文章目录
- 什么是LLM
- 核心概念
- RAG(检索增强生成)
-
- 基础概念
- 传统工程与LLM的结合
- [粗排 `and` 精排](#粗排
and精排)
什么是LLM
- 定义:基于
Transformer架构、在海量文本数据上训练出来的、具有强大语言理解和生成能力的超大规模语言模型。 - 核心能力:语言生成、知识问答、内容总结、代码编写等。
- 典型代表:
GPT系列、LLaMA系列、ChatGLM等。
核心概念
关键术语扫盲
Token化:文本如何被切分成模型能理解的单元。Prompt Engineering(提示词工程):如何通过设计输入文本来引导模型输出你想要的结果。这是后端工程师必须掌握的核心技能。RAG:检索增强生成。这是后端工程师最能发挥价值的领域,它结合了信息检索和LLM,解决模型"幻觉"和知识陈旧问题。embedding:
RAG(检索增强生成)
基础概念
- 是什么:检索增强生成。
- 解决什么问题:解决了
LLM的幻觉和知识陈旧问题。 - 工作流程:
- 检索 :当用户提问 时,先从你的私有知识库(如数据库、文档库)中检索出最相关的信息片段。
- 增强 :将检索到的信息片段和用户问题一起组合成一个新的、更丰富的提示。
- 生成 :将增强后的提示送给
LLM,让它基于这些可靠信息生成答案。
- 关键组件:
- 向量数据库(存储文档的向量化表示)
- 嵌入模型(把文本变成向量)
- 检索器 (找到最相关的文档片段)
这个流程图清晰地展示了检索增强生成(RAG) 的核心工作流。它完美结合了后端工程(API、数据库)和AI能力。
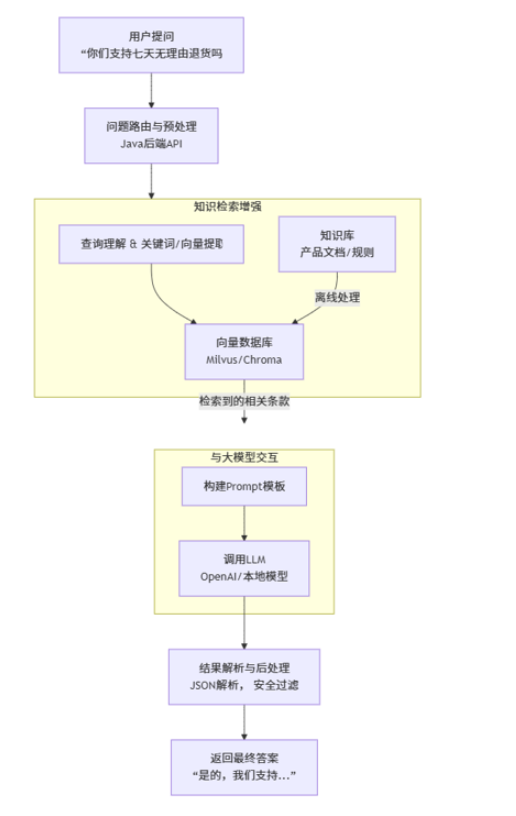
传统工程与LLM的结合
RAG架构的后端工程实现
核心数据流与组件:
- 文档注入管道 :
- 挑战:原始数据(
PDF、Word、Wiki)是非结构化的。 - 后端实现:一个异步处理服务。它需要完成:
- 文件的上传 :分片上传,断点续传机制,使用
MinIO进行存储 - 文本提取与清洗 :使用
Apache Tika或pdfbox等库。 - 智能切片 :这是关键质量点。简单的按字符长度切分会破坏语义。你需要采用递归切片、基于标记(如标题)的切片等策略。
- 向量化 :调用
Embedding模型API(如OpenAI, 或本地部署的bge-large)将文本切片转换为向量。 - 存入向量数据库 :将向量和元数据(如来源、切片
ID)持久化。
- 挑战:原始数据(
查询响应流程:
- 挑战:低延迟、高相关性的检索。
- 后端实现:
Query理解与改写:在将用户查询向量化前,可能先用一个轻量级LLM对其进行改写、扩展或优化,以提升检索效果。- 多路检索与融合:为了更高的召回率,可能同时使用向量检索(语义相似)和关键词检索(如
Elasticsearch,保证字面匹配),然后对结果进行融合排序。 Prompt模板引擎:检索到的文档片段是动态的,需要与用户问题一起填入一个预设的Prompt模板。这需要一个灵活、可配置的模板渲染服务。LLM API网关与代理:统一封装对上游多个LLM服务(如OpenAI、Azure、自研模型)的调用,实现负载均衡、熔断降级、鉴权计费。
- 技术栈选型:
- 向量数据库:
Milvus、Pinecone(云服务)、Pgvector(PostgreSQL插件,简单场景首选)。 - 全文检索:
Elasticsearch。 - 异步任务:
Spring Boot+@Async、消息队列(如RabbitMQ / Kafka)处理文档注入。 - 缓存:用
Redis缓存频繁查询的检索结果或生成的最终答案,大幅降低成本和延迟。
- 向量数据库:
架构图如下:
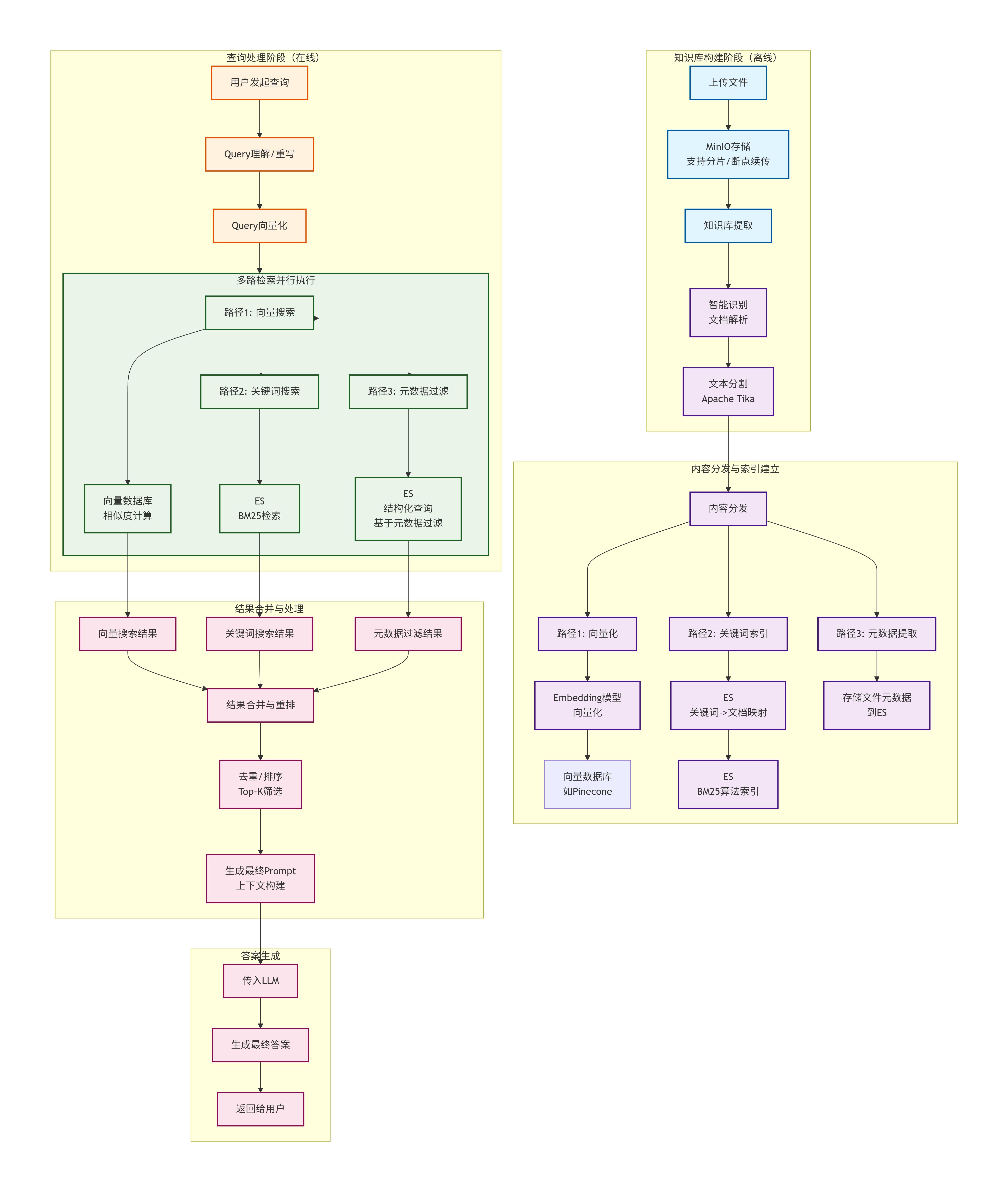
流程图说明:
这个流程图完整展示了从知识库构建到多路检索再到答案生成的完整
RAG系统工作流程:
阶段1:知识库构建(离线)文件上传:用户通过
MinIO上传文件,支持分片和断点续传文档处理:使用
Apache Tika进行文本解析和分割内容分发:处理后的文本分发给三个不同索引路径
阶段2:多路索引建立向量索引路径:文本 →
Embedding模型 → 向量数据库关键词索引路径:文本 →
ES建立BM25倒排索引元数据路径:提取文件元数据存入
ES
阶段3:查询处理(在线)
Query理解:LLM重写/优化用户查询
Query向量化:将查询转换为向量表示并行多路检索:同时在三类索引中搜索
阶段4:结果处理与生成结果合并:合并三种检索路径的结果
重排去重:基于相关性排序(
TopK排序)并去重
Prompt构建:构建包含上下文的Prompt答案生成:
LLM基于检索结果生成最终答案
这个架构确保了RAG系统既有高召回率 (多路检索 不漏结果),又有高准确率 (重排去重精选最佳上下文)。
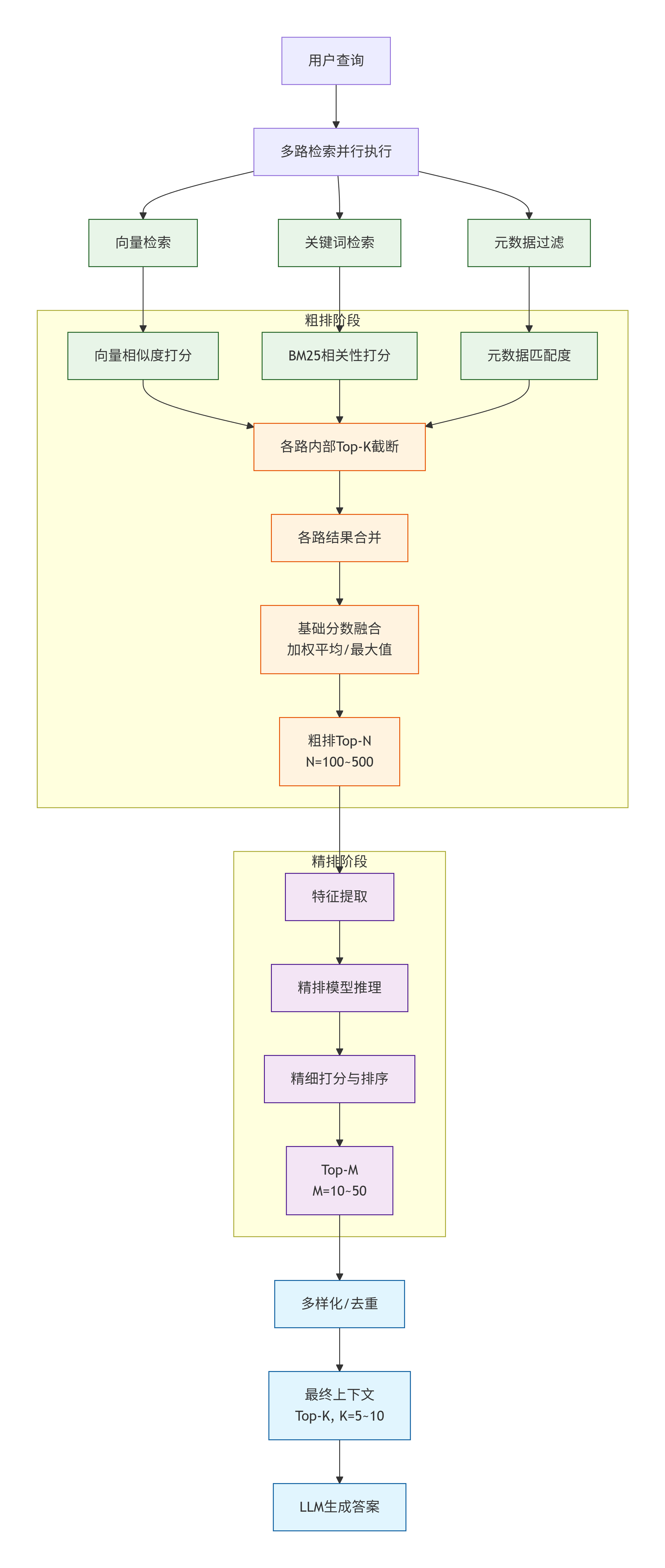
- 什么是召回阶段 :一个过程/阶段,从全量数据中初步筛选候选集 。相当于我们进行多路检索这一步骤的执行阶段。
- 什么是召回率 :召回率是一个评估指标,衡量系统找全的能力。它的核心问题是:"所有真正相关的物品中,系统找回了多少?" 。举例说明 :如果知识库中相关的文档一共有
100份,系统召回80份,且这80份强相关,那么说明当前的召回率是80%,精确率100%;
多路检索优势:
向量检索 :语义理解,找到意思相关的文档
关键词检索 :精确匹配,找到包含特定词汇的文档
元数据过滤:基于属性筛选,如时间、部门、文件类型等
粗排 and 精排
粗排 and精排 :