大家好,我是java1234_小锋老师,最近写了一套基于Python深度学习的车辆车牌识别系统(PyTorch2卷积神经网络CNN+OpenCV4实现)视频教程,持续更新中,计划月底更新完,感谢支持。
视频在线地址:
https://www.bilibili.com/video/BV1BdUnBLE6N/
课程简介:
本课程采用主流的Python技术栈实现,分两套系统讲解,一套是专门讲PyTorch2卷积神经网络CNN训练模型,识别车牌,当然实现过程中还用到OpenCV实现图像格式转换,裁剪,大小缩放等。另外一套是基于前面Django+Vue通用权限系统基础上,加了车辆识别业务模型,Mysql8数据库,Django后端,Vue前端,后端集成训练好的模型,实现车牌识别。
基于Python深度学习的车辆车牌识别系统(PyTorch2卷积神经网络CNN+OpenCV4实现)视频教程 - 通过训练好的模型识别车牌
前面我们把模型已经训练好,以及进行了图像预处理,车牌矩阵定位,裁剪和矫正车牌,以及切割车牌字符。下面我们来进行车牌识别。
# 识别车牌字符
def cnn_recongnize_char(img_list, model_path):
model = torch.load(model_path, weights_only=False) # 加载模型
text_list = [] # 识别结果
tf = transforms.ToTensor()
for img in img_list:
"""
这段代码的功能是:
将图像数据转换为模型输入格式。具体包括:
1. `np.array(img)` - 将PIL图像转换为numpy数组
2. `tf()` - 使用ToTensor变换将numpy数组转换为PyTorch张量
3. `.unsqueeze(0)` - 在第0维添加批次维度,使单张图像变为批次大小为1的张量,符合模型输入要求
"""
input = tf(np.array(img)).unsqueeze(0)
with torch.no_grad():
output = model(input)
_, predicted = torch.topk(output, 1)
text_list.append(char_table[predicted])
return text_list
if __name__ == '__main__':
car_plate_w, car_plate_h = 136, 36 # 车牌宽高
char_w, char_h = 20, 20 # 字符宽高
char_model_path = "char.pth"
test_images_root = 'images/test/' # 测试图片路径
files = list_all_files(test_images_root)
files.sort()
for file in files:
img = cv2.imread(file) # 读取图片
pred_img = pre_process(img) # 预处理图片
car_plate_list = locate_carPlate(img, pred_img) # 车牌定位
if len(car_plate_list) == 0:
continue
else:
car_plate = car_plate_list[0] # 获取车牌
char_img_list = extract_char(car_plate) # 获取车牌字符
for id in range(len(char_img_list)):
img_name = 'char/char-' + str(id) + '.jpg'
cv2.imwrite(img_name, char_img_list[id])
text = cnn_recongnize_char(char_img_list, char_model_path)
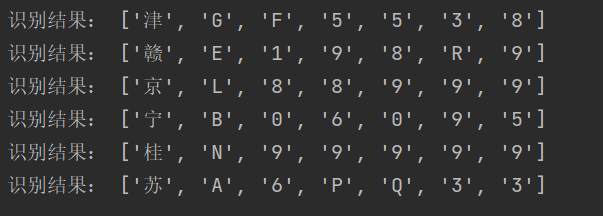
print('识别结果:', text)运行结果: