流匹配模型因其坚实的理论基础和在生成高质量图像方面的优异性能,已成为图像生成(SD, Flux)和视频生成(Sora,WanX,HunyuanVideo)领域最先进模型的训练方法。然而,即便是这些业界领先的模型,在处理包含多个物体、复杂属性关系的场景,以及文本渲染等任务时,仍然面临显著挑战。与此同时,在线强化学习凭借其高效的探索与反馈机制,在大语言模型领域已取得令人瞩目的进展,但其在图像生成领域的应用仍处于早期探索阶段。
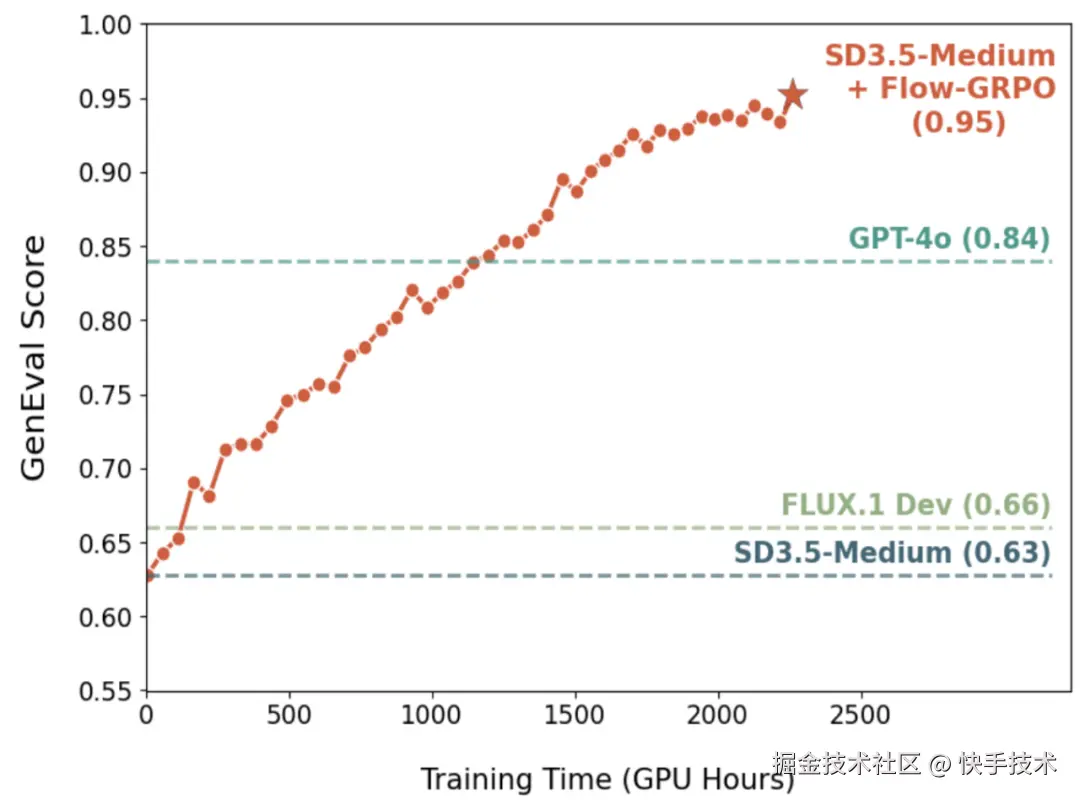
为此,港中文 MMLab、清华大学、快手可灵等团队联合提出 Flow-GRPO,首个将在线强化学习引入 Flow Matching 模型的开创性工作 。在 Flow-GRPO 加持下,SD3.5-Medium 在 GenEval 基准测试中的准确率从 63%提升到 95%,在该基准上甚至超越了 GPT-4o ,这说明流匹配模型仍具有巨大的提升空间可以被激发。
Flow-GRPO 的成功实践,为未来利用强化学习进一步解锁和增强各类流匹配生成模型(包括但不限于图像、视频、3D 等多个模态)在可控性、组合性、推理能力方面的潜力,开辟了充满希望的新范式。
-
论文标题:Flow-GRPO: Training Flow Matching Models via Online RL

目前该论文已被 NeurIPS 2025 会议录用。全部训练代码均已开源,支持 SD-3.5, FLUX.1-Dev, FLUX.1-Kontext, Qwen-Image, Wan-2.1, Bagel 等主流生成模型的 GRPO 训练。
一、核心思路
Flow-GRPO 的核心在于两项关键策略,旨在克服在线强化学习与流匹配模型内在特性之间的固有矛盾,并大幅提升训练效率:
1. ODE-SDE 等价转换
流匹配模型本质上依赖确定性的常微分方程(ODE)进行生成。为满足强化学习探索所需的随机性,作者提出了一种创新的 ODE 到随机微分方程(SDE)的转换机制。该机制在理论上严格保证了转换后的 SDE 在所有时间步上均能精确匹配原始 ODE 模型的边缘分布,从而在不改变模型基础特性的前提下,为强化学习提供了有效的探索空间。
2. 去噪步数「减负」提效
在强化学习训练采样阶段,大胆减少生成步数(例如从 40 步降至 10 步),极大加速数据获取效率;而在最终推理生成时,仍然使用完整步数,确保高质量输出。这种"训练时轻量化,推理时完整化"的策略,在极大提升在线强化学习训练效率的同时,保证了性能不下降。
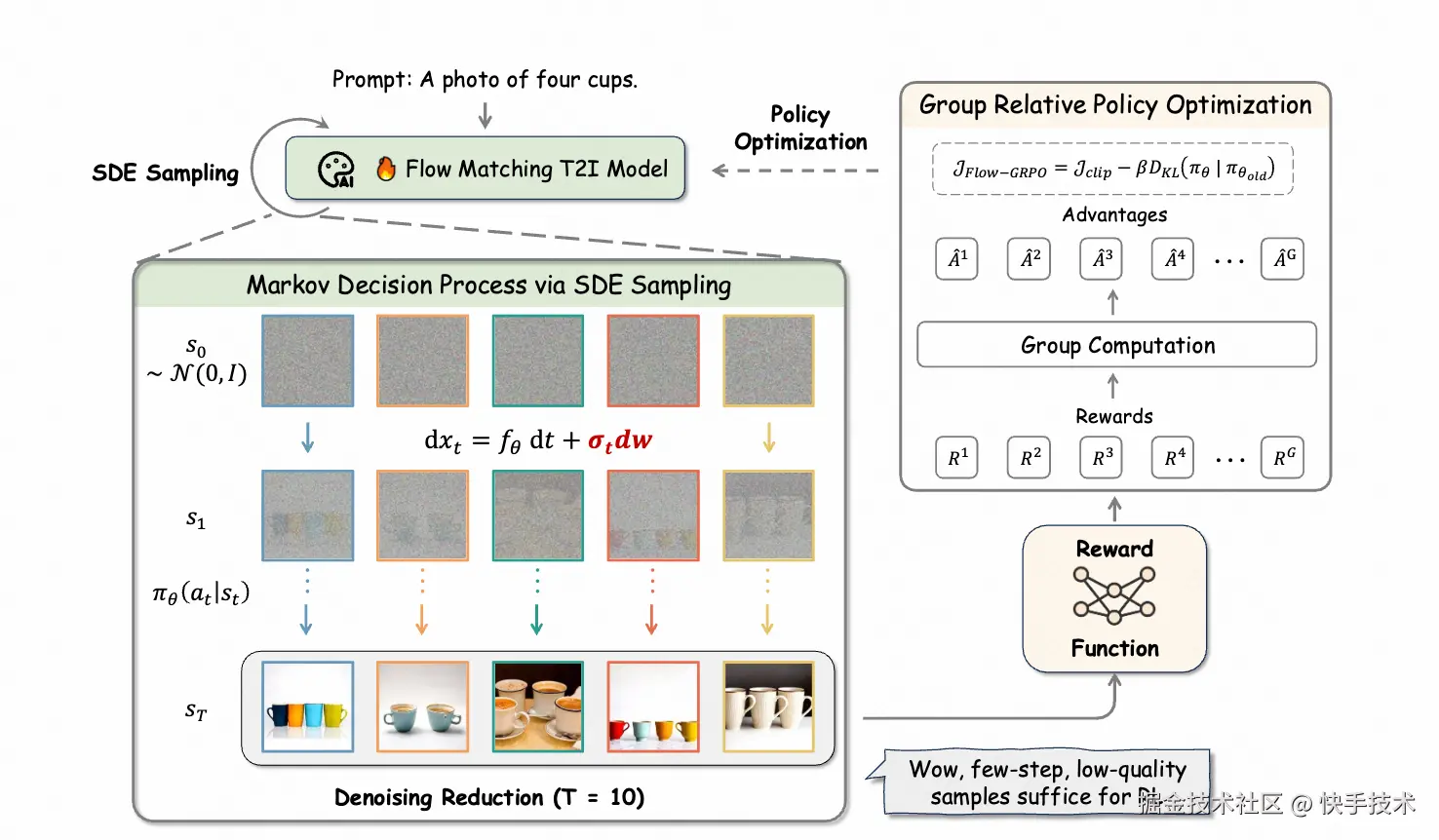
二、ODE to SDE
GRPO(Group Relative Policy Optimization)依赖随机采样过程,以生成多样化的轨迹批次用于优势估计和策略探索。然而,流匹配模型的确定性采样过程无法满足 GRPO 的这一要求。
为解决这一根本性限制,作者将确定性的 Flow-ODE 巧妙转换为一个等效的 SDE,使其精确匹配原始模型的边际概率密度函数(详细数学证明见论文附录 A)。
原始的 flow matching 模型的推理公式:
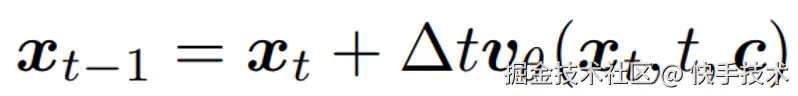
转换为 SDE 后的采样形式:
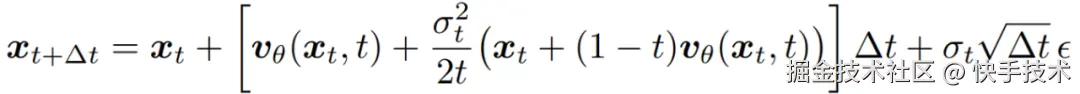
通过控制噪声水平参数,可以精准调节强化学习策略的探索性,在保持模型生成质量的同时,赋予其必要的随机性。
三、Denoising Reduction
为了生成高质量的图像,流匹配模型通常需要大量的去噪步骤,这使得在线强化学习的训练数据收集成本较高。作者发现,对于在线强化学习训练,较大的时间步长在样本生成时是多余的,只需要在推理时保持原有的去噪步骤仍能获得高质量的样本。
作者在训练时将时间步长设置为 10,而推理时的时间步长保持为原始的默认设置 40。通过这样的「训练时低配,测试时满配」的设置,在不牺牲最终性能的前提下,实现了训练速度的大幅提升。
四、核心实验效果
Flow-GRPO 在多个文本到图像(T2I)生成任务中展现出卓越表现:
1. 复杂组合生成能力大幅提升
在 GenEval 基准测试中,将 SD3.5-M 的准确率从 63% 提升至 95%,在物体计数、空间关系理解、属性绑定等多个维度达到近乎完美的水平,在该评测榜单上效果超越 GPT-4o!
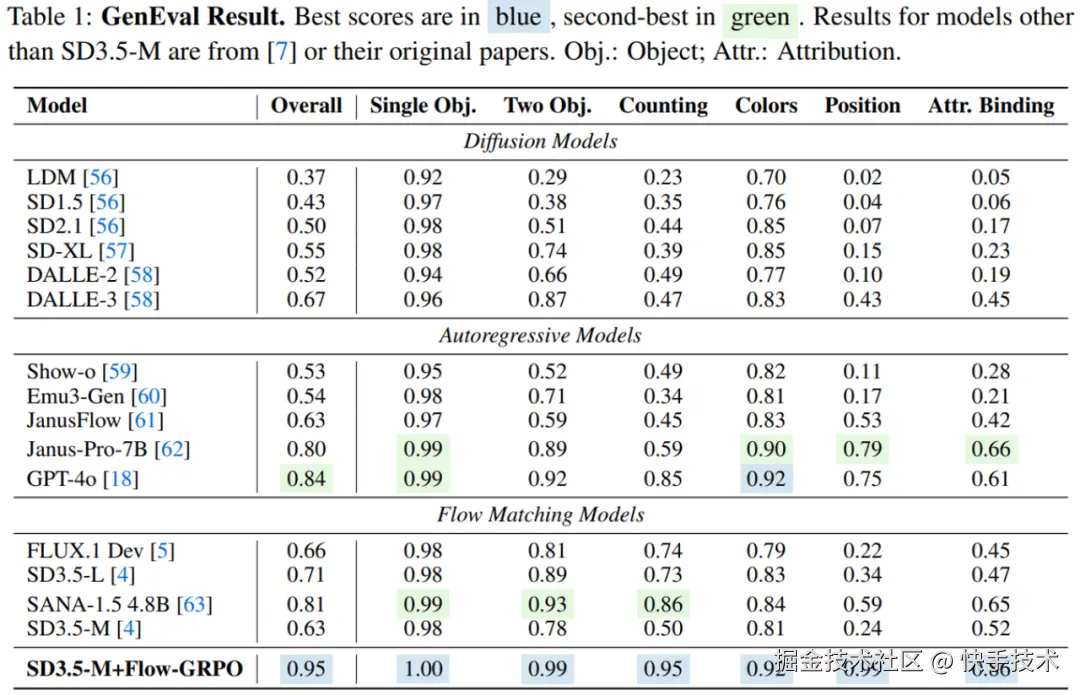

2. 文字渲染精准无误
视觉文本渲染准确率从 59% 大幅提升至 92%,可以精准地在图像中渲染复杂文字内容。

3. 更懂人类偏好
在人类偏好对齐任务上同样取得了显著进步,生成的图像更符合人类审美标准。

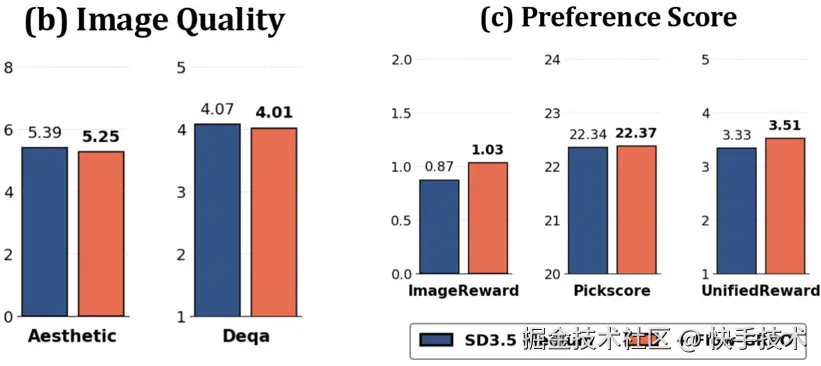
4. 有效抑制奖励黑客行为
Flow-GRPO 在性能大幅提升的同时,图像质量和多样性基本未受影响,有效缓解了强化学习中常见的 Reward Hacking 问题。
五、总结与展望
作为首个将在线强化学习成功引入流匹配模型的算法,Flow-GRPO 通过将流模型的确定性采样机制巧妙转化为随机微分方程(SDE)采样,并创新性地引入 Denoising Reduction 技术,实现了在流匹配模型上的高效在线强化学习。
**实验结果充分表明:**即便是当前最先进的流匹配模型,在引入强化学习后依然拥有巨大的性能提升空间。Flow-GRPO 在组合式生成、文字渲染和人类偏好对齐等多个任务上,相比基线模型均取得了质的飞跃。
Flow-GRPO 的意义不仅体现在指标上的领先,更在于其揭示了一条利用在线强化学习持续提升流匹配生成模型性能的可行路径 。其成功实践为未来进一步释放流匹配模型在可控性、组合性与推理能力方面的潜力,尤其在图像、视频、3D 等多模态生成任务中,提供了一个充满前景的新范式。