
CVPR-2018
github:https://github.com/JiaRenChang/PSMNet
文章目录
- [1、Background and Motivation](#1、Background and Motivation)
- [2、Related Work](#2、Related Work)
- [3、Advantages / Contributions](#3、Advantages / Contributions)
- 4、Method
-
- [4.1、Network Architecture](#4.1、Network Architecture)
- [4.2、Spatial Pramid Pooling Module](#4.2、Spatial Pramid Pooling Module)
- [4.3、Cost Volume](#4.3、Cost Volume)
- [4.4、3D CNN](#4.4、3D CNN)
- [4.5、Disparit Regression](#4.5、Disparit Regression)
- 4.6、Loss
- 5、Experiments
-
- [5.1、Datasets and Metrics](#5.1、Datasets and Metrics)
- 5.2、KITTI2015
- [5.3、Scene Flow](#5.3、Scene Flow)
- [5.4、KITTI 2012](#5.4、KITTI 2012)
- [6、Conclusion(own) / Future work](#6、Conclusion(own) / Future work)
1、Background and Motivation
立体匹配是计算机视觉中的核心任务之一,旨在通过分析一对校正后的立体图像来估计场景的深度信息。在自动驾驶、机器人导航、三维重建和目标检测等应用中具有至关重要的作用。
传统的立体匹配方法通常包括匹配代价计算(matching cost computation)、代价聚合(cost aggregation)、视差优化(disparity optimization)和后处理(disparity refinement)四个步骤
ill-posed regions
- occlusion areas
- repeated patterns
- textureless regions
- reflective surfaces
随着深度学习的发展,基于卷积神经网络(CNN)的立体匹配方法逐渐成为主流,它们能够通过学习特征表示和匹配函数来提高匹配的准确性
这些方法在 ill-posed regions 往往效果不佳。作者提出 pyramid stereo matching network(PSMNet),利用 SPP 来强化网络的 global context information,用 stacked hourglass 3D CNN 来 regularize cost volume
2、Related Work
传统方法 4 步曲,
SOTA 的方法 focus on how to accurately compute the matching cost using CNNs
Some studies focus on the post-processing
Recently, end-to-end networks(incorporate context information to reduce mismatch)
- 分割领域,获取 global context 的方法有 SPP 和 encoder-decoder architecture
- SPyNet introduces image pyramids to estimate optical flow in a coarse-to-fine approach
Luo W, Schwing A G, Urtasun R. Efficient deep learning for stereo matchingC//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 5695-5703.
computation of matching costs is treated as a multi-label classification
SPyNet
Ranjan A, Black M J. Optical flow estimation using a spatial pyramid networkC//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 4161-4170.
本文作者用 SPP 和 stacked hourglass(encoder-decoder) 来强化 global context information
3、Advantages / Contributions
- 提出了 end-to-end learning framework(PSMNet ) for stereo matching ,用 Spatial pyramid pooling(SPP ) 提取 global context information,用 stacked hourglass 3D CNN 去 regularize the cost volume(也强化了 global context information)
- ranked first in the KITTI 2012 and 2015 leaderboards before March 18, 2018
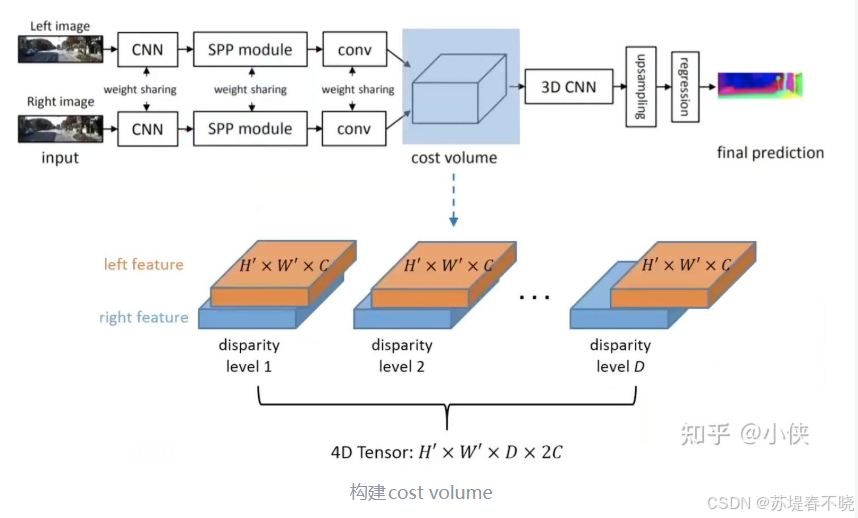
4、Method
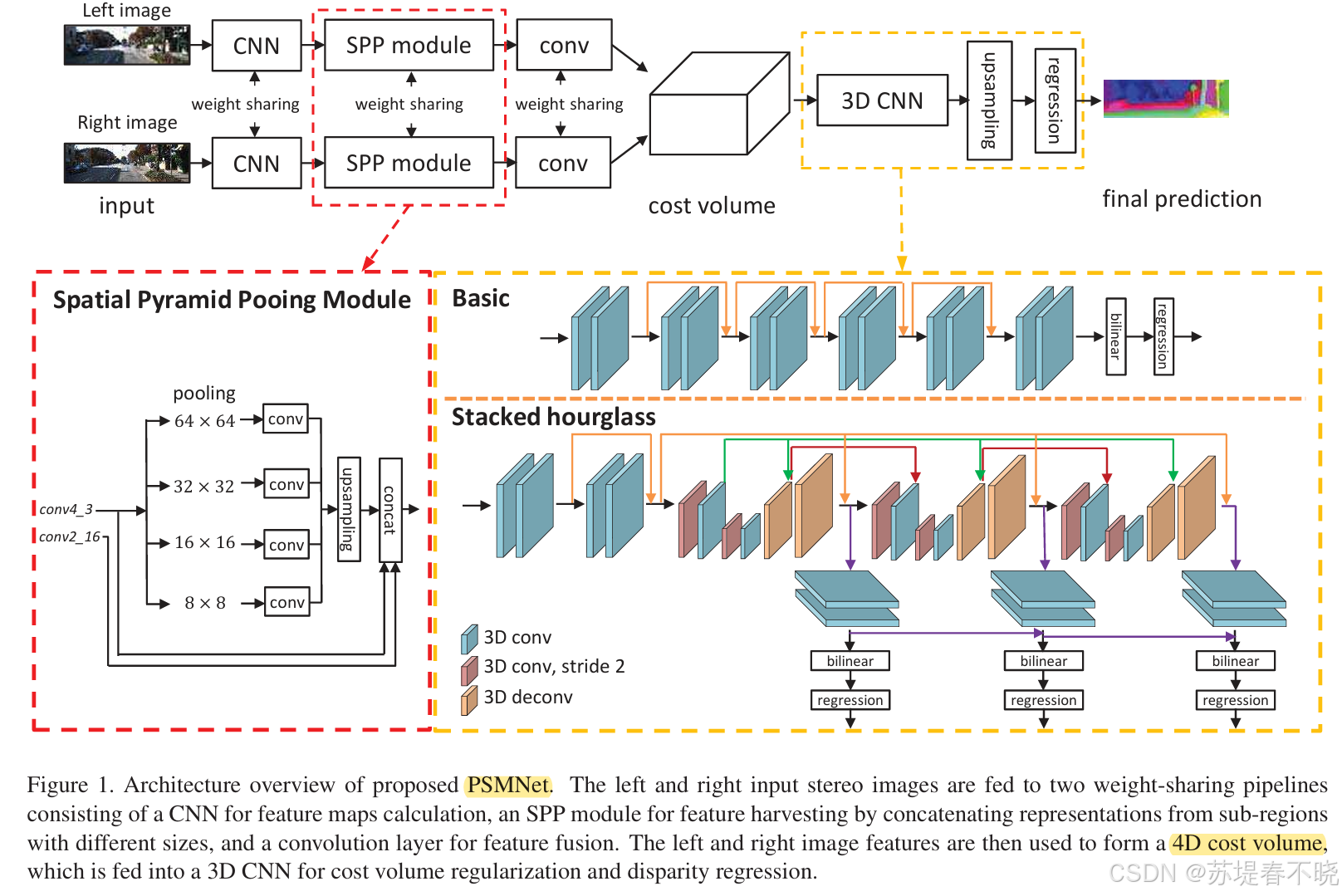
SPP,multi-scale context aggregation
concatenate the left and right feature maps into a cost volume(暴力)
stacked hourglass
4.1、Network Architecture
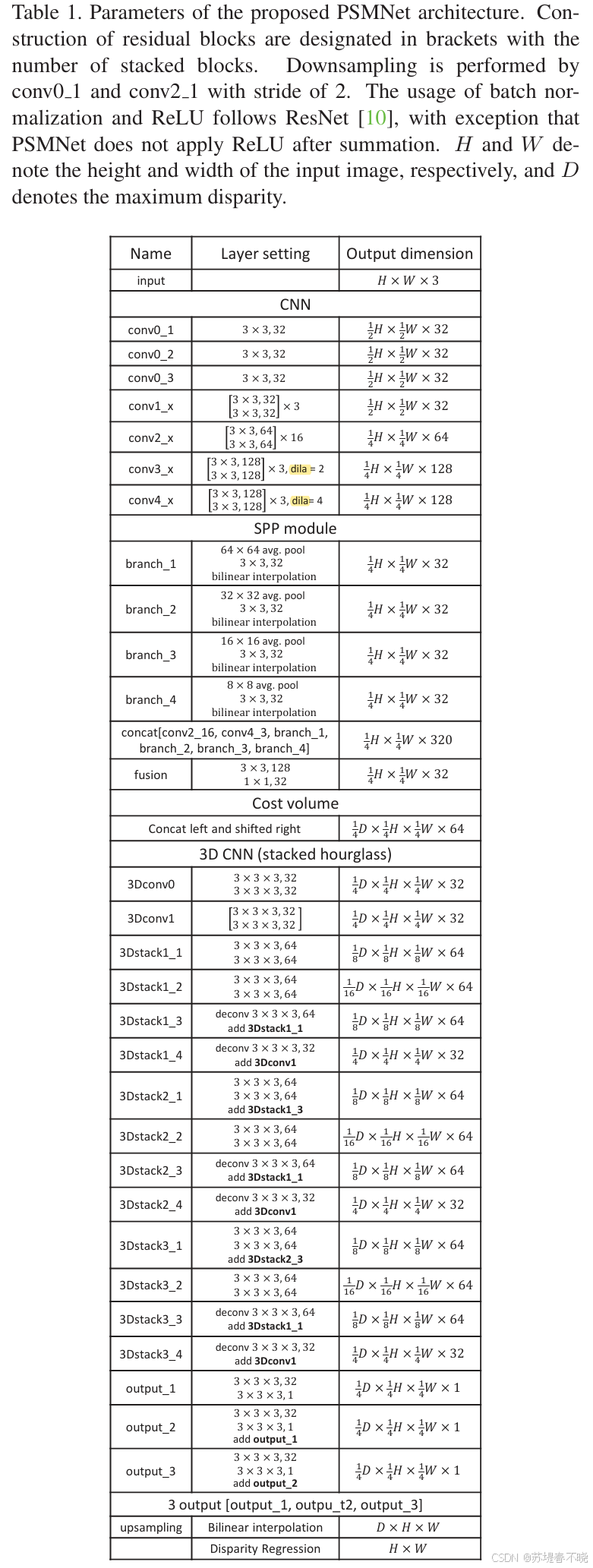
基础部件是 basic residual blocks
conv3 和 conv4 还引入了 dilated conv
有 3 个输出
4.2、Spatial Pramid Pooling Module
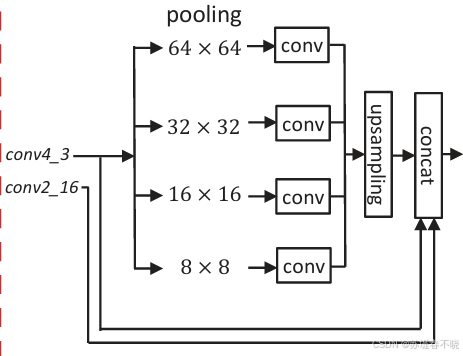
1 × 1 convolution
the relationship between an object (for example,a car) and its sub-regions (windows, tires, hoods, etc.) is learned by the SPP module to incorporate hierarchical context information.
car vs 窗户、轮胎、引擎盖
4.3、Cost Volume
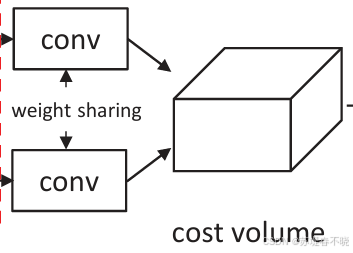
直接 concatenating 的
4D volume (height × width × disparity × feature size)
4.4、3D CNN
two kinds of 3D CNN architectures for cost volume regularization
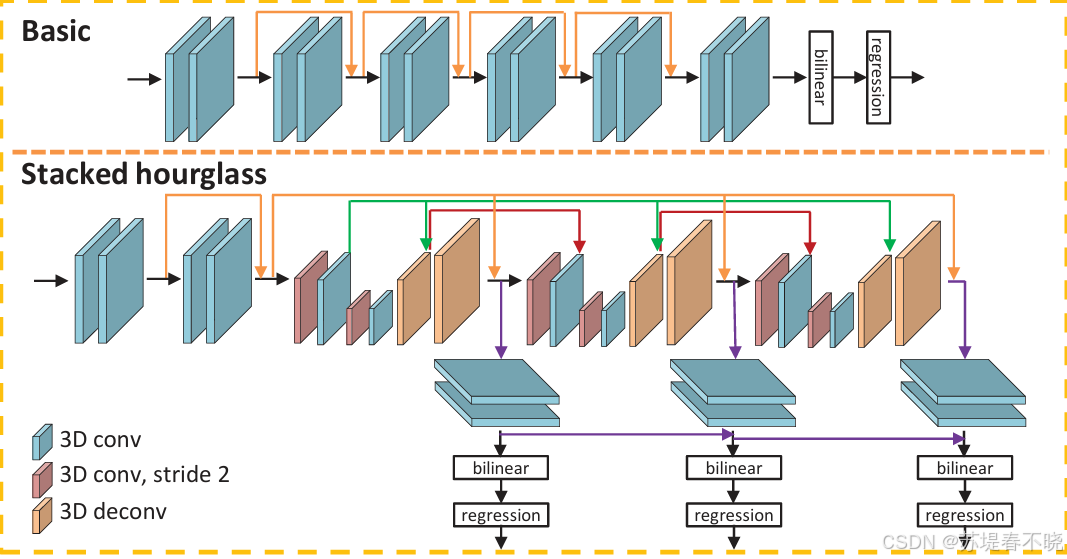
built using residual blocks
three main hourglass
three outputs and losses (Loss 1, Loss 2, and Loss 3).
测试的时候用最后一个输出视差图( final disparity map is the last of three outputs)
上图中 Basic 结构用于消融 SPP 用的,因为 Basic 结构不是专门用来强化 global context information 的

4.5、Disparit Regression
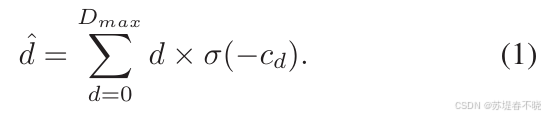
σ \sigma σ 是 softmax
disparity regression is more robust than classification-based
python
cost = F.upsample(cost, [self.maxdisp,left.size()[2],left.size()[3]], mode='trilinear')
cost = torch.squeeze(cost,1)
pred = F.softmax(cost)
pred = disparityregression(self.maxdisp)(pred)其中 disparityregression 的实现如下
python
class disparityregression(nn.Module):
def __init__(self, maxdisp):
super(disparityregression, self).__init__()
self.disp = torch.Tensor(np.reshape(np.array(range(maxdisp)),[1, maxdisp,1,1])).cuda()
def forward(self, x):
out = torch.sum(x*self.disp.data,1, keepdim=True)
return out公式里面有个负号,代码里面好像没有,负号的含义
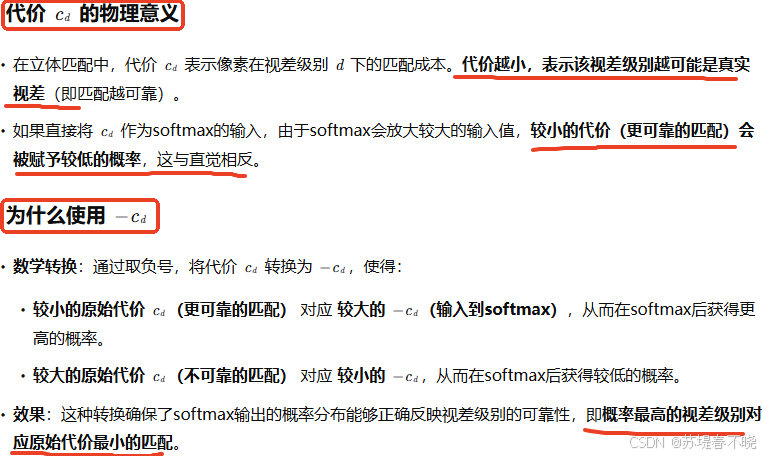
类似于 conv?其实是相关,哈哈哈
网络中 softmax 后的概率峰值位置应与实际中最小代价对应的视差一致
softmax 前的不对应,哈哈哈
4.6、Loss
回归任务采用的常规的 smooth L1

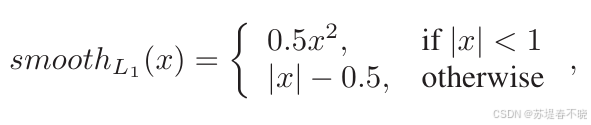
优势 low sensitivity to outliers
5、Experiments
5.1、Datasets and Metrics
数据集
- Scene Flow, 35454 training and 4370 testing
- KITTI2012,H=376,W=1240,194 train 195 test,train split 160 and 34 for train and val
- KITTI2015,H=376,W=1240,200 train 200 test,train split 80% and 20% for train and val
评价指标
- EPE
- D1-bg
- D1-fg
- D1-all
5.2、KITTI2015
(1) Ablation study for PSMNet

在 val 数据集上做的实验
看下来 dilated conv 提点最明显
pooling with more levels works better
引入 stacked hourglass 后效果进一步提升
(2)Ablation study for Loss Weight
在 val 数据集上做的实验
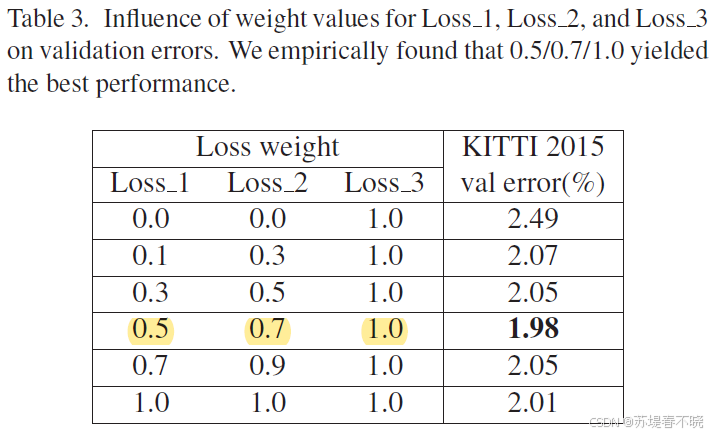
(3)Results on Leaderboard
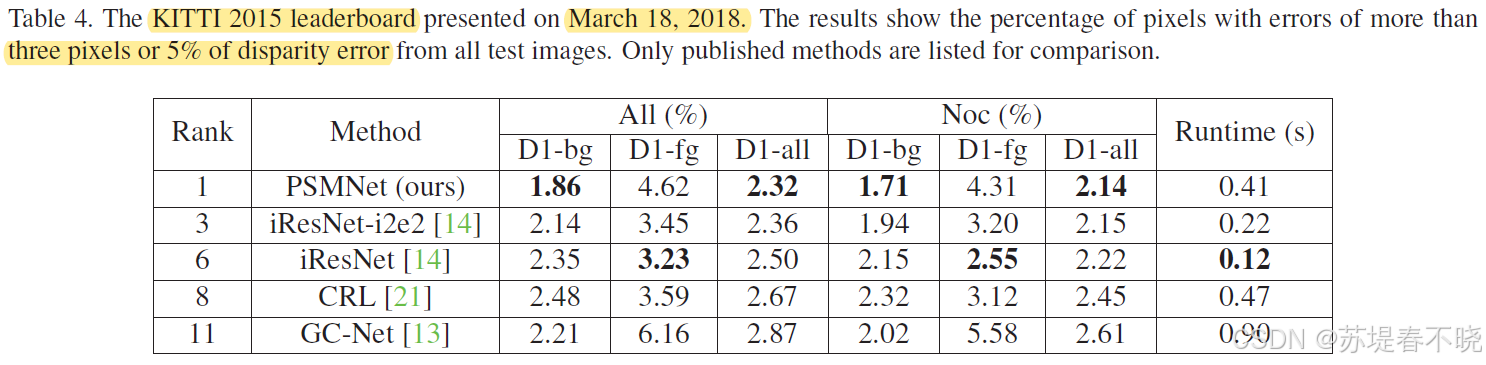
排名第一
(4)Qualitative evaluation

黄色箭头所指区域作者的方法优势明显,第二行和第四行是 error maps,越红表示误差越大
5.3、Scene Flow
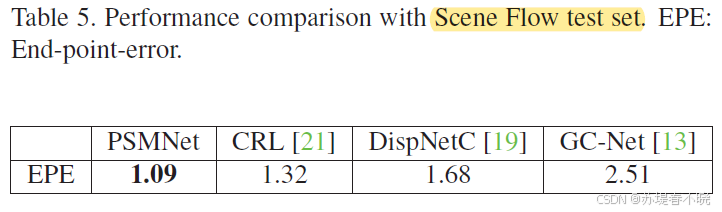

5.4、KITTI 2012
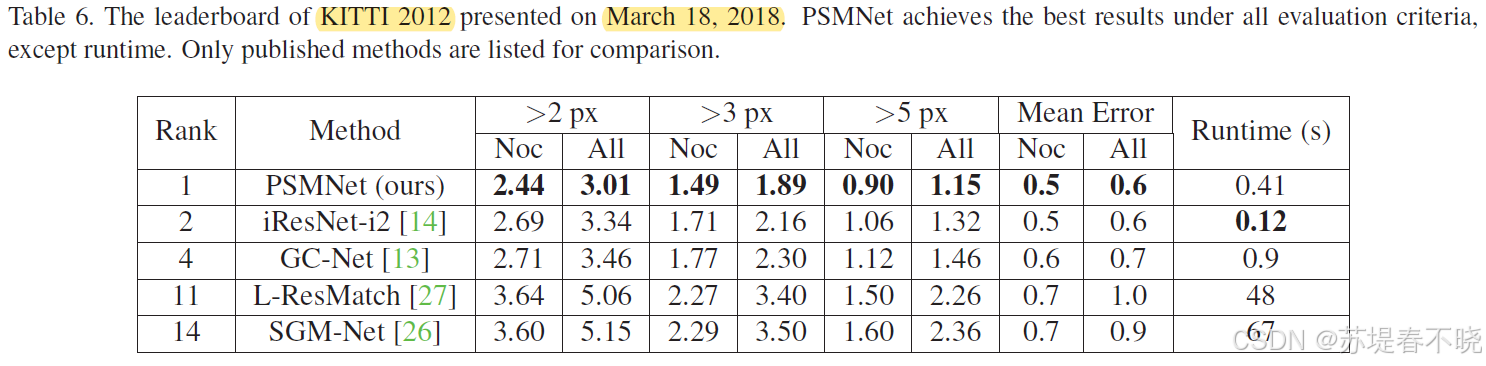
也是排名第一

第二行和第四行也是 error map,越亮表示 error 越大,作者的方法白色比较少
6、Conclusion(own) / Future work
- 借鉴分割任务的思想,在 stereo matching 任务中引入 spp 和 encoder-decoder(hourglass net) 结构来强化 global context information
- disparity regression is more robust than classification-based
- 网络中的 cost volume 接 softmax才表示真实的 cost volume
- 创新点一般般,效果比较好,讲的故事和给出的例子逻辑上也没有很顺畅吧,例子可以挑一些更有代表性的
-
-
-
-
-


 -
- 

更多论文解读,请参考 【Paper Reading】