强化学习
强化学习的核心框架围绕着智能体(Agent)与环境(Environment)的交互展开。智能体就像是一个在陌生城市中探索的旅行者,它处于特定的环境状态(State)下,需要根据当前状态从一系列可行的动作(Action)中做出选择 。当智能体执行某个动作后,环境会根据这个动作发生相应的变化,转移到新的状态,并给予智能体一个奖励(Reward)信号,这个奖励信号是环境对智能体动作的反馈,告诉智能体该动作的好坏程度。智能体的目标是通过不断地与环境交互,学习到一种策略(Policy),使得在长期的交互过程中累积获得的奖励最大化。
以机器人在迷宫中寻找出口为例,机器人就是智能体,迷宫的布局和机器人在迷宫中的位置构成了环境状态,机器人可以采取的动作包括向前移动、向左转、向右转等 。当机器人朝着出口的方向移动时,可能会得到正奖励;如果撞到墙壁或者偏离出口方向,可能会得到负奖励。机器人通过不断尝试不同的动作,根据得到的奖励反馈,逐渐学会如何在迷宫中找到出口的最优路径。
与监督学习和无监督学习相比,强化学习具有明显的区别。监督学习依赖于大量带有标签的训练数据,通过学习输入数据与标签之间的映射关系来进行预测,就像学生根据老师批改好的作业答案来学习知识;无监督学习则主要致力于从无标签的数据中发现数据的内在结构和规律,比如对数据进行聚类分析 。而强化学习没有明确的 "正确答案" 标签,智能体通过在环境中的实际操作和探索来学习,其学习过程是动态的,并且需要考虑长期的奖励回报,更像是一个人在生活中通过不断尝试和总结经验来提升自己的能力。
深度强化学习(DRL)
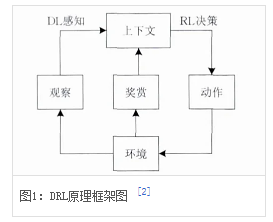
深度强化学习(Deep Reinforcement Learning,DRL)是融合深度学习感知能力与强化学习决策能力的人工智能方法,通过智能体(Agent)与环境(Environment)的交互实现从图像输入到动作输出的端到端控制,模拟人类决策思维方式。其结合深度神经网络的特征提取与强化学习的策略优化,形成从高维输入到动作输出的映射框架,核心算法包括深度Q网络(DQN)及其改进变体。
该技术通过记忆库随机采样和固定Q目标机制提升学习效率,智能体在交互中不断优化预期回报。主要研究方向包含基于值的方法(如DQN)和策略梯度方法(如PPO、DDPG),多智能体深度强化学习涉及通信、合作与博弈场景建模。后续算法引入长短时记忆网络和注意力机制,形成DRQN与DARQN变体以适应部分可观测环境。
DRL是一种端对端(end-to-end)的感知与控制系统,具有很强的通用性.其学习过程可以描述为:
(1)在每个时刻agent与环境交互得到一个高维度的观察,并利用DL方法来感知观察,以得到具体的状态特征表示;
(2)基于预期回报来评价各动作的价值函数,并通过某种策略将当前状态映射为相应的动作;
(3)环境对此动作做出反应,并得到下一个观察.通过不断循环以上过程,最终可以得到实现目标的最优策略。
DQN算法
深度 Q 网络(Deep Q-Network,DQN)算法融合了神经网络和Q learning的方法, 名字叫做 Deep Q Network。Q 学习通过维护一个 Q 值表来记录在每个状态下采取每个动作的预期奖励,而 DQN 则利用深度神经网络来近似这个 Q 值函数。以 Atari 游戏为例,DQN 可以直接将游戏画面作为输入,通过卷积神经网络提取画面中的特征,然后输出每个动作对应的 Q 值,智能体根据 Q 值选择动作,从而实现对游戏的自动学习和控制,它能够学会玩各种复杂的 Atari 游戏,如《打砖块》《太空侵略者》等,并且在一些游戏中的表现超越了人类玩家。
参考链接:https://blog.csdn.net/chsy1987/article/details/155207602?spm=1011.2415.3001.5331
自编码器(AE)
自编码器(Autoencoder,AE)是一种无监督学习的神经网络模型,宛如一位神奇的信息 "压缩大师" 和 "还原艺术家" 。它的核心结构由编码器(Encoder)和解码器(Decoder)两部分组成。编码器负责将输入数据,如高维的图像、文本或音频数据,映射到一个低维的潜在空间,这个过程就像是将一本厚厚的书籍提炼成简洁的大纲,去除冗余信息,保留关键特征,实现了数据的压缩。而解码器则承担着相反的任务,它将低维表示映射回原始输入空间,把提炼后的大纲再扩展成完整的书籍内容,尽可能恢复原始数据的全貌,完成数据的重构。
自编码器在多个领域都有着广泛的应用。在图像去噪领域,当图像受到噪声干扰时,自编码器可以通过学习噪声图像中的特征模式,在编码过程中去除噪声信息,然后在解码时重构出清晰的图像。在医学影像中,去除扫描过程中产生的噪声,提高图像的清晰度,有助于医生更准确地诊断病情;在卫星图像分析中,去除大气干扰等噪声,能获取更准确的地理信息 。
此外,自编码器还可以用于数据可视化。对于高维数据,人类很难直接理解其内在结构和分布规律,自编码器可以将高维数据映射到二维或三维空间,通过可视化这些低维表示,我们能够直观地观察数据的分布情况、聚类结构以及不同数据之间的关系,从而更好地理解数据的本质 。
注意力机制(Attention Mechanism)
注意力机制(Attention Mechanism)是深度学习领域中一种强大且灵活的技术,它模拟了人类在处理信息时的注意力分配方式 。当我们阅读一篇文章时,不会平均地关注每个字词,而是会根据上下文和当前的任务需求,有重点地关注某些关键部分;在观看一幅图像时,我们的目光会聚焦在感兴趣的物体或区域上。注意力机制在深度学习模型中实现了类似的功能,使模型能够在处理输入数据时,自动地对不同位置的信息分配不同的权重,将更多的 "注意力" 集中在与当前任务相关的重要信息上,从而提高模型的性能和效率。
以机器翻译任务为例,当模型将源语言句子翻译成目标语言时,注意力机制可以帮助模型在翻译每个目标语言单词时,动态地关注源语言句子中与之相关的部分。在将英文句子 "Hello, I am going to the park." 翻译成中文 "你好,我要去公园。" 的过程中,翻译 "公园" 这个词时,注意力机制会使模型更关注源语言中的 "park" 以及与之相关的上下文信息,从而更准确地完成翻译 。
在图像字幕生成任务中,注意力机制能够让模型在生成描述图像的文本时,聚焦于图像中的不同区域。当描述一幅包含人物、风景和动物的图像时,模型在生成描述人物的文字时,会将注意力集中在人物所在的区域;生成描述动物的文字时,注意力则会转移到动物区域,从而生成更贴合图像内容的字幕 。
在语音识别中,注意力机制也发挥着重要作用。语音信号是一种序列数据,包含了丰富的时间信息。注意力机制可以使模型在处理语音信号时,关注不同时间段的关键语音特征,从而更准确地识别语音内容,提高语音识别的准确率,减少因语音模糊或背景噪声干扰导致的识别错误 。
算法选择与应用场景
参考链接:https://blog.csdn.net/xiaoyingxixi1989/article/details/151627962
在深度学习的实际应用中,根据数据类型和任务类型选择合适的算法至关重要,就像选择合适的工具来完成不同的工作一样。
对于图像数据,对于图像数据,卷积神经网络(CNN)是当之无愧的首选算法 。图像具有天然的网格结构,CNN 的局部连接、权值共享和池化操作使其能够有效地提取图像的特征,如边缘、纹理、形状等。在图像分类任务中,CNN 可以准确判断图像中物体的类别;目标检测任务里,它不仅能识别物体,还能确定物体在图像中的位置;图像分割任务中,CNN 能够将图像中的每个像素进行分类,实现对图像的精细划分。如果要对大量的水果图片进行分类,判断图片中的水果是苹果、香蕉还是橙子等,CNN 就能发挥其强大的图像特征提取能力,准确完成分类任务。
当处理文本数据时,循环神经网络(RNN)及其变体,如长短期记忆网络(LSTM)和门控循环单元(GRU),以及基于 Transformer 架构的模型表现出色 。文本是一种典型的序列数据,每个单词或字符的含义都与上下文密切相关。RNN 及其变体能够处理序列数据中的时间动态性,通过隐藏层的自连接保存和利用过去的信息来理解当前的输入,从而更好地处理文本。Transformer 架构则引入了注意力机制,使模型能够在处理文本时自动关注与当前任务相关的部分,进一步提升了对长文本的处理能力。在机器翻译中,Transformer 模型可以将源语言文本准确地翻译成目标语言;文本生成任务里,它能根据给定的提示生成连贯、自然的文本。
语音数据同样具有序列特性,RNN、LSTM、GRU 等算法也常用于语音识别、语音合成等任务 。在语音识别中,这些算法可以将语音信号转换为文字;语音合成任务中,它们能根据文本生成自然流畅的语音。此外,基于深度学习的声纹识别技术也在不断发展,通过提取语音中的特征信息,实现对说话人的身份识别,在安全验证、智能客服等领域有着广泛的应用。
在分类任务中,除了上述针对不同数据类型的算法外,前馈神经网络(FFNN)也可以用于简单的分类问题 。FFNN 通过将输入数据映射到输出层,经过隐藏层的特征提取和变换,输出分类结果。对于一些特征简单、分类类别较少的数据集,FFNN 能够快速学习到数据的模式,实现准确分类。
回归任务旨在预测一个连续的数值,如预测房价、股票价格等 。在这种情况下,可以使用全连接神经网络(FCN),它是前馈神经网络的一种特殊形式,所有神经元都与下一层的神经元全连接。通过调整网络的权重和偏置,FCN 可以学习到输入数据与输出数值之间的映射关系,从而进行回归预测。一些基于深度学习的时间序列预测模型,如 LSTM、GRU 等,也常用于预测具有时间序列特性的数值,如股票价格的走势。
生成任务则需要用到生成式算法,如生成对抗网络(GAN)和变分自编码器(VAE) 。GAN 通过生成器和判别器的对抗训练,能够生成逼真的数据样本,在图像生成、图像风格迁移等领域有着出色的表现;VAE 则基于概率模型,将高维数据映射到低维潜在空间,并在该空间中进行概率建模,生成具有多样性的样本,常用于图像生成和异常检测等任务。
深度学习算法的选择需根据具体应用场景和数据特性进行匹配,以下是常见场景的算法推荐:
-
计算机视觉
图像分类:ResNet、VGGNet、GoogLeNet(适用于ImageNet等大规模数据集)
目标检测:YOLO、SSD(实时检测)、Faster R-CNN(高精度检测)
图像分割:U-Net、Mask R-CNN(医学影像、自动驾驶场景)
-
自然语言处理
文本分类:BERT、RoBERTa(预训练模型)
机器翻译:Transformer、Seq2Seq(结合Attention机制)
情感分析:LSTM、GRU(处理长序列依赖)
-
序列建模
时间序列预测:LSTM、GRU(金融、气象预测)
语音识别:CTC(Connectionist Temporal Classification)
-
生成任务
图像生成:GAN(StyleGAN、DCGAN)
文本生成:Transformer(ChatGPT、LLaMA)
-
强化学习
游戏AI:DQN(Deep Q-Network)
机器人控制:PPO(Proximal Policy Optimization)
-
优化算法选择
小数据集:SGD或Adam(收敛快)
大数据集:Mini-batch SGD(平衡效率与稳定性)
高维数据:Adam或RMSprop(自适应学习率)
-
工业应用
质检:YOLO、ResNet(实时缺陷检测)
推荐系统:Embedding模型(Word2Vec、Graph Neural Networks)