/------------Linux入门篇-----------/
/------------Linux工具篇------------/
/------------Linux进程篇-------------/
【 冯诺依曼体系与操作系统 】
进程是 Linux 系统资源调度的核心单元,而fork是创建进程的 "入门级" 系统调用 ------ 这篇文章先帮你理清进程的底层逻辑,再手把手带你吃透fork的用法与运行机制,搞懂 "一个进程如何变成两个"。


📊 文章专栏:<Linux>
📋 其他专栏:< C++ > 、<数据结构 > 、<优选算法>
目录
[【用 /proc 目录查看进程属性】](#【用 /proc 目录查看进程属性】)
[3、ps ajx指令](#3、ps ajx指令)
[【用 ps ajx 查看进程核心属性】](#【用 ps ajx 查看进程核心属性】)
[1、为什么 fork 要给子进程返回 0,给父进程返回子进程 pid?](#1、为什么 fork 要给子进程返回 0,给父进程返回子进程 pid?)
[4、fork 函数,究竟在干什么?干了什么?](#4、fork 函数,究竟在干什么?干了什么?)
【问题】:调用fork()创建父子进程后,父进程和子进程谁会先运行?
一、进程概念
1、通俗理解
你可以把进程理解成 "正在内存里跑的程序 ":
- 当你双击一个程序(比如.exe),它会被加载到内存,此时就变成了 "进程";
- 系统里同时开着的浏览器、微信,本质都是独立的进程(也叫 "任务")。
2、官方定义
- 课本说法:进程是 "程序的一个执行实例",或者 "正在执行的程序";
- 内核视角:进程是操作系统分配资源(CPU 时间、内存)的基本单位------ 系统给谁分资源?就是给进程分。
3、进程的组成结构
进程 =PCB(进程控制块) + 程序的代码&数据 + 系统分配的独立资源
【拆解一下】:
- 代码 & 数据: 就是你写的程序逻辑(比如 C++ 的
main()函数)和要处理的变量 / 对象;- **系统资源:**核心是内存(分成代码段、数据段、栈、堆等区域),还包括 CPU 时间片、打开的文件句柄等;
- PCB: 这是进程的 "身份证",下面重点讲它。
这三者不是孤立的 ------PCB 记录进程的属性和资源位置,系统资源给代码 & 数据提供运行空间,代码 & 数据是进程实际要执行的内容"
4、进程的特点
- 动态性:进程是程序的执行过程,有生命周期
- 并发性:多个进程可以在操作系统中并发执行
- 独立性:每个进程都有自己独立的地址空间
- 异步性:进程以不可预知的速度向前推进
进程是操作系统进行资源分配和调度的基本单位。通过进程管理,操作系统能够让多个程序 "同时" 运行,充分利用计算机资源。
二、如何管理进程?
操作系统进行管理时,会先对一个对象进行描述,然后再进行组织,接下来就从描述和组织两方面讲解如何管理进程
1、描述进程
任何一个进程,在加载到内存的时候,形成真正的进程时,操作系统,要先创建描述进程的结构体对象,也就是**"PCB"(process ctrl block)****,全名"进程控制块"**
**PCB:**描述进程属性值的结构体
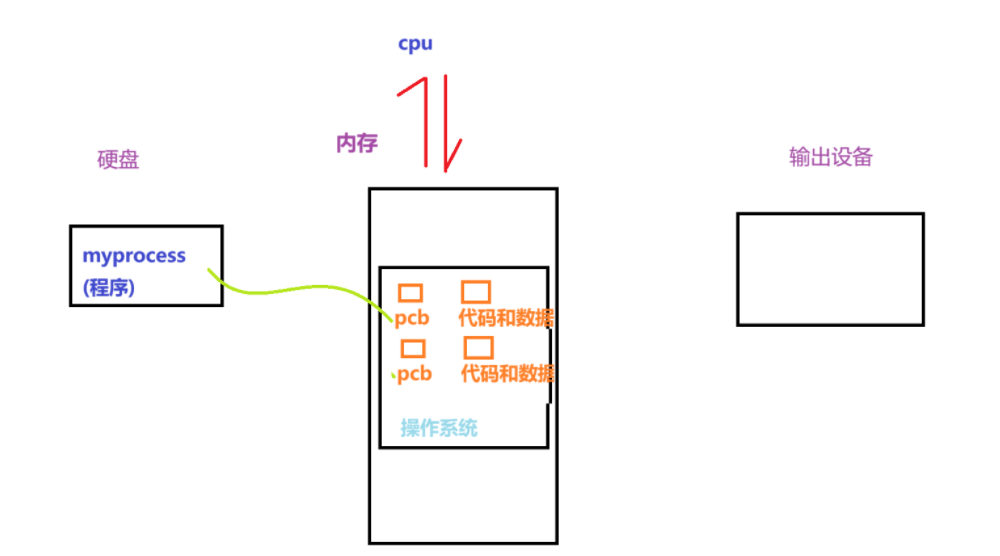
操作系统要同时管几十个进程,靠的就是PCB(Process Control Block) ------ 每个进程对应一个 PCB 结构体,系统通过管理 PCB 来管理进程。
- 这就好比我们了解一个人,不会深究他本身,而是先了解他的属性(比如姓名、年龄),当属性够多,这一堆属性的集合,就是目标对象;OS 管理进程也一样,靠 PCB 里的进程属性就能完成管控。
2、组织进程
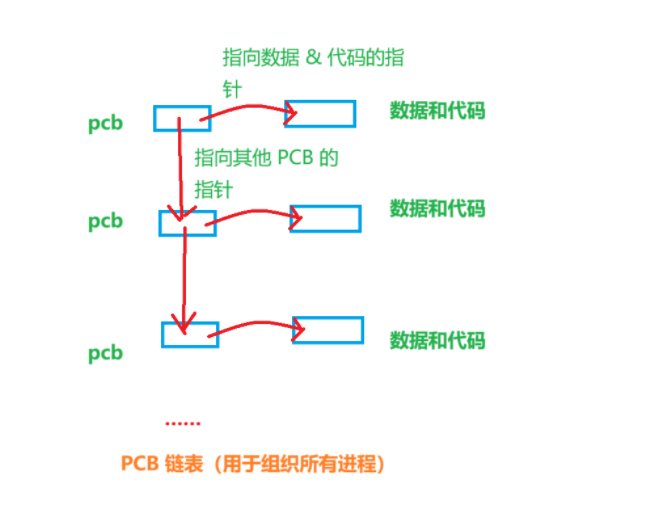
- 在组织进程时,每个进程都由 "PCB(进程控制块)" 和 "数据 & 代码" 两部分独立模块组成。因此,我们会在 PCB 结构体中定义一个指针,让 PCB 指向对应的进程数据和代码------ 这样操作系统就能通过 PCB 快速找到进程的实际运行内容。
- 同时,操作系统中会同时存在大量进程,为了高效管理这些进程,我们还会在 PCB 里再定义一个指针,用它把多个进程的 PCB 链接成链表结构。
- 通过这两个指针,操作系统既能快速定位单个进程的资源,又能便捷地对所有进程进行增删、调度等管理操作。
三、Linux_PCB
我们上述所说的 PCB(进程控制块) 是针对所有操作系统的通用概念 ,提取了进程的公共属性 ;但不同操作系统的进程属性存在差异,各自的 PCB 也会包含专属属性。
所以,接下来我会先简单介绍 Linux 系统下的 PCB,后面的文章会对这些属性做详细讲解。
1、task_struct
- 在Linux中描述进程的结构体叫做task_struct。
- task_struct是Linux内核的一种数据结构(也就是一种自定义类型),它会被装载到RAM(内存)里并且包含着进程的信息(进程属性)

2、task_struct内容分类
- 进程的管理不是只依赖task_struct这一个结构:你想对进程做哪方面的管理,就会把它放到对应的辅助数据结构中。
- 比如想让进程在运行队列里等待CPU,就把它的task_struct节点加入运行队列;想管理阻塞的进程,就放到阻塞队列里。
- 标示符: 描述本进程的唯一标示符,用来区别其他进程。
- 状态: 任务状态,退出代码,退出信号等。
- 优先级: 相对于其他进程的优先级。
- 程序计数器: 程序中即将被执行的下一条指令的地址。
- 内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
- 上下文数据: 进程执行时处理器的寄存器中的数据休学例子,要加图CPU,寄存器。
- I/O状态信息: 包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。
- 记账信息: 可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
- 其他信息
四、如何查看进程
1、进程标识符(PID)
PID(Process ID,进程标识符)是操作系统为每个正在运行的进程分配的唯一数字编号,用于在系统中标识、管理不同的进程。
它的核心作用是:让操作系统能精准区分每个独立的进程(就相当于你的电话号码,能通过电话号码精准找到你),每个进程在其生命周期内都会持有一个唯一的 PID,进程终止后,其 PID 可能会被系统回收复用。
2、/proc目录
进程的所有属性信息可以通过 /proc 系统文件夹查看,/proc 下的进程信息会随进程终止自动销毁------ 因为 /proc 是虚拟文件系统,其中的进程目录(如 /proc/PID)是动态生成的:进程运行时,系统会在 /proc 下创建对应 PID 的目录并填充信息;进程终止后,该目录会被系统自动删除,关机时整个 /proc 文件系统也会随系统停止而消失。
【用 /proc 目录查看进程属性】

在 Linux 中,用ls /proc能查看当前运行的进程:输出里的蓝色数字(如 1、113)是进程 PID 对应的目录(每个运行程序的唯一标识)。进入
cd /proc/[PID]目录,这里的虚拟文件包含该进程所有属性(比如status看优先级 / 线程数、statm看内存、cmdline看启动命令),用cat命令(如cat /proc/[PID]/status)就能查看完整信息。目录里的driver等黑字文件是系统配置,普通用户无需关注。
3、ps ajx指令
ps ajx 是 Linux 中查看系统所有进程核心属性的命令,其侧重点是展示进程的关联关系与详细元信息(如进程树结构、父进程 ID(PPID)、进程关联的终端等)拆解开每个参数的作用更清楚:
- **
ps:**基础指令,用来显示系统里的进程信息;a: 显示所有用户的进程(不光是你当前登录用户的);j:显示进程的控制终端、进程组这些管理相关的信息;x:显示没有控制终端的进程(比如后台运行的程序)。合起来用
ps ajx,就能一次性看到系统里所有进程的完整列表,包括后台进程、其他用户的进程,还能看到进程的归属、运行终端这些细节~
【用 ps ajx 查看进程核心属性】

ps ajx | head -1 && ps ajx | grep ./test
ps ajx:列出系统所有进程(含所有用户、后台进程);| head -1:只取进程列表的第一行(即表头,比如 PPID、PID、COMMAND 列名);&&:先执行左边命令,再执行右边;| grep ./test:过滤出和./test相关的进程(含运行的./test程序,及过滤用的grep进程)。

有人可能好奇,我过滤的是
./test进程,这行咋还有个grep ./test?其实它是执行grep ./test时临时启动的进程 ------ 因为它的命令里包含./test,所以会被自己过滤出来。不过这个进程是瞬时的,执行完过滤操作就会立刻终止。前面的指令也会产生相应的进程,不过也是瞬时的,执行完立马就销毁了。
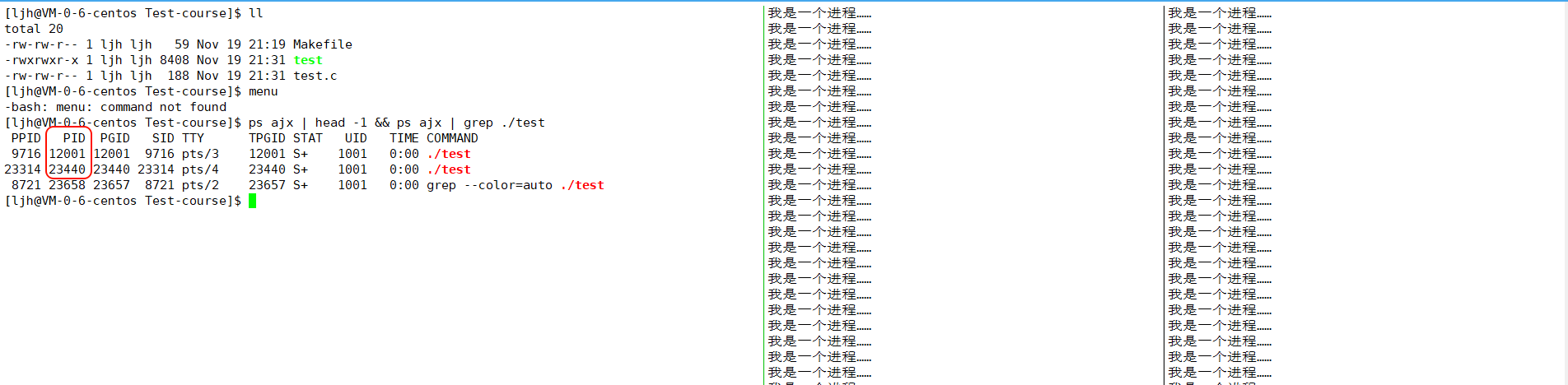
"我现在将同一个程序执行了两次,从进程列表可以看到:系统实际创建了两个独立的进程(对应不同 PID)。这也体现了程序与进程的关系:同一个程序每执行一次,系统就会为其创建一个独立的进程实例------ 每个进程拥有唯一的 PID,以及独立的资源(如内存空间),彼此是相互独立的运行实体。"
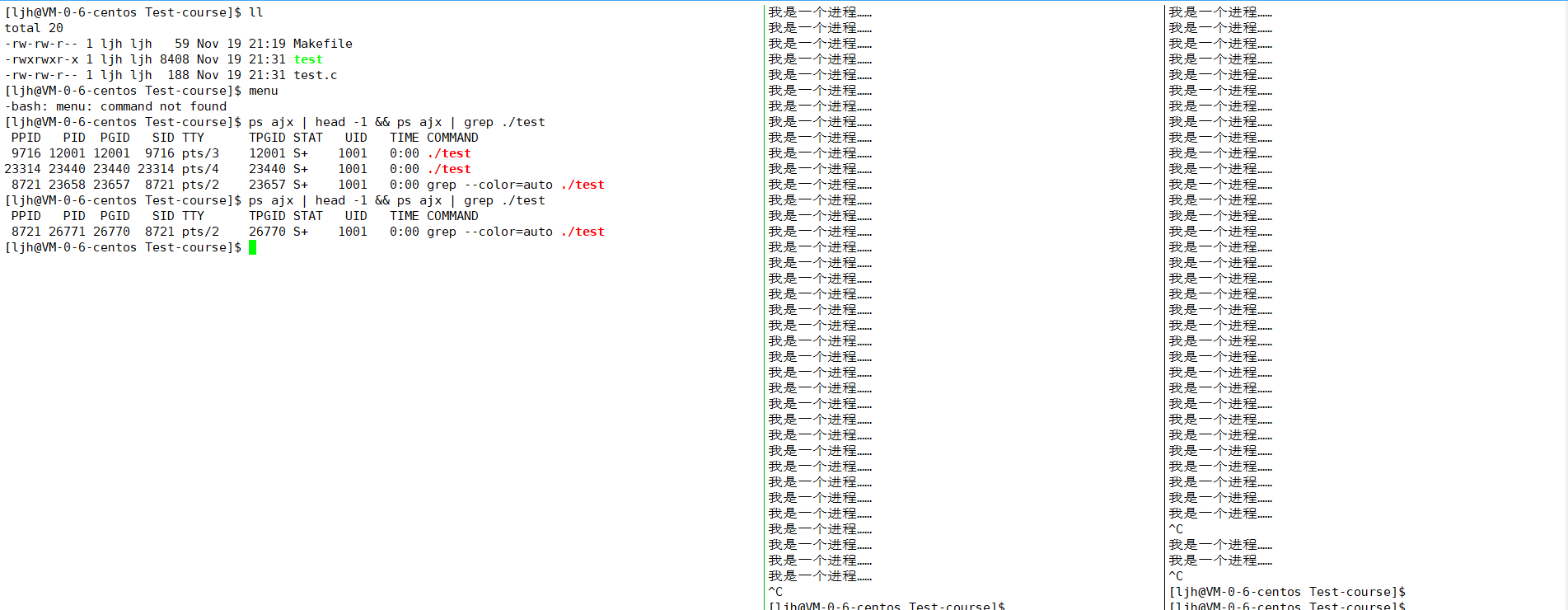
"终止程序后,对应的进程会被系统回收(即进程终止并释放资源);再次执行该程序时,系统会为新启动的进程分配新的 PID------ 由于 PID 是动态分配且可能被复用,但通常新进程的 PID 与之前的 PID 不会重复。"
下面是通过/proc目录查看到2183进程的相关属性,我们目前关注圈的这两个属性
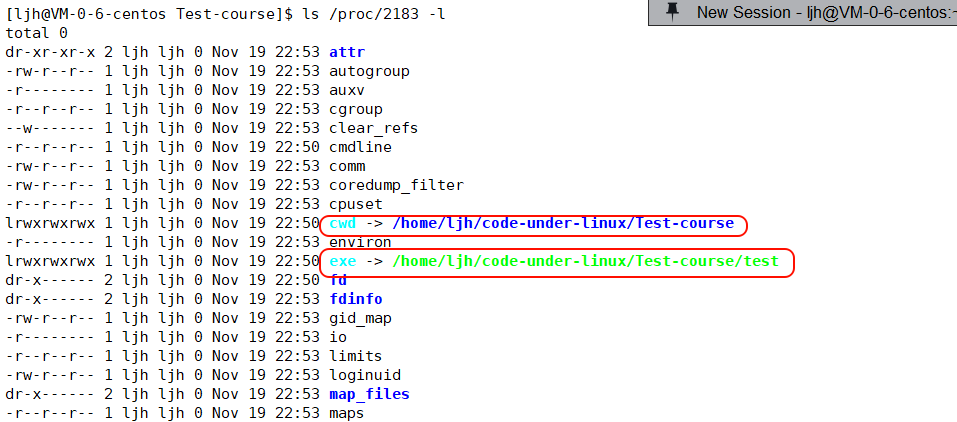
cwd是 "Current Working Directory" 的缩写,代表这个进程的当前工作目录。示例里
cwd -> /home/ljh/code-under-linux/Test-course,说明 2183 进程运行时的工作目录是这个路径。exe 代表这个进程对应的可执行文件路径。示例里
exe -> /home/ljh/code-under-linux/Test-course/test,说明 2183 进程是由test这个可执行程序启动的。
【问题】:为什么创建文件默认用当前路径?
- 这是因为进程的 "当前工作目录"(对应
/proc/[PID]/cwd)会作为默认路径- 当进程启动时,操作系统会在进程的 PCB(进程控制块)中记录它的 "当前工作目录"(也就是进程启动时所在的路径)。
- 当我们在程序中创建文件但不指定路径时,系统会自动使用 PCB 里记录的 "当前工作目录" 作为默认路径,所以文件会直接创建在这个路径下。
- 举个例子:如果进程启动时所在的路径是
/home/ljh/Test-course(对应/proc/2183/cwd的指向),那程序里执行创建文件操作时,文件就会直接生成在/home/ljh/Test-course目录下。
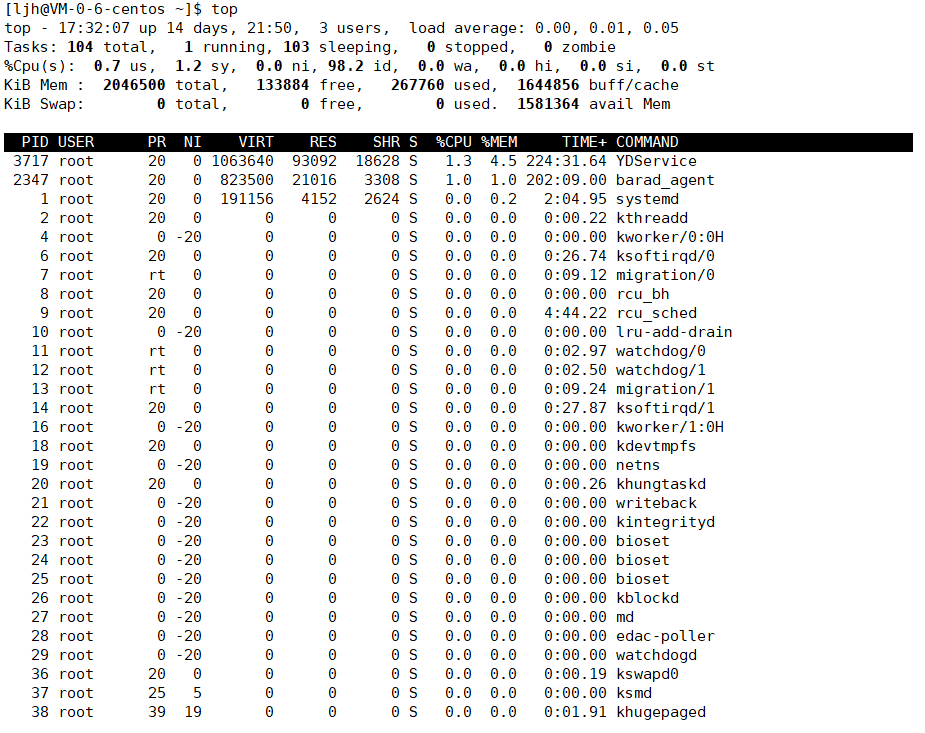
4、top指令
top是 Linux 中用于实时监控系统进程与资源状态的命令,其侧重点是动态展示进程的资源占用情况与系统整体负载(如 CPU / 内存使用率、进程实时状态、系统平均负载等),默认会周期性刷新数据(通常每 3 秒一次),便于实时跟踪资源消耗情况。
5、通过系统调用获得进程标识符
1、父子进程
- 父进程:创建其他进程的进程(对应
PPID列,即 "父进程 ID");- 子进程:由父进程创建的新进程(对应
PID列,其PPID等于父进程的PID)。


在 Linux 终端中,所有你手动执行的程序(比如./test),都是由当前终端的 bash 进程创建的,所以 bash 是这些程序进程的父进程。只要不退出当前终端(bash 进程不终止),这些程序的 PPID(指向 bash 的 PID)就不变;若退出终端再重新登录,新终端会启动新的 bash 进程(PID 改变),此时新执行程序的 PPID 会变成新 bash 的 PID。
问题:为啥bash需要创建子进程?
bash 创建子进程主要是为了保障自身稳定 + 实现指令的独立执行,核心原因有 2 点:
避免自身崩溃每条指令 / 程序对应独立进程,bash 通过创建子进程执行指令 ------ 即便子进程(比如运行的
./test)崩溃,也不会影响 bash 本身的运行,能继续处理后续命令。实现指令的独立与权限管控bash 的核心作用是 "解析命令 + 限制非法操作",子进程可以独立承载指令的执行逻辑,同时 bash 能通过进程权限机制,管控子进程的操作范围(阻止不符合权限的行为)。
2、getpid
getpid是 Linux 下的函数,它的核心作用是获取当前进程自己的进程 ID(PID) 。每个进程在系统中都有唯一的 PID,通过getpid可以在程序内部拿到自身的标识,常用于日志记录、进程间通信时标记自身身份等场景。
3、getppid
getppid的作用是获取当前进程的父进程 ID(PPID)。每个进程都是由另一个进程创建的,getppid能拿到创建当前进程的父进程的标识,常用于程序中确认自身的父进程是谁、判断父进程是否存活等场景。
两者的返回类型都是pid_t ,表示有符号整数
- 正整数:对应系统中真实存在的进程 PID(每个进程的 PID 都是正整数);
- 0:是系统保留的特殊 PID(对应内核空闲进程,不会分配给普通用户进程);
- -1:是约定俗成的 "无效 PID " 标识(比如
fork()创建进程失败时会返回 - 1,waitpid()指定 "等待任意子进程" 时也会用 - 1 作为参数)。不过要注意:
pid_t本身是有符号类型,所以能表示负数值,但实际系统中不会给进程分配负的 PID,负数仅用于表达 "特殊状态 / 无效"。
五、通过fork创建进程
我们目前学的创建进程的方法是执行可执行文件,这是从终端外部启动新进程的方式。而如果想在运行中的程序内部手动创建新进程,就要用到核心函数系统调用接口fork:它能让当前进程(父进程)复制出一个与自身代码、数据几乎一致的子进程,子进程既可以继续执行父进程的逻辑,也能配合
exec系列函数执行其他程序,是程序内部实现多进程的基础。
【拓展知识】
1. 并发(Concurrency)
- 核心定义 :多个任务在同一时间段内交替执行,宏观上看似 "同时进行",微观上是单个执行单元(如单核 CPU)快速切换处理。
- 核心特点:侧重 "任务调度方式",不要求多个执行单元,单核即可实现。
- 举例:电脑同时开浏览器、微信、文档,CPU 快速切换处理三个程序的请求。
【并发的 "迷惑点"】:
- 不是 "同时做",是 "快速切换着做"------ 比如你边吃饭边回消息,实际是 "吃一口→看手机→吃一口",微观上是串行交替,宏观上像同时进行。
- 单核 CPU 的并发,本质是 "时间分片":操作系统把 CPU 时间分成小片段,每个任务分一块,快速切换给用户 "同时运行" 的错觉。
2. 并行(Parallelism)
- 核心定义 :多个任务在同一时刻被不同的执行单元(如多核 CPU 的不同核心)同时处理。
- 核心特点:侧重 "同时执行",必须依赖多个执行单元(多核、多设备),单核无法实现。
- 举例:双核 CPU 同时处理 "浏览器请求" 和 "微信消息",两个任务真正同步推进。
【并行的 "限制条件"】:
- 必须有 "多个执行单元"------ 比如你和朋友一起搬砖,是真正的并行;但你一个人 "左手搬砖 + 右手递砖",其实是并发(同一时间段内交替做)。
- 并行的效率上限是 "执行单元数量":比如 8 核 CPU 最多同时处理 8 个任务,再多的任务就得靠并发调度。
3. 高并发(High Concurrency)
- 核心定义 :同一时间段内有大量任务请求的并发场景,是 "并发的高强度版本"。
- 核心特点:侧重 "任务规模",不特指执行方式,通常结合并行 + 并发协同处理。
- 举例:电商秒杀 10 万人抢票、春运抢票、直播平台百万用户同时互动。
【高并发的 "核心矛盾"】:
- 不是 "技术",是 "问题"------ 高并发的难点是 "大量请求同时来,系统扛不住",所以需要用 "并发调度(拆分任务)+ 并行处理(多核 / 集群)+ 缓存 / 限流" 等技术解决。
- 举例的 "强度差异":普通并发是 "3 个软件同时开",高并发是 "100 万人同时点一个按钮",前者靠单核调度就行,后者必须上集群 + 分布式。
【fork函数原型】

上图展示的是函数原型和头文件包含;

成功时,父进程中会返回子进程的 PID (进程 ID),而子进程中会返回 0。失败时,父进程中会返回 - 1,不会创建子进程,同时会适当设置errno(错误码)。
这个时候就会有问题了,为啥一个函数会有两个返回值?这在我们C语言之前的学习中肯定是没见过的,接下来就根据这个问题展开学习fork函数的原理!
【fork函数演示】
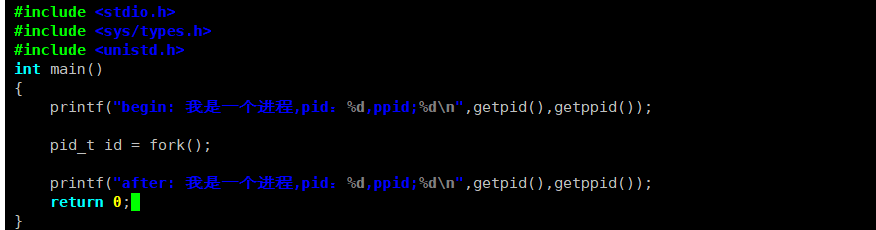

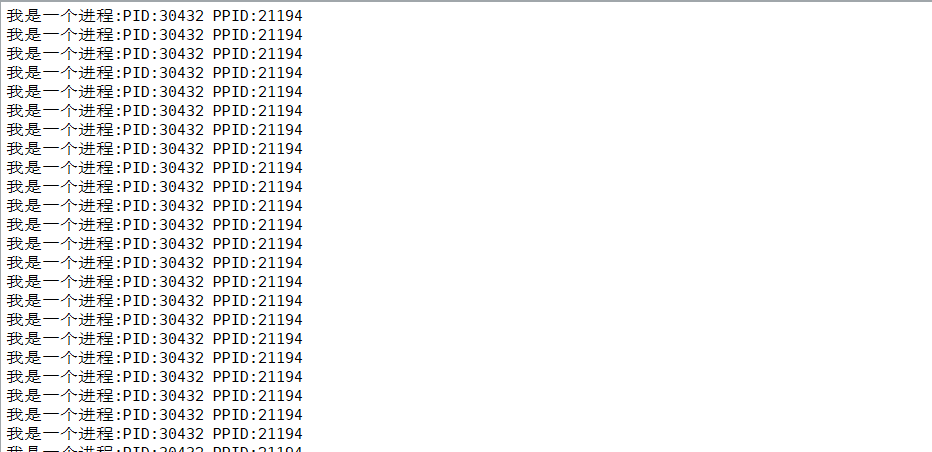
程序运行后能看到:
fork之后的代码执行了两次;而且第二次执行结果里的 PPID(父进程 ID),恰好是第一次执行结果里的 PID(进程 ID)------ 这是不是正好能说明,当前程序中已经创建出一个子进程了?
六、fork函数原理
1、为什么 fork 要给子进程返回 0,给父进程返回子进程 pid?
父子关系的唯一性约束一个父进程可以创建多个子进程,但一个子进程只有一个父进程:
- 子进程不需要 "区分父进程"(它的父进程是唯一的,可通过
getppid()直接获取父进程 PID),所以返回0即可(0是 "无特殊标识" 的约定值);- 父进程需要 "管理多个子进程"(比如给子进程发信号、回收资源),必须通过子进程的 PID 来唯一标识每个子进程,因此返回子进程 PID。
为了区分执行流,实现不同逻辑fork 返回不同值,是为了让父子进程能执行不同的代码块:代码中可以通过
if(id==0)(子进程)、if(id>0)(父进程)的判断,让父子进程分别进入不同的逻辑分支(比如子进程执行任务、父进程等待子进程结束)。
2、一个函数是如何做到返回两次的?如何理解?
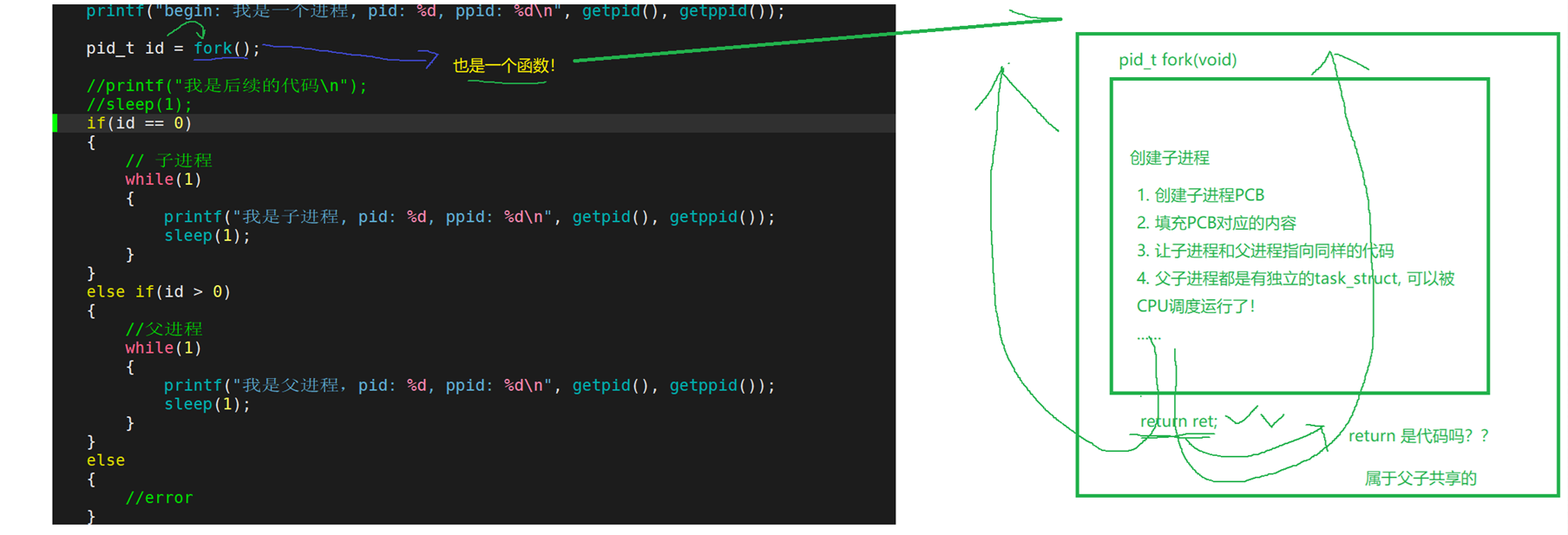
核心逻辑是:
fork函数通过复制进程的方式,让父进程和子进程在各自独立的地址空间(后面学了虚拟地址空间就明白了)中继续执行,从而使得 fork 之后的代码(包括返回操作)被执行两次
fork的核心行为 :fork函数执行时,会创建一个与当前进程(父进程)几乎完全相同的新进程(子进程)。这个复制过程包括:
- **代码段共享:**父子进程执行的是同一份程序代码
- 数据段(写时拷贝 - Copy-On-Write): 初始时,子进程共享父进程的数据段、堆和栈。但是,一旦任何一个进程(父或子)试图修改这些数据,系统会立即为修改方创建一个该数据的私有副本。 这就是 "写时拷贝 " 机制(在fork执行结束后,运行fork后代码时才会发生)
- 进程控制块(PCB)独立: 系统会为子进程创建一个全新的、独立的 PCB,其中包含了新的进程 ID(PID)、父进程 ID(PPID)等信息
"返回两次" 的本质(聚焦
id的写时拷贝):fork 函数开始执行时,只有父进程。当 fork 完成子进程创建后,内核会将父子进程设为就绪态,等待调度
父进程的执行流 :父进程从 fork 调用处继续执行。此时,fork 需要将 "子进程 PID" 写入变量
id------ 这个写操作触发写时拷贝 ,内核为父进程创建id的私有副本,父进程中id的值为子进程 PID(>0)子进程的执行流 :子进程同样从 fork 调用处执行。此时,fork 需要将 "0" 写入变量
id------ 这个写操作也触发写时拷贝 ,内核为子进程创建id的私有副本,子进程中id的值为 0
【总结】:
fork 通过创建子进程并结合写时拷贝机制,让 id 变量分裂为两个独立副本(分别存储子进程 PID 和 0 这两个不同返回值),这并非 fork 函数本身返回了两次,而是 fork 创建新进程后,借助写时拷贝为父子进程生成了 id 的独立副本,使得后续代码在两个进程中各执行一次;而 id 的不同值(父进程中为子进程 PID、子进程中为 0)正是区分执行路径的关键,通过判断 id 的值,就能让父子进程执行不同的代码逻辑,最终呈现出 "一个函数返回两次" 的现象。
【如何理解(聚焦
id)】:可以想象:你(父进程)看书到某一页(fork 调用),复制出一个自己(子进程)和同样的书(代码 / 数据)。你们都从这一页继续看,但这一页的
id内容会因写时拷贝 "分裂":
你(父进程)看到的id是 "子进程编号 X"(自己的副本); 复制的你(子进程)看到的id是 "编号 0"(自己的副本)。
3、一个变量怎么会有不同的内容?如何理解?
这不是一个变量存了两个值 ------
fork通过写时拷贝,让原本共享的id分裂成父子进程各自的私有副本 :
fork后,id初始共享且只读;- 当
fork返回时,父进程要存 "子进程 PID"、子进程要存 "0",这两个写操作会分别触发写时拷贝,为父子进程各创建一个独立的id副本;- 最终是两个独立的
id变量,各自存不同值,并非一个变量存了两个内容。
4、fork 函数,究竟在干什么?干了什么?
fork 函数的核心是创建一个和当前进程(父进程)几乎完全相同的新进程(子进程),具体干了这几件事:
- 复制父进程的 PCB(进程控制块),给子进程分配新 PID;
- 让父子进程共享代码段(只读),同时将数据段 / 堆 / 栈设为 "共享且只读"(为写时拷贝做准备);
- 把父子进程都设为就绪态,等待 CPU 调度;
- 最后通过写时拷贝,让父子进程各自得到不同的返回值(父进程是子进程 PID,子进程是 0),从而区分执行逻辑。
简单说:fork 就是 "复制进程 + 设置共享 / 写时拷贝 + 区分返回值",最终让两个进程从同一点开始独立执行。
【问题】:调用fork()创建父子进程后,父进程和子进程谁会先运行?
不确定。父子进程的运行顺序由操作系统的调度器决定,调度器会根据系统当前的进程队列、优先级、调度算法等因素分配 CPU 时间片,因此无法提前确定父进程还是子进程先获得运行权。
【小彩蛋】:写时拷贝的意义
写时拷贝的意义在于:以 "延迟拷贝" 的方式,既实现了进程创建时的高效(避免冗余数据复制),又保证了进程间的数据隔离(修改时自动独立),平衡了内存开销与执行效率。
