摘要:在自动驾驶的下半场,拼的不再是路测里程,而是"数据闭环"的效率。仿真(Simulation)作为闭环的核心引擎,是如何吞噬海量数据并吐出算法能力的?本文将从大数据开发的视角,深度解密 Rosbag 到 OpenSCENARIO 的转化逻辑,揭秘工业界如何构建自动驾驶的"黑客帝国"。
引言:为什么我们需要"制造"一个世界?
现在的自动驾驶行业有一个共识:实车跑一亿公里,不如仿真跑一万个Corner Case。
实车测试太贵、太慢、太危险。为了让算法快速迭代,车企和 Tier 1 正在疯狂构建虚拟世界------这听起来像《黑客帝国》,在工业界我们称之为数据驱动的仿真。
但在搭建这个"矩阵"时,最大的痛点不是显卡够不够快,而是数据怎么喂?作为大数据开发工程师,我们的任务不是简单的搬运 Log,而是将物理世界的混沌数据,提炼为仿真引擎能读懂的"标准资产"。
一、 仿真软件的"春秋战国":谁在统治虚拟世界?
首先,我们要知道数据是喂给谁吃的。工业界的仿真软件并没有"一款通吃"的神器,而是分工明确的军团:
"考驾照"的考官(场景验证) :VTD (Virtual Test Drive) 和 IPG CarMaker:强在确定性与动力学,同样的参数跑一万次结果必须一样,是做 HIL(硬件在环)的首选。
"练视力"的画师(感知训练) :Carla / AirSim / NVIDIA DRIVE Sim:基于游戏引擎(UE4/Omniverse)或光线追踪,画质逼真,生成的合成数据能以假乱真,主要用于训练视觉算法。
"查身体"的医生(车辆动力学/CAE) :CarSim / Abaqus:负责算"车怎么动"以及"撞了会不会坏"。智驾算法发指令,CarSim 算侧倾和抓地力。

二、 打破巴别塔:仿真数据的"全家桶"标准
不同的软件就像说着不同方言的人。为了让数据流通,ASAM(自动化及测量系统标准协会) 定义了一套全球通用的"普通话"。
如果你是数据开发,请把这张表贴在显示器旁边,这是你工作的核心:
|-----------|-------------------|-------|---------------|---------------------------|
| 数据类型 | 行业标准格式 | 文件后缀 | 核心作用 | 开发任务 (Pipeline) |
| 高精地图 | OpenDRIVE | .xodr | 虚拟世界的"基建图纸" | 解析路网拓扑,生成 XML |
| 测试剧本 | OpenSCENARIO | .xosc | 描述"谁在动、怎么动" | 场景挖掘:从 Log 中提取切入、急刹事件 |
| 路面细节 | OpenCRG | .crg | 描述路面坑洼、起伏 | 点云网格化,生成二进制地形 |
| 真值/接口 | ASAM OSI | .osi | 传感器模型与真值的通用接口 | Protobuf 序列化,用于云端大规模仿真 |
| 实车数据 | Rosbag / MDF4 | .bag | 原始数据的载体 | 解析、索引、切片 |
| 算法模型 | FMI Standard | .fmu | 跨软件的模型黑盒 | 管理控制组提交的算法库 |
三、 为什么满大街都是 ROS?------ 研发界的"潜规则"
在量产车底层(Runtime),我们用 AUTOSAR、用 C++、用 QNX。但在研发阶段 ,ROS (Robot Operating System) 格式(.bag)几乎是统治级的。
为什么?
-
感知数据的"集装箱" :
传统车企用的 MDF4/BLF 适合记几个字节的信号(车速、温度),但面对激光雷达(每秒几百万个点)和 4K 视频,MDF4 处理起来捉襟见肘。ROS 的 PointCloud2 和 Image 消息结构天生就是为吞吐多媒体数据设计的。
-
可视化的降维打击(Rviz / Foxglove) :
这是重点。 算法工程师离不开可视化的调试工具(如 Rviz)。-
误区:很多入门开发者以为大数据只要负责存数据就行。
-
真相:大数据开发的真正价值在于**"解析(Parsing)"与"切片(Slicing)"**。
-
原始的 Bag 包动辄几百 GB,是二进制的"黑盒"。
-
算法工程师如果想看"昨天下午3点那次急刹车",他不想下载500G的文件并在本地解析半天。
-
我们的工作 :在云端通过 Spark/Flink 对 Bag 包进行消息级解析 ,将数据结构化存入数据仓(Hive/Iceberg)。当工程师检索到问题场景时,我们提供基于时间戳的精准切片------只生成那个"关键30秒"的 Bag 包给他们下载调试。
-
-
结论 :能帮算法工程师从海量数据中免解析直接提取出可视化的场景片段,这才是让他们"感激涕零"的服务。
-

四、 核心实战:从"数据挖掘"到"仿真重现"的流水线
作为数据开发,如何构建一条自动化的场景工厂 (Scenario Factory)?以下是基于真实业务场景的技术拆解:
第一步:场景挖掘
每天车队上传海量数据,利用 Spark/Flink 进行"淘金"。
-
逻辑:设定业务规则。例如 Ego.Speed > 60 AND Target.TTC < 2s AND Target.Cut_In = True。
-
产出:命中事件的元数据(Metadata),包含 Bag ID、开始时间、结束时间。
第二步:参数化提取
从结构化数据中提取关键物理参数,用于重构场景。
-
主车初始速度:v0=80km/h
-
旁车切入时机:t=3.5s
-
旁车轨迹坐标序列:(x1,y1),(x2,y2),...
第三步:自动化生成 OpenSCENARIO (.xosc)
这是最秀的一步。利用 Python 库(如 scenariogeneration),将提取的参数填入 XML 模板。
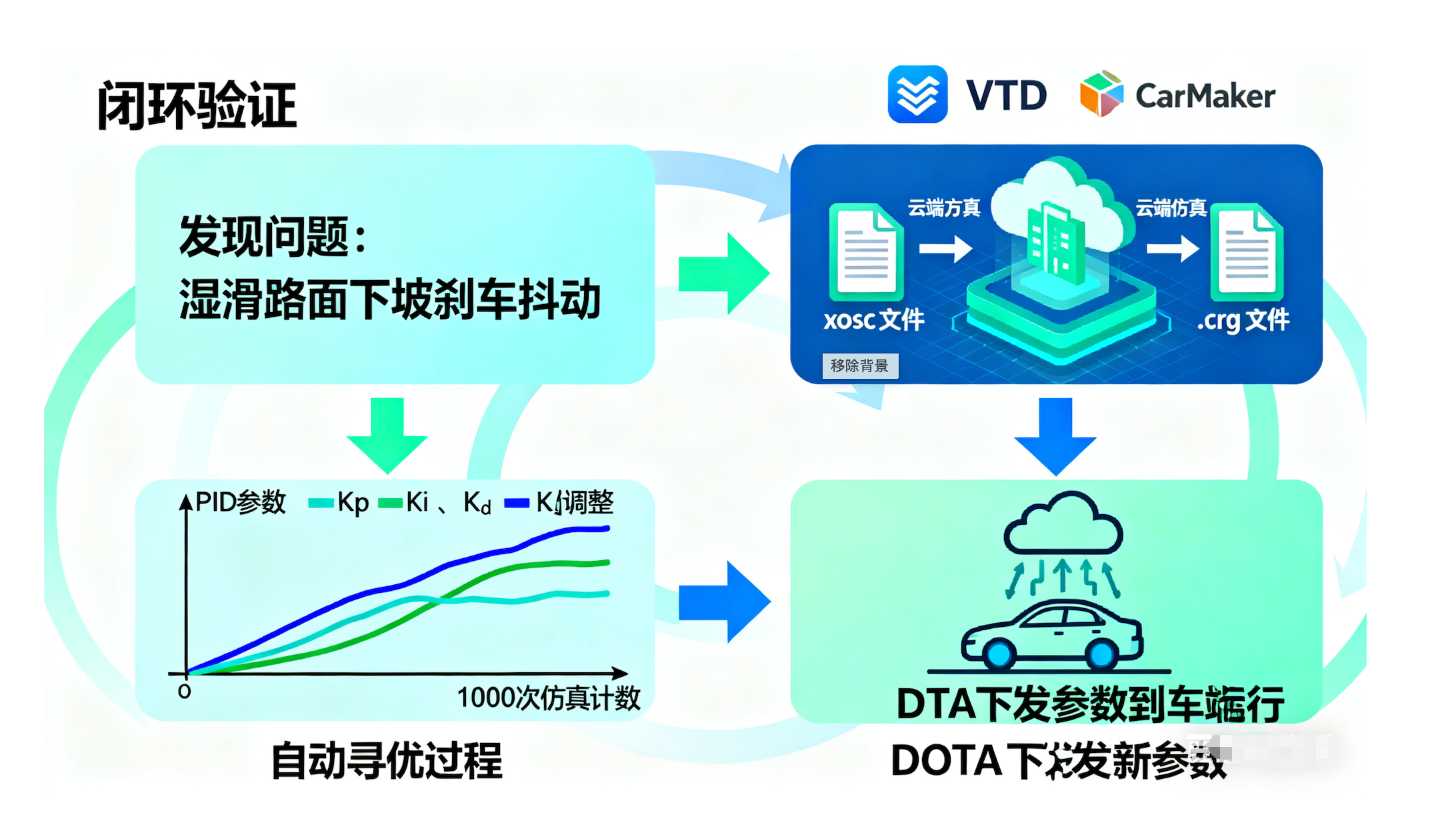
第四步:闭环验证(以 PID 优化为例)
数据生成了怎么用?以最经典的 PID 控制器 调参为例:
-
发现问题:数据挖掘发现,在湿滑路面下坡时,现有的 PID 参数会导致刹车抖动。
-
云端仿真:将生成的 .xosc(剧本)和 .crg(湿滑路面模型)推送到 VTD/CarMaker 中。
-
自动寻优:在仿真里跑 1000 次,自动调整 PID 的 Kp,Ki,Kd
参数,直到找到一组让刹车曲线最平滑的参数。
-
影子模式:新参数通过 OTA 下发,在车端"影子运行",验证无误后转正。
 这就是仿真数据闭环的终极形态
这就是仿真数据闭环的终极形态
结语:大数据的下一个金矿
自动驾驶的竞争,正在从"代码行数"转变为"数据资产的质量"。
作为开发者,如果你能熟练玩转 Rosbag 消息解析 、OpenSCENARIO 生成 以及 ETL 自动化管线 ,你就不再是一个简单的 ETL 工程师,而是自动驾驶虚拟世界的架构师。
在这个领域,数据不是静止的石油,而是流动的血液,它在物理世界和虚拟矩阵之间循环,每一次循环,都让自动驾驶离我们更近一步。
如果你觉得这篇文章有帮助,欢迎点赞收藏,评论区交流你在仿真数据落地中遇到的坑!