

前言
在C语言及底层开发中,数据在内存中的存储是核心基础知识点,直接影响程序的正确性、效率及跨平台兼容性。很多开发者在遇到类型转换异常、跨平台数据传输错误、调试时内存值与预期不符等问题时,根源往往是对内存存储规则理解不透彻。本文将从整数存储、大小端字节序、浮点数存储三个维度,结合原理推导、代码案例、调试过程,全方位拆解数据存储的底层逻辑,帮你彻底吃透这一知识点。
一、整数在内存中的存储
整数作为编程中最常用的数据类型,其二进制表示有三种形式:原码、反码、补码。这三种编码的核心作用是解决"符号位如何参与运算"的问题,最终实现"加法统一减法"的底层逻辑。
1.1 编码的通用结构
无论是原码、反码还是补码,都由两部分组成:
- 符号位 :占1位,位于二进制的最高位。
0表示正数,1表示负数。 - 数值位:剩余的位,用于表示数值的大小。例如32位int类型,符号位占1位,数值位占31位。
1.2 正整数的编码规则
正整数的原码、反码、补码完全相同,无需额外转换,直接将十进制数翻译成二进制即可。
- 示例:int类型的
5(32位)- 二进制数值:
00000000 00000000 00000000 00000101 - 原码 = 反码 = 补码 =
00000000 00000000 00000000 00000101
- 二进制数值:
1.3 负整数的编码规则
负整数的三种编码差异显著,转换需遵循固定流程:
- 原码 :直接将数值的绝对值翻译成二进制,再将最高位设为
1(符号位)。 - 反码 :符号位保持不变,数值位按位取反(
0变1,1变0)。 - 补码 :反码的基础上加1(若加1后有进位,需依次进位,直至无进位)。
详细示例:int类型的-5(32位)
- 绝对值
5的二进制:00000000 00000000 00000000 00000101。- 原码:最高位置
1→10000000 00000000 00000000 00000101。- 反码:符号位不变,数值位取反 →
11111111 11111111 11111111 11111010。- 补码:反码加1 →
11111111 11111111 11111111 11111011。
1.4 核心结论:内存中存储的是补码
计算机系统最终选择补码作为整数的存储形式,而非原码或反码,核心原因有三点:
- ① 符号位与数值域统一处理:无需额外硬件电路区分符号位和数值位,运算时可直接参与计算;
- ② 加法统一减法:CPU仅需设计加法器,减法运算可通过"加上减数的补码"实现(例如
a - b = a + (-b)的补码); - ③ 转换规则统一:补码转原码的流程与原码转补码完全一致(补码→反码→加1),无需额外逻辑。
实战验证:减法运算的底层实现
计算3 - 5(即3 + (-5)),通过补码验证:
3的补码:00000000 00000000 00000000 00000011;-5的补码:11111111 11111111 11111111 11111011;- 相加结果:
00000000 00000000 00000000 00000011 + 11111111 11111111 11111111 11111011 = 11111111 11111111 11111111 11111110;- 结果转原码:先取反(
10000000 00000000 00000000 00000001),再加1 →10000000 00000000 00000000 00000010(即-2),与预期结果一致。
二、大小端字节序
当数据占用的字节数超过1(如short、int、long等类型)时,就会面临"多个字节如何在内存地址中排列"的问题,这就是大小端字节序的核心。理解大小端是跨平台开发、数据序列化(如网络传输、文件存储)的关键。
2.1 大小端的严格定义
首先明确两个关键概念:
- 高位字节 :数据二进制中权重较高的字节。例如
0x11223344(32位int),0x11是最高位字节,0x22次之,0x44是最低位字节; - 内存地址 :内存以字节为单位划分,每个字节对应唯一的地址,地址从低到高依次递增(如
0x005DF848、0x005DF849、0x005DF84A...)。
基于以上概念,大小端的定义如下:
- 大端(Big-Endian)模式 :数据的高位字节 存储在内存的低地址 处,低位字节 存储在内存的高地址处。
- 小端(Little-Endian)模式 :数据的低位字节 存储在内存的低地址 处,高位字节 存储在内存的高地址处。
2.2 直观示例:0x11223344的存储方式
假设int变量a = 0x11223344,存储在内存地址0x005DF848开始的4个字节中,两种模式的存储差异如下:
| 内存地址 | 大端模式存储内容 | 小端模式存储内容 |
|---|---|---|
| 0x005DF848(低地址) | 0x11(最高位字节) | 0x44(最低位字节) |
| 0x005DF849 | 0x22 | 0x33 |
| 0x005DF84A | 0x33 | 0x22 |
| 0x005DF84B(高地址) | 0x44(最低位字节) | 0x11(最高位字节) |
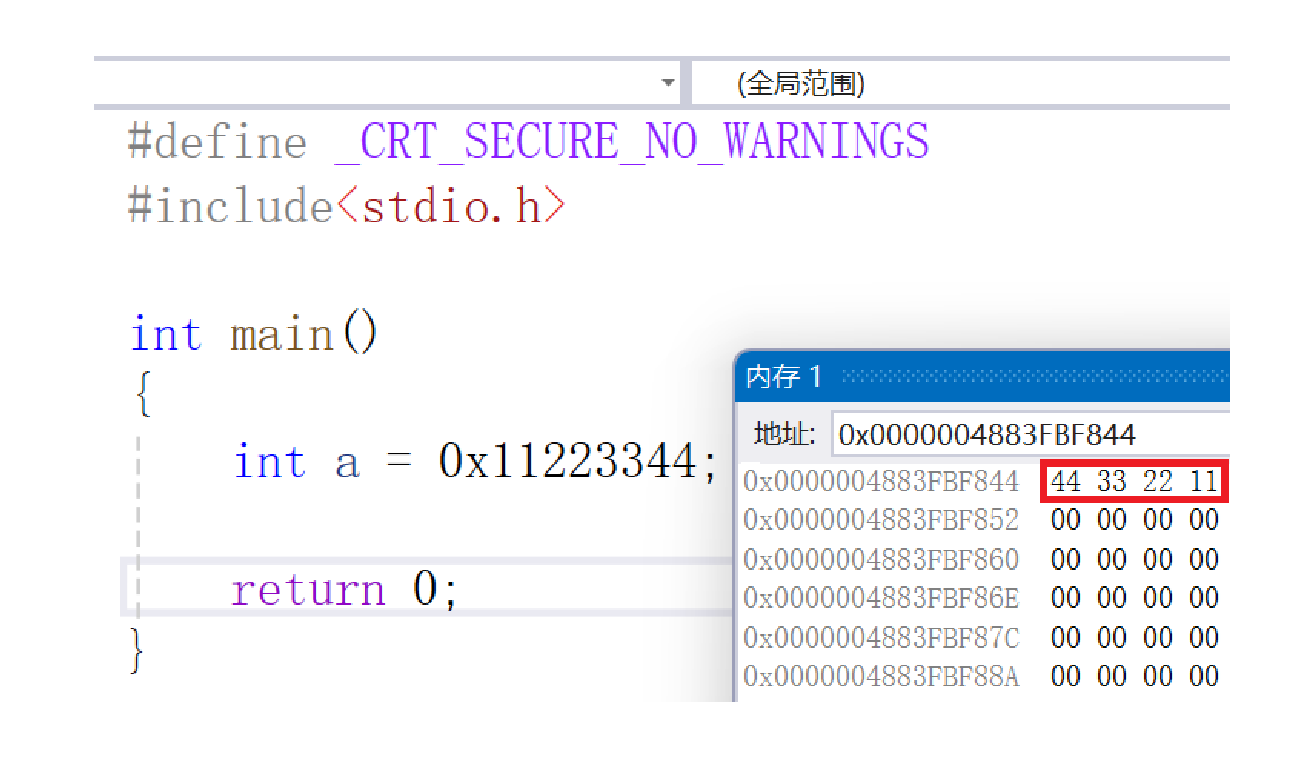
通过调试工具观察,X86架构(PC、服务器常用)中,内存显示为44 33 22 11,正是小端模式,与示例一致。
2.3 大小端存在的根本原因
计算机系统以"字节"为基本存储单位(1字节=8bit),但CPU的寄存器宽度(如16位、32位、64位)往往大于1字节。当CPU读取多字节数据时,需要明确"先读取哪个地址的字节",不同硬件厂商的设计选择不同,最终形成了两种模式:
- 大端模式:符合人类的阅读习惯(从高位到低位),常见于早期大型机、KEIL C51编译器、部分网络协议(如TCP/IP);
- 小端模式:更符合CPU的运算逻辑(从低位开始运算),常见于X86架构、大部分ARM处理器、DSP芯片,是目前主流模式。
2.4 面试考题:大小端判断的两种实现方案
判断当前机器的字节序是高频面试题,核心思路是:利用"多字节数据的最低位字节在小端模式下会存储在低地址"的特性,通过代码读取低地址的字节值来判断。
方案1:指针强制转换(最简洁)
c
#include <stdio.h>
// 返回1:小端;返回0:大端
int check_endian() {
int i = 1; // 二进制:00000000 00000000 00000000 00000001
char *p = (char *)&i; // 强制转换为char*,仅读取第一个字节(低地址)
return *p; // 小端:低地址存0x01,返回1;大端:低地址存0x00,返回0
}
int main() {
if (check_endian() == 1) {
printf("当前机器是小端模式\n");
} else {
printf("当前机器是大端模式\n");
}
return 0;
}方案2:共用体(union)特性(更易理解)
共用体(union)的核心特性是"所有成员共享同一块内存空间",利用这一特性可直接读取低地址的字节:
c
#include <stdio.h>
int check_endian() {
union {
int i; // 4字节
char c; // 1字节(共享i的低地址字节)
} un;
un.i = 1; // 给i赋值,c会读取i的低地址字节
return un.c; // 逻辑与方案1一致
}
int main() {
printf("当前机器是%s模式\n", check_endian() ? "小端" : "大端");
return 0;
}2.5. 经典练习解析
以下练习均来自实际面试题,核心考察"大小端+整数存储+类型转换"的综合应用:
练习1:unsigned char与signed char的差异
c
#include <stdio.h>
int main() {
char a = -1;
signed char b = -1;
unsigned char c = -1;
printf("a=%d, b=%d, c=%d\n", a, b, c); // 输出:-1, -1, 255
return 0;
}- 解析:
char默认是signed char(部分编译器除外),存储-1的补码为0xFF(8位)。- 打印时按
%d(int类型)输出,会发生"符号扩展":
signed char:符号位为1,扩展后补码为0xFFFFFFFF(32位),转原码为-1。unsigned char:无符号位,扩展后补码为0x000000FF,对应十进制255。
练习2:char类型存储超出范围的值
c
#include <stdio.h>
int main() {
char a = 128;
printf("%u\n", a); // 输出:4294967168
return 0;
}- 解析:
signed char的取值范围是-128~127,128超出范围,发生"溢出"。128的二进制为10000000,存储为signed char时,补码为10000000(对应-128)。- 按
%u(无符号int)输出,符号扩展为0xFFFFFF80,十进制为4294967168。
练习3:无限循环的陷阱
c
#include <stdio.h>
int main() {
unsigned char i = 0;
for (i = 0; i <= 255; i++) {
printf("hello world\n");
}
return 0;
}- 解析:
unsigned char的取值范围是0~255,无负数。- 当
i=255时,i++会溢出,结果为0,永远满足i <= 255,导致无限循环。
练习4:数组与指针的内存访问
c
#include <stdio.h>
int main() {
int a[4] = {1, 2, 3, 4};
int *ptr1 = (int *)(&a + 1);
int *ptr2 = (int *)((int)a + 1);
printf("%x, %x\n", ptr1[-1], *ptr2); // 输出:4, 2000000
return 0;
}- 解析(假设小端模式,int为4字节):
a的内存布局(低地址到高地址):01 00 00 00 02 00 00 00 03 00 00 00 04 00 00 00。&a是数组指针(类型为int(*)[4]),&a + 1指向数组末尾后4字节,ptr1[-1]等价于*(ptr1 - 1),指向数组最后一个元素4。(int)a是数组首地址的数值,(int)a + 1指向首地址后1字节,即00 00 00 02(小端模式下),解析为int是0x02000000(即2000000)。
三、浮点数的存储:IEEE 754标准的深度拆解
浮点数(float、double、long double)的存储规则与整数完全不同,遵循IEEE 754国际标准。这也是为什么"同一个内存值,按整数和浮点数解析结果完全不同"的核心原因。
3.1 浮点数的科学计数法表示
任意二进制浮点数V,都可以表示为以下形式(类似十进制的科学计数法):
V = (-1)\^S \\times M \\times 2\^E
- S(符号位) :
0表示正数,1表示负数,仅占1位; - M(有效数字) :满足
1 ≤ M < 2,形式为1.xxxxxx(xxxxxx为小数部分); - E(指数位):决定浮点数的数量级,可为正数或负数。
示例:十进制浮点数的二进制转换
- 十进制
5.0→ 二进制101.0→ 科学计数法1.01 × 2^2→S=0,M=1.01,E=2;- 十进制
-5.0→ 二进制-101.0→ 科学计数法-1.01 × 2^2→S=1,M=1.01,E=2;- 十进制
0.5→ 二进制0.1→ 科学计数法1.0 × 2^(-1)→S=0,M=1.0,E=-1。
3.2 IEEE 754的内存分配规则
IEEE 754标准为32位float和64位double规定了明确的内存分配方案:
| 类型 | 总位数 | 符号位(S) | 指数位(E) | 有效数字位(M) |
|---|---|---|---|---|
| float | 32 | 1(第31位) | 8(第23-30位) | 23(第0-22位) |
| double | 64 | 1(第63位) | 11(第52-62位) | 52(第0-51位) |
3.3 浮点数的存储流程
浮点数存储时,会对M和E进行特殊处理,以节省存储空间并统一格式:
步骤1:处理有效数字M
由于1 ≤ M < 2,M的整数部分永远是1,IEEE 754规定:存储时只保留小数部分 ,整数部分的1默认省略,读取时再补回。
示例:
M=1.01 → 存储时仅保留
01(23位不足时补0);M=1.10101 → 存储时保留10101。
步骤2:处理指数E
E是带符号整数(可正可负),但存储时需转为无符号整数,方法是加上一个"中间数"(偏移量):
- float(E为8位):中间数=127(取值范围0-255);
- double(E为11位):中间数=1023(取值范围0-2047)。
- 示例:E=2(float)→ 存储值=2+127=129(二进制
10000001);E=-1(float)→ 存储值=-1+127=126(二进制01111110)。
完整示例:float类型存储9.0
- 9.0的二进制:
1001.0→ 科学计数法:1.001 × 2^3。- S=0(正数)。
- M=1.001 → 存储小数部分
001,补0至23位 →00100000000000000000000。- E=3 → 存储值=3+127=130 → 二进制
10000010。- 最终存储的32位二进制:
0 10000010 00100000000000000000000(十六进制0x41100000)。
3.4 浮点数的读取流程(三种情况)
读取时需根据指数E的存储值,分三种情况处理,以float为例:
情况1:E不全为0且不全为1(正常情况)
- 步骤:E的真实值 = 存储值 - 127;M = 1 + 存储的小数部分。
- 示例:存储的E=130 → 真实E=130-127=3;M=1+0.001=1.001 → V=1.001×2^3=9.0。
情况2:E全为0(表示接近0的小数)
- 步骤:E的真实值 = 1 - 127 = -126;M = 0 + 存储的小数部分(不再补1)。
- 目的:表示±0和极小的数;
- 示例:E=00000000 → 真实E=-126;M=0.00000000000000000001001 → V=1.001×2^(-146)(接近0)。
情况3:E全为1(表示无穷大或NaN)
- 若M全为0:表示±无穷大(S=0为正无穷,S=1为负无穷)。
- 若M不全为0:表示NaN(Not a Number,非数值,如0/0、√-1)。
3.5 经典面试题:整数与浮点数的转换
c
#include <stdio.h>
int main() {
int n = 9;
float *pFloat = (float *)&n;
printf("n的值为:%d\n", n); // 输出:9
printf("*pFloat的值为:%f\n", *pFloat); // 输出:0.000000
*pFloat = 9.0;
printf("n的值为:%d\n", n); // 输出:1091567616
printf("*pFloat的值为:%f\n", *pFloat); // 输出:9.000000
return 0;
}这道题的核心是"同一个内存块,按不同类型解析的差异",我们分两步拆解:
第一步:int n=9 按float解析为0.000000
- int 9的32位二进制(补码):
00000000 00000000 00000000 00001001;- 按float格式拆分:S=0,E=00000000,M=000000000000000000001001;
- 符合"E全为0"的情况:E真实值=-126,M=0.00000000000000000001001;
- 计算V:
V = 1.001 × 2^(-146),是极小的正数,按%f输出时显示为0.000000。
第二步:float 9.0 按int解析为1091567616
- float 9.0的存储过程如前所述,最终32位二进制为:
0 10000010 00100000000000000000000;- 按int类型解析时,该二进制被视为补码(int存储补码);
- 计算该二进制对应的十进制:
0×2^31 + 1×2^30 + 0×2^29 + ... + 1×2^23= 1073741824 + 16777216 + 8388608 = 1091567616。
通过本文的详细拆解,相信你已经彻底理解了数据在内存中的存储规则。这些知识点不仅是面试的重点,更是底层开发的基础,掌握后能帮你快速定位各类内存相关的bug,提升代码的健壮性和兼容性。
至此,我们已梳理完"数据在内存中的存储"的全部内容了。最后我们在文末来进行一个投个票,告诉我你对哪部分内容最感兴趣、收获最大,也欢迎在评论区聊聊你的学习感受。
以上就是本期博客的全部内容了,感谢各位的阅读以及关注。如有内容存在疏漏或不足之处,恳请各位技术大佬不吝赐教、多多指正。

