一,编译原理
C语言编译分为四个步骤:预编译/预处理→编译→汇编→链接
1.预编译/预处理:对源代码进行初步文本处理,包括宏定义展开,文件的包含,注释删除,条件编译等 xxx.c-xxx.i
2.编译:检查语法错误,若没有错误就将其编译为汇编语言文件(汇编文件) xxx.i-xxx.s
3.汇编:将汇编文件转换为目标文件(二进制文件) xxx.s-xxx.o4.链接:将一个或多个目标文件(.o)以及库文件合并成最终可执行的文件
二、输入输出函数
2.1 printf函数
函数原型:int printf( const char *format, ... );
函数功能:printf()函数根据format(格式)给出的格式打印输出到STDOUT(标准输出)和其它参数中
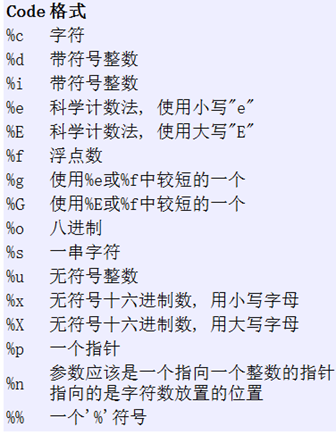
用法一:printf("字符串\n");
用法二:printf("字符串+格式控制符\n",输出参数);
用法三:printf("格式控制符1+格式字符串2\n",输出参数1,输出参数2);
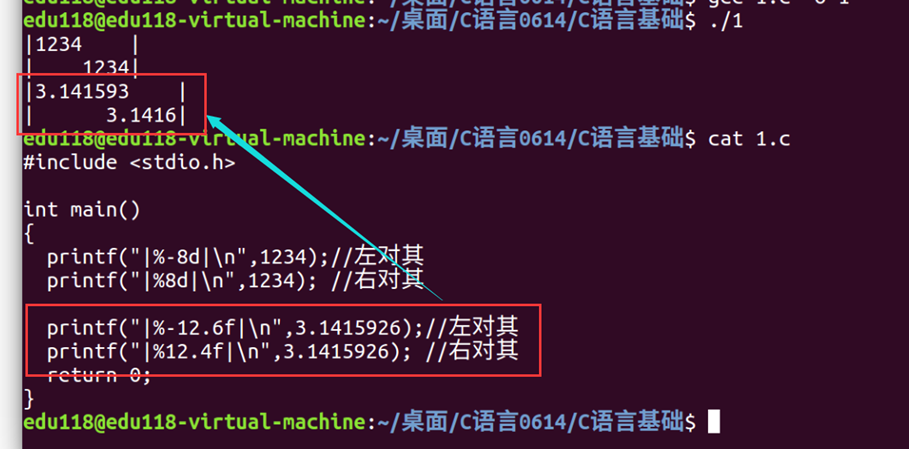
宽度与精度控制:
1.宽度说明符控制实际的输出宽度
2.精度说明符控制实际的输出精度(小数点后几位)
3.%-f 或 %f:%号后面的正负决定输出是左对齐还是右对齐,整数表示宽度,小数部分表示精度
2.2 scanf函数
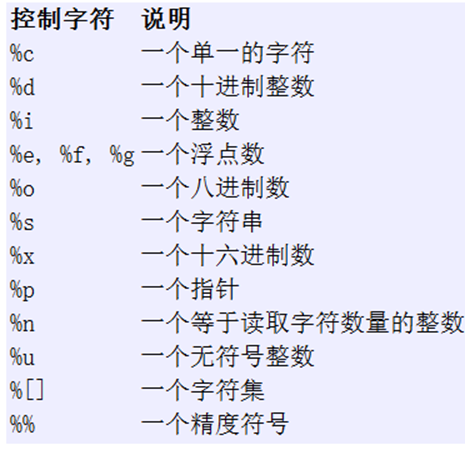
函数原型:int scanf( const char *format, ... );
函数功能:scanf()函数根据由format(格式)指定的格式从stdin(标准输入)读取,并保存数据到其它参数
用法一:scanf("字符串+格式控制符",地址表)
用法二:scanf("格式控制符1 格式控制符2",地址表1,地址表2);
注意:scanf函数双引号内除了格式控制符之外都要原样输入
%d格式控制符只能识别0-9,+ -(正负号),%d,%i,%f,%lf,%u,%o,%s,%x会跳过前导空白字符(包括空格、制表符、换行符)
注意:
scanf函数始终从输入缓冲区读取数据。如果缓冲区中有符合format格式的数据,就直接提取并赋给变量;如果缓冲区为空或数据不符合格式,会根据情况等待用户输入或立即返回失败。成功读取的数据会从缓冲区移除,失败时问题数据保留在缓冲区中。

2.3 getc与putc函数
函数原型:int getc(FILE *stream);
函数功能:从指定的文件流中读取一个字符
;
返回值:返回读取的字符(转换为int类型),如果到达文件末尾或发生错误,返回EOF
函数原型:int putc(int char, FILE *stream);函数功能:将一个字符写入指定的文件流
函数参数:参数
char是要写入的字符(作为int传递)返回值:返回写入的字符,如果发生错误返回
EOF
2.4 getchar与putchar函数
函数原型:int getchar(void);等价于
getc(stdin)函数功能:从标准输入(stdin)读取一个字符
返回值:返回读取的字符(转换为
int类型),如果到达文件末尾或发生错误,返回EOF
函数原型:int putchar(int char);等价于putc(char, stdout)函数功能:将一个字符写入标准输出(stdout)
函数参数:
char是要写入的字符(作为int传递)返回值:返回写入的字符,如果发生错误返回
EOF
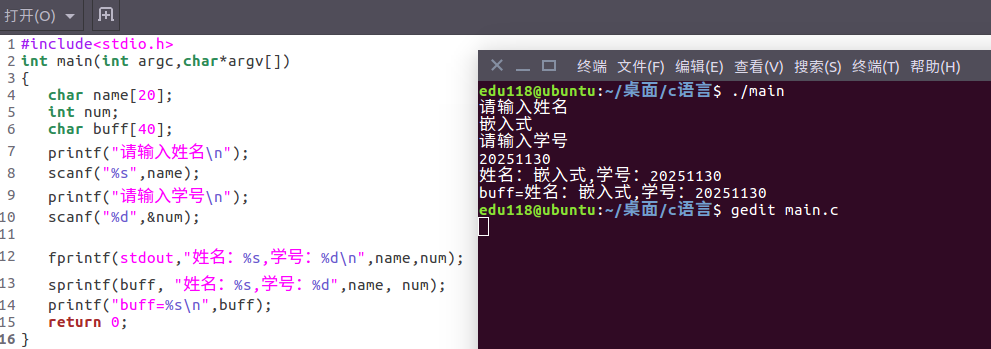
2.5 fprintf与sprintf函数
函数原型:int fprintf(FILE *stream, const char *format, ...);
函数功能:将格式化数据写入指定的文件流
函数原型:int sprintf(char *str, const char *format, ...);函数功能:不直接输出到屏幕或文件,而是存储到字符数组中
三、缓冲区
为什么引入缓冲区?
当高速设备与低速设备不匹配时,势必会让高速设备花时间等待低速设备,可以在这两者之间设立一个缓冲区。
作用一:可以解除两者的制约关系,数据可以直接送往缓冲区,高速设备不用再等待低速设备,提高了计算机的效率
作用二:可以减少数据的读写次数,如果每次数据只传输一点数据,就需要传送很多次,这样会浪费很多时间,因为开始读写与终止读写所需要的时间很长,如果将数据送往缓冲区,待缓冲区满后再进行传送会大大减少读写次数,这样就可以节省很多时间。
缓冲区刷新条件
1.缓冲区满:当缓冲区满时,会自动刷新
2.遇到换行符(对于行缓冲区):例如,标准输出(stdout)是行缓冲的,所以遇到'\n'时会刷新
3.手动刷新:使用fflush函数强制刷新缓冲区
4.程序正常结束:当main函数返回或调用exit时,所有打开的输出流会被刷新
5.关闭文件:当使用fclose关闭文件时,缓冲区会被刷新
6.从无缓冲流中读取:如果从无缓冲流中读取,则所有输出流会被刷新(这取决于实现)
7.从行缓冲流中读取:如果从行缓冲流中读取,则该流会被刷新(例如,从stdin读取时,会刷新stdout)
注意:标准错误流(stderr)通常是无缓冲的,这样错误信息可以立即显示
四、数据类型
4.1 关键字
①数据类型关键字:char short int float double long signed unsigned struct enum union void typedef volatile
基本数据类型:char short int long float double
派生类型:struct enum union
类型修饰符:signed unsigned
空修饰符:void
②控制语句关键字
选择结构:if-else switch-case-default
循环结构:for while do continue goto return break
③与存储类关键字
auto static extern const register
④运算符关键字
sizeof
作用:
auto:所有局部变量默认就是auto的
static:局部变量:保持值的持久性,只在第一次初始化
全局变量/函数:限制作用域为当前文件
extern:声明在其他文件中定义的全局变量或函数,用于多文件编程
const:定义只读变量,防止意外修改
register:建议编译器将变量存储在寄存器中(很少用)
volatile:告诉编译器变量可能被意外修改,防止编译器进行优化
变量名命名规则:①不能和关键字重名;②只能是数值,字母,下划线,美元符$;③第一个字符不能为数字

4.2 地址概述
CPU的位数主要决定了其通用寄存器的宽度,这直接影响CPU单次操作能处理的数据量和理论上能直接寻址的内存空间范围,但实际实现可能受地址总线宽度、操作系统和硬件架构的影响
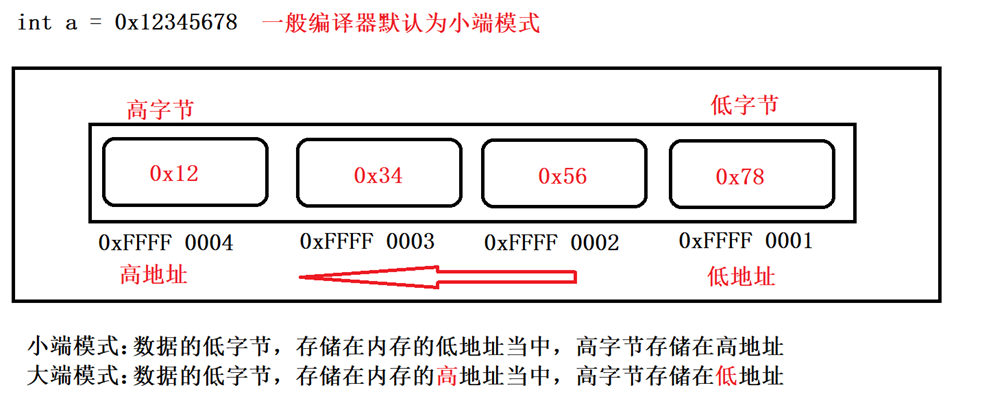
4.3 大小端模式
4.4 存储原理
4.4.1 整形数据
整形数据是以补码的形式存储在内存当中
①如果数据为正数:原码 = 反码 = 补码
②如果数据为负数:反码 = 原码按位取反(除去符号位),补码 = 反码+1
4.4.2 浮点型数据
float:单精度浮点数(精确到小数点后6位)
double:双精度浮点数(精确到小数点后15位)
4.4.3 字符型数据
字符变量用来存储单个字符,在C语言中用char表示,其中每个字符占用一个字节。再给字符型变量赋值是,需要用一对英文半角格式的单引号('')将字符括起来
字符变量实际上并不是将字符本身放在变量的内存单元中,而是将字符对应ASCII编码放到变量的存储单元中。Char本质上就是一个字节大小的整形。

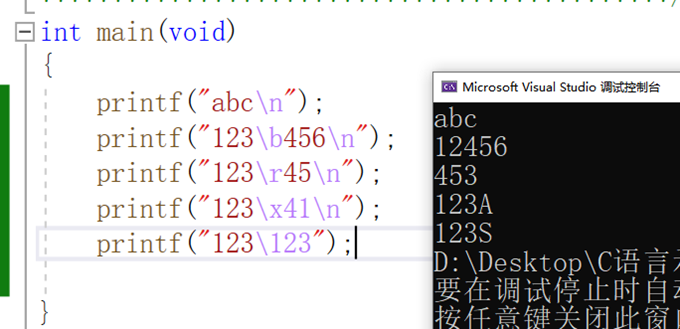
4.5 转义字符
|--------------------------------|---------------------|-------|
| 转义字符 | 含义 | ASCII |
| \a | 警报 | 7 |
| \b | 退格(BS),当前位置移到前一列 | 8 |
| \f | 换页(FF),将当前位置移到下页开头 | 12 |
| \n | 换行(LF),将当前位置移到下一行开头 | 10 |
| \r | 回车(CR),将当前位置移到本行开头 | 13 |
| \t | 水平制表符(HT),调到下一个tab | 9 |
| \v | 垂直制表符(VT) | 11 |
| \0 | 数字0 | 0 |
| \ + 1-3位八进制数字(0-7) | 8进制的转义字符(\123→S) | |
| \x + 1-n位十六进制数字(0-9,A-F,a-f) | 16进制转义字符(\41→A) | |