温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片 :)
1. 系统概述
随着医疗大数据的快速发展,利用机器学习技术辅助疾病诊断已成为智慧医疗的重要方向。本项目开发了一套基于数据挖掘的中风智能预测系统。该系统旨在通过分析患者的性别、年龄、生活习惯(如吸烟)、生理指标(如血糖、BMI)等数据,挖掘潜在的中风风险因素,并构建高精度的预测模型。
系统不仅包含完整的数据挖掘与建模流程(Jupyter Notebook 实现),还配套了一个基于 Flask 的 Web 应用程序。通过 Web 端,用户可以直观地查看数据分析图表,并输入个人健康数据获取实时的中风风险预测结果。
系统演示视频:https://www.bilibili.com/video/BV1Uem2BaEjX/
2. 系统架构概览
系统采用经典的 B/S (Browser/Server) 架构,实现了从数据后端到 Web 前端的完整闭环。
技术栈选型
- 开发语言: Python 3.10+
- Web 框架: Flask (轻量级,适合快速开发)
- 数据挖掘: Pandas, NumPy, Scikit-learn (随机森林算法)
- 前端技术: HTML5, Tailwind CSS (现代 UI 设计), ECharts (交互式数据可视化)
- 数据库: SQLite + SQLAlchemy ORM
- 开发工具: VS Code, Jupyter Notebook
架构设计
- 数据层: 使用 SQLite 存储用户信息和预测记录,CSV 文件作为训练模型的基础数据集。
- 算法层 : 利用 Scikit-learn 进行数据预处理(缺失值填充、标准化、LabelEncoder)、特征工程及模型训练(Random Forest),并将训练好的模型保存为
.pkl文件供 Web 层调用。 - 应用层: Flask 后端负责路由分发、业务逻辑处理(登录注册、预测逻辑)以及与前端的数据交互。
- 展示层: 前端页面展示数据分析仪表盘和预测表单,通过 ECharts 实现数据的可视化展示。
3. 算法建模流程 (Jupyter Notebook)
算法建模是本系统的核心引擎。我们在 Jupyter Notebook 中完成了从数据探索到模型保存的全过程。
3.1 数据加载与预处理
我们使用 healthcare-dataset-stroke-data.csv 数据集。在预处理阶段,重点处理了:
- 缺失值处理 :
bmi列存在缺失值,我们采用均值填充策略。 - 数据清洗 : 删除了对预测无用的
id列。
python
df = pd.read_csv('healthcare-dataset-stroke-data.csv')
df.head()
# 使用均值填充 BMI 缺失值
imputer = SimpleImputer(strategy='mean')
df['bmi'] = imputer.fit_transform(df[['bmi']])
# 再次检查
df.isnull().sum()
# 删除 id 列
df = df.drop('id', axis=1)3.2 探索性数据分析 (EDA)
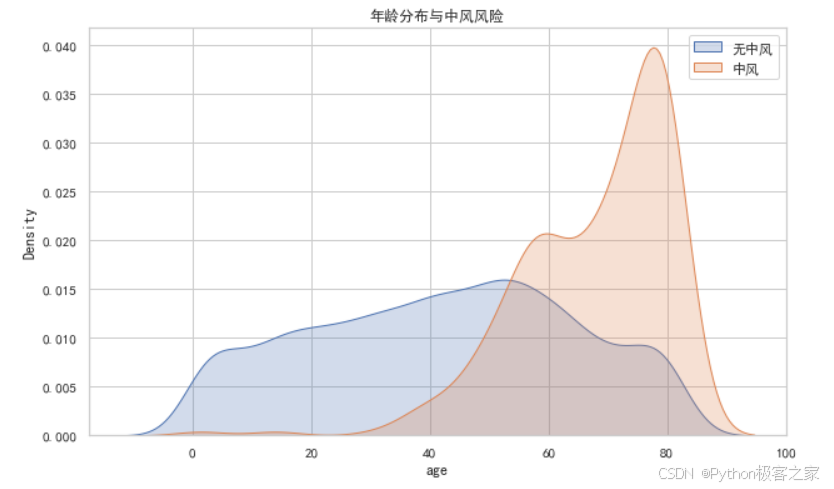
通过 seaborn 和 matplotlib 对数据进行了多维度的可视化分析,例如分析年龄、血糖水平与中风的关系。
(1)类别特征分布
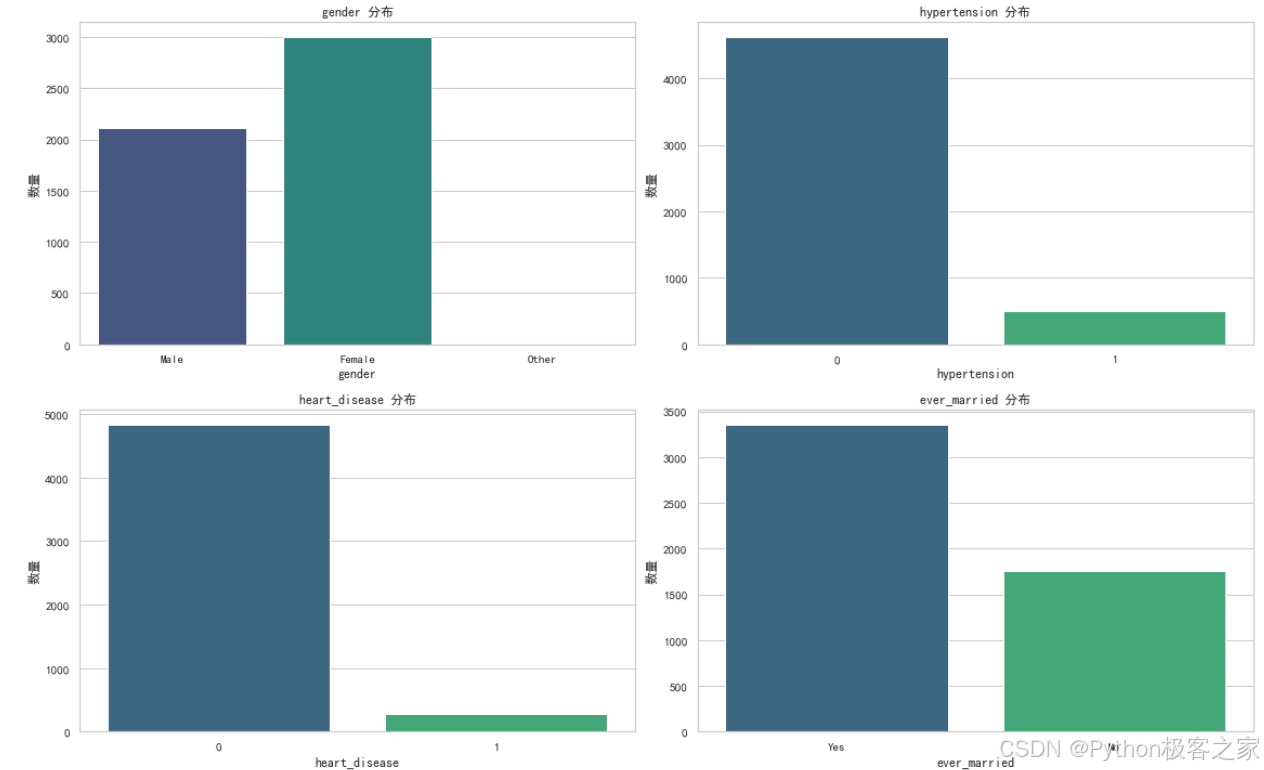
(2)数值特征分布
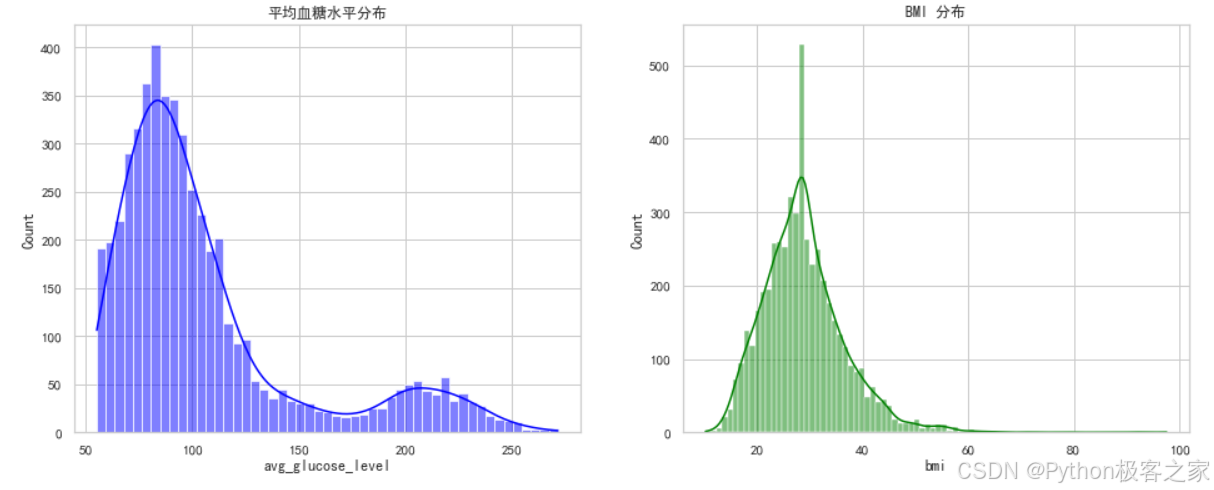
(3)数值型特征相关性
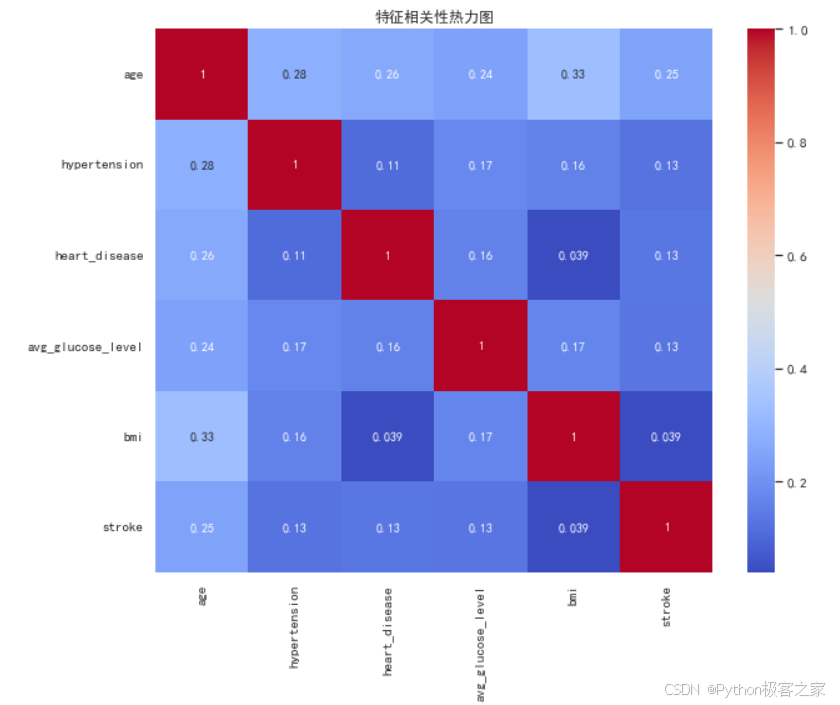
(4)数值特征与中风的关系 (箱线图)
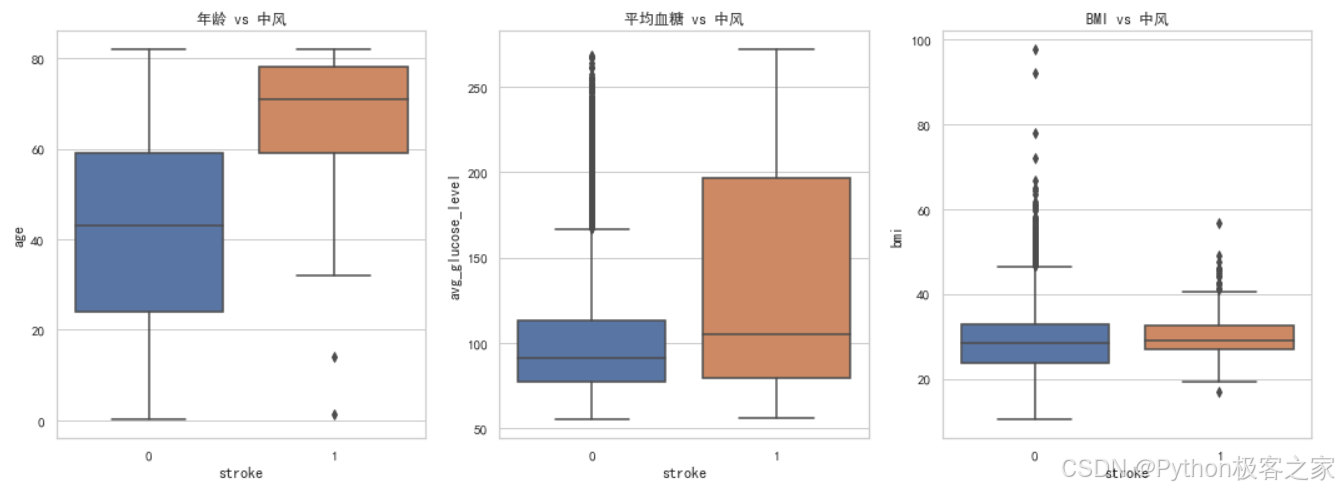
(5)年龄与中风的关系
3.3 特征工程与建模
- 特征编码 : 将文本类型的分类变量(如
gender,work_type)转换为数值编码。 - 标准化 : 对
avg_glucose_level和bmi等连续变量进行标准化处理。 - 模型训练 : 选用 Random Forest Classifier,因为它能够很好地处理非线性关系且抗过拟合能力强。
- 模型评估: 使用准确率 (Accuracy) 和混淆矩阵 (Confusion Matrix) 评估模型表现。
python
categorical_cols = ['gender', 'ever_married', 'work_type', 'Residence_type', 'smoking_status']
le_dict = {}
for col in categorical_cols:
le = LabelEncoder()
df[col] = le.fit_transform(df[col])
le_dict[col] = le
print(f"{col} 编码映射: {dict(zip(le.classes_, le.transform(le.classes_)))}")
df.head()使用随机森林 (Random Forest) 进行训练。
python
# 初始化模型
model = RandomForestClassifier(n_estimators=100, random_state=42)
# 训练
model.fit(X_train_scaled, y_train)
# 预测
y_pred = model.predict(X_test_scaled)
# 评估
print("准确率:", accuracy_score(y_test, y_pred))
print("分类报告:", classification_report(y_test, y_pred))
# 混淆矩阵
cm = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(6,5))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.title('混淆矩阵')
plt.ylabel('真实值')
plt.xlabel('预测值')
plt.show()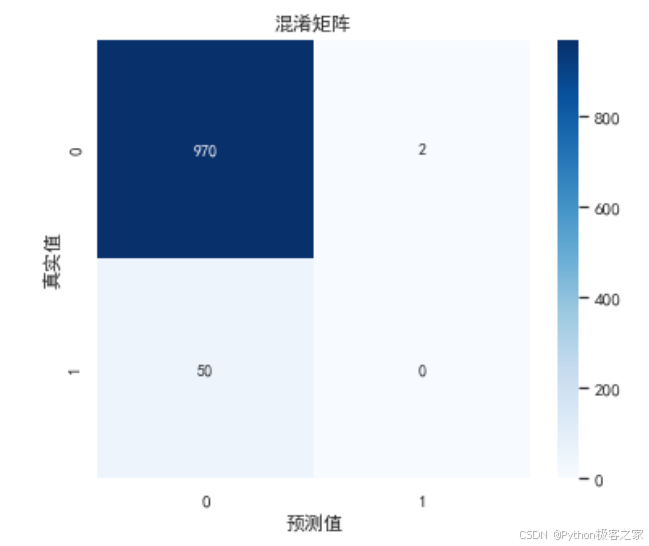
4. Web 系统功能详解
Web 系统为用户提供了可视化的交互界面,主要包含以下功能模块:
4.1 系统首页
4.2 用户注册登录
系统采用了现代化的 Tailwind CSS 进行 UI 设计,风格简约大气。实现了完整的用户注册、登录及登出功能,保障了用户数据的私密性。
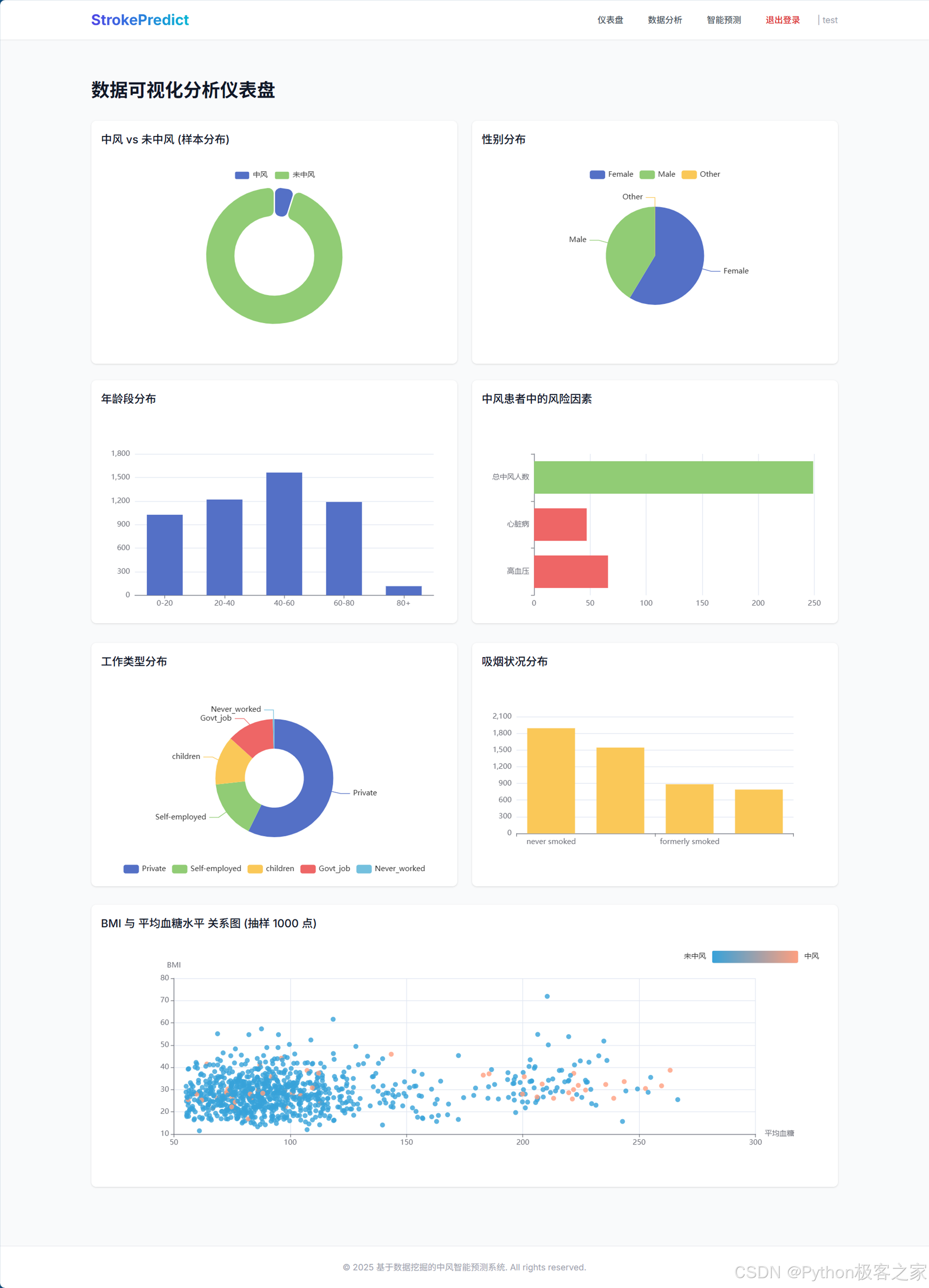
4.3 数据可视化仪表盘 (/analysis)
这是系统的亮点之一。我们集成了 ECharts,将静态的数据分析结果转化为可交互的动态图表。
- 多维展示: 包含中风样本分布、风险因素(高血压/心脏病)占比、BMI 与血糖的散点图分析等。
- 动态交互: 用户可以悬停查看具体数值,或通过图例筛选数据。
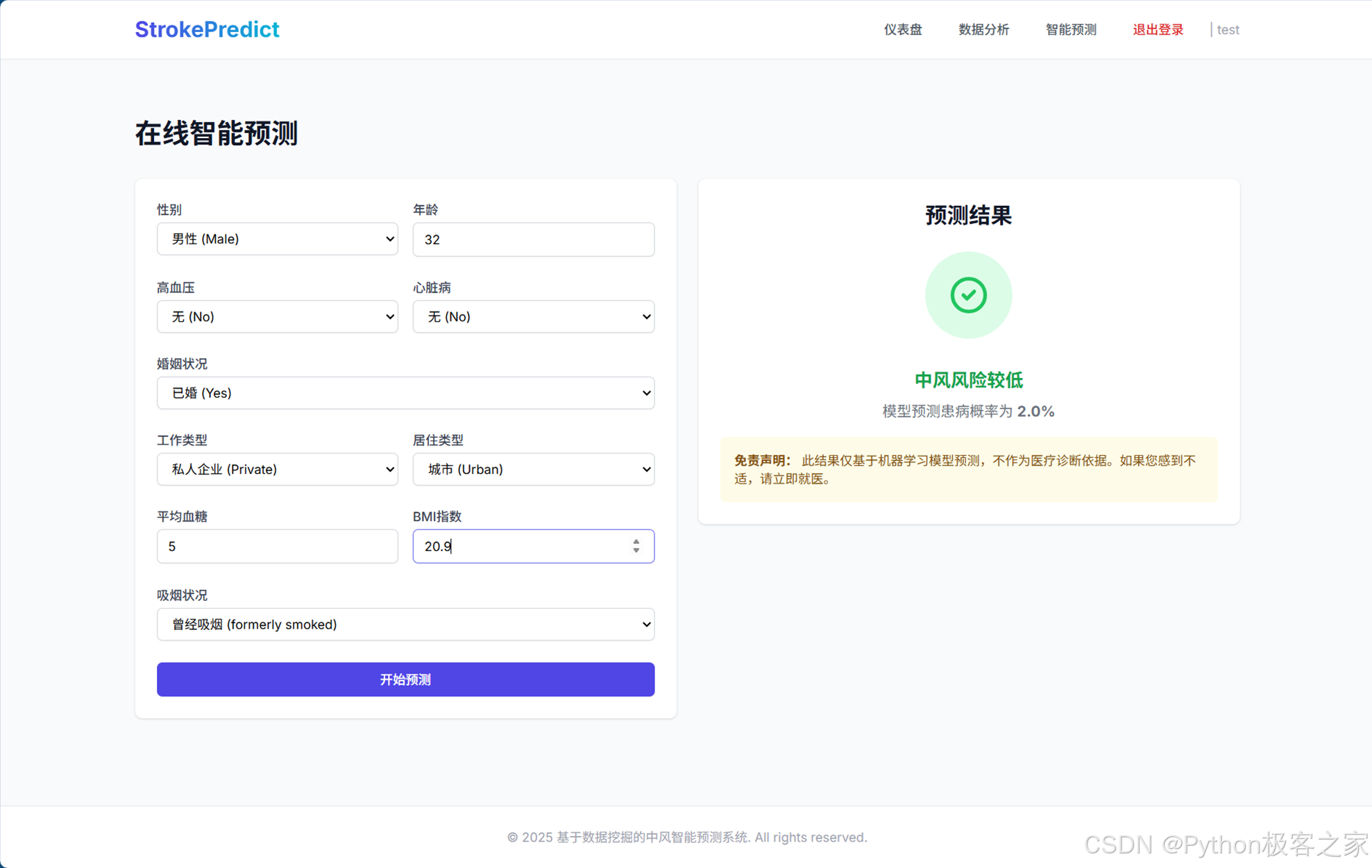
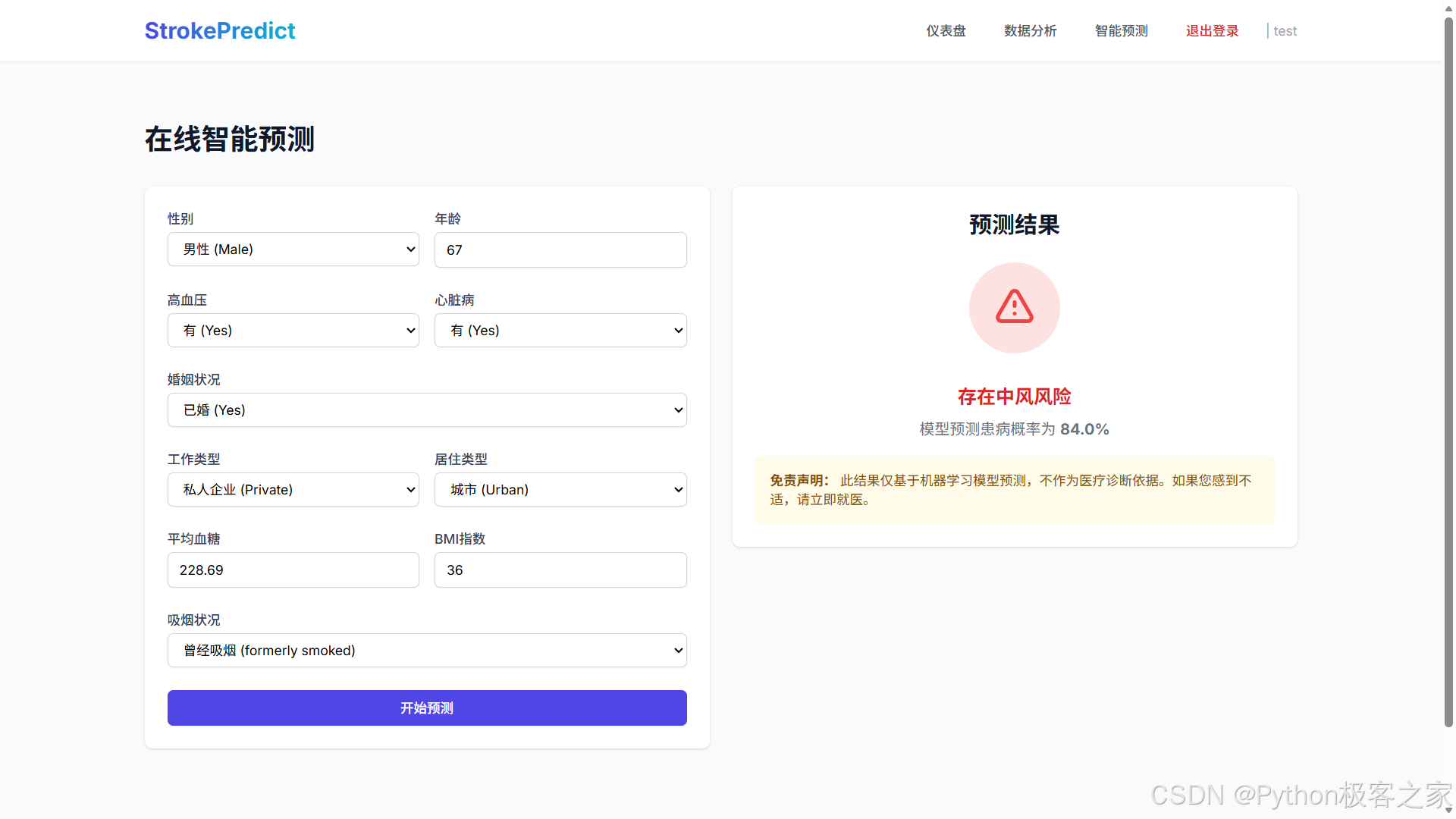
4.4 智能风险预测 (/predict)
用户在前端填写健康信息表单,后端加载预训练的 .pkl 模型进行实时推理。
- 输入便捷: 表单设计简洁,支持下拉选择。
- 实时反馈: 点击预测后,系统立即给出"低风险"或"高风险"的判断及具体的概率值。
5. 总结与展望
本项目成功实现了一个从底层算法到上层应用的中风智能预测系统。
- 成果: 完成了数据清洗、特征分析、模型构建,并成功部署到 Flask Web 应用中,实现了直观的数据可视化和便捷的预测服务。
- 改进方向: 未来可以尝试引入深度学习模型(如神经网络)以提高预测精度;在 Web 端增加用户历史健康数据的趋势跟踪功能;以及考虑移动端的适配开发。
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。技术交流、源码获取 认准下方 CSDN 官方提供的学长 QQ 名片 :)
精彩专栏推荐订阅:
