文章目录
1.整体结构
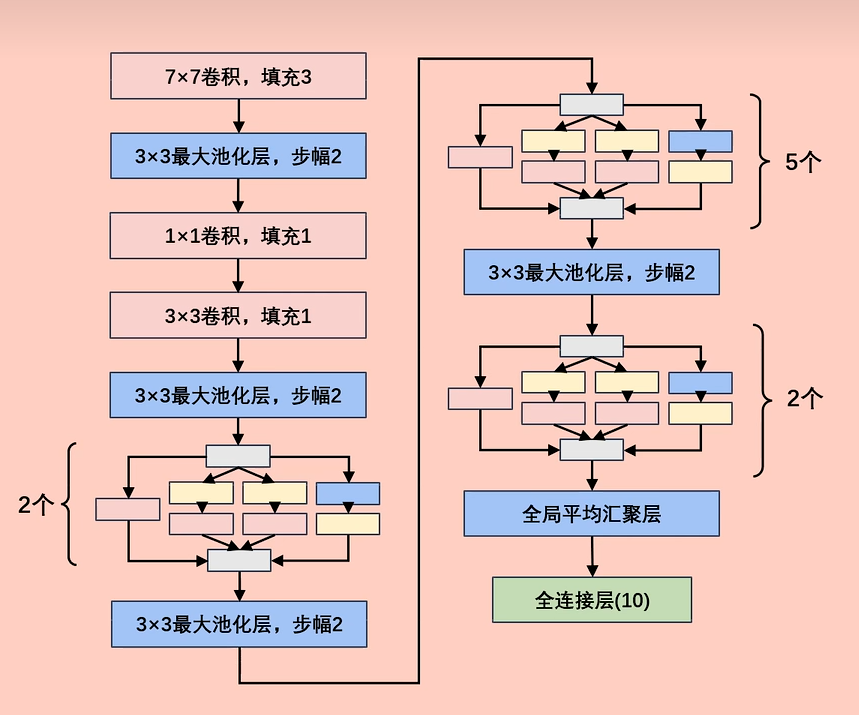
看着很复杂是吧,不要着急,一层层拆解。
2.背景
在2014年的ImageNet图像识别挑战赛中,一个名叫 GoogLeNet 的网络架构大放异彩。以前流行的网络使用
小到1×1,大到7×7的卷积核。本文的一个观点是,有时 使用不同大小的卷积核组合 是有利的。
在GoogLeNet中,基本的卷积块被称为Inception块(Inception block)。这很可能得名于电影《盗梦空间》(Inception),因为电
影中的一句话"我们需要走得更深"("We need to go deeper")。
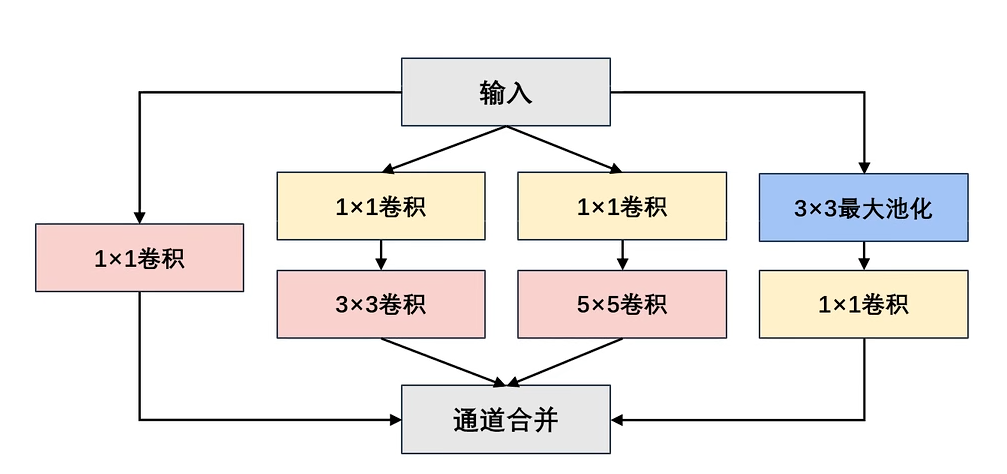
Inception块由四条并行路径组成:
- 前三条路径使用窗口大小为1×1、3×3和5×5的卷积层,从不同空间大小中提取信息。
- 中间的两条路径在输入上执行1×1卷积,以减少通道数(卷积核数量决定),从而降低模型的复杂性。
- 第四条路径使用3×3最大池化层,然后使用1×1卷积层来改变通道数(卷积核数量决定)。
- 这四条路径都使用合适的 填充和步幅 来使输入与输出的高和宽一致(即宽高不变)。
- 最后我们将每条线路的输出在通道维度上连结,并构成Inception块的输出。
- 在Inception块中,通常调整的 超参数 是每层输出通道数。
【举例】:
输入为224×224×3三通道的图像。
路径1:
(1)输入为224×224×3,卷积核数量为64个;卷积核的尺寸大小为1×1×3;步幅为1(stride=1),填充为0(padding=0);卷积后得到shape为224×224×64的特征图输出。
路径2:
(1)输入为224×224×3,卷积核数量为96个;卷积核的尺寸大小为1×1×3;步幅为1(stride=1),填充为0(padding=0);卷积后得到shape为224×224×96的特征图输出。
(2)输入为224×224×96,卷积核数量为128个;卷积核的尺寸大小为3×3×96;步幅为1(stride=1),填充为1(padding=1);卷积后得到shape为224×224×128的特征图输出。
路径3:
(1)输入为224×224×3,卷积核数量为16个;卷积核的尺寸大小为1×1×3;步幅为1(stride=1),填充为0(padding=0);卷积后得到shape为224×224×16的特征图输出。
(2)输入为224×224×16,卷积核数量为32个;卷积核的尺寸大小为5×5×16;步幅为1(stride=1),填充为2(padding=2);卷积后得到shape为224×224×32的特征图输出。
路径4:
(1)输入为224×224×3,池化感受野的尺寸大小为3×3;步幅为1(stride=1),填充为1(padding=1);池化后得到shape为224×224×3的特征图输出。
(2)输入为224×224×3,卷积核数量为32个;卷积核的尺寸大小为1×1×3;步幅为1(stride=1),填充为0(padding=0);卷积后得到shape为224×224×32的特征图输出。
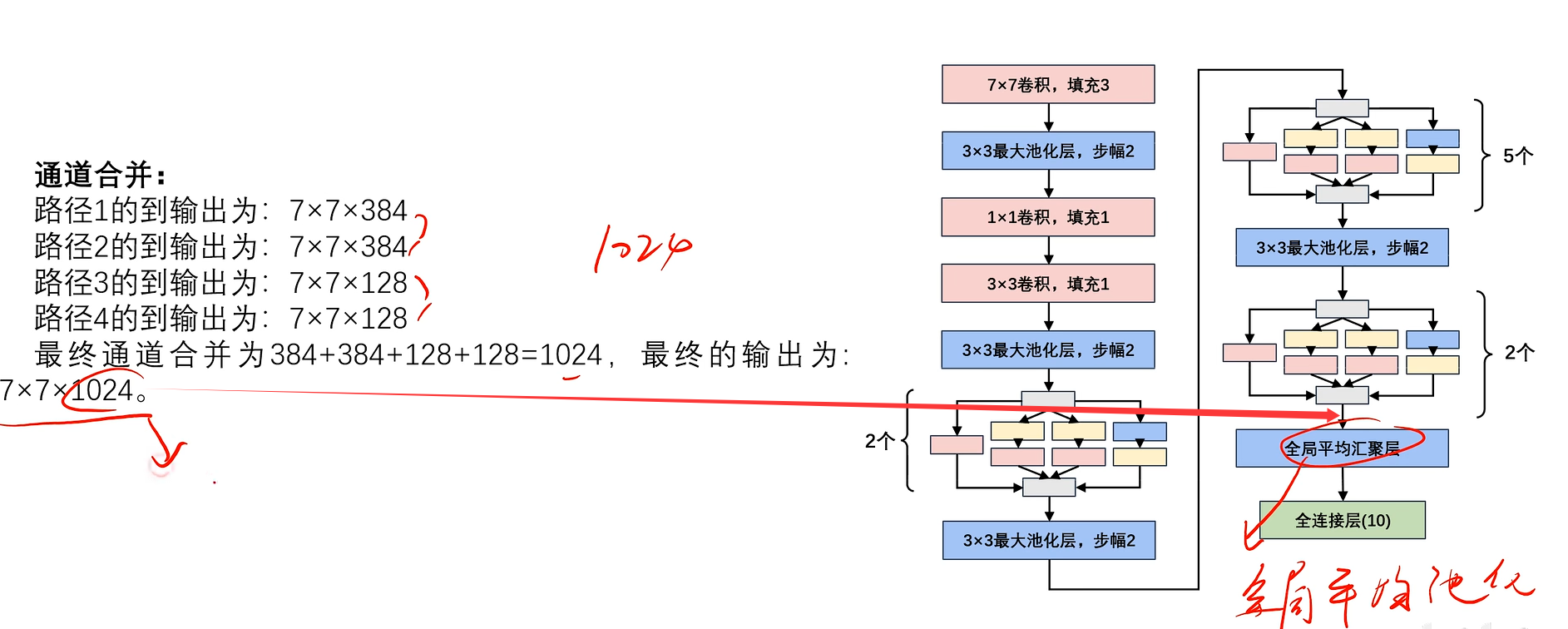
通道合并:
路径1的到输出为:224×224×64
路径2的到输出为:224×224×128
路径3的到输出为:224×224×32
路径4的到输出为:224×224×32
最终通道合并为64+128+32+32=256,最终的输出为:224×224×256。
那么为什么GoogLeNet这个网络如此有效呢?
首先我们考虑一下滤波器(filter)(指的是卷积核)的组合,它们可以用各种滤波器尺寸(不同尺寸的卷积核)探索图像,这意味着不同大小的滤波器可以有效地识别不同范围的图像细节。同时,我们可以为不同的滤波器分配不同数量的参数。
3.大小为1×1卷积核的优点
本节的内容讲的太勉强,不够有说服力,感兴趣的去看看原视频。
- 实现跨通道的交互和信息整合(其他尺寸卷积核也有该效果)
- 卷积核通道数的降维和升维,减少网络参数
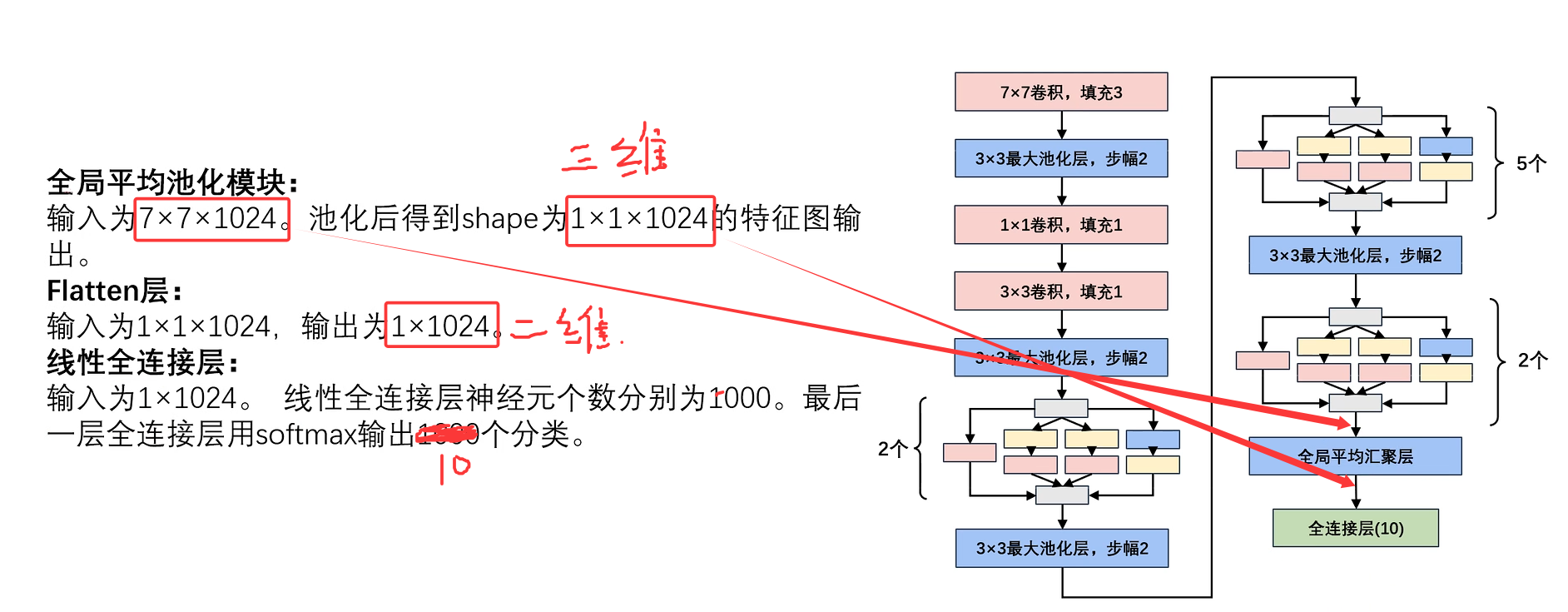
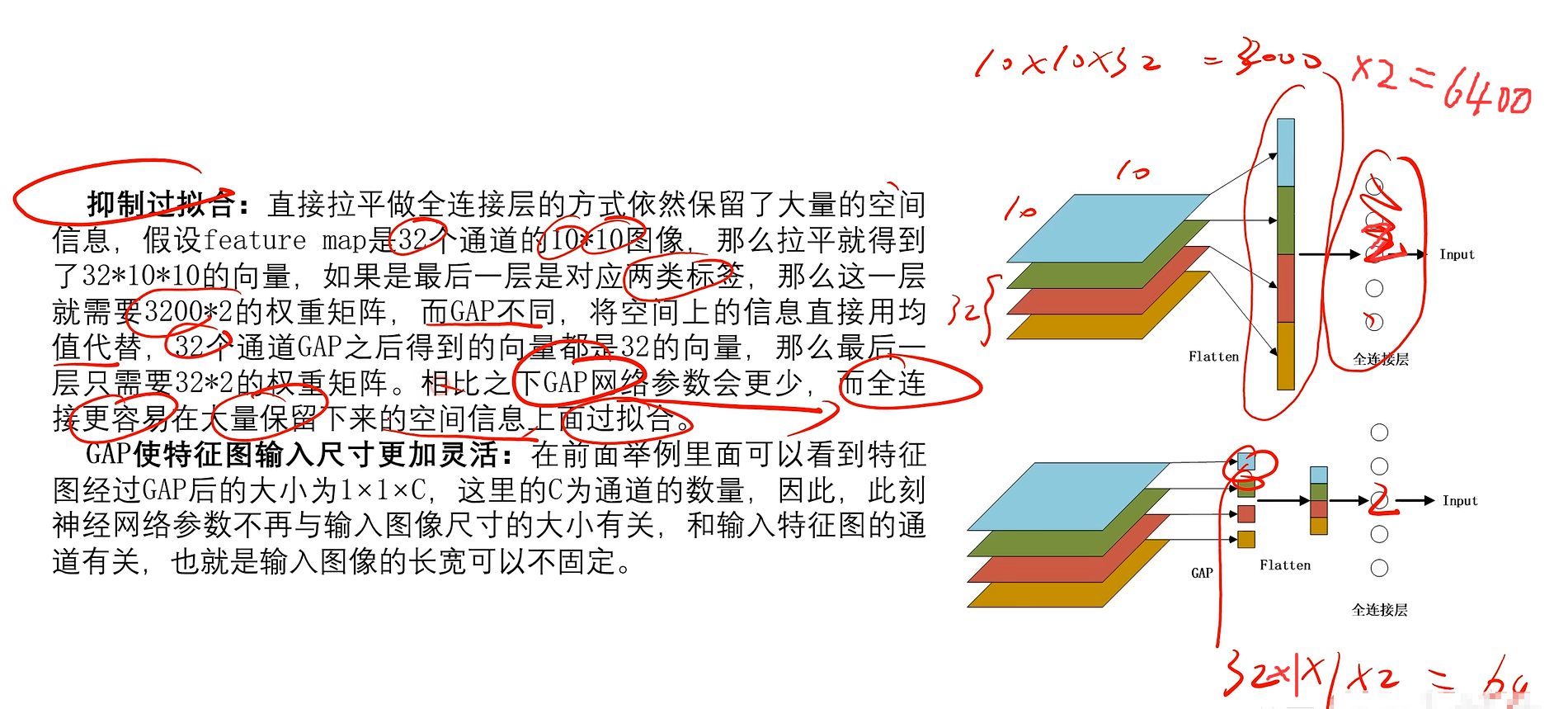
4.全局平均池化层GAP
4.1优点
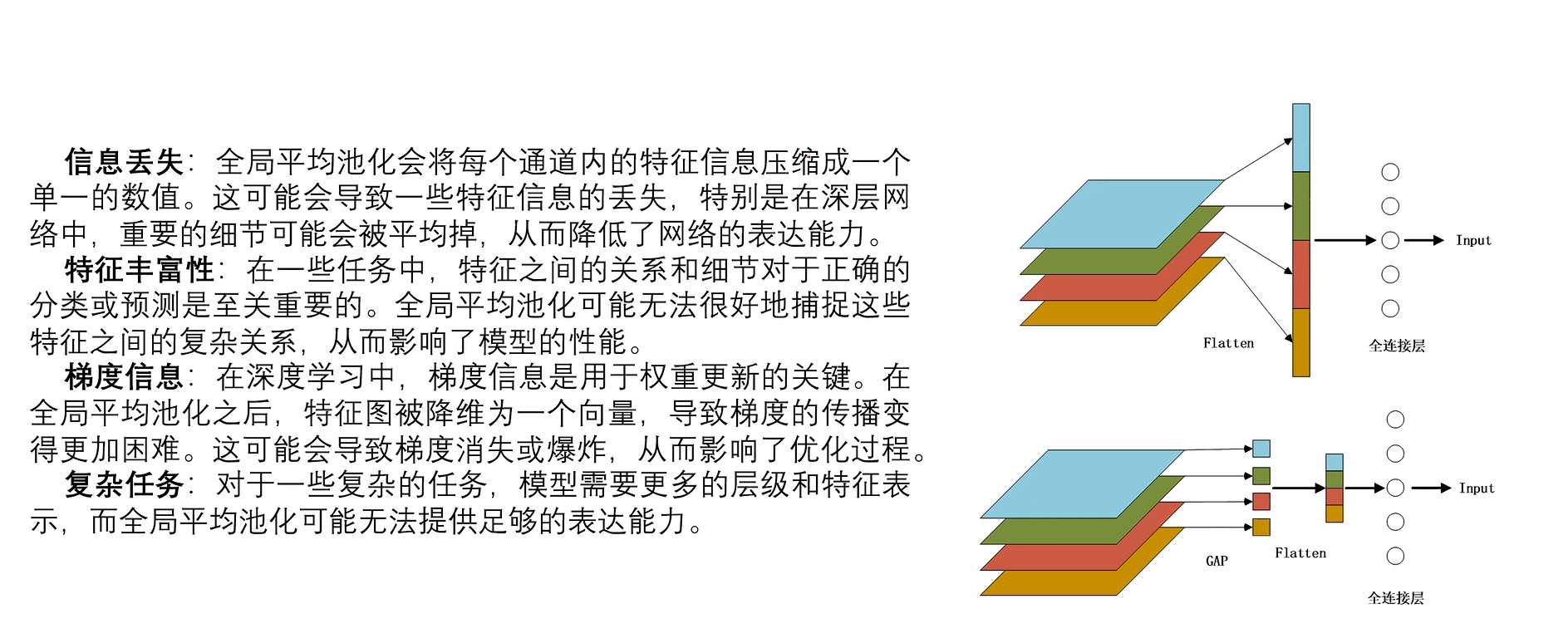
4.2缺点
5.网络参数详解
注意: 根据公式计算输出图大小时,Pytorch是 向下取整。
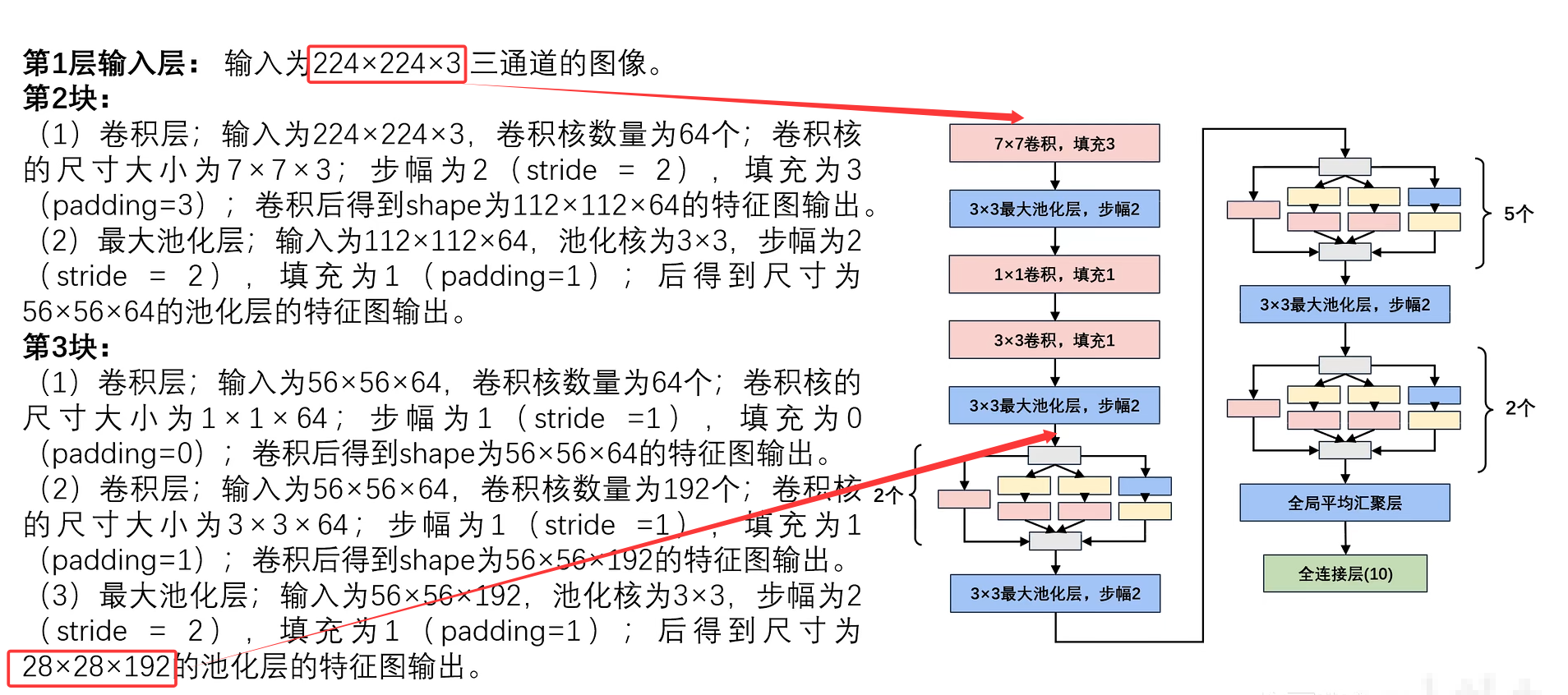
Inception块只改变输入特征图的通道数,不改变其大小
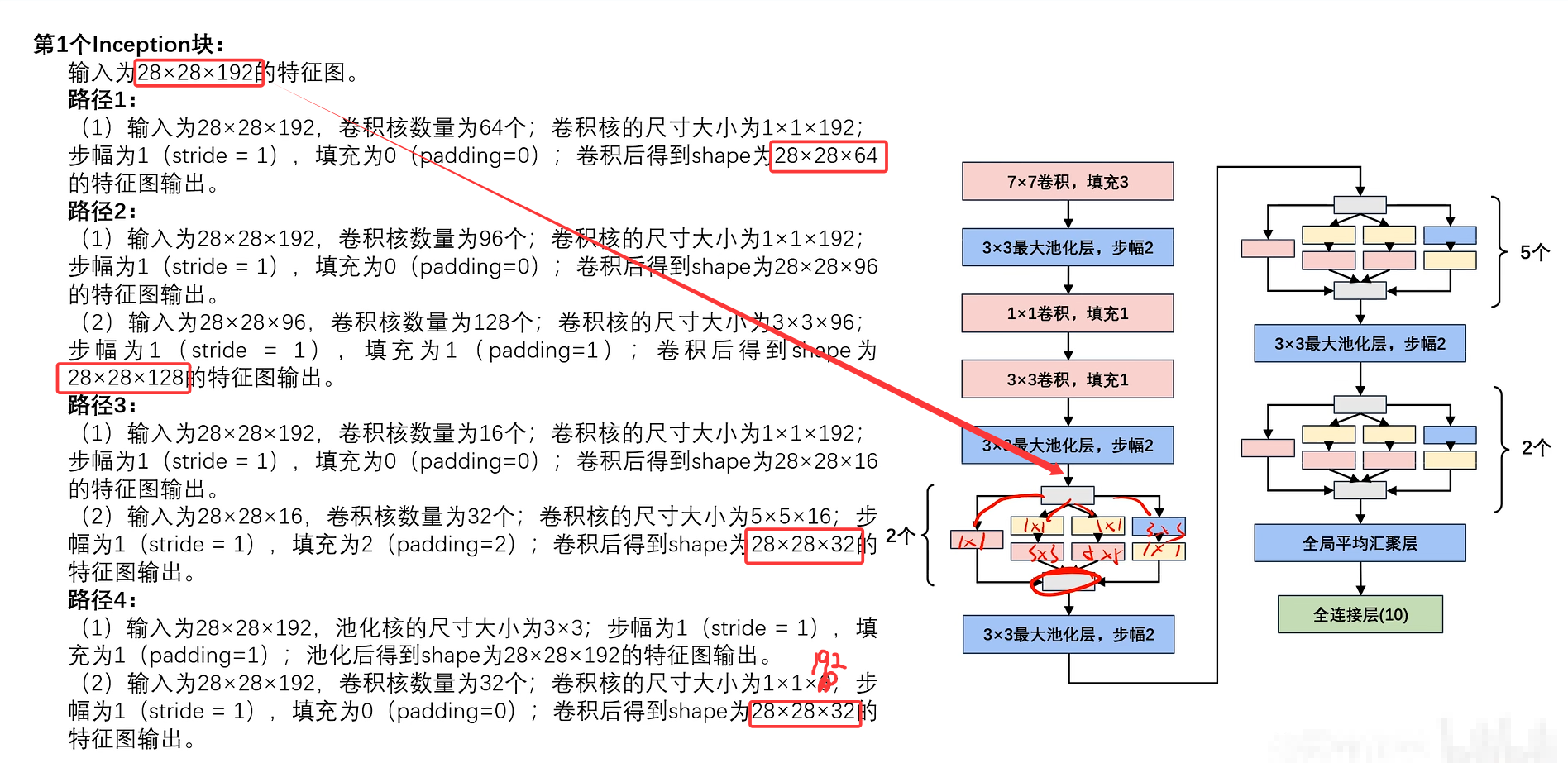
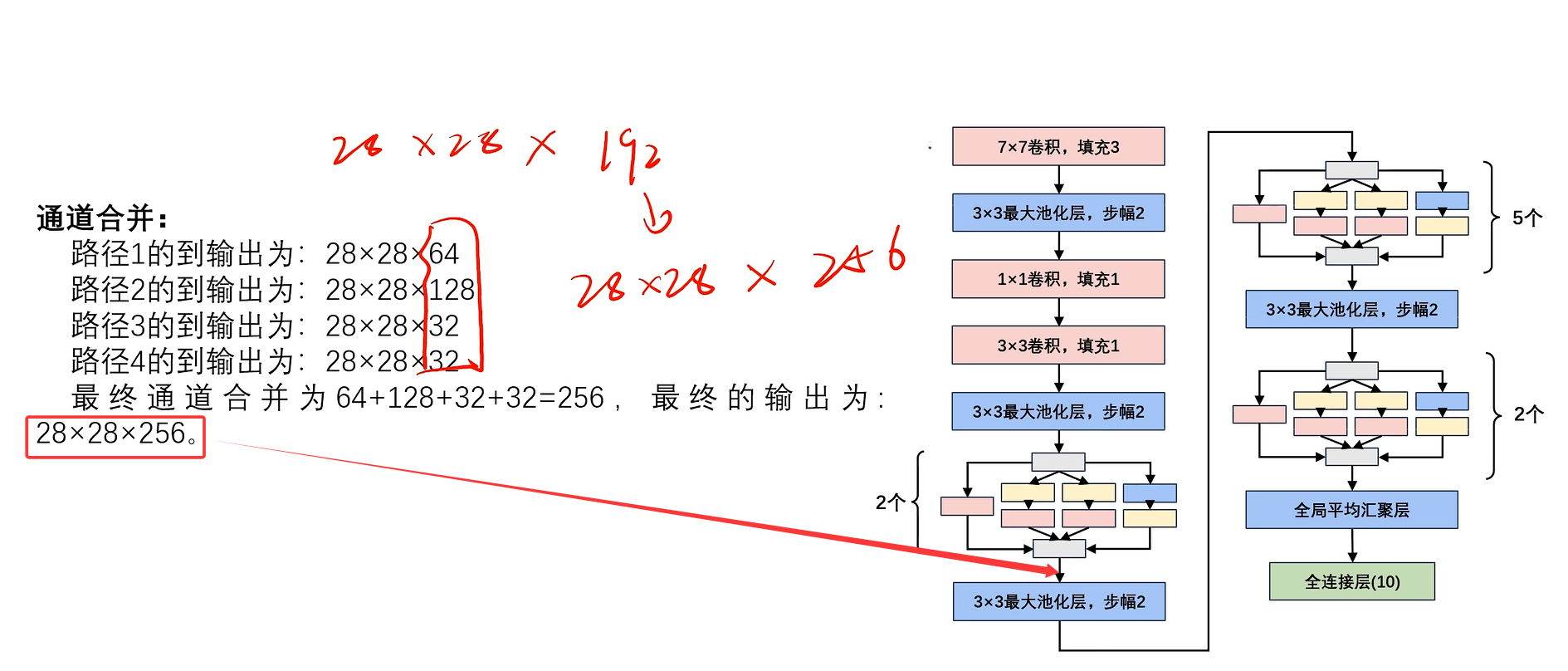
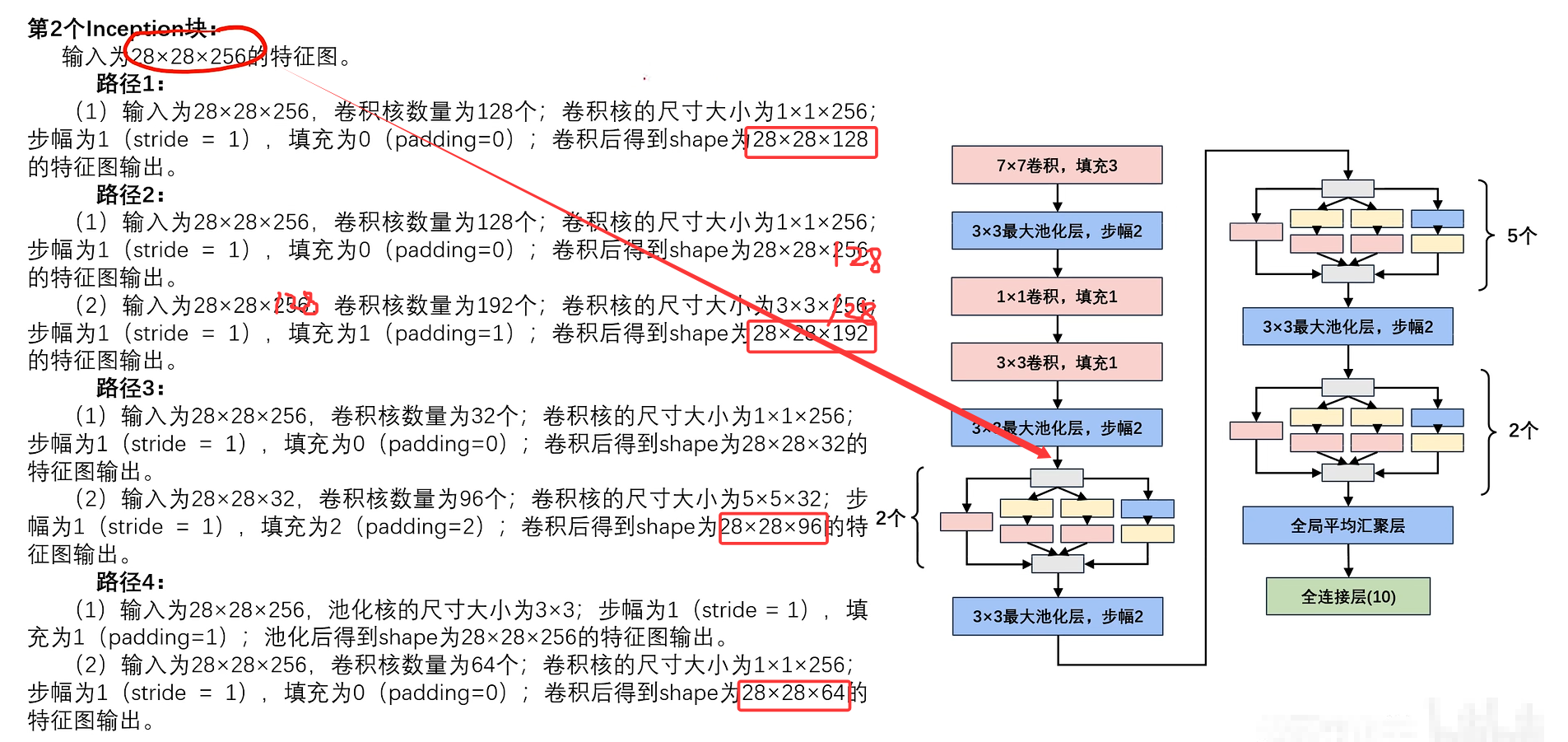
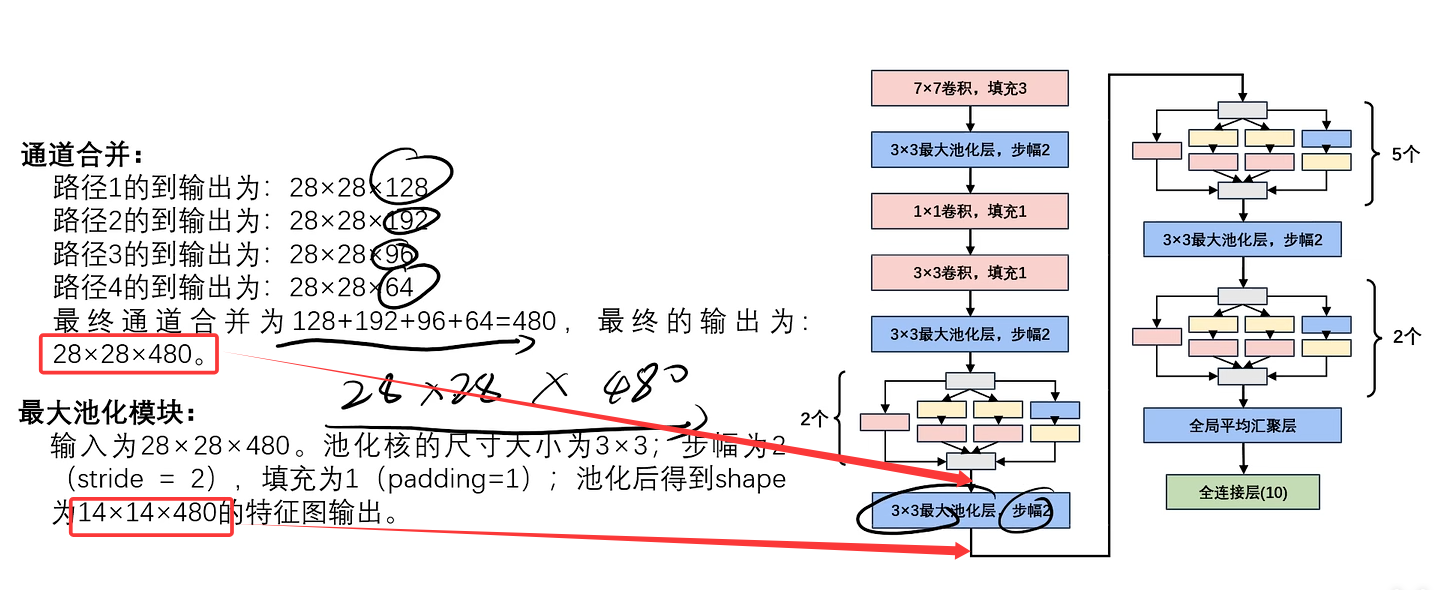
此处省略5个Inception块的计算,只给出最终结果。(计算逻辑都一样)
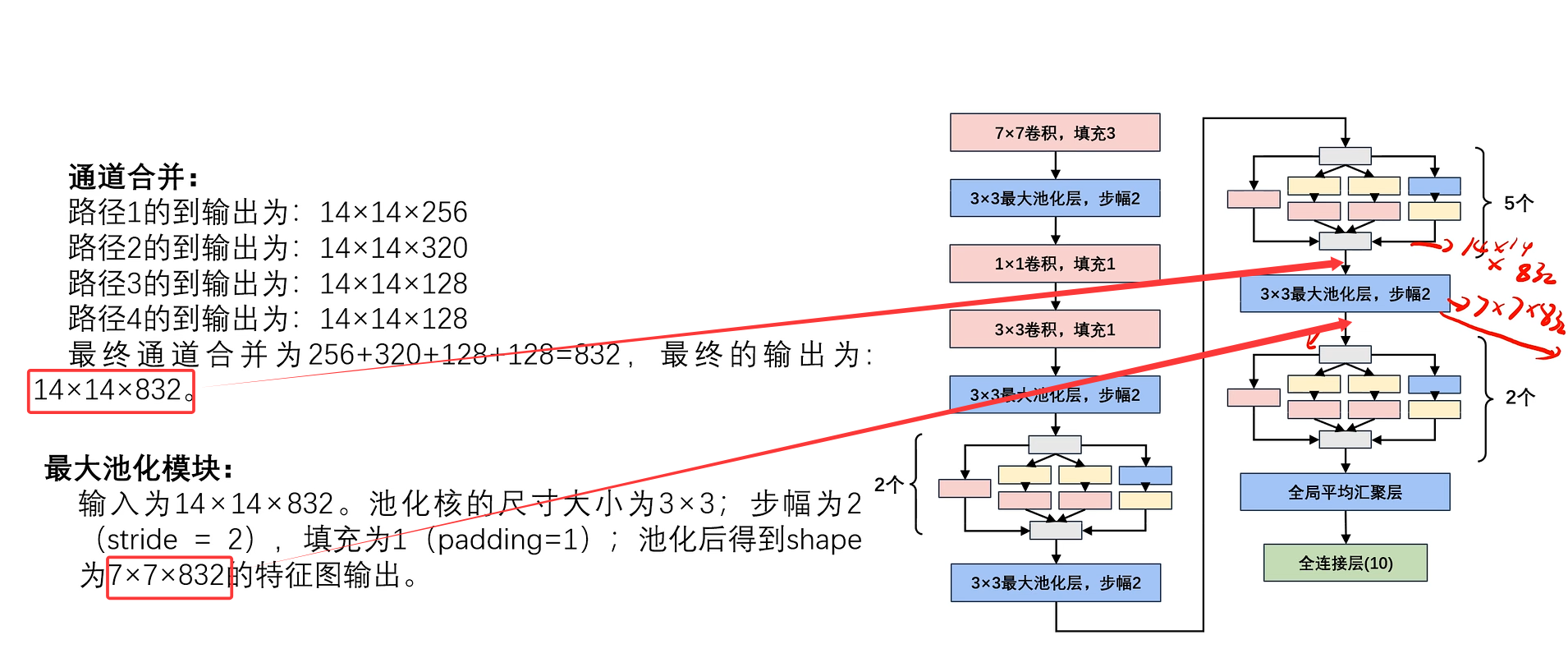
此处省略2个Inception块的计算,只给出最终结果。(计算逻辑都一样)