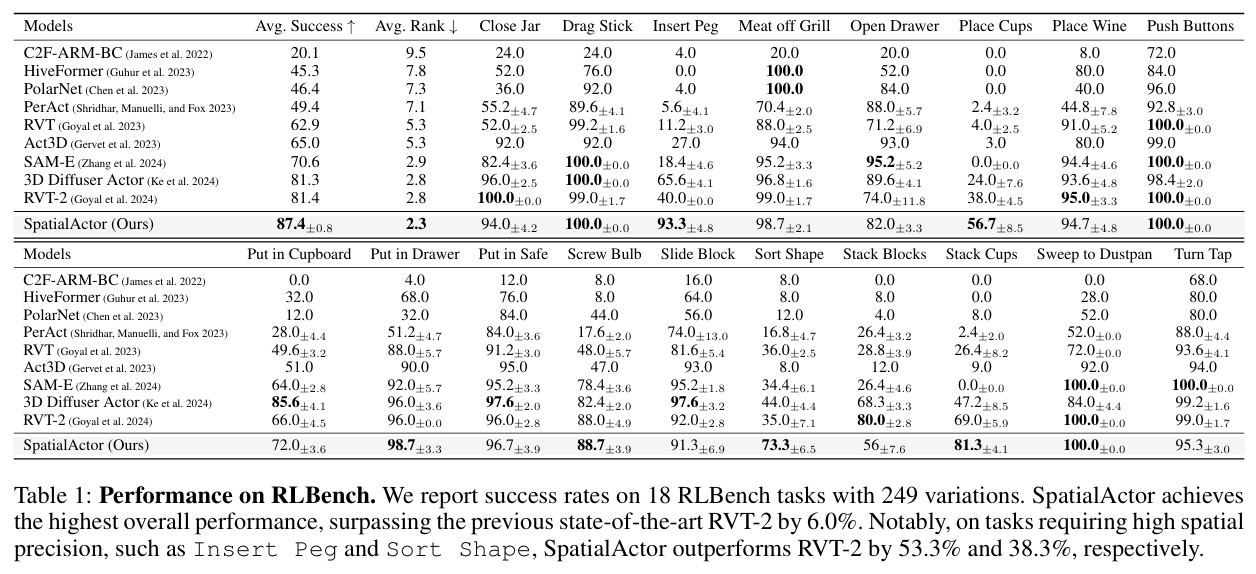
在 RLBench 基准(18个任务,249种场景变化)上,SpatialActor 取得了 87.4% 的平均成功率,显著优于先前的 SOTA 方法 RVT-2 (81.4%)。尤其在需要高精度空间推理的任务上,优势更为明显,例如在 Insert Peg(插销)任务上成功率高出 53.3% ,在 Sort Shape(形状分类)任务上高出 38.3%。
3.2 噪声鲁棒性测试
为模拟真实世界中的传感器噪声,我们在重建的点云中注入不同程度的高斯噪声。实验表明,SpatialActor 的性能始终保持稳健,而基线模型则出现显著下降。

这充分验证了 SGM 模块在对抗噪声、稳定几何表征方面的有效性。
3.3 少样本泛化能力
在少样本(Few-shot)设定下,对于每个新任务仅使用 10 个示范样本进行微调,SpatialActor 依然能达到 79.2% 的成功率,远超 RVT-2 的 46.9%,显示出极强的快速适应和泛化能力。
3.4 真实机器人实验
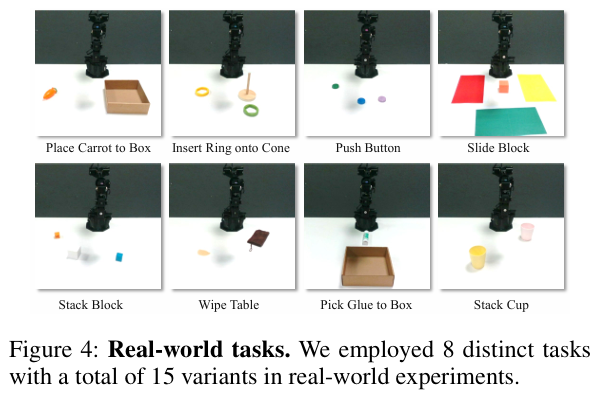
在基于 WidowX 机械臂和 RealSense D435i 相机的真实世界测试中,我们评估了 8 类共 15 种场景。SpatialActor 的平均成功率达到 63%,显著高于 RVT-2 的 43%。即使在面临光照变化、背景替换等干扰时,模型依旧能保持稳健的动作输出。
4. 结论
SpatialActor 的核心贡献在于提出了一种全新的机器人空间理解范式:通过解耦与分层,重构空间表征。它将纠缠不清的语义与几何信息分离,让语义理解保持稳定;将几何信息细化为"稳健的粗结构"与"精细的细节",并通过 SGM 模块实现抗噪融合;最后通过 SPT 模块赋予每个特征显式的 3D 空间定位,实现精准操控。
这项工作证明,一个能够在噪声中保持稳定、在少样本中快速学习、在现实中精确对位的机器人系统是完全可以实现的。我们相信,SpatialActor 为构建更可靠、更通用的具身智能系统迈出了坚实的一步。