先看下效果:
测试前飞书文档内容:

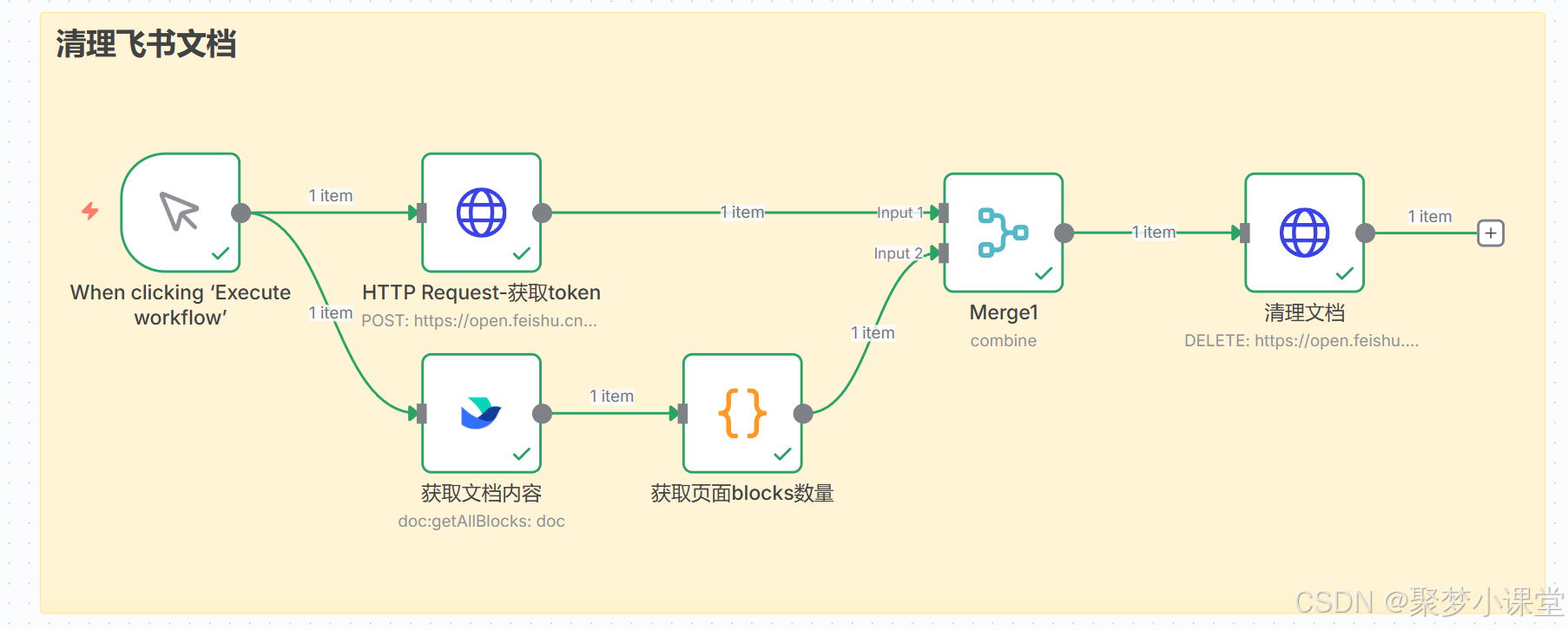
n8n工作流
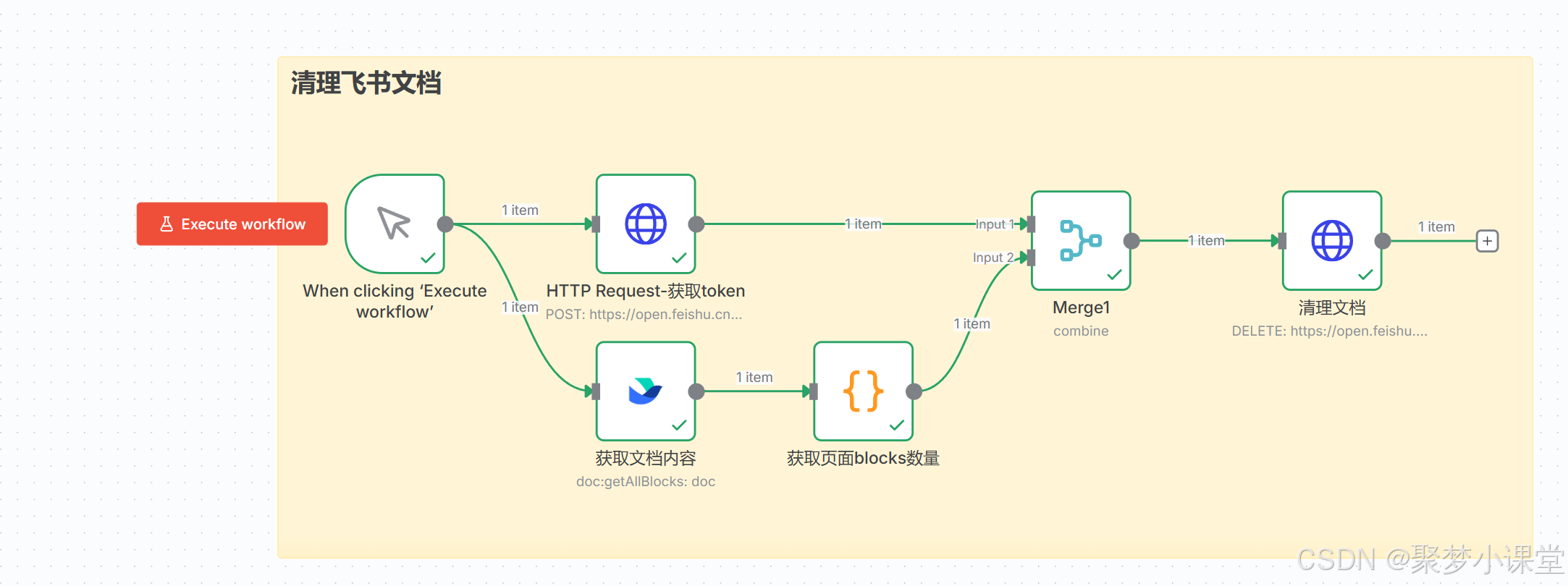
执行之后:

好了,如果这个需求也是你想实现的,那么可以继续往下看:
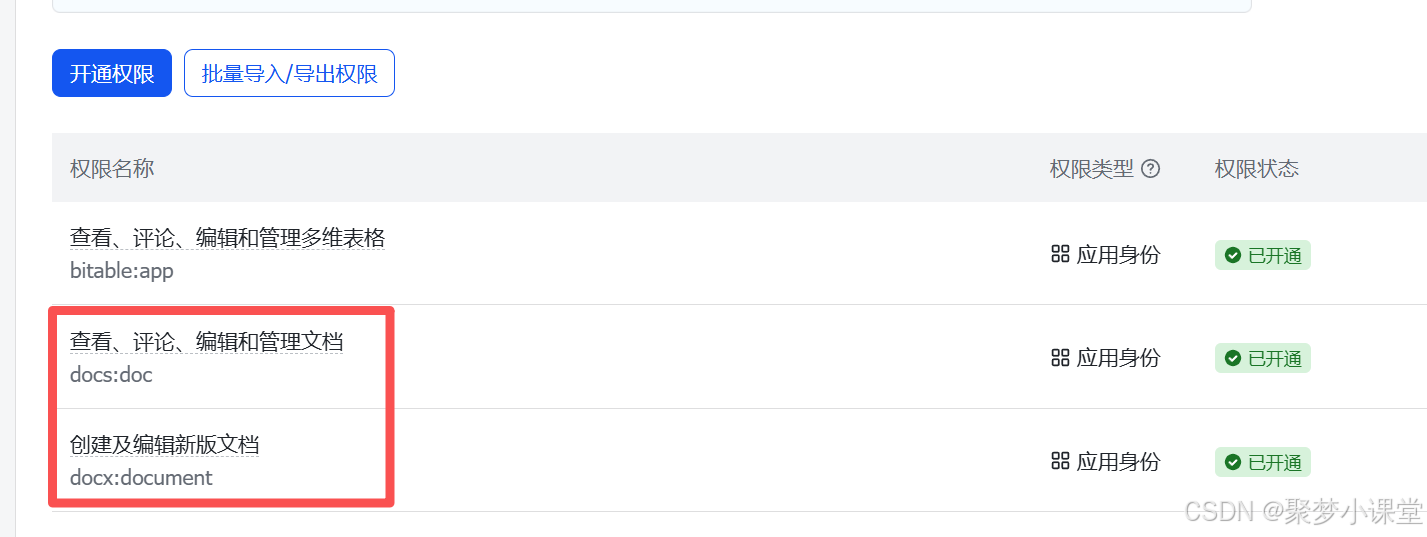
首先,你需要有一个做好的飞书应用,并且设置好飞书文档的读写权限,这一步比较简单,直接略过。保证这两个权限都开了就好(其实开docx应该就可以):
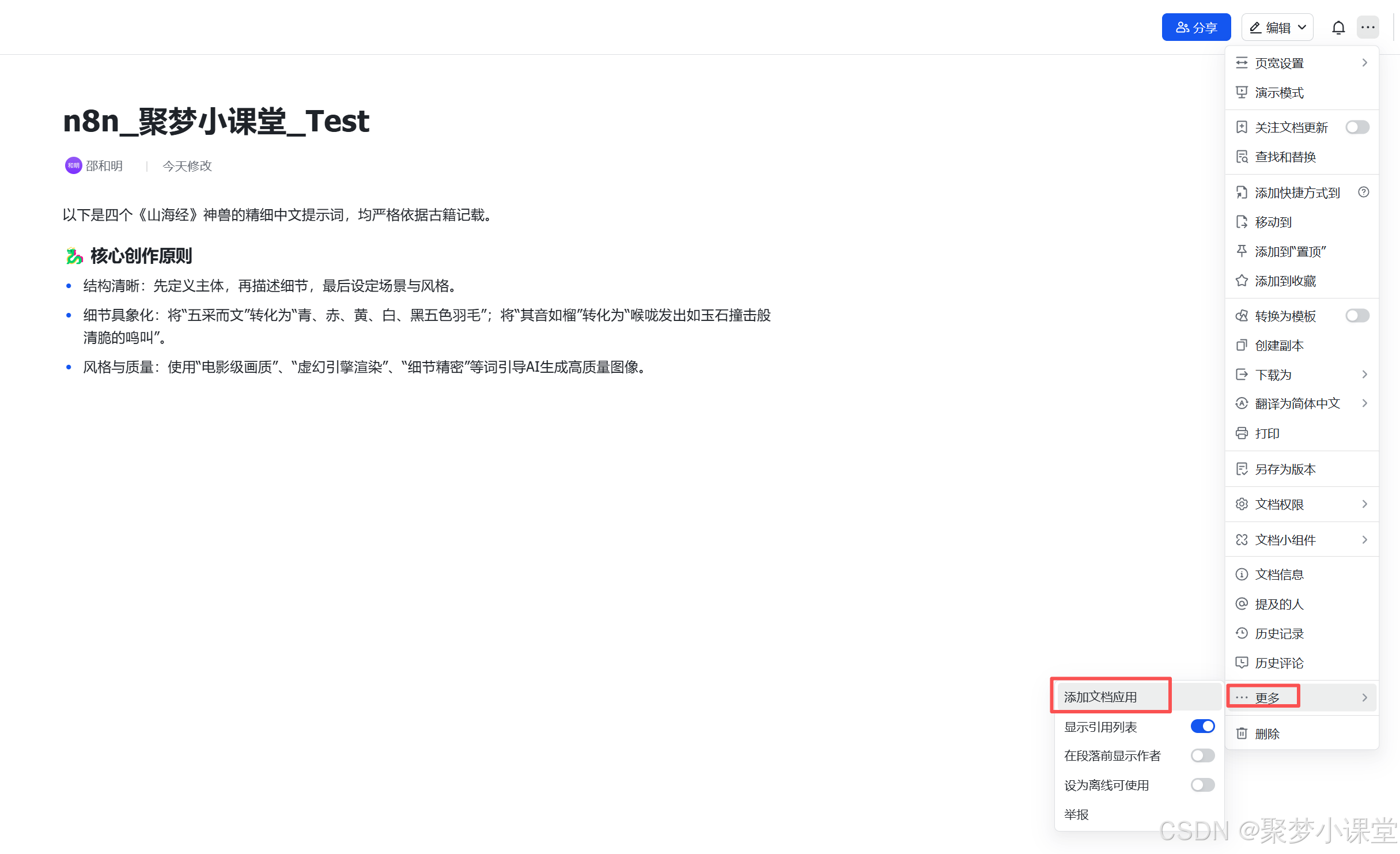
然后在要操作的飞书文档页面添加你申请好的飞书应用:
第三步,回到n8n中,从社区节点里边安装一个飞书的社区节点:feishu-lite
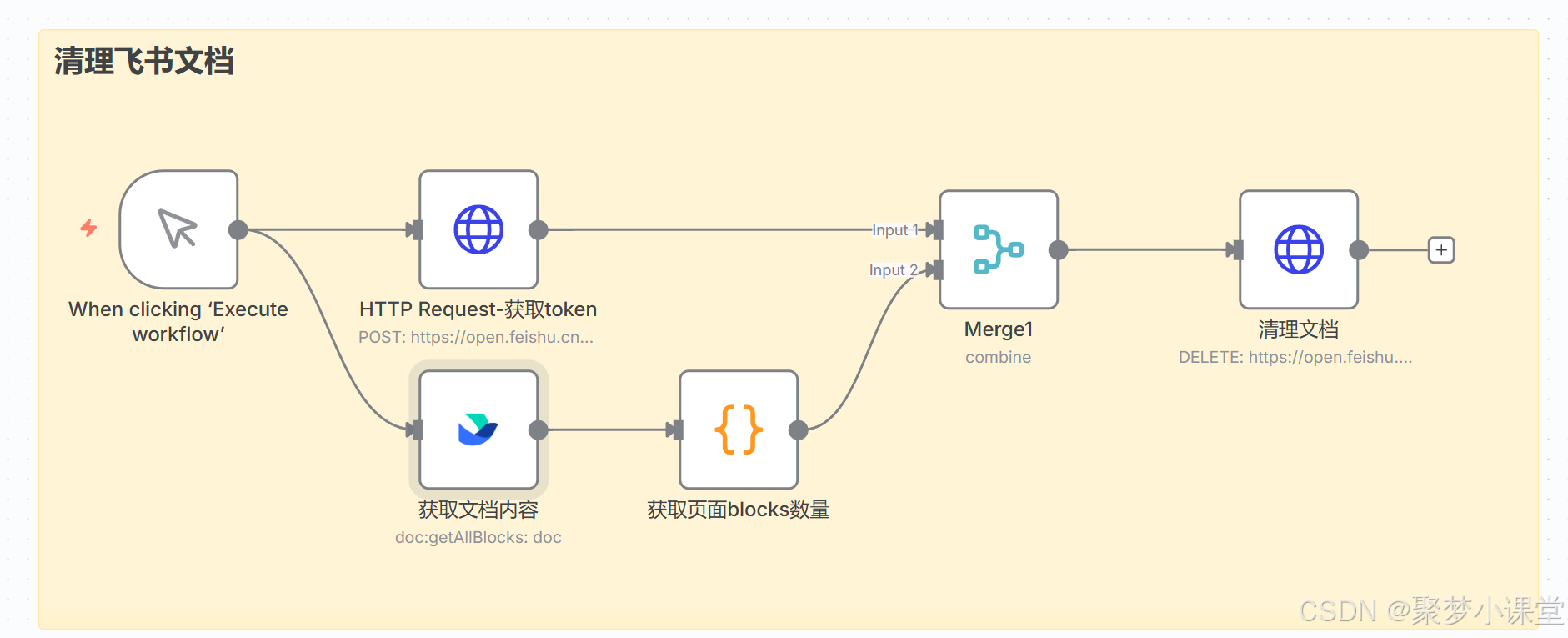
第四步,按照这样的方式先把框架搭建起来(地球图标的是http request节点,大括号图表的是code节点,飞书的就是飞书节点咯):
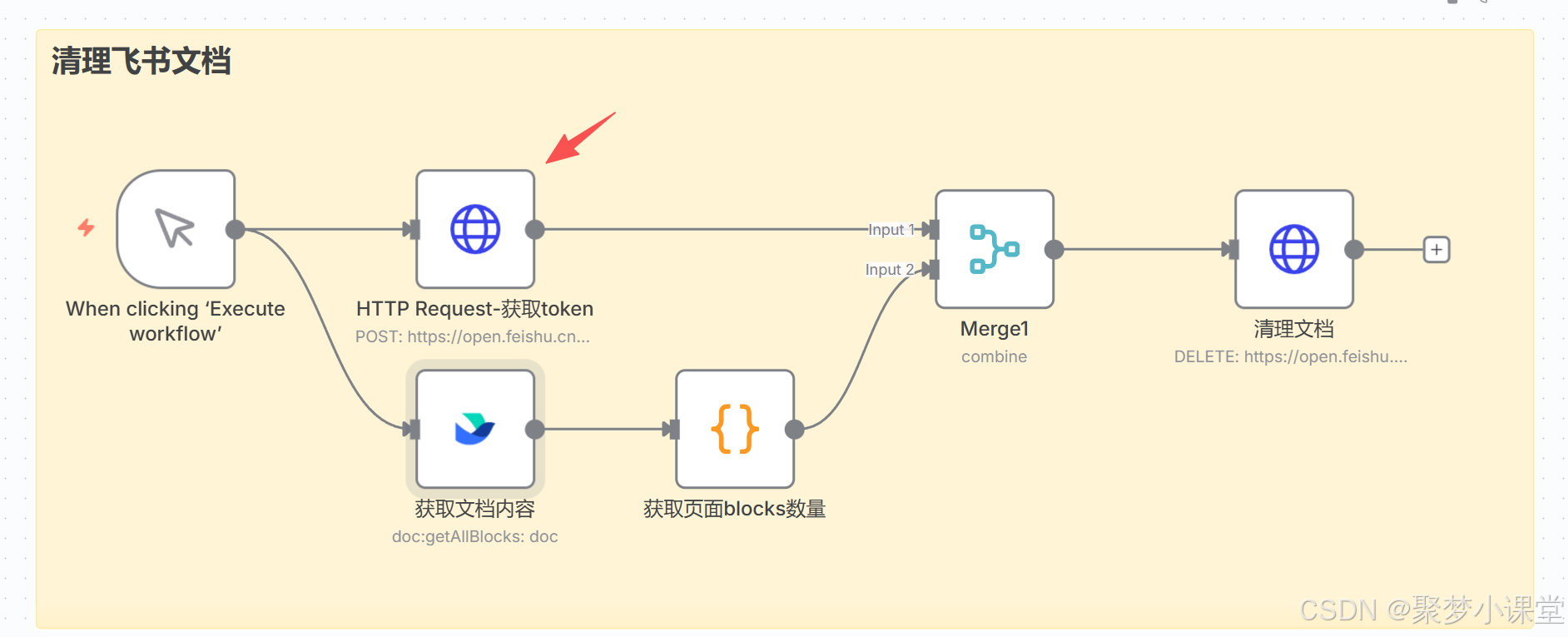
第五步,先配置获取token节点,因为飞书文档的token每隔一段时间就会变更,所以你需要配置一个httprequest节点来动态的获取;
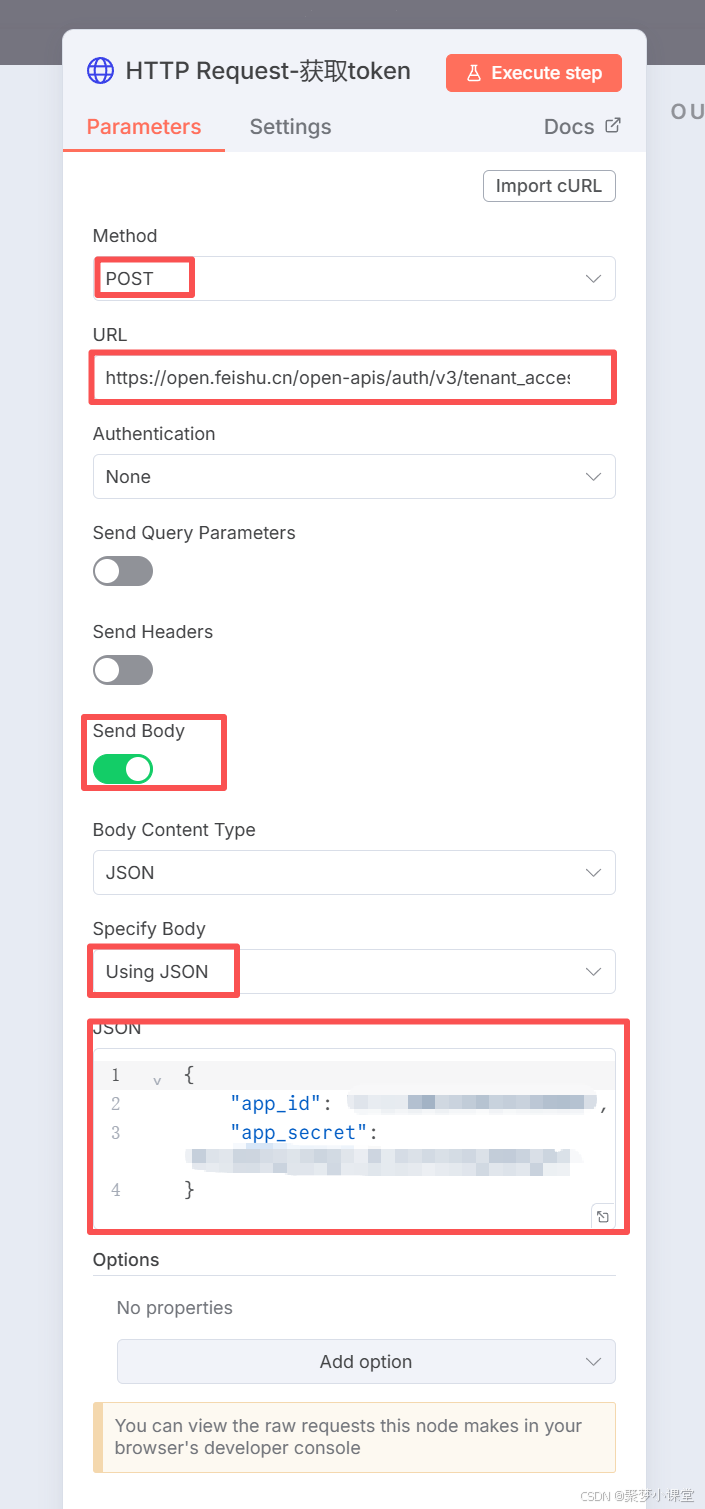
URL是:https://open.feishu.cn/open-apis/auth/v3/tenant_access_token/internal
这个是固定的,飞书开放平台里边写的,按照这个配置就可以;
Body要填写你的app_id和app_secret,内容是:
{
"app_id": "xxx",
"app_secret": "xxx"
}
在你的飞书开放平台的后台能查到这个信息:

第六步,配置获取内容节点:
按照我的方案配置即可:
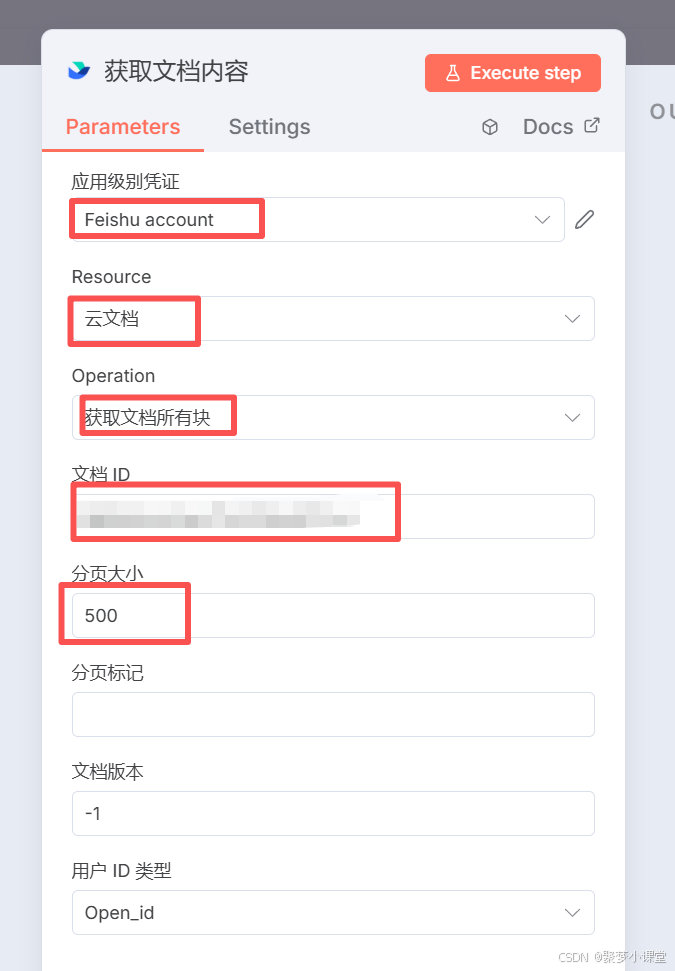
说明,第一个凭证官方有详细的说明,简单配置下即可;
resource选择云文档;
operation选择获取文档所有块;
文档id在你的文档的链接地址后边:
分页大小:这里要删掉所有内容,所以配置的大了点;
第七步,配置获取block数量的节点
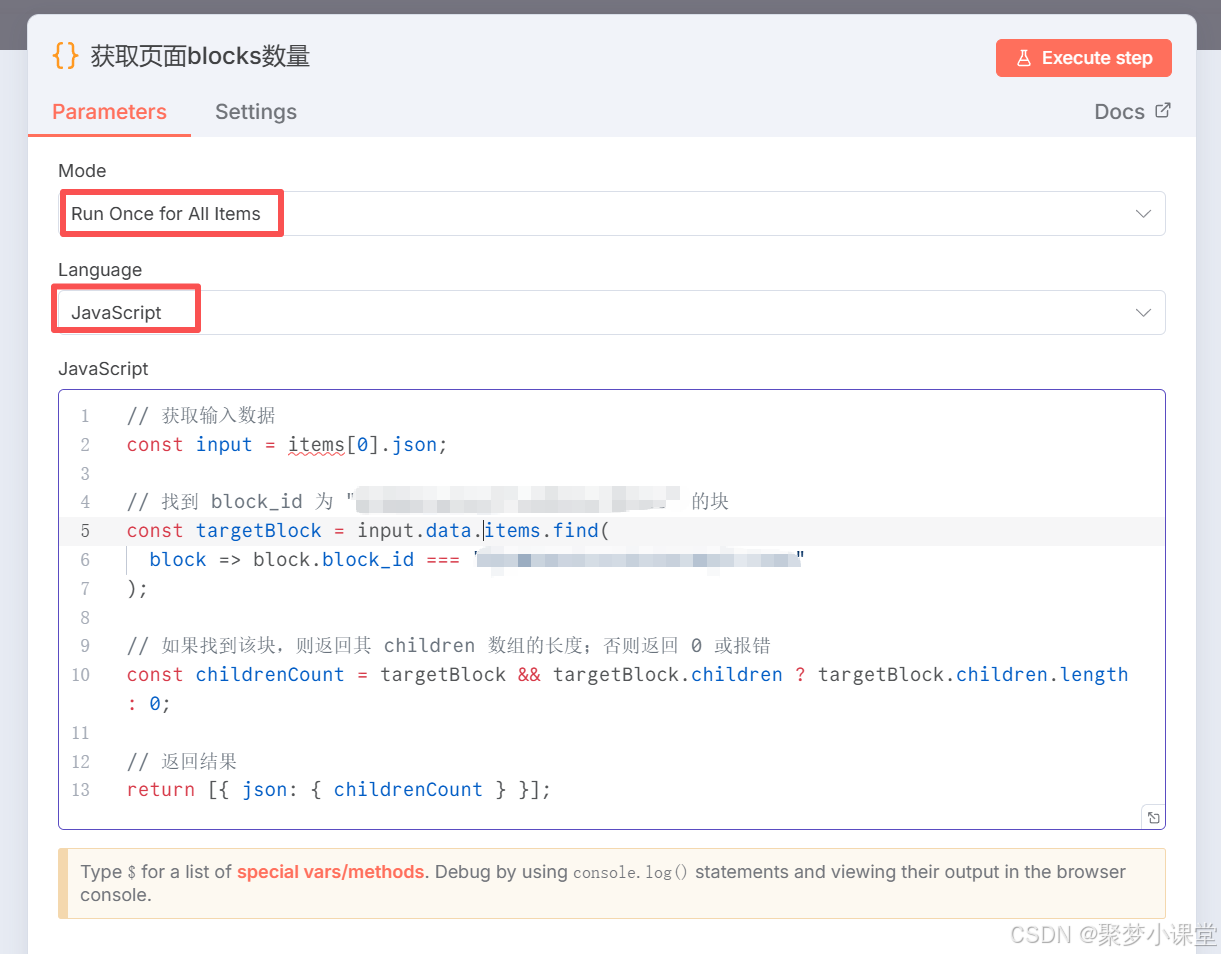
打码的部分写上一步获取的文档id即可,因为要全部清除,而所有的文档内blocks其实挂在文档下边,所以找到这个根节点然后全清掉即可。
代码内容:
// 获取输入数据
const input = items0.json;
// 找到 block_id 为 "xxx" 的块
const targetBlock = input.data.items.find(
block => block.block_id === "根节点-需要修改"
);
// 如果找到该块,则返回其 children 数组的长度;否则返回 0 或报错
const childrenCount = targetBlock && targetBlock.children ? targetBlock.children.length : 0;
// 返回结果
return { json: { childrenCount } };
第八步,merge下两条分支。
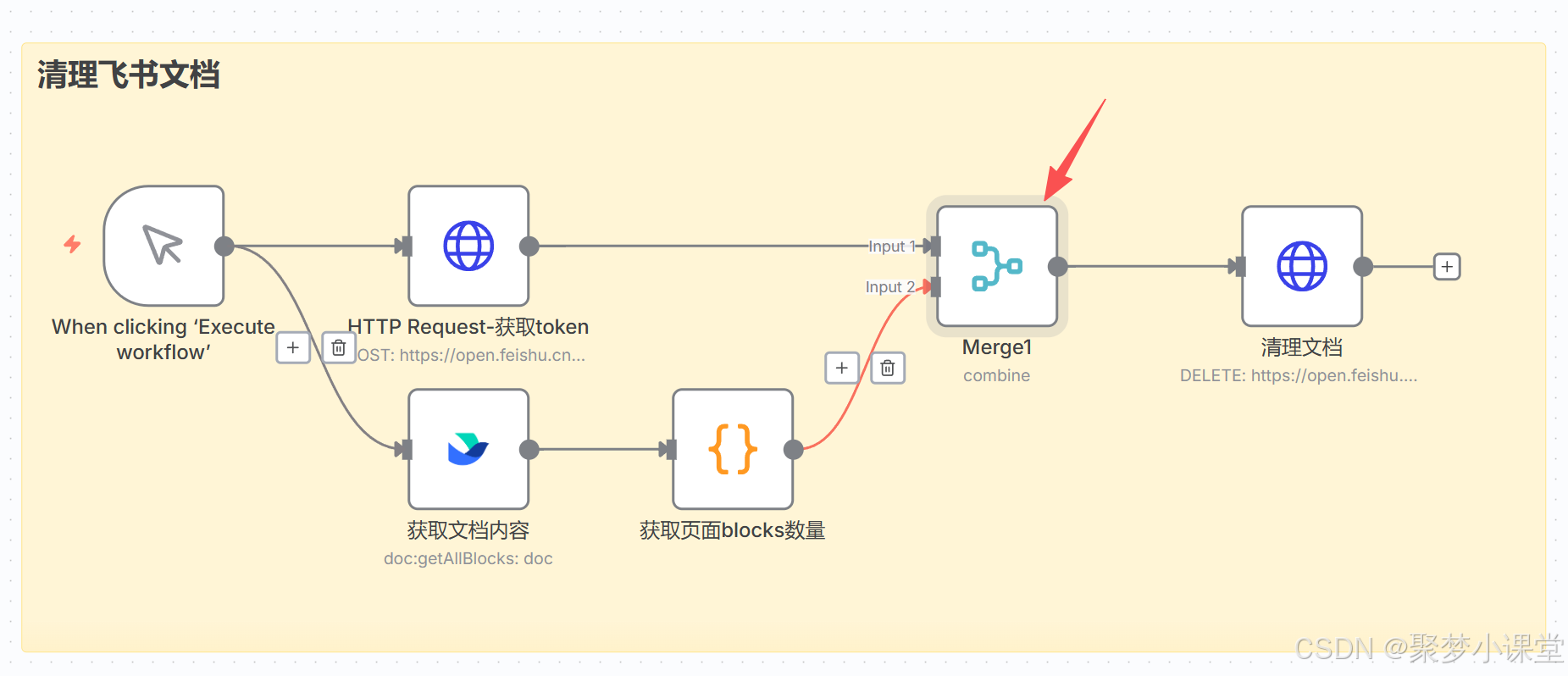
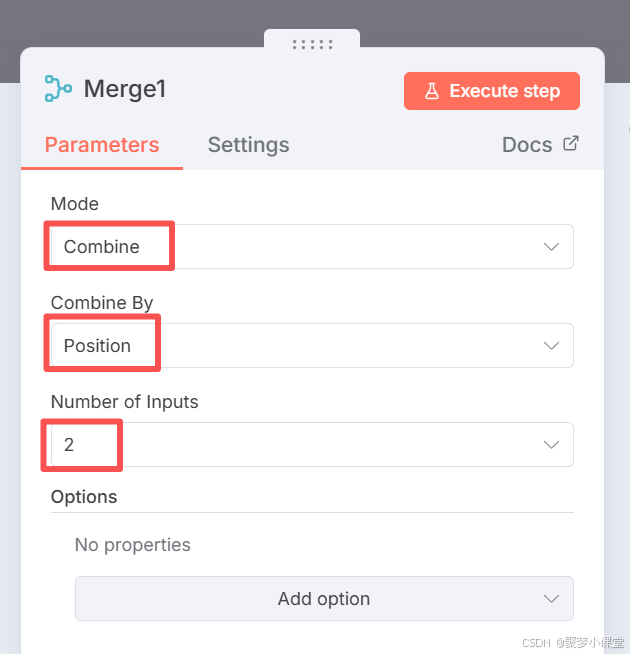
用于把两个分支的内容拼合为一条数据然后供后续实际删除的节点来使用。
第九步,真正执行清理文档的操作: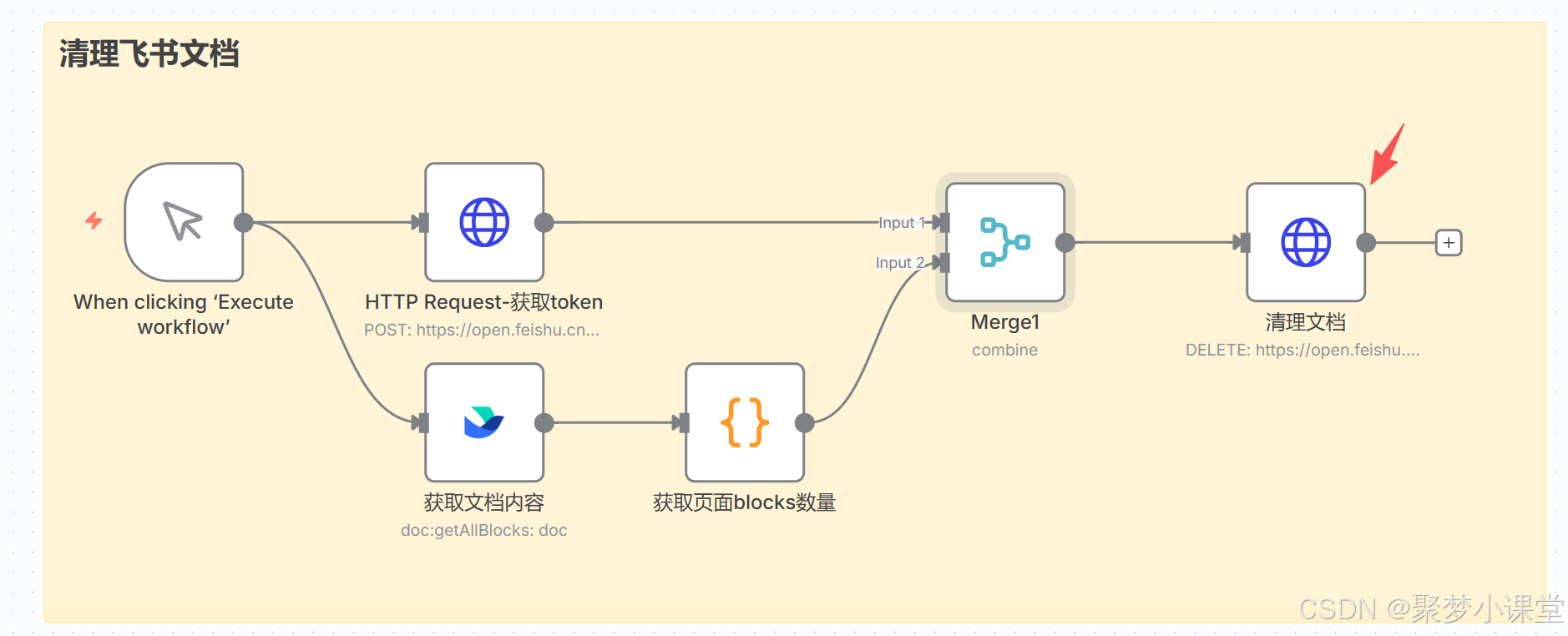
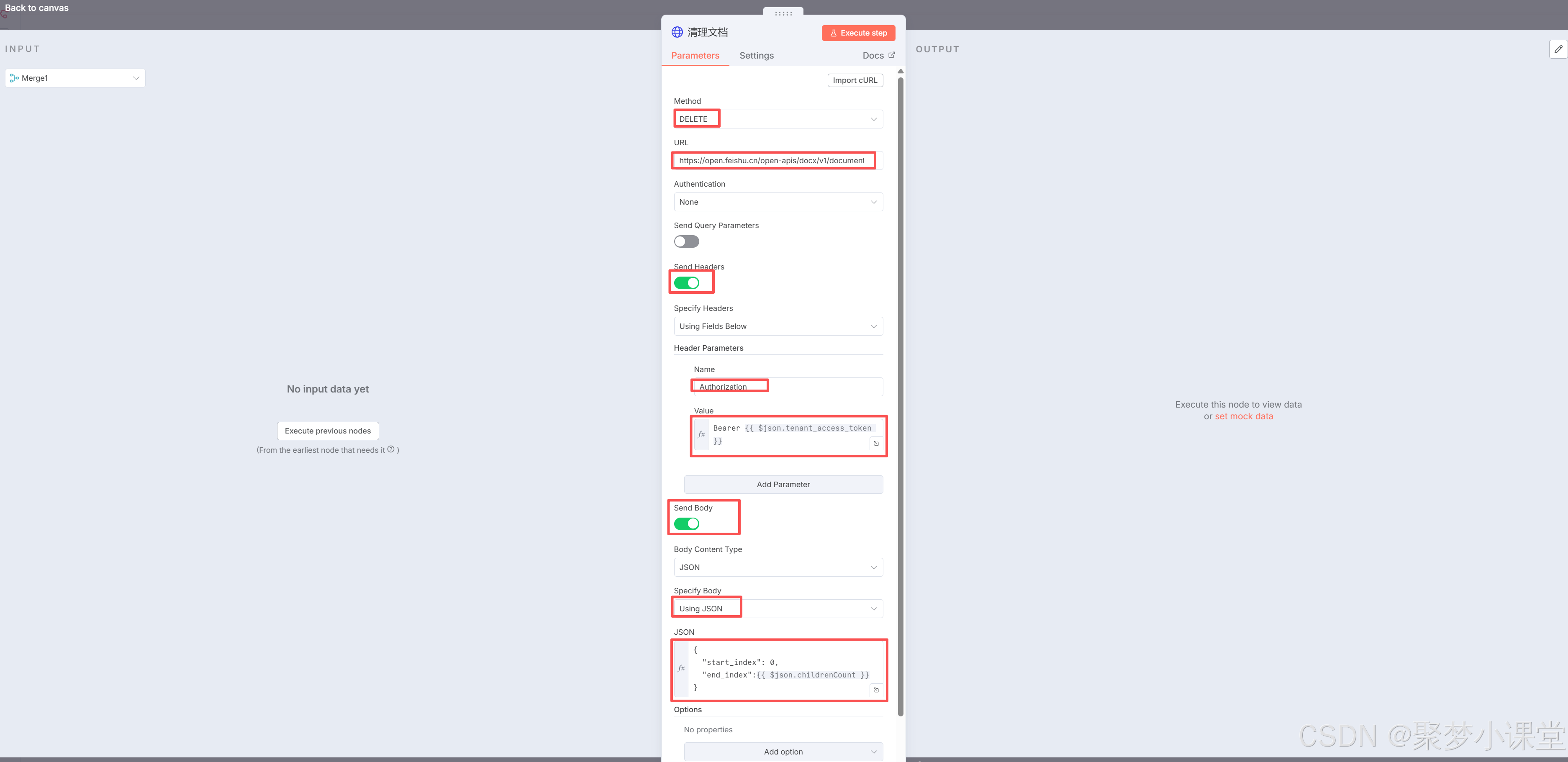
从上到下的参数:
URL(记得替换两个参数为你的实际页面id地址):https://open.feishu.cn/open-apis/docx/v1/documents/你文档的id/blocks/你文档的id/children/batch_delete
授权的value:
Bearer {{ $json.tenant_access_token }}
请求体的json:
{
"start_index": 0,
"end_index":{{ $json.childrenCount }}
}
意思就是从第0个block到全部的block都删掉。
以上配置完应该就可以正常运行了。
如果对你有帮助,记得帮忙点个赞咯~