订单优化
一、状态机
需求说明:
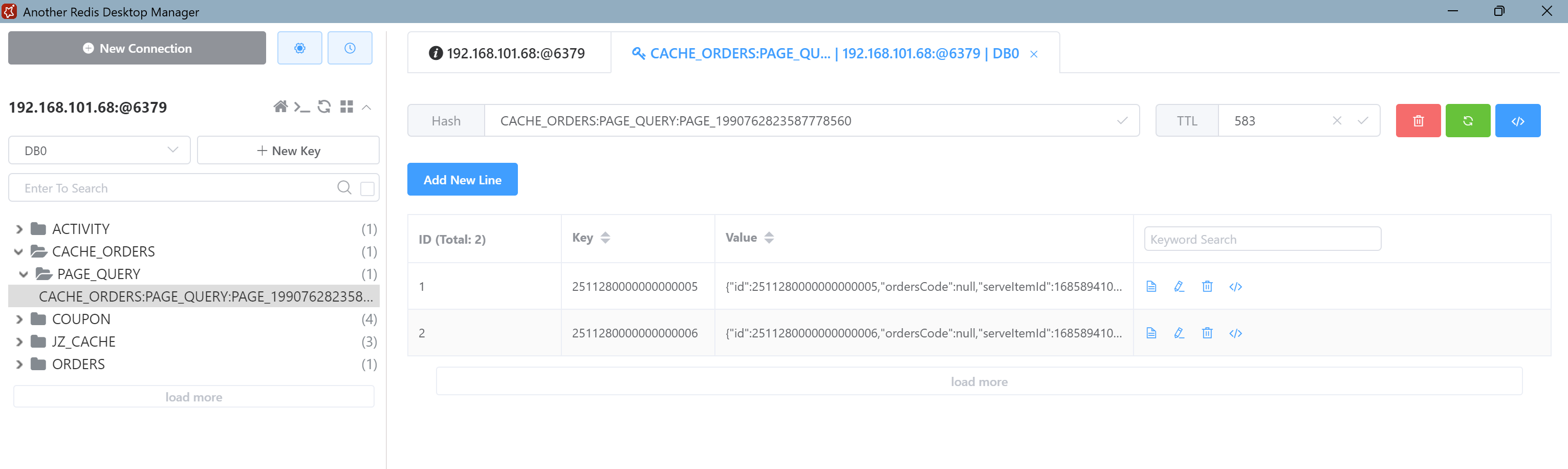
在订单模块中订单共设计了7种状态,如下图
订单会在多个状态间进行转换,这就需要我们开发人员都去记忆这些转换关系,这是非常麻烦的
java
if(订单状态 == 待支付){
//如果用户支付成功,执行此场景下的业务逻辑,更新订单状态为派单中
update(id,派单中)
)
if(订单状态 == 待支付){
//如果用户取消支付,执行此场景下的业务逻辑。更新订单状态为已取消
update(id,已取消)
)
...针对这种情况,我们可以引入状态机对订单状态进行统一管理,我们可以认为状态机就是一个封装好的组件
调用它的时候,只需要告诉它订单id和要执行的事件,它内部就可以完成对应的所有操作,类似于下面代码
java
//调用状态机执行支付成功事件
orderStateMachine.changeStatus(订单id,支付成功事件);
//调用状态机执行支付取消事件
orderStateMachine.changeStatus(订单id,支付取消事件);因此使用状态机的好处就是:
-
易于理解:可以使业务模型清晰,开发人员可以更好地理解状态转换流程
-
方便调用:可以使调用者以不关注细节的角度去使用其暴露的接口方法
当然使用状态机也是有缺点的:
-
代码复杂:状态机需要较多接口和实现类,因此代码复杂度会高一点
-
运行效率:状态机需要经常创建状态机实例,运行效率会稍微差一点
状态机是一种抽象的数学模型,用于描述事物在不同状态之间转移和行为变化的过程
它的核心是将状态之间的变更定义为事件,然后将事件暴露出来,通过执行状态变更事件去更改状态
理解状态机设计模式需要理解四个要素:现态、次态、事件、动作
-
现态:是指当前所处的状态,比如说下图的待支付
-
次态:条件满足后要转变为的新状态,比如说下图的派单中
-
事件:状态变更的触发条件,比如说下图的用户支付成功事件
-
动作:事件发生时执行的操作,将订单状态由待支付更改为派单中,它不是必需的
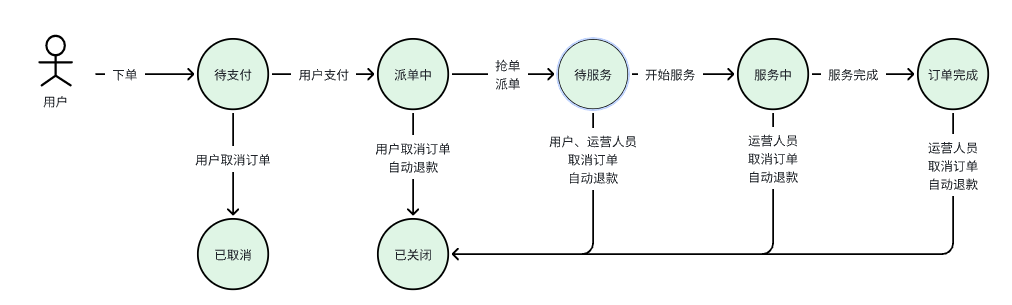
我们拿待支付状态到派单中状态举例
接下来我们就使用状态机来优化订单的状态转化代码
编写订单状态机
实现状态机步骤比较复杂,核心步骤如下:
-
引入通用状态机组件,内部定义了一些类和接口,订单状态机要去继承或实现这些类和接口
-
创建状态类,定义订单所有的状态,里面就包含所有现态和次态
-
创建事件类,定义触发订单状态改变的事件,它关联现态和次态
-
创建快照类,用来记录事件发生时,订单变化瞬间的状态及相关信息
-
创建动作类,用来执行订单状态发生改变需要触发的操作
-
创建状态机类,定义状态机的名称和初始状态
1)添加依赖
在jzo2o-orders-base工程的pom.xml中添加状态机组件的依赖
XML
<dependency>
<groupId>com.jzo2o</groupId>
<artifactId>jzo2o-statemachine</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>2)创建订单状态类
定义订单所有的状态,实现接口StatusDefine
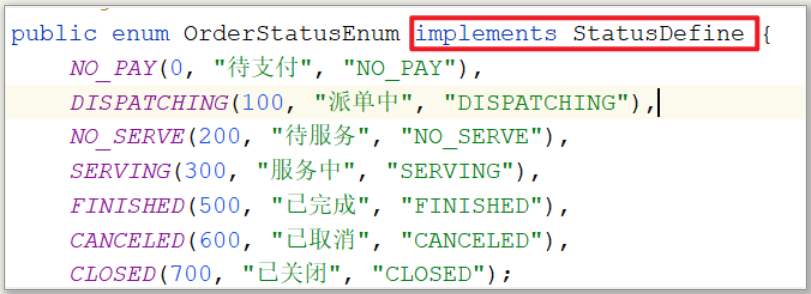
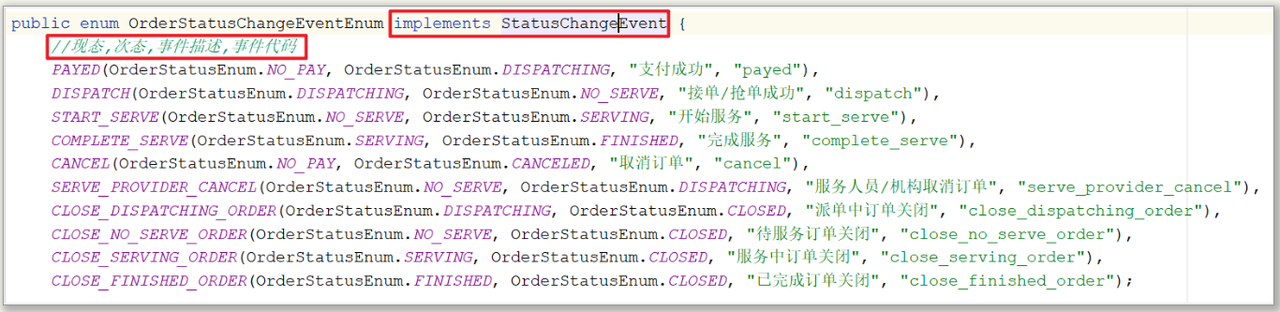
3)创建订单事件类
定义触发订单状态改变的事件,它关联现态和次态,实现接口StatusChangeEvent
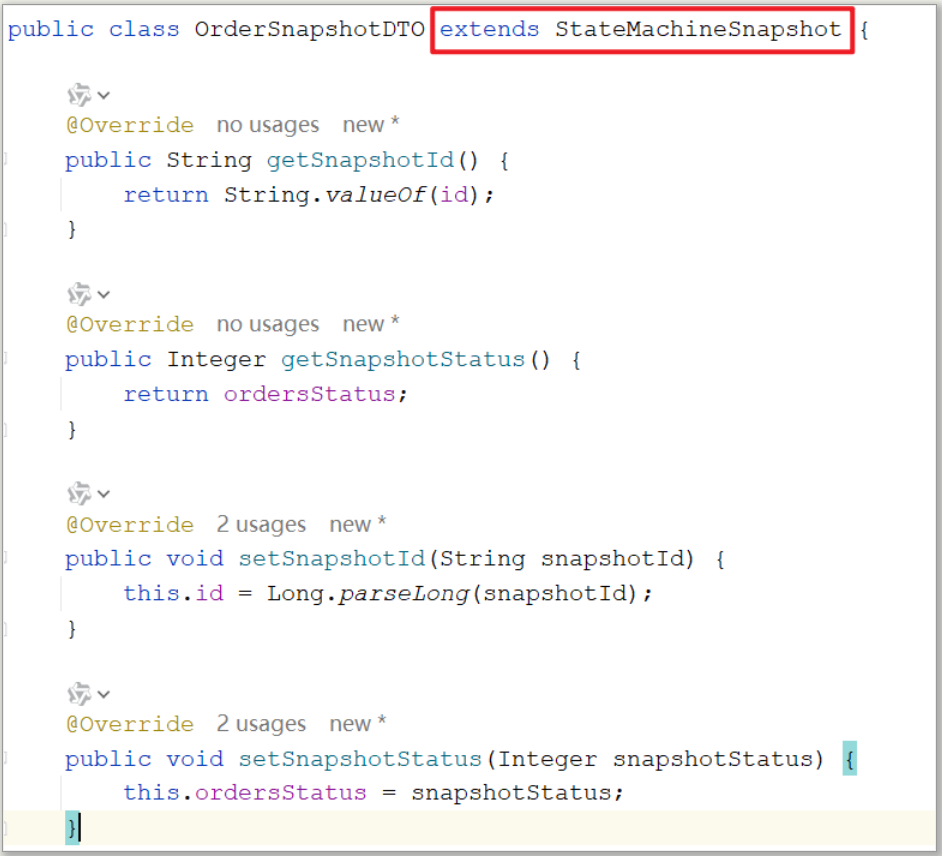
创建订单快照类
用来记录事件发生时,订单变化瞬间的状态及相关信息,继承StateMachineSnapshot,例如:
-
001号订单创建成功,此时会记录它的快照信息(订单号、下单人、订单详细信息、订单状态等)
-
001号订单支付成功,此时也会记录它的快照信息
订单快照可以追溯订单的历史变化信息,只要状态发生变化便会记录快照
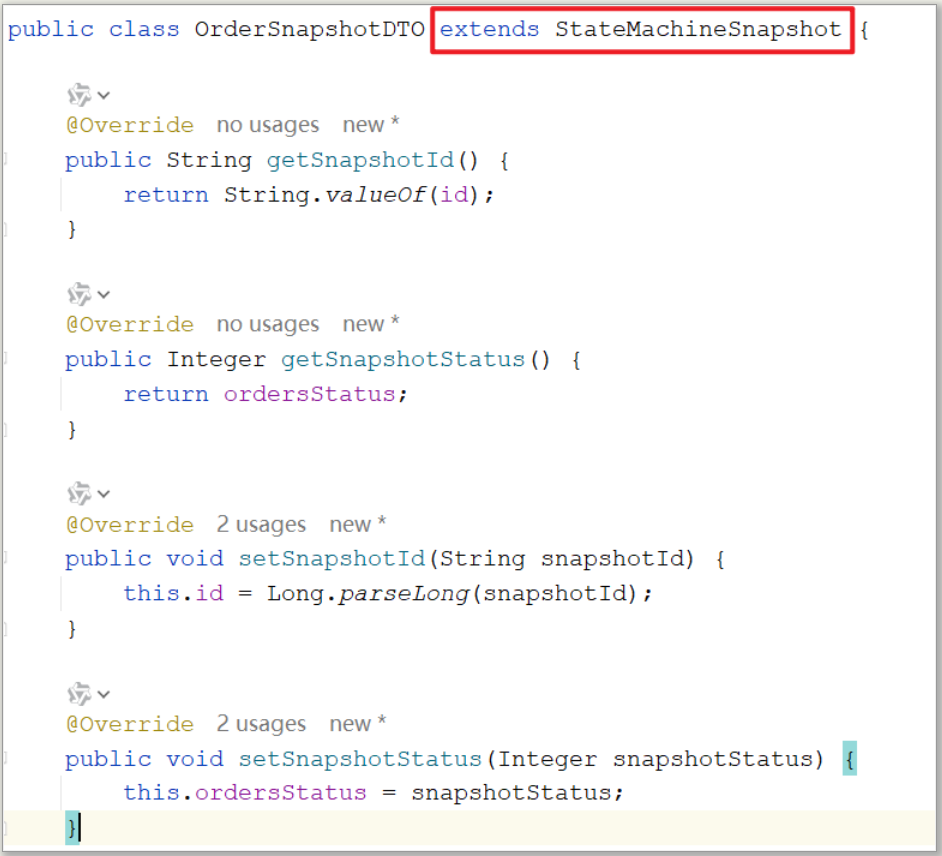
4)创建订单快照类
用来记录事件发生时,订单变化瞬间的状态及相关信息,继承StateMachineSnapshot,例如:
-
001号订单创建成功,此时会记录它的快照信息(订单号、下单人、订单详细信息、订单状态等)
-
001号订单支付成功,此时也会记录它的快照信息
订单快照可以追溯订单的历史变化信息,只要状态发生变化便会记录快照
5)创建订单动作类
用来执行订单状态发生改变需要触发的操作,实现StatusChangeHandler
java
package com.jzo2o.orders.base.handler;
import com.jzo2o.orders.base.model.dto.OrderSnapshotDTO;
import com.jzo2o.orders.base.service.IOrdersCommonService;
import com.jzo2o.statemachine.core.StatusChangeEvent;
import com.jzo2o.statemachine.core.StatusChangeHandler;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
//订单支付事件逻辑处理器
@Slf4j
@Component("order_payed")//接口实现类的bean名称规则为:状态机名称_事件名称
public class OrderPayedHandler implements StatusChangeHandler<OrderSnapshotDTO> {
@Autowired
private IOrdersCommonService ordersService;
/**
* 订单支付处理逻辑
*
* @param bizId 业务id
* @param bizSnapshot 快照
*/
@Override
public void handler(String bizId, StatusChangeEvent statusChangeEventEnum, OrderSnapshotDTO bizSnapshot) {
log.info("支付成功事件处理逻辑开始,订单号:{}", bizId);
}
}6)创建订单状态机类
定义状态机的名称和初始状态,继承AbstractStateMachine
java
package com.jzo2o.orders.base.config;
import com.jzo2o.orders.base.enums.OrderStatusEnum;
import com.jzo2o.orders.base.model.dto.OrderSnapshotDTO;
import com.jzo2o.statemachine.AbstractStateMachine;
import com.jzo2o.statemachine.persist.StateMachinePersister;
import com.jzo2o.statemachine.snapshot.BizSnapshotService;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
/**
* 订单状态机
*/
@Component
public class OrderStateMachine extends AbstractStateMachine<OrderSnapshotDTO> {
public OrderStateMachine(StateMachinePersister stateMachinePersister, BizSnapshotService bizSnapshotService, RedisTemplate redisTemplate) {
super(stateMachinePersister, bizSnapshotService, redisTemplate);
}
/**
* 设置状态机名称
*
* @return 状态机名称
*/
@Override
protected String getName() {
return "order";
}
/**
* 设置状态机初始状态
*
* @return 状态机初始状态
*/
@Override
protected OrderStatusEnum getInitState() {
return OrderStatusEnum.NO_PAY;
}
/**
* 后置处理器 订单创建之后要做的操作,暂时啥也不做
*
* @param orderSnapshotDTO 订单快照
*/
@Override
protected void postProcessor(OrderSnapshotDTO orderSnapshotDTO) {
}
}AbstractStateMachine状态机抽象类是状态机的核心类,是具体的状态机要继承的抽象类

在整个状态机运转过程中需要两张数据表来记录数据,分别是
状态机表:每个订单在此表中有一条数据,里面存储订单的最新状态
状态机快照表:每个订单在此表有多条记录,里面存储的是订单到现在为止历经的状态

测试订单状态机
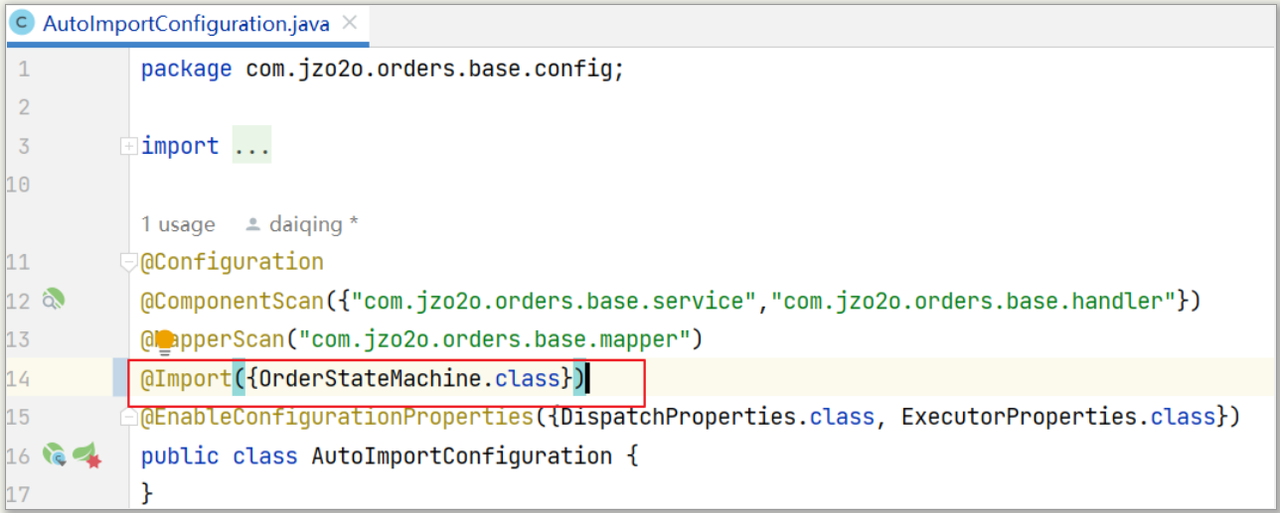
1)加载订单状态机
首先,在jzo2o-orders-base工程的AutoImportConfiguration类中配置导入订单状态机
2)测试启动状态机
在jzo2o-orders-manager下编写测试代码
调用OrderStateMachine的start()方法启动一个订单的状态机,它会设置订单的初始状态
java
package com.jzo2o.orders.manager.service;
@SpringBootTest
@Slf4j
public class OrderStateMachineTest {
@Resource
private OrderStateMachine orderStateMachine;
@Test
public void test_start() {
//启动状态机,指定订单id,设置现态
String start = orderStateMachine.start("888");
log.info("返回初始状态:{}", start);
}
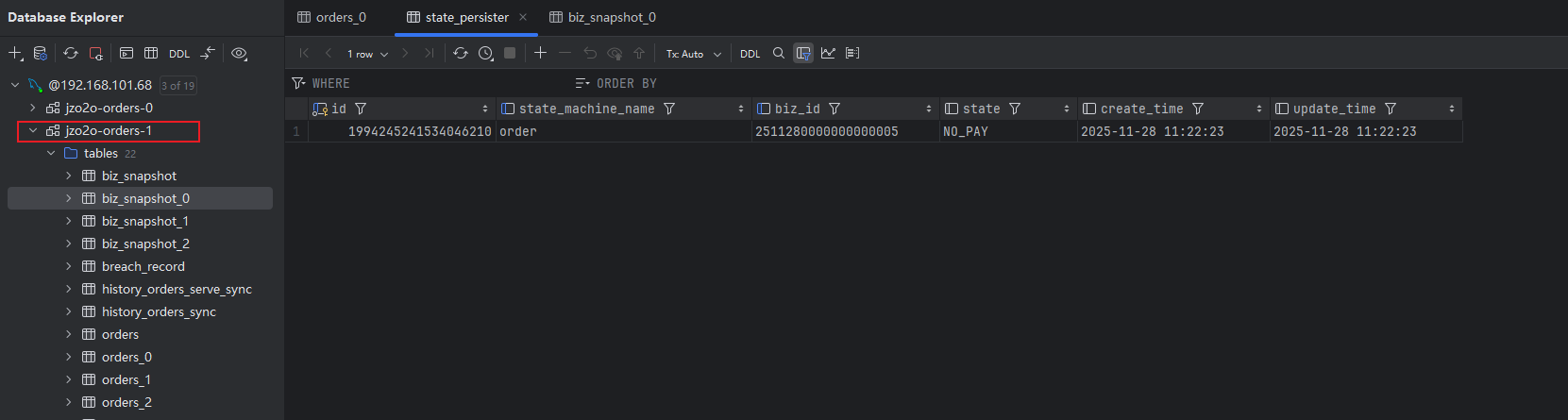
}执行测试方法,对888订单启动状态机管理,启动后888号订单的状态为NO_PAY待支付状态
观察state_persister表有一条888号订单的状态持久化记录

观察biz_snapshot表有一条888号订单的快照信息,一条订单在biz_snapshot表对应多个条记录,每次订单状态变更都会产生一个快照

注意:如果报错:java.lang.IllegalStateException: 已存在状态,不可初始化 ,说明888号订单的状态机已启动,可以更改101测试其它订单状态机启动
3)测试状态变更方法
执行测试方法后888订单的状态由NO_PAY(待支付)变更为DISPATCHING(派单中)。
java
@Test
public void test_changeStatus() {
//状态变更
orderStateMachine.changeStatus("888", OrderStatusChangeEventEnum.PAYED);
}执行此方法,预期结果:
state_persister表中888订单的状态变更为DISPATCHING
biz_snapshot表多了一条888号订单的快照信息
观察输出日志,如果输出"支付事件处理逻辑开始,订单号..."表示此处理器已正常执行
源码阅读:
com.jzo2o.statemachine.AbstractStateMachine:
启动状态机:
首先判断该订单是否启动状态,如果没有启动则向状态机表插入记录,否则抛出异常"已存在状态,不可初始化".
java
/**
* 状态机初始化,不保存快照
* @param bizId 业务id
* @return 初始化状态代码
*/
public String start(String bizId) {
return start(null, bizId, initState, null);
}
/**
* 启动状态机,并设置当前状态和保存业务快照,快照分库分表
* @param dbShardId 分库键
* @param bizId 业务id
* @param statusDefine 当前状态
* @param bizSnapshot 快照
* @return 当前状态代码
*/
public String start(Long dbShardId, String bizId, StatusDefine statusDefine, T bizSnapshot) {
//1.初始化状态机状态
String currentState = stateMachinePersister.getCurrentState(name, bizId);
if (ObjectUtil.isEmpty(currentState)) {
stateMachinePersister.init(name, bizId, statusDefine);
} else {
throw new IllegalStateException("已存在状态,不可初始化");
}
//2.保存业务快照
if (bizSnapshot == null) {
bizSnapshot = ReflectUtil.newInstance(getSnapshotClass());
}
//设置快照id
bizSnapshot.setSnapshotId(bizId);
//设置快照状态
bizSnapshot.setSnapshotStatus(statusDefine.getStatus());
//快照转json
String bizSnapshotString = JSONUtil.toJsonStr(bizSnapshot);
if (ObjectUtil.isNotEmpty(bizSnapshot)) {
bizSnapshotService.save(dbShardId, name, bizId, statusDefine, bizSnapshotString);
}
//执行后处理方法
postProcessor(bizSnapshot);
return statusDefine.getCode();
}当状态机启动后,会通过状态机名称、状态机id查询状态机表当中是否存在该状态机:
这里就是通过状态机名称以及业务Id(这里是订单id)作为条件获取状态机并用select方法指定获取state这一字段而不是所有字段;再通过ObjectUtils.get方法获取状态并在空值时返回null防止报错
随后判断是否存在该状态机,存在则报错,不存在则执行init初始化方法(该方法由于StateMachinePersisterImpl类实现了StateMachinePersister接口,所以执行的是实现类当中的逻辑):
这里先是通过抽象接口的getCode方法在枚举类当中的实现完成状态码的获取(OrderStatusEnum枚举实现了StatusDefine接口),再创建状态机实例并把信息保存到数据库当中;
随后保存快照信息(即状态机创建、状态的变化都会登记在业务快照表当中);由于我们执行后处理方法为空,所以相当于结束

状态变更:
状态变更前会判断订单的当前状态是否和事件定义的源状态一致
如果不一致则说明当前订单的状态不能通过该事件去更新状态,此时将终止状态变更
否则将通过状态变更处理器更新订单的状态
java
/**
* 变更状态并保存快照,快照不进行分库
*
* @param bizId 业务id
* @param statusChangeEventEnum 状态变换事件
*/
public void changeStatus(String bizId, StatusChangeEvent statusChangeEventEnum) {
changeStatus(null, bizId, statusChangeEventEnum, null);
}
/**
* 变更状态并保存快照,快照分库分表
*
* @param dbShardId 分库键
* @param bizId 业务id
* @param statusChangeEventEnum 状态变换事件
* @param bizSnapshot 业务数据快照(json格式)
*/
public void changeStatus(Long dbShardId, String bizId, StatusChangeEvent statusChangeEventEnum, T bizSnapshot) {
//1.查询当前状态
String statusCode = getCurrentState(bizId);
//2.校验起止状态是否与事件匹配
if (ObjectUtil.isNotEmpty(statusChangeEventEnum.getSourceStatus()) && ObjectUtil.notEqual(statusChangeEventEnum.getSourceStatus().getCode(), statusCode)) {
throw new CommonException(HTTP_INTERNAL_ERROR, "状态机起止状态与事件不匹配");
}
//3.获取状态处理程序bean
//事件代码
String eventCode = statusChangeEventEnum.getCode();
StatusChangeHandler bean = null;
try {
bean = SpringUtil.getBean(name + "_" + eventCode, StatusChangeHandler.class);
} catch (Exception e) {
log.info("不存在'{}'StatusChangeHandler", name + "_" + eventCode);
}
if (bizSnapshot == null) {
bizSnapshot = ReflectUtil.newInstance(getSnapshotClass());
}
//设置快照id
bizSnapshot.setSnapshotId(bizId);
//设置目标状态
bizSnapshot.setSnapshotStatus(statusChangeEventEnum.getTargetStatus().getStatus());
if (ObjectUtil.isNotNull(bean)) {
//4.执行状态变更
bean.handler(bizId, statusChangeEventEnum, bizSnapshot);
}
//5.状态持久化
stateMachinePersister.persist(name, bizId, statusChangeEventEnum.getTargetStatus());
//6、存储快照
if (ObjectUtil.isNotEmpty(bizSnapshot)) {
//构建新的快照信息
bizSnapshot = buildNewSnapshot(bizId, bizSnapshot, statusChangeEventEnum.getSourceStatus());
String newBizSnapShotString = JSONUtil.toJsonStr(bizSnapshot);
bizSnapshotService.save(dbShardId, name, bizId, statusChangeEventEnum.getTargetStatus(), newBizSnapShotString);
}
//7.清理快照缓存
String key = "JZ_STATE_MACHINE:" + name + ":" + bizId;
redisTemplate.delete(key);
//执行后处理方法
postProcessor(bizSnapshot);
}更改状态之前需要从数据库查询状态机表当中状态机状态(同上面初始化时查询状态的方法),由于OrderStatusChangeEventEnum枚举实现了StatusChangeEvent接口,因此可以直接执行枚举当中获取源状态编码的方法获取状态码与数据库当中做比较(其实就是校验数据库中信息与业务层传来的信息比较(这里业务层传过来的是一个事件枚举,该枚举分原状态和目标状态,也就是说原状态要跟数据库当中状态机的状态相同),相同才能继续执行)
随后更改实体类表状态、修改状态机表状态并生成快照
项目集成:
下单时启动状态机
下单完成后,使用状态机的启动方法开启状态机对该订单状态的管理
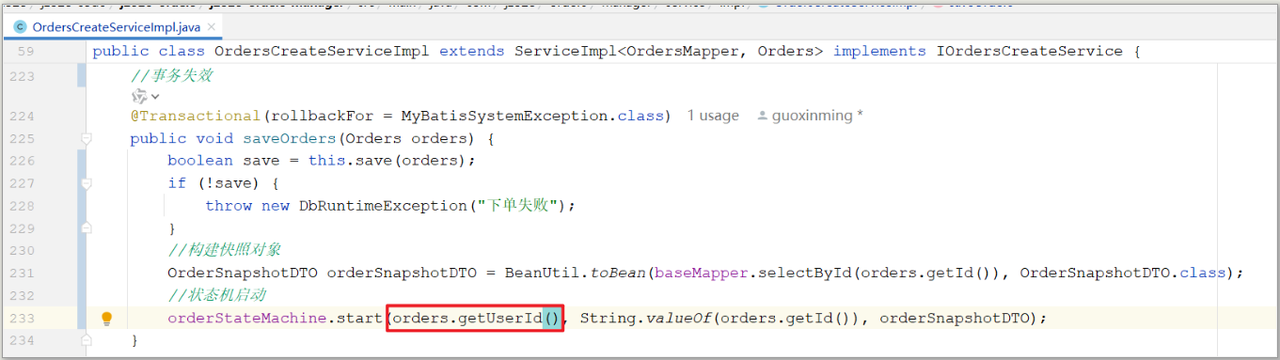
修改OrdersCreateServiceImpl类中保存订单的方法,添加启动状态机的逻辑
注意:状态机的操作方法要和业务方法处于一个事务中

在下单完成时创建订单的状态机:由于订单状态机OrderStateMachine继承了我们的AbstractStateMachine<OrderSnapshotDTO>状态机抽象类,从而继承了其内部的start方法,该方法需要订单的快照类(该类继承了StateMachineSnapshot抽象类),因此创建相关快照类并通过id从数据库当中查询订单信息拷贝到快照类当中;
随后start方法根据快照类信息(id、状态)、从getName方法获取名称生成状态机
java
@Autowired
private OrderStateMachine orderStateMachine;
//构建快照
OrderSnapshotDTO orderSnapshotDTO = BeanUtil.toBean(this.getById(orders.getId()), OrderSnapshotDTO.class);
//启动状态机
orderStateMachine.start(null,orders.getId().toString(),orderSnapshotDTO);
//构建快照
OrderSnapshotDTO orderSnapshotDTO = BeanUtil.toBean(this.getById(orders.getId()), OrderSnapshotDTO.class);
//启动状态机
orderStateMachine.start(null,orders.getId().toString(),orderSnapshotDTO);支付成功使用状态机
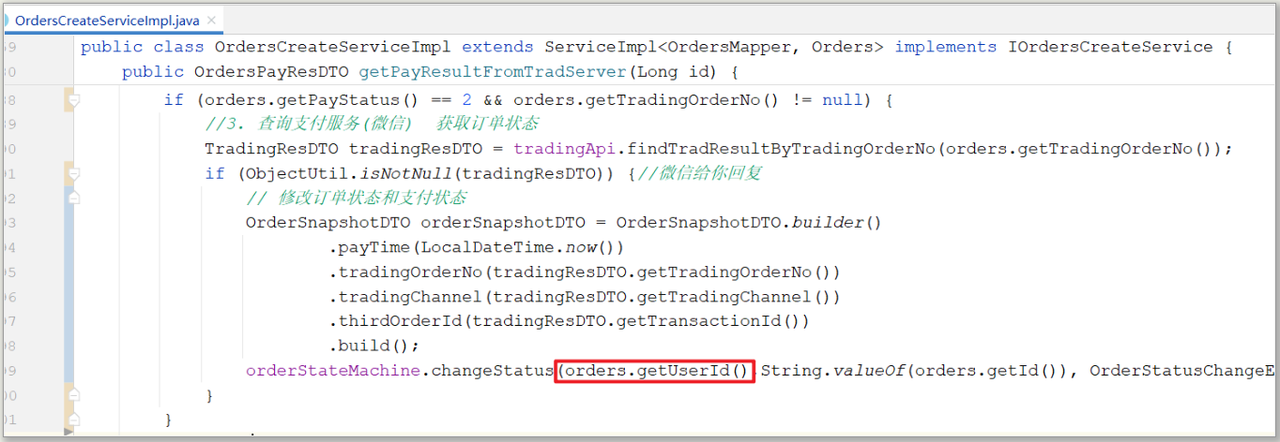
支付成功通过状态机将订单状态由待支付更新派单中
① 将订单状态变化的代码转移到 状态变更动作类
java
// 修改订单状态和支付状态
OrderUpdateStatusDTO orderUpdateStatusDTO = OrderUpdateStatusDTO.builder()
.id(Long.valueOf(bizId))
.originStatus(OrderStatusEnum.NO_PAY.getStatus())
.targetStatus(OrderStatusEnum.DISPATCHING.getStatus())
.payStatus(OrderPayStatusEnum.PAY_SUCCESS.getStatus())
.payTime(bizSnapshot.getPayTime())
.tradingOrderNo(bizSnapshot.getTradingOrderNo())
.transactionId(bizSnapshot.getThirdOrderId())
.tradingChannel(bizSnapshot.getTradingChannel())
.build();
int result = ordersService.updateStatus(orderUpdateStatusDTO);
if (result <= 0) {
throw new DbRuntimeException("支付事件处理失败");
}② 在支付成功方法中调用状态机,完成状态变更

java
if (ObjectUtil.equal(tradingState, TradingStateEnum.YJS)) {
// 修改订单状态和支付状态
OrderSnapshotDTO orderSnapshotDTO = OrderSnapshotDTO.builder()
.payTime(LocalDateTime.now())
.tradingOrderNo(tradingResDTO.getTradingOrderNo())
.tradingChannel(tradingResDTO.getTradingChannel())
.thirdOrderId(tradingResDTO.getTransactionId())
.build();
orderStateMachine.changeStatus(null, orders.getId().toString(), OrderStatusChangeEventEnum.PAYED, orderSnapshotDTO);
} else {
//todo 其它情况暂不处理,应该每种都对应一个处理器
}实际上就是将更改状态的逻辑封装到了状态机的OrderPayedHandler(继承于StatusChangeHandler<OrderSnapshotDTO>)的方法当中去,然后在业务当中调用状态机的handler方法实现状态转换
效果展示:
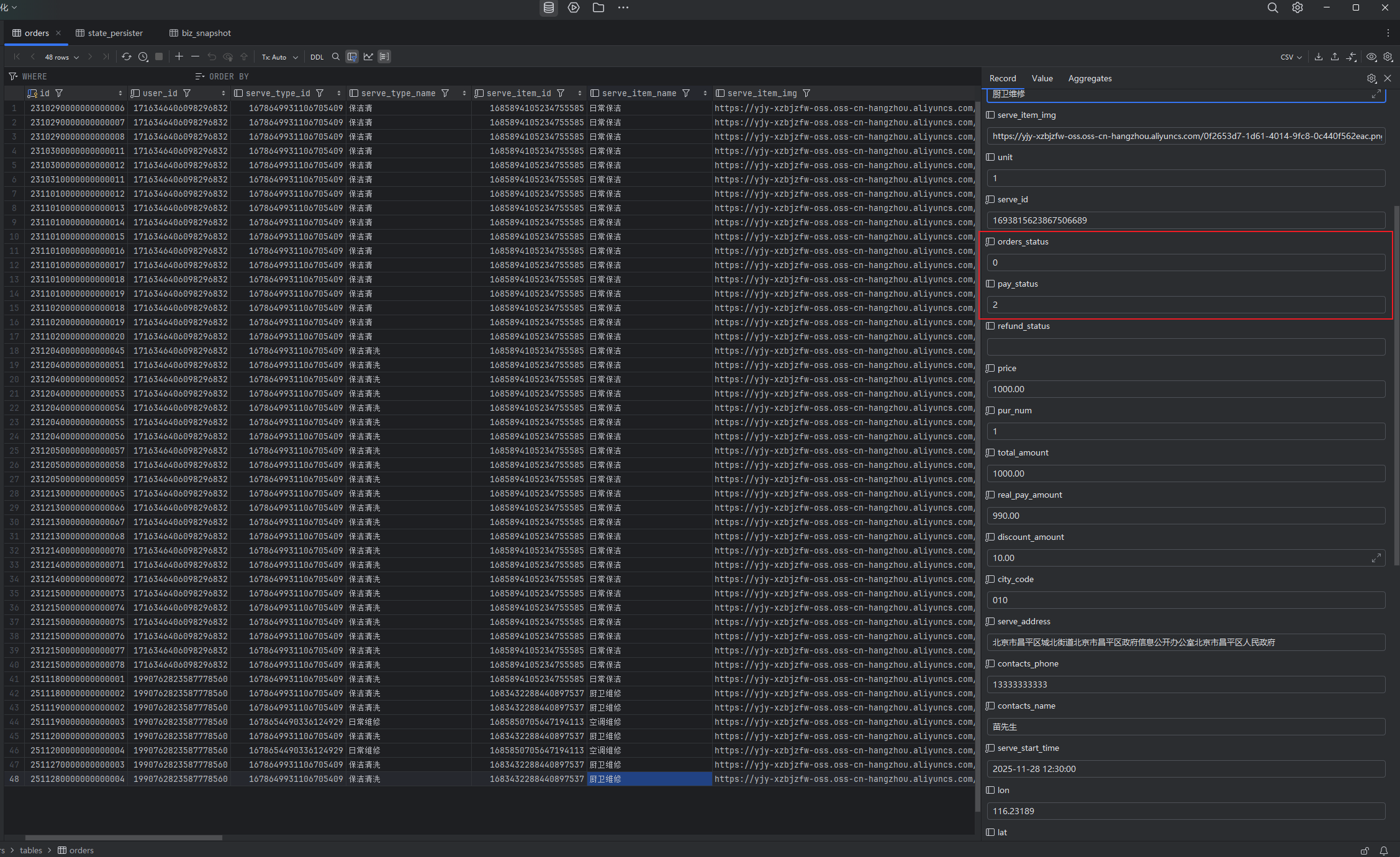

支付成功后:
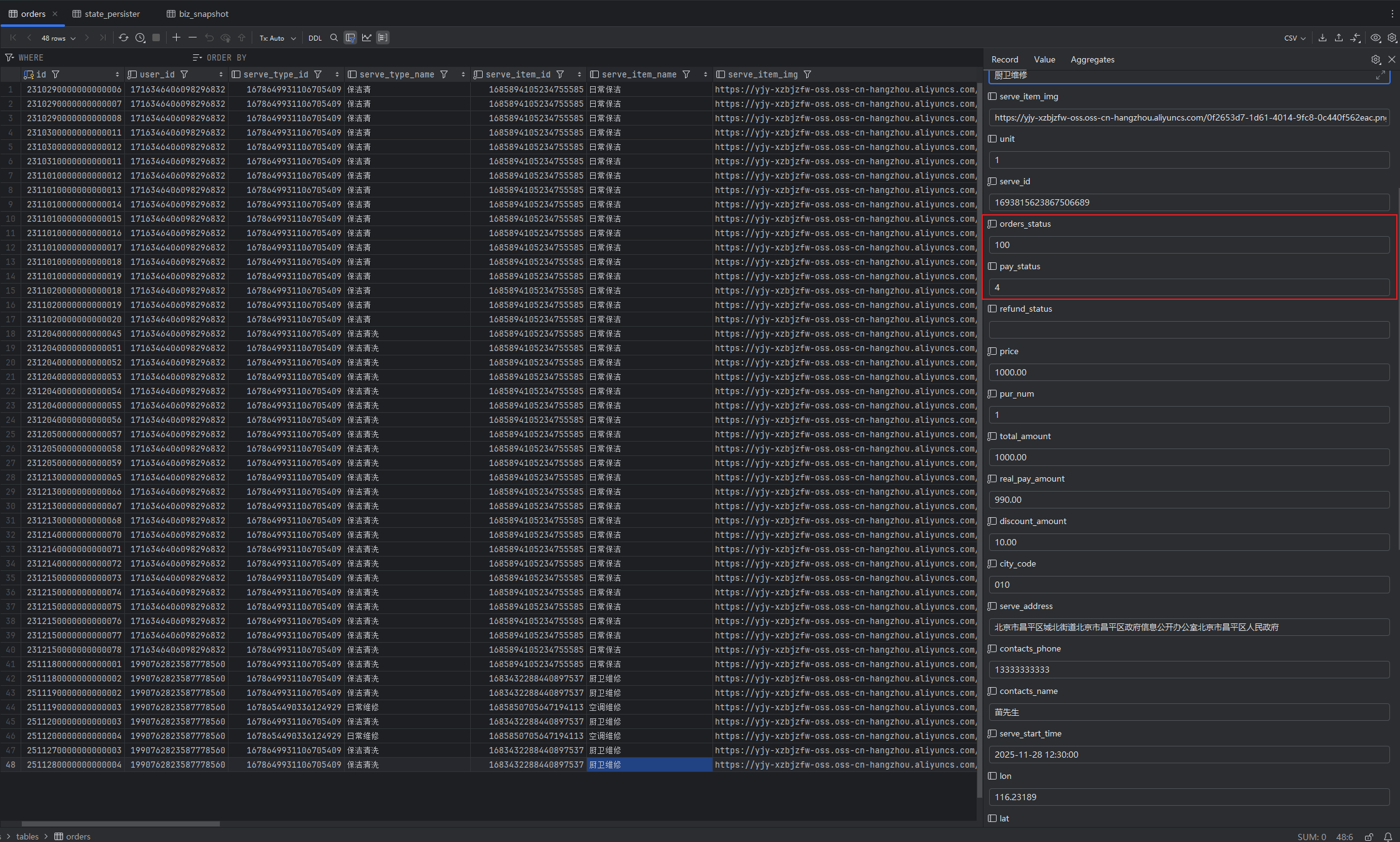

全程快照信息:

二、分库分表
随着用户不断的进行下单,MySQL订单表中的数据会不断的增多,其存储及查询性能也会随之下降
当数据量没有那么大的时候,可以通过添加索引和缓存来进行查询优化,但是数据量过大,就只能分库分表了
分库分表可以简单理解为原来一个表存储数据现在改为通过多个数据库及多个表去存储
一般认为,当MySQL单表行数超过500万行或者单表容量超过2GB时建议进行分库分表
在数据量及访问压力不是特别大的情况,首先考虑缓存、读写分离、索引技术等方案
只有上面方法已经无法支撑时,再考虑进行分库分表,因为分库分表成本比较高,带来的问题也比较多
方案介绍:
分库分表包括分库和分表两个部分,在生产中通常包括:垂直分库、水平分库、垂直分表、水平分表四种方式
我们目前在微服务环境下,一般一个微服务对应一个数据库,也就是说已经实现了分库,因此我们重点来看分表
1)垂直分表
垂直分表就是将一张表中的列分到多张表中,一般用在单张数据表列比较多的情况下按冷热字段进行拆分
例如下面的案例中,用户在浏览商品列表时,只会关注商品名称、图片、价格等
只有对某商品感兴趣时才会查看该商品的详细描述
也就是说,商品描述字段访问频次较低,且该字段存储占用空间较大,访问单个数据IO时间较长
在此情况下,就可以将访问频次较高的商品基本信息放在一张表中,而将访问频次低的描述信息单独放在一张表中
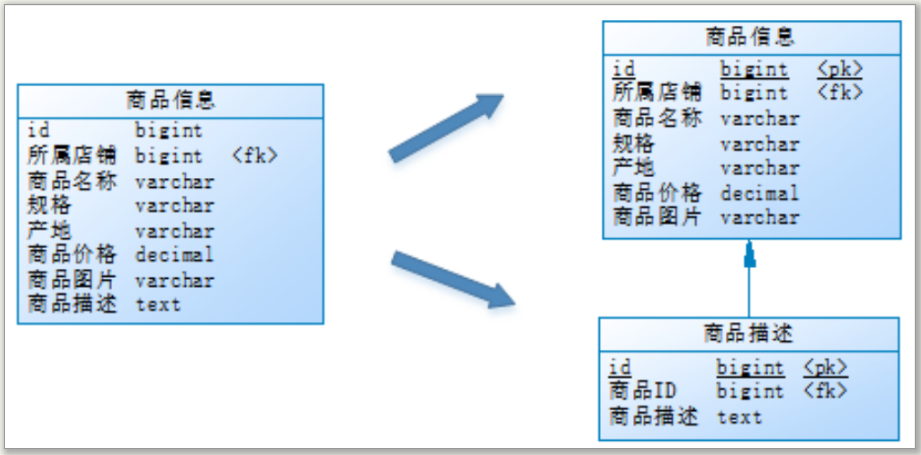
垂直分表带来的好处是:减少了每张表中的字段数量,提高了热数据的访问效率
垂直分表的一般规则是:
-
把不常用的字段单独放在一张表
-
把text、blob等大字段单独放在一张表
-
经常组合查询的列放在一张表中
2)水平分表
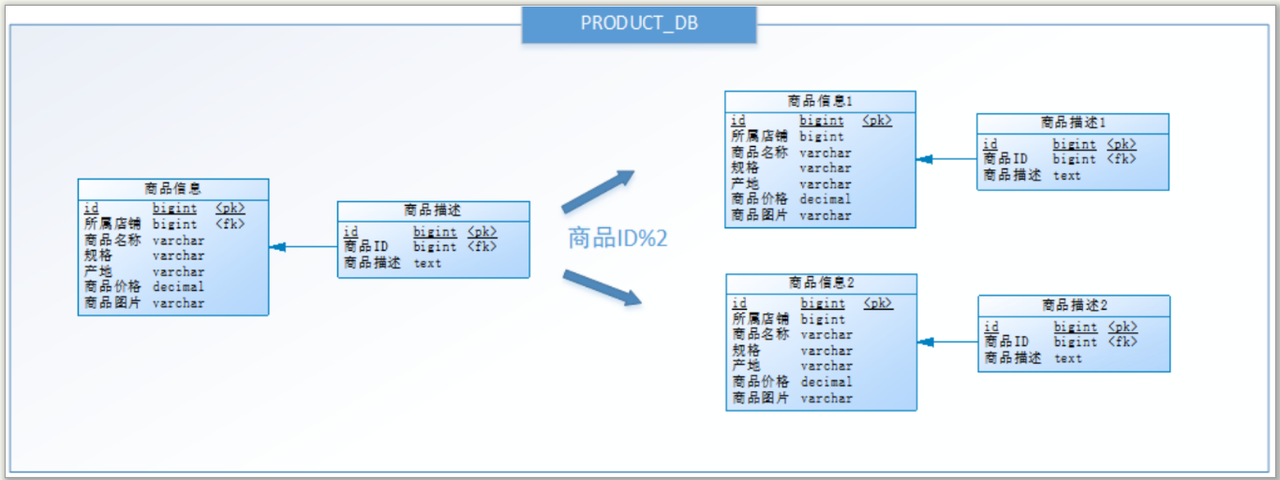
水平分表就是一张表的数据分散到多张数据表中去,一般用在单张表数据量过多的情况
例如下面的案例中,商品表的数据量假设有1000w,就可以将一张商品表拆分为结构一样的两张,每个表存500w
至于分散数据的原则,经常使用到的两种方案是:hash方式和range方式
-
hash方式:按照订单id散列法进行数据分散,id对表数量取余得到的结果就是数据要分散到表的索引
此方式的优点是数据分散均匀,缺点是扩容时需要迁移数据
-
range方式:0到500万到1表,500万到1000万到2表,依次类推
此方式的优点是扩容时不需要迁移数据,缺点是存在数据分布不均匀的情况
接下来,我们以订单表为例,将其数据进行分库分表
方案设计:
1)说明
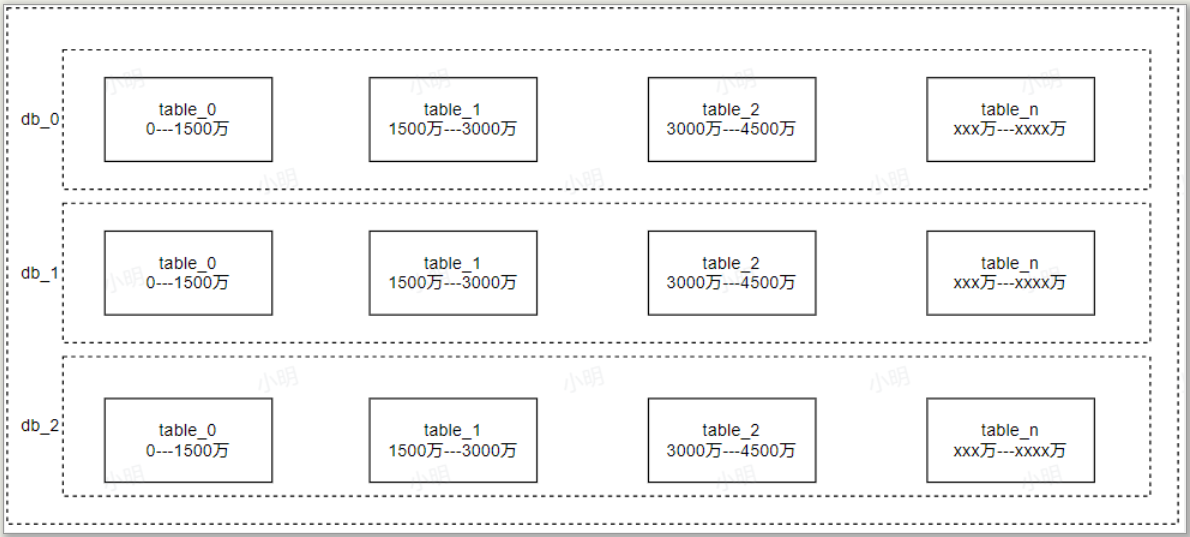
本次订单分库分表,我们使用hash法进行分库,使用range法进行分表
-
分库:设计三个数据库,根据用户id分库,分库表达式为:db_用户id % 3
-
分表:根据订单范围分表,0---1500万落到table_0,1500万---3000万落到table_1,依次类推
2)操作
订单数据库分为三个库 :jzo2o-orders-0、jzo2o-orders-1、jzo2o-orders-2

每个数据库对orders、biz_snapshot、orders_serve进行分表(暂分3个表)
其它表为广播表(即在每个数据库都存在且数据是完整的)
3)技术
ShardingSphere是一款分布式的数据库生态系统,可以将任意数据库转换为分布式数据库
它基于底层数据库提供分布式数据库解决方案,可以水平扩展计算和存储
官方文档:https://shardingsphere.apache.org/document/current/cn/overview/
具体实现:
1)添加依赖
在jzo2o-orders-base工程引入jzo2o-shardingsphere-jdbc的依赖
XML
<dependency>
<groupId>com.jzo2o</groupId>
<artifactId>jzo2o-shardingsphere-jdbc</artifactId>
</dependency>2)添加配置
在jzo2o-orders-base工程的resources下配置shardingsphere-jdbc-dev.yml
XML
##yaml##
dataSources: # 数据源, 下面可以配置多个数据库连接信息
jzo2o-orders-0:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
jdbcUrl: jdbc:mysql://192.168.101.68:3306/jzo2o-orders-0?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai
username: root
password: mysql
jzo2o-orders-1:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
jdbcUrl: jdbc:mysql://192.168.101.68:3306/jzo2o-orders-1?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai
username: root
password: mysql
jzo2o-orders-2:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
jdbcUrl: jdbc:mysql://192.168.101.68:3306/jzo2o-orders-2?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai
username: root
password: mysql
rules:
- !TRANSACTION
defaultType: BASE
providerType: Seata
- !SHARDING
tables: # 数据分片规则配置
orders: # 逻辑表名称
actualDataNodes: jzo2o-orders-${0..2}.orders_${0..2} # 实际数据节点 数据源名+表名
tableStrategy: # 分表策略
standard:
shardingColumn: id #分片列名称
shardingAlgorithmName: orders_table_inline #分片算法名称
databaseStrategy: # 分库策略
standard: # 用于单分片键的标准分片场景
shardingColumn: user_id # 分片列名称
shardingAlgorithmName: orders_database_inline # 分片算法名称
orders_serve:
actualDataNodes: jzo2o-orders-${0..2}.orders_serve_${0..2}
tableStrategy:
standard:
shardingColumn: id
shardingAlgorithmName: orders_serve_table_inline
databaseStrategy:
standard:
shardingColumn: serve_provider_id
shardingAlgorithmName: orders_serve_database_inline
biz_snapshot:
actualDataNodes: jzo2o-orders-${0..2}.biz_snapshot_${0..2}
tableStrategy:
standard:
shardingColumn: biz_id
shardingAlgorithmName: biz_snapshot_table_inline
databaseStrategy:
standard:
shardingColumn: db_shard_id
shardingAlgorithmName: biz_snapshot_database_inline
shardingAlgorithms:
# 订单-分库算法
orders_database_inline:
type: INLINE
props:
# 分库算法表达式
algorithm-expression: jzo2o-orders-${user_id % 3}
# 分库支持范围查询
allow-range-query-with-inline-sharding: true
# 订单-分表算法
orders_table_inline:
type: INLINE
props:
# 分表算法表达式
algorithm-expression: orders_${(int)Math.floor(id % 10000000000 / 15000000)}
# 允许范围查询
allow-range-query-with-inline-sharding: true
# 服务单-分库算法
orders_serve_database_inline:
type: INLINE
props:
# 分库算法表达式
algorithm-expression: jzo2o-orders-${serve_provider_id % 3}
# 允许范围查询
allow-range-query-with-inline-sharding: true
# 服务单-分表算法
orders_serve_table_inline:
type: INLINE
props:
# 允许范围查询
algorithm-expression: orders_serve_${(int)Math.floor(id % 10000000000 / 15000000)}
# 允许范围查询
allow-range-query-with-inline-sharding: true
# 快照-分库算法
biz_snapshot_database_inline:
type: INLINE
props:
# 分库算法表达式
algorithm-expression: jzo2o-orders-${db_shard_id % 3}
# 允许范围查询
allow-range-query-with-inline-sharding: true
# 快照-分表算法
biz_snapshot_table_inline:
type: INLINE
props:
# 允许范围查询
algorithm-expression: biz_snapshot_${(int)Math.floor((Long.valueOf(biz_id)) % 10000000000 / 15000000)}
# 允许范围查询
allow-range-query-with-inline-sharding: true
# id生成器
keyGenerators:
snowflake:
type: SNOWFLAKE
- !BROADCAST # 广播表
tables:
- breach_record
- orders_canceled
- orders_refund
- orders_dispatch
- orders_seize
- serve_provider_sync
- state_persister
- orders_dispatch_receive
- undo_log
- history_orders_sync
- history_orders_serve_sync
props:
sql-show: true # 打印sql3)加载配置
进入nacos在jzo2o-orders-manager.yaml中配置数据源使用ShardingSphereDriver:
XML
##yaml##
spring:
datasource:
driver-class-name: org.apache.shardingsphere.driver.ShardingSphereDriver
url: jdbc:shardingsphere:classpath:shardingsphere-jdbc-${spring.profiles.active}.yml4)状态机分库
由于对状态机进行了分库分表,需要修改创建订单方法中启动状态机代码:
使用start(Long dbShardId, String bizId, T bizSnapshot) 方法启动状态机,传入分片键user_id
支付成功调用状态机变更状态方法:
使用:changeStatus(Long dbShardId, String bizId, StatusChangeEvent statusChangeEventEnum, T bizSnapshot)变更状态, 传入分片键user_id,代码如下:
效果展示:

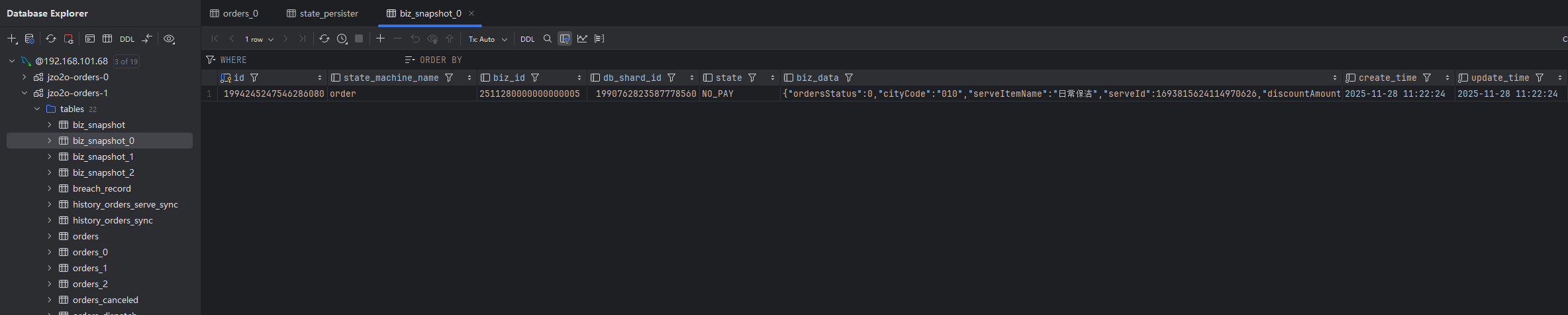
三、订单查询优化
小程序端的订单查询是一个高频接口,并且订单数据非常大,必须要做出优化,参考思路如下:
-
针对订单详情页面的单条查询,可以使用缓存进行优化
-
针对订单列表页面的分页查询,可以使用索引+缓存进行优化
订单详情优化
用缓存进行优化也就是先从缓存查,缓存没有就从数据库查,然后保存到缓存中;修改数据的时候,删除缓存
类似的功能,我们可以采用SpringCache实现,也可以使用RedisTemplate实现
在当前项目中,这部分代码已经实现好了,它写在了AbstractStateMachine类的getCurrentSnapshotCache方法中
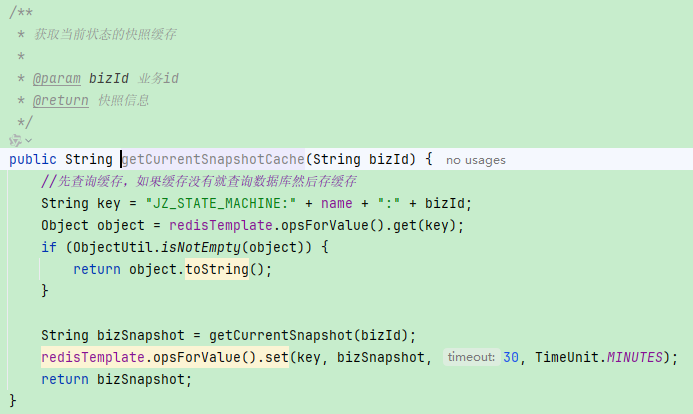
要注意的是,他是从订单库的快照表(biz_snapshot)中快照字段(biz_data)中查询的数据

当订单状态变更,此时订单最新状态的快照有变更,会删除快照缓存
AbstractStateMachine:
java
@Autowired
private OrderStateMachine orderStateMachine;
/**
* 变更状态并保存快照,快照分库分表
*
* @param dbShardId 分库键
* @param bizId 业务id
* @param statusChangeEventEnum 状态变换事件
* @param bizSnapshot 业务数据快照(json格式)
*/
public void changeStatus(Long dbShardId, String bizId, StatusChangeEvent statusChangeEventEnum, T bizSnapshot) {
...
//7.清理快照缓存
String key = "JZ_STATE_MACHINE:" + name + ":" + bizId;
redisTemplate.delete(key);
//执行后处理方法
postProcessor(bizSnapshot);
}因此,我们可以直接在订单查询时,调用它提供的这个方法,也就是修改代码如下
java
/**
* 根据订单id查询
*
* @param id 订单id
* @return 订单详情
*/
@Override
public OrderResDTO getDetail(Long id) {
//Orders orders = queryById(id);
//OrderResDTO orderResDTO = BeanUtil.toBean(orders, OrderResDTO.class);
//从快照中获取数据
String json = orderStateMachine.getCurrentSnapshotCache(id.toString());
//将数据转换为快照对象
OrderSnapshotDTO orderSnapshotDTO = JSON.parseObject(json, OrderSnapshotDTO.class);
//将快照对象转换为返回值对象
OrderResDTO orderResDTO = BeanUtil.toBean(orderSnapshotDTO, OrderResDTO.class);
return orderResDTO;
}效果展示:
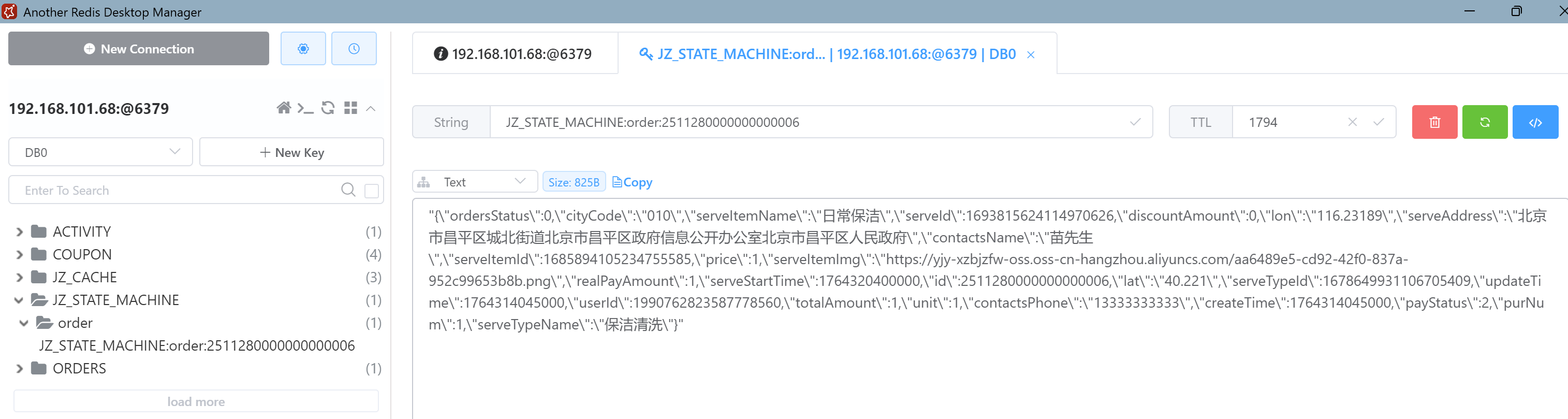
订单列表优化
方案设计:
小程序端查询订单列表,界面上没有分页的按钮,可以采用滚动查询的方式
1)滚动查询
滚动查询就是每次查询都从上次查询到的最后一条记录往后查询,例如下面这样:
sql
-- 第一次查询
select * from orders order by id limit 10; -- 假设返回的记录id是1-10
-- 第二次查询
select * from orders where id > 10 order by id limit 10; -- 假设返回的记录id是11-24
-- 第三次查询
select * from orders where id > 24 order by id limit 10;这种方式,相比较与分页查询,它的好处是不需要进行count统计总记录数,省去了count查询的消耗
但是它需要有一列唯一且有序的字段作为滚动字段,而在我们的订单表中使用的是sort_by字段,实现如下
sort_by 字段的生成规则是:serve_start_time秒级时间戳+订单id后六位
sql
select * from orders
where sort_by < 上次查询最后一条记录的sort_by值
order by sort_by desc
limit 10而订单列表的查询条件是用户id(user_id)、状态(orders_status)、是否展示(display),因此SQL修改为
sql
select * from orders
where user_id = 登录用户id
and orders_status = 订单状态(非必传)
and display = 1
and sort_by < 上次查询最后一条记录的sort_by值
order by sort_by desc
limit 10由于订单表数据量比较大,因此我们要进行索引优化
创建索引
先说说怎么创建索引:这里我们以user_id、orders_status、display、sort_by 四个字段为条件查询字段,所以要在其上添加索引(一般要在where、order、group后的字段上添加,还有表连接字段上添加索引),又由于这里还有sort_by的排序字段,所以不仅要建立sort-by的索引还要给该字段设置desc;
为了避免索引失效,sort_by进行了比较,会导致其后的索引失效
(例如,查询WHERE age>30 AND name='John'中,name无法使用索引),所以将其放在最后一位,最终生成以下索引:
sqlcreate index query_index_0 on `jzo2o-orders-1`.orders_0 (orders_status asc, user_id asc, display asc, sort_by desc);但是以上只是sql语句确定的情况下才生成了以上索引,我们的orders_status字段并不是必传的,这样会导致我们联合索引整个失效(最左匹配原则,连索引第一个字段都没了后面肯定都匹配不上了
(或者,查询
WHERE age=30 AND name='John'中,如果age不是索引列,name无法使用索引)),所以针对这种情况我们还需要另一个没有该字段的索引:
sqlcreate index query_index_1 on `jzo2o-orders-1`.orders_0 (user_id asc, display asc, sort_by desc);创建完索引我们还面临着回表问题:
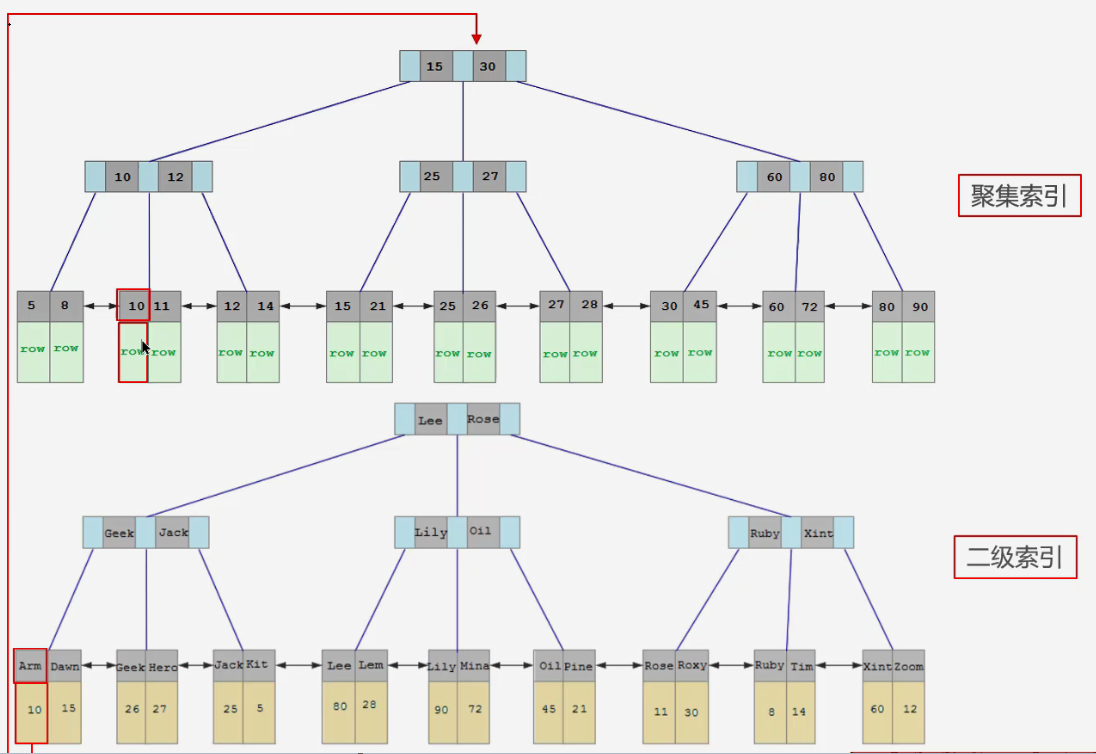
在MySQL的B+树中,索引分为聚集索引和非聚集索引(二级索引)
聚集索引的叶子节点直接保存的是数据的整条记录
非聚集索引的叶子节点则保存的是一条记录中主键的值
因此,当我们通过非聚集索引进行查询时,如果查询的列不在索引中,那么它
首先会通过非聚集索引查找到主键的值,然后再通过主键回到聚集索引中查询一次,这个过程称为回表
sql-- 假设有一张user表,包含id、name、age字段,判断下面的索引使用情况 -- 走聚集索引, 不会产生回表 select * from user where id = 1; -- 走二级索引, 不会产生回表 select id,name from user where name = 'Geek'; -- 走二级索引, 但是会产生回表 select * from user where name = 'Geek';我们现在的sql语句要查出所有字段(select * ...),但是我们的索引字段并没有覆盖所有字段,所以查询时会根据索引字段查出id,并通过id回表查出所有字段
优化如下:
sql-- 1. 先根据查询条件拿到订单的id集合(走非聚集索引,但是不会回表) select id from orders where user_id = 登录用户id and orders_status = 订单状态(非必传) and display = 1 and sort_by < 上次查询最后一条记录的sort_by值 order by sort_by desc limit 10 -- 2. 根据id集合再去查询订单信息(走聚集索引,不会回表) select * from orders where id in (上面拿到的id集合)
OrdersManagerServiceImpl.consumerQueryList():
java
/**
* 滚动分页查询
*
* @param currentUserId 当前用户id
* @param ordersStatus 订单状态,0:待支付,100:派单中,200:待服务,300:服务中,400:待评价,500:订单完成,600:已取消,700:已关闭
* @param sortBy 排序字段
* @return 订单列表
*/
@Override
public List<OrderSimpleResDTO> consumerQueryList(Long currentUserId, Integer ordersStatus, Long sortBy) {
//-- 1. 先根据查询条件拿到订单的id集合(走非聚集索引,但是不会回表)
List<Orders> list = this.lambdaQuery()
.select(Orders::getId)//select id from orders
.eq(Orders::getUserId, currentUserId)//where user_id = 登录用户id
.eq(ordersStatus != null, Orders::getOrdersStatus, ordersStatus)//and orders_status = 订单状态(非必传)
.eq(Orders::getDisplay, EnableStatusEnum.ENABLE.getStatus())//and display = 1
.lt(sortBy != null, Orders::getSortBy, sortBy)//and sort_by < 上次查询最后一条记录的sort_by值
.orderByDesc(Orders::getSortBy)//order by sort_by desc
.last("limit 10")//limit 10
.list();
if (CollUtil.isEmpty(list)){
return List.of();
}
//-- 2. 根据id集合再去查询订单信息(走聚集索引,不会回表)
//select * from orders where id in (上面拿到的id集合)
List<Long> orderIdList = list.stream().map(Orders::getId).collect(Collectors.toList());
List<Orders> ordersList = baseMapper.selectBatchIds(orderIdList);
if (CollUtil.isEmpty(ordersList)){
return List.of();
}
//3. 结果转换封装
return BeanUtils.copyToList(ordersList,OrderSimpleResDTO.class);
}首先根据我们刚才写好的sql语句书写lambdaQuery的MP代码;这里主要注意一下两个不一定传入的值需要做判空处理,没有的话就不加该where条件,最终查出id的集合list
id集合判空,true则返回空list,false则继续执行语句:根据id集合查询所有字段并拷贝封装返回
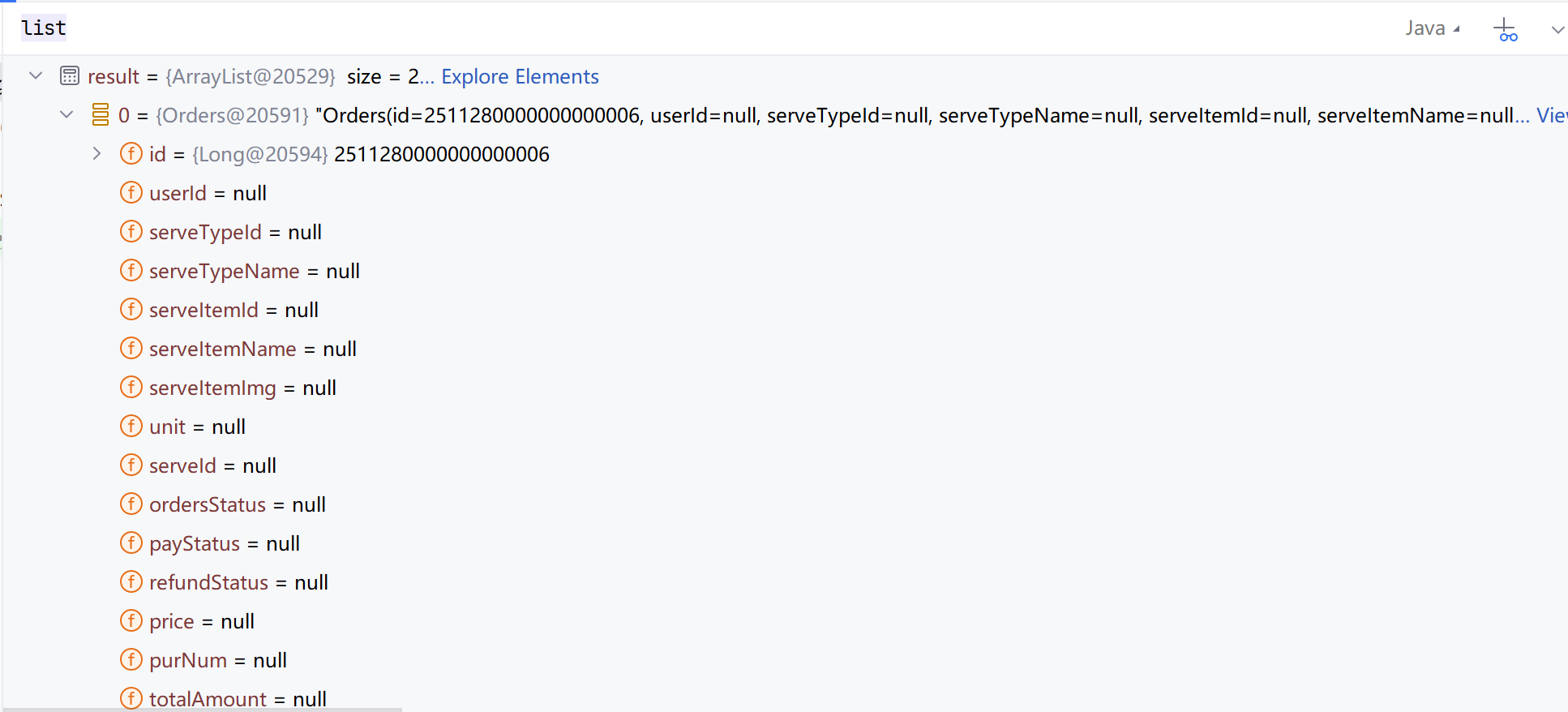
这里我发现了一个神奇的地方:通过MP查到的list居然是一整个完整的对象且包含所有字段(除了id都为null),所以还需要stream流将id取出来重新封装:
让我们看看DeepSeek对此的解释:


加入缓存
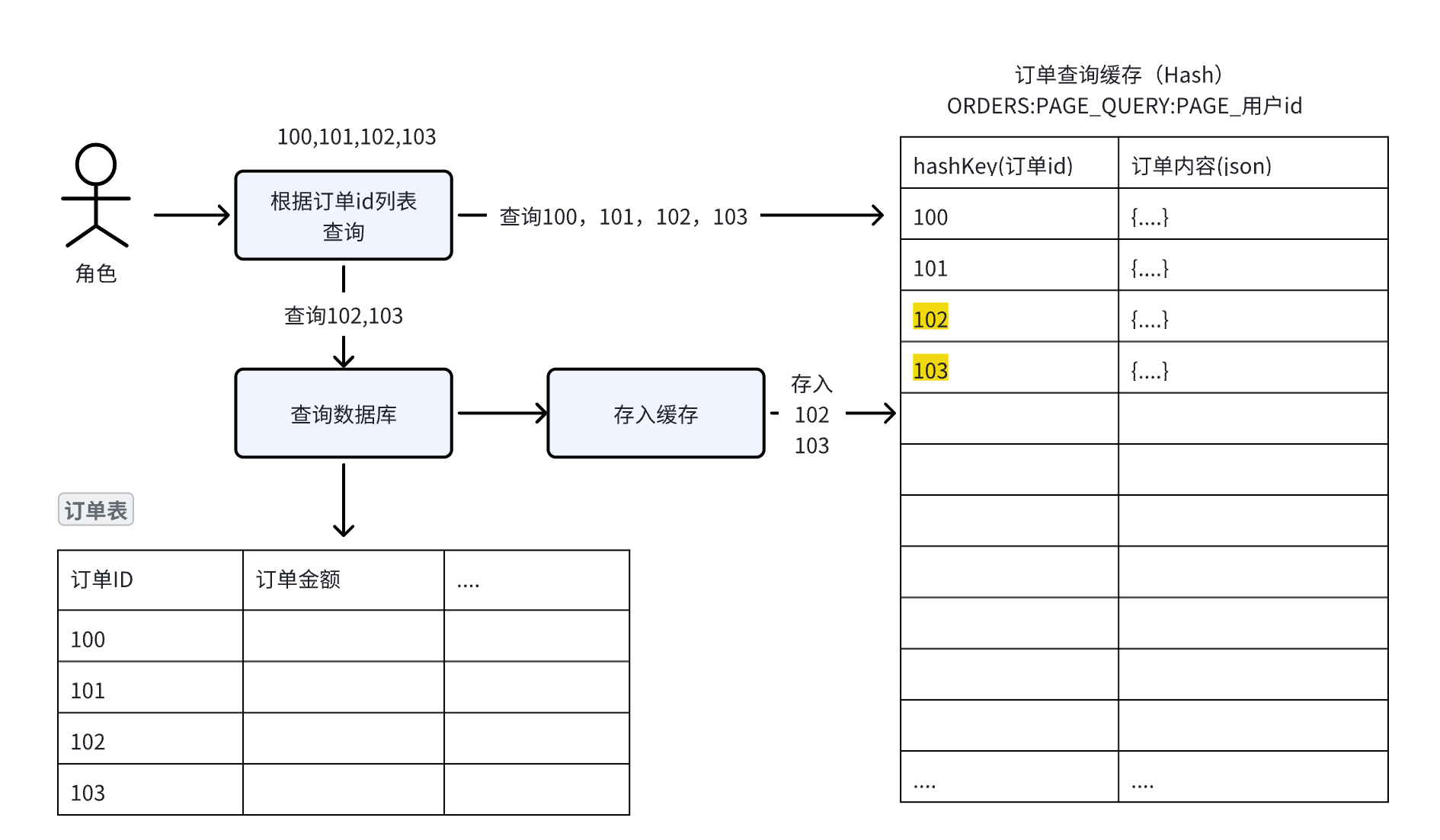
最后将查询到数据进行缓存,如果有缓存则直接获取,否则从数据库查询,过程如下图:
比如要查询的订单id为:100、101、102、103,缓存中已存在100、101的数据
那只需要从数据库查询102、103的数据,存储到缓存中即可
接下来,我们在查询列表的逻辑中加入缓存功能,在当前的项目中提供了一个缓存工具类CacheHelper
它有一个方法batchGet专门用于此功能的操作,我们可以直接调用,放入如下
java
/**
* 批量获取缓存数据,按照id列表顺序返回目标数据,如果缓存不存在则查询数据库
*
* @param dataType 缓存中的键,CACHE_加dataType 为redisKey
* @param objectIds 目标数据唯一id
* @param batchDataQueryExecutor 批量目标数据获取执行器用于当缓存数据不存在时查询数据库
* @param clazz 目标数据类型class
* @param ttl 目标数据整体过期时间(ttl大于0才会设置有效期)
* @param <K> 目标数据id数据类型
* @param <T> 目标数据类型
* @return
*/
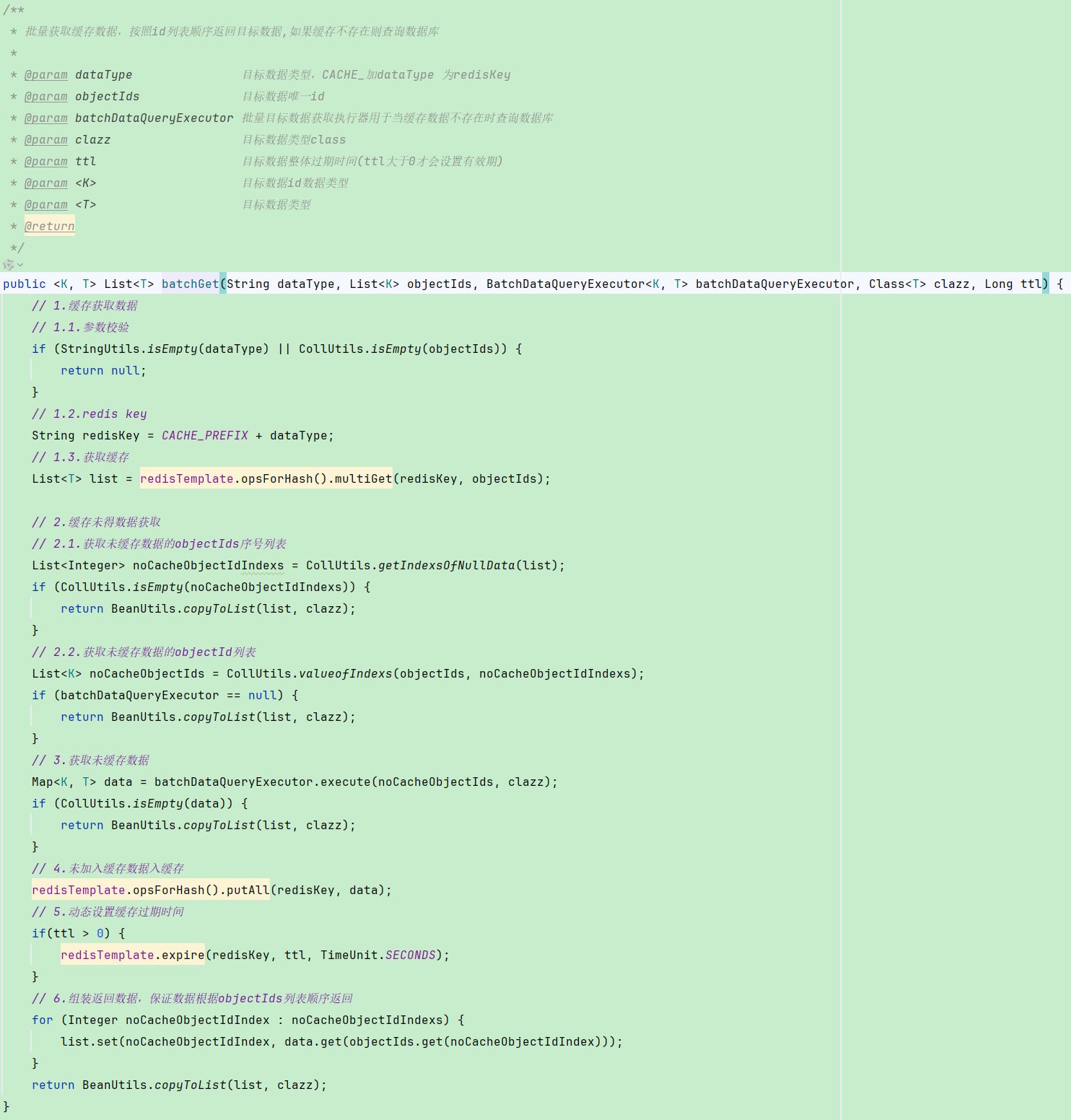
public <K, T> List<T> batchGet(String dataType, List<K> objectIds, BatchDataQueryExecutor<K, T> batchDataQueryExecutor, Class<T> clazz, Long ttl) {下边使用CacheHelper 实现订单查询缓存,代码如下:

java
@Autowired
private CacheHelper cacheHelper;
......
//-- 2. 根据id集合再去查询订单信息(走聚集索引,不会回表)
//select * from orders where id in (上面拿到的id集合)
//缓存key ORDERS:PAGE_QUERY:PAGE_用户id
String redisKey = String.format(ORDERS, currentUserId);
//收集要查询的订单id集合
List<Long> orderIdList = list.stream().map(Orders::getId).collect(Collectors.toList());
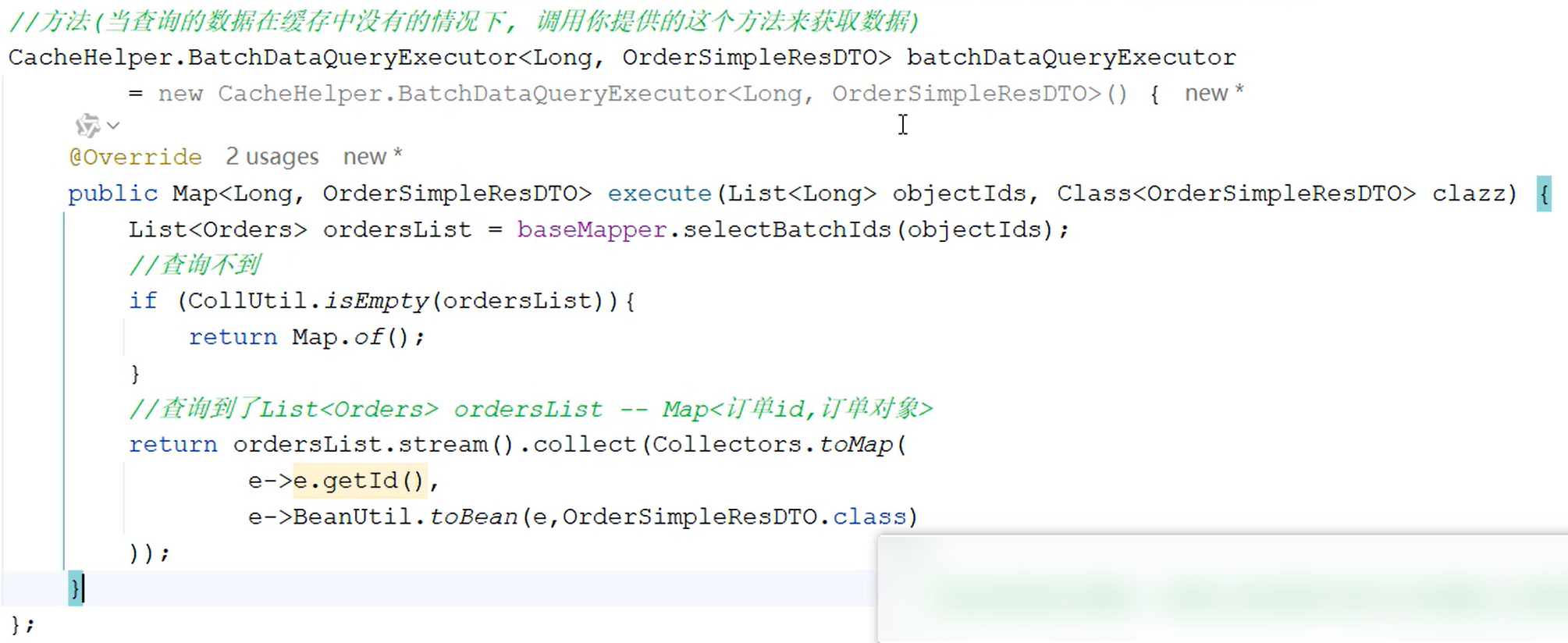
//方法(当查询的数据在缓存中没有的情况下, 调用你提供的这个方法来获取数据)
CacheHelper.BatchDataQueryExecutor<Long, OrderSimpleResDTO> batchDataQueryExecutor
= (objectIds, clazz) -> {
List<Orders> ordersList = baseMapper.selectBatchIds(objectIds);
//查询不到
if (CollUtil.isEmpty(ordersList)) {
return Map.of();
}
//查询到了List<Orders> ordersList -- Map<订单id,订单对象>
return ordersList.stream().collect(Collectors.toMap(
e -> e.getId(),
e -> BeanUtil.toBean(e, OrderSimpleResDTO.class)
));
};
List<OrderSimpleResDTO> orderSimpleResDTOS
= cacheHelper.batchGet(redisKey, orderIdList, batchDataQueryExecutor, OrderSimpleResDTO.class, 600L);
//3. 结果转换封装
return orderSimpleResDTOS;首先通过String的format方法将"ORDERS:PAGE_QUERY:PAGE_%s"字符串拼接替换上用户id生成缓存key:ORDERS:PAGE_QUERY:PAGE_用户id;
随后跟前面一样,从orders对象(其他属性为null)集合当中获取id集合;
接下来就是实现CacheHelper当中的interface:BatchDataQueryExecutor并实现其内部方法execute:
实现过程可以用以上代码中的lambda表达式替代;具体实现就是取不到缓存后执行的代码:根据id集合从数据库获取订单信息;
接下来看看CacheHelper的batchGet方法:
可以看到有很多参数,整个方法就是对查询缓存以及成功与否的抽象封装,我们只需要传参数进去、实现缓存获取失败后方法就能够达成目的
效果展示: