在实际项目中,我们常常会遇到这样的场景:
-
业务数据在 MySQL
-
日志 / 时序数据在 TDengine
-
报表数据在 PostgreSQL
-
部分历史数据在 Oracle
这时,你并不希望它们"互相切换",而是:
不同的业务 → 使用不同的数据库
不同的模块 → 绑定不同的数据源
这种模式,我们称之为:
多数据源并存
注意,不是:读写分离、动态切换、主从切换
动态数据源可以看看这篇:
一、什么是「多数据源并存」?
核心思想只有一句话:
我不切换数据源,我只是同时拥有多个 DataSource,每一个都明确对应自己的 Mapper / SqlSessionFactory / 事务管理器。
在代码里表现为:
java
@Resource(name = "mysqlDataSource")
private DataSource mysqlDataSource;
@Resource(name = "tdengineDataSource")
private DataSource tdengineDataSource;其核心特点是:
-
同时存在多个 DataSource Bean
-
每个 DataSource 有自己的配置
-
每个 DataSource 对应自己的 Mapper / Dao / Service
-
不使用 AbstractRoutingDataSource
-
不需要 ThreadLocal 切换
-
不互相影响
-
各自为政
-
使用起来一模一样
二、适合使用多数据源并存的场景
多数据源并存非常适合这类情况:
✅ 不同数据库类型:
-
MySQL + TDengine
-
MySQL + Oracle
-
MySQL + MongoDB
✅ 职责不同:
-
一个是业务库
-
一个是日志库
-
一个是时序库
-
一个是分析库
✅ 不存在「切换依赖关系」
-
不需要主从切换
-
不需要读写分离
-
不需要租户隔离
比如现在要设计一个无人机轨迹的数据库,时序数据一天百万,如果使用MySQL,没几天就炸了。那我们现在就要引入时序数据库。
那我们现在已经引入了两个数据库:
| 数据源 | 用途 | 名称 |
|---|---|---|
| MySQL | 业务核心数据 | mysqlDataSource |
| TDengine | 时序/日志/设备轨迹 | tdengineDataSource |
我们要做到:
-
MySQL 有自己的一套 Mapper
-
TDengine 有自己的一套 Mapper
-
配置互不干扰
-
使用方式极其统一
三、配置两个数据源
我这里是用Druid,
java
spring:
# 配置数据源
datasource:
# 1. MySQL 数据源(存业务元数据)
mysql:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.112.58:3306/uav-safety?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowMultiQueries=true&rewriteBatchedStatements=true
username: root
password: root
type: com.alibaba.druid.pool.DruidDataSource
# 连接池配置
initialSize: 10
min-idle: 5
max-active: 20
max-wait: 60000
time-between-eviction-runs-millis: 60000
min-evictable-idle-time-millis: 300000
validation-query: SELECT 1
testWhileIdle: true
pool-prepared-statements: true
max-pool-prepared-statement-per-connection-size: 20
# 配置监控统计拦截的filters
filters: stat,wall,slf4j
# 2. TDengine 数据源(时序库)
tdengine:
driver-class-name: com.taosdata.jdbc.rs.RestfulDriver
url: jdbc:TAOS-RS://192.168.112.58:6041/uav_safety?useSSL=false
username: root
password: taosdata
type: com.alibaba.druid.pool.DruidDataSource
# 连接池配置
initialSize: 7
minIdle: 5
maxActive: 20
maxWait: 60000
time-between-eviction-runs-millis: 60000
min-evictable-idle-time-millis: 300000
validationQuery: SELECT 1
testWhileIdle: true
pool-prepared-statements: true
max-pool-prepared-statement-per-connection-size: 50
# 配置监控统计拦截的filters
filters: stat四、创建 MySQL 数据源配置
java
@Configuration
@MapperScan(
basePackages = "com.za.uav.mapper.mysql",
sqlSessionFactoryRef = "mysqlSqlSessionFactory"
)
public class MysqlDataSourceConfig {
@Bean(name = "mysqlDataSource")
@ConfigurationProperties(prefix = "spring.datasource.mysql")
public DataSource mysqlDataSource() {
return new com.alibaba.druid.pool.DruidDataSource();
}
@Bean(name = "mysqlSqlSessionFactory")
public SqlSessionFactory mysqlSqlSessionFactory(
@Qualifier("mysqlDataSource") DataSource dataSource
) throws Exception {
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setDataSource(dataSource);
return bean.getObject();
}
@Bean(name = "mysqlTransactionManager")
public DataSourceTransactionManager mysqlTransactionManager(
@Qualifier("mysqlDataSource") DataSource dataSource
) {
return new DataSourceTransactionManager(dataSource);
}
}注意点:
-
@MapperScan 扫描的是: com.za.uav.mapper.mysql
-
所有属于 MySQL 的 mapper 都必须放进这个包
-
ConfigurationProperties配置好之后,它会自己读取Druid的配置
五、 TDengine 数据源配置类
java
@Configuration
@MapperScan(
basePackages = "com.za.uav.mapper.tdengine",
sqlSessionFactoryRef = "tdengineSqlSessionFactory"
)
public class TdengineDataSourceConfig {
@Bean(name = "tdengineDataSource")
@ConfigurationProperties(prefix = "spring.datasource.tdengine")
public DataSource tdengineDataSource() {
return new com.alibaba.druid.pool.DruidDataSource();
}
@Bean(name = "tdengineSqlSessionFactory")
public SqlSessionFactory tdengineSqlSessionFactory(
@Qualifier("tdengineDataSource") DataSource dataSource
) throws Exception {
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setDataSource(dataSource);
return bean.getObject();
}
}重点:
✅ 包名区分
✅ Bean 名称区分
到这里,多数据源就已经正确并存了。
六、事务管理器
!!有个重点
这里我们不需要TdEngine的事务管理器,所以就不创建bean了。
但是这个问题很严重,所以专门拉一个出来写一下。
我们一般单数据源的时候,事务管理器只会有一个。所以我们事务用这个 @Transactional 就贼方便。
但如果你的系统中有多个事务管理器,在使用的时候必须显式指定事务管理器
比如MySQL的:
java
@Transactional(transactionManager = "mysqlTransactionManager", rollbackFor = Exception.class)
public void saveMysql() {
mysqlMapper.insert(data);
}TDengine的:
java
@Transactional(transactionManager = "tdengineTransactionManager", rollbackFor = Exception.class)
public void saveTd() {
tdMapper.insert(data);
}这个一定要有个肌肉记忆。事务可开不得玩笑。
如果你是项目负责人,可以立一条项目规则:只要是 Service 里写 @Transactional,不写 transactionManager = xxx 一律算 BUG。
6.2 便捷方式
因为很麻烦,所以其实可以自定义注解,比如我们现在可以分成:
java
@MysqlTx
public void saveUser(){...}
@TdTx
public void saveRecord(){...}那我们要做的就是------包一层自己的注解进去:
java
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Transactional(
transactionManager = "mysqlTransactionManager",
rollbackFor = Exception.class
)
@Documented
public @interface MysqlTx {
}也就是说:
✅ 我们只是给 @Transactional 起了一个「有语义的别名」
TDengine同理。就很方便了。
6.3 如果一个方法要操作两个数据库怎么办?
java
public void saveAll(){
mysqlMapper.insert(...);
tdMapper.insert(...);
}我们业务经常要操作两个库,那这时候就有问题了。因为@Transactional 一次只能绑定一个事务管理器,所以如果异常了,只会保证:
✅ MySQL 可回滚
❌ TDengine 不在这个事务里,不回滚。
反过来也是一样。
那一般这种情况我们常用的就是业务补偿了:
java
@Transactional(transactionManager = "mysqlTransactionManager")
public void process() {
mysqlMapper.insert(order);
try {
tdMapper.insert(log);
} catch (Exception e) {
// 自行补偿(删 MySQL 或记录异常单)
mysqlMapper.deleteById(order.getId());
throw e;
}
}七、MapperScan
这个跟事务差不多重要。@Mapper 注解就不要用了:
注册Bean的方式 换成MapperScan:
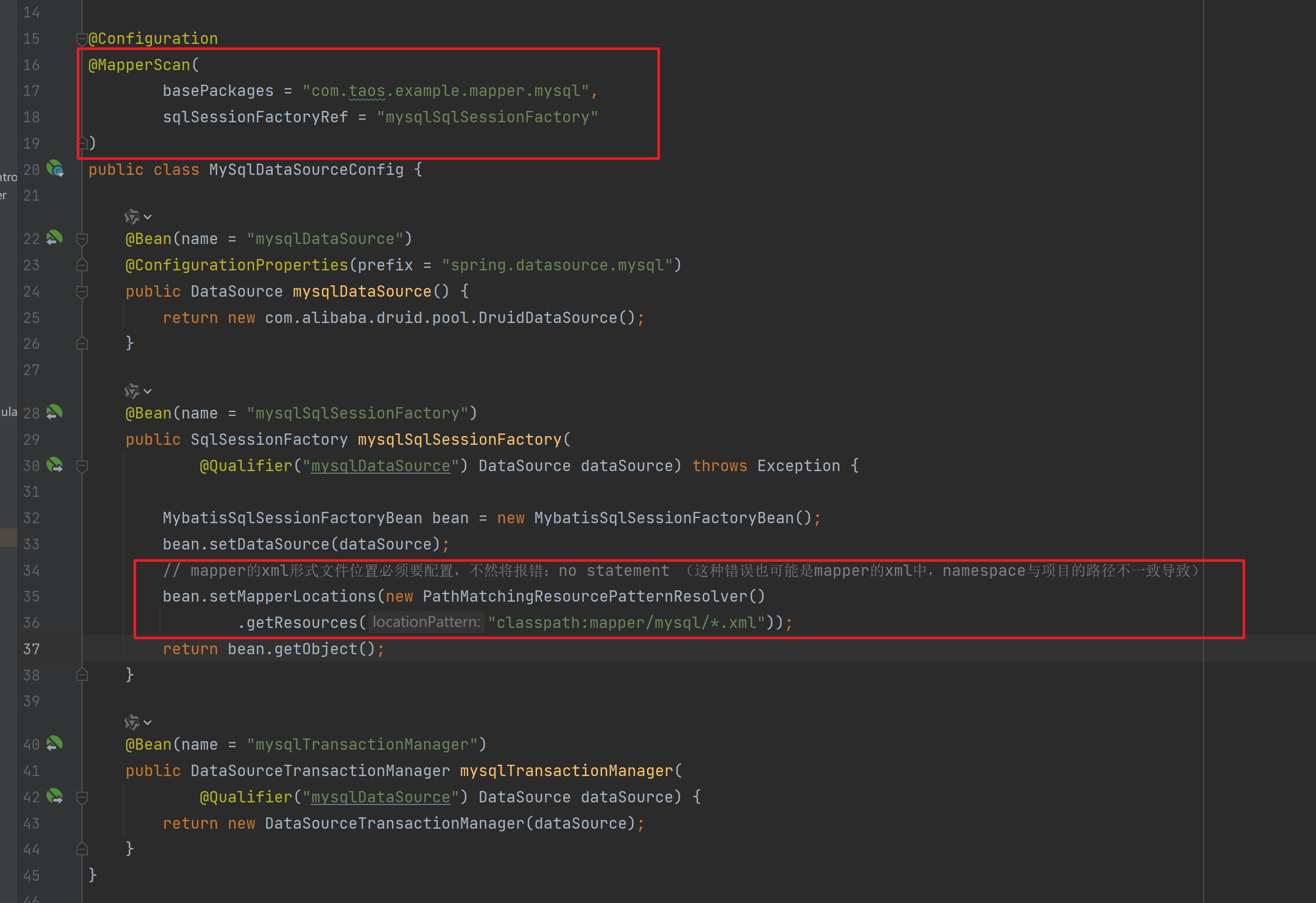
不然有时候它会不知道是哪个数据源的,会出错。
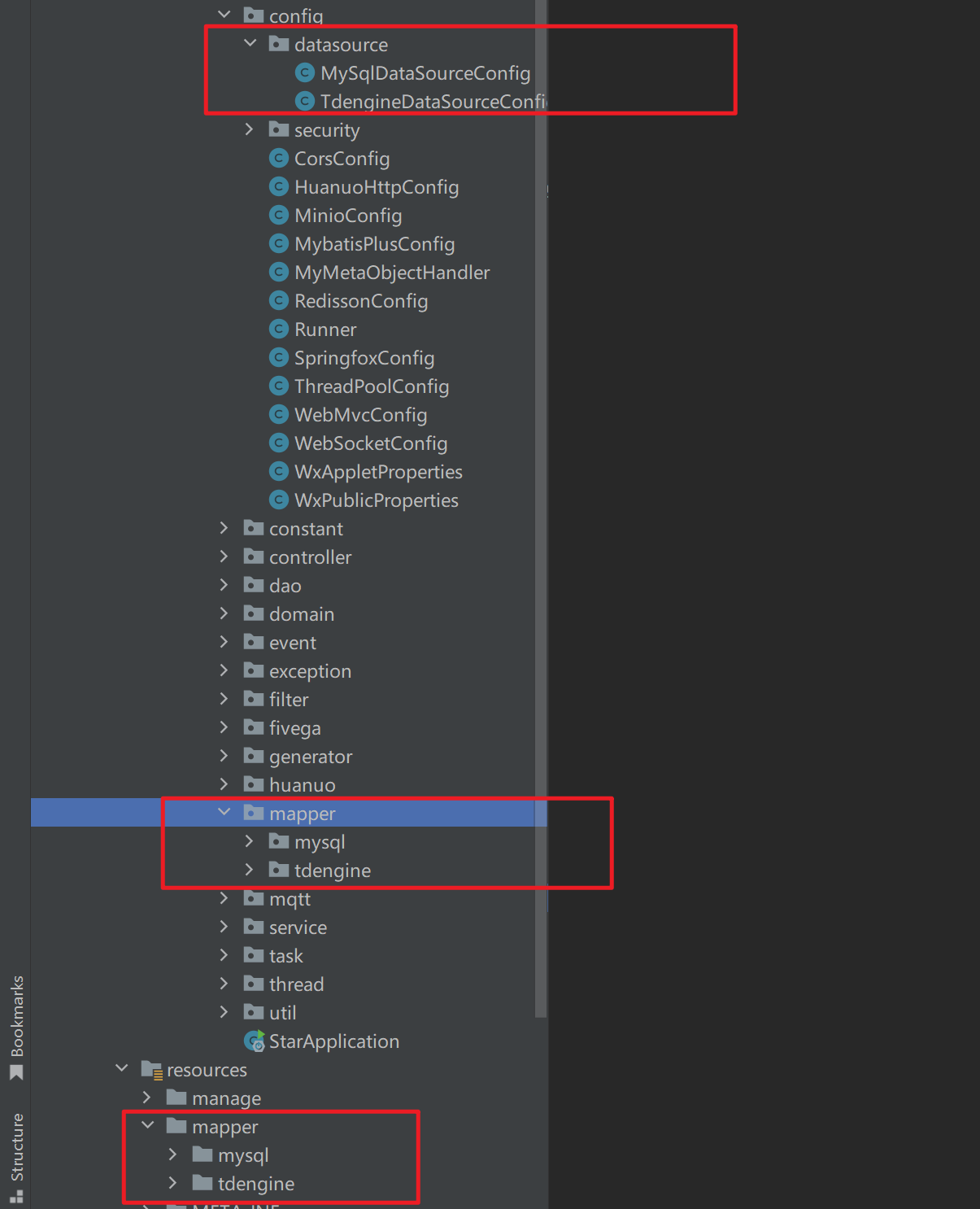
Mapper和xml都要要这样隔离开来放:
八、和「动态数据源」的核心区别对比
| 对比项 | 多数据源并存 | 动态数据源(切换) |
|---|---|---|
| DataSource 数量 | 多个 | 只有 1 个对外 |
| 是否切换 | 不切换 | 通过 ThreadLocal 切换 |
| 适合场景 | 不同业务不同库 | 读写分离 / 多租户 |
| 是否推荐 | 强烈推荐 | 只在必要时推荐 |
九、使用姿势
java
@Service
public class UserService {
@Resource
private UserMapper userMapper;
@Resource
private TdLogMapper tdLogMapper;
@MysqlTx
public void saveUser(User user) {
userMapper.insert(user);
}
@TdTx
public void saveLog(Log log) {
tdLogMapper.insert(log);
}
}你会发现:
| 维度 | MySQL | TDengine |
|---|---|---|
| 注入方式 | @Resource | @Resource |
| 调用方式 | 一样 | 一样 |
| 感觉 | 一模一样 | 一模一样 |
业务代码根本**无感知数据源差异 ,**这就是并存方式最爽的地方。项目结构就如下:
一些常见问题
1,druidSQL监控不生效
我个人反正习惯用Druid的面板。
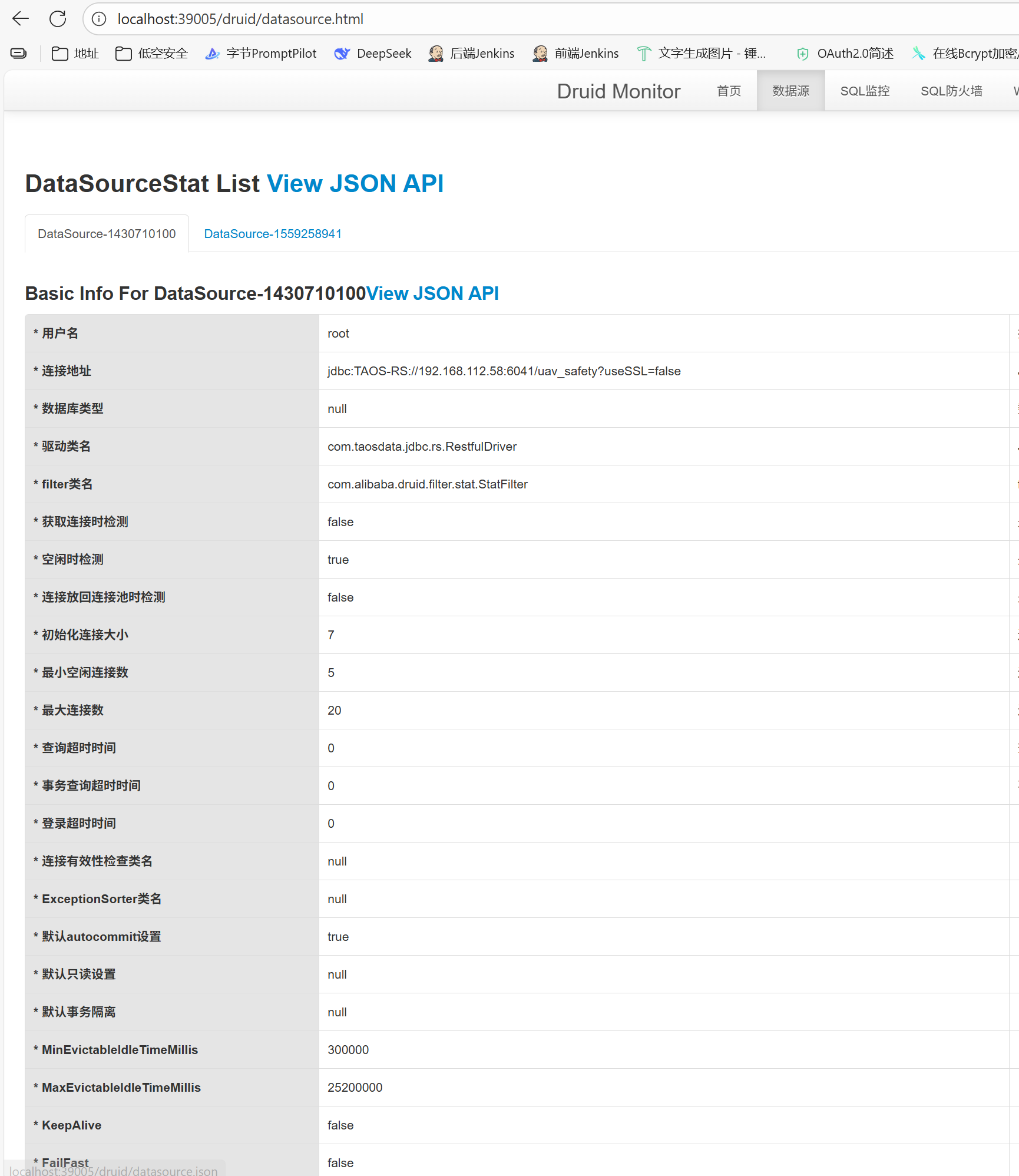
其中有个SQL统计,我们发现TD的不会被统计进来。
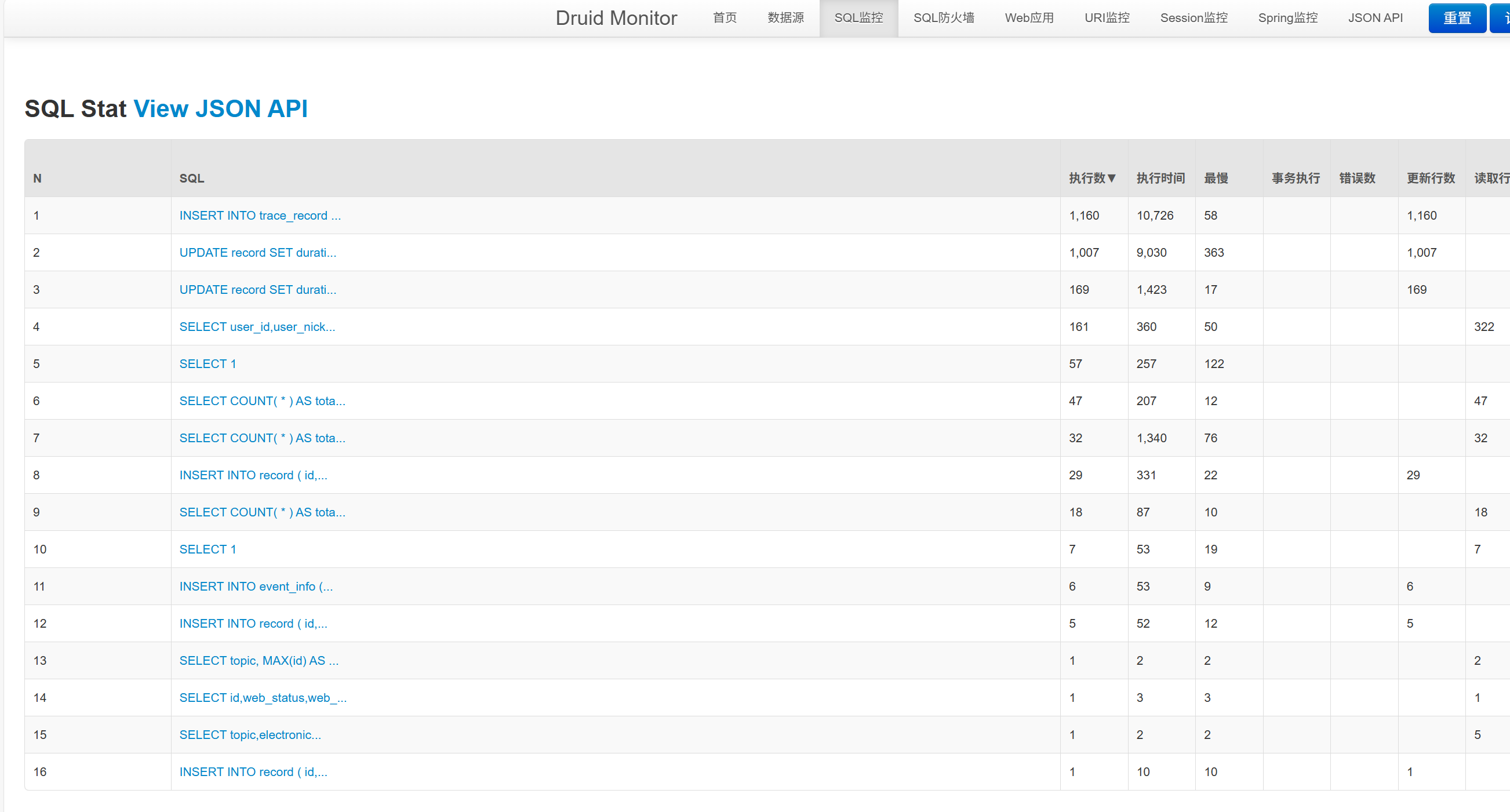
这时候要看看配置一下:
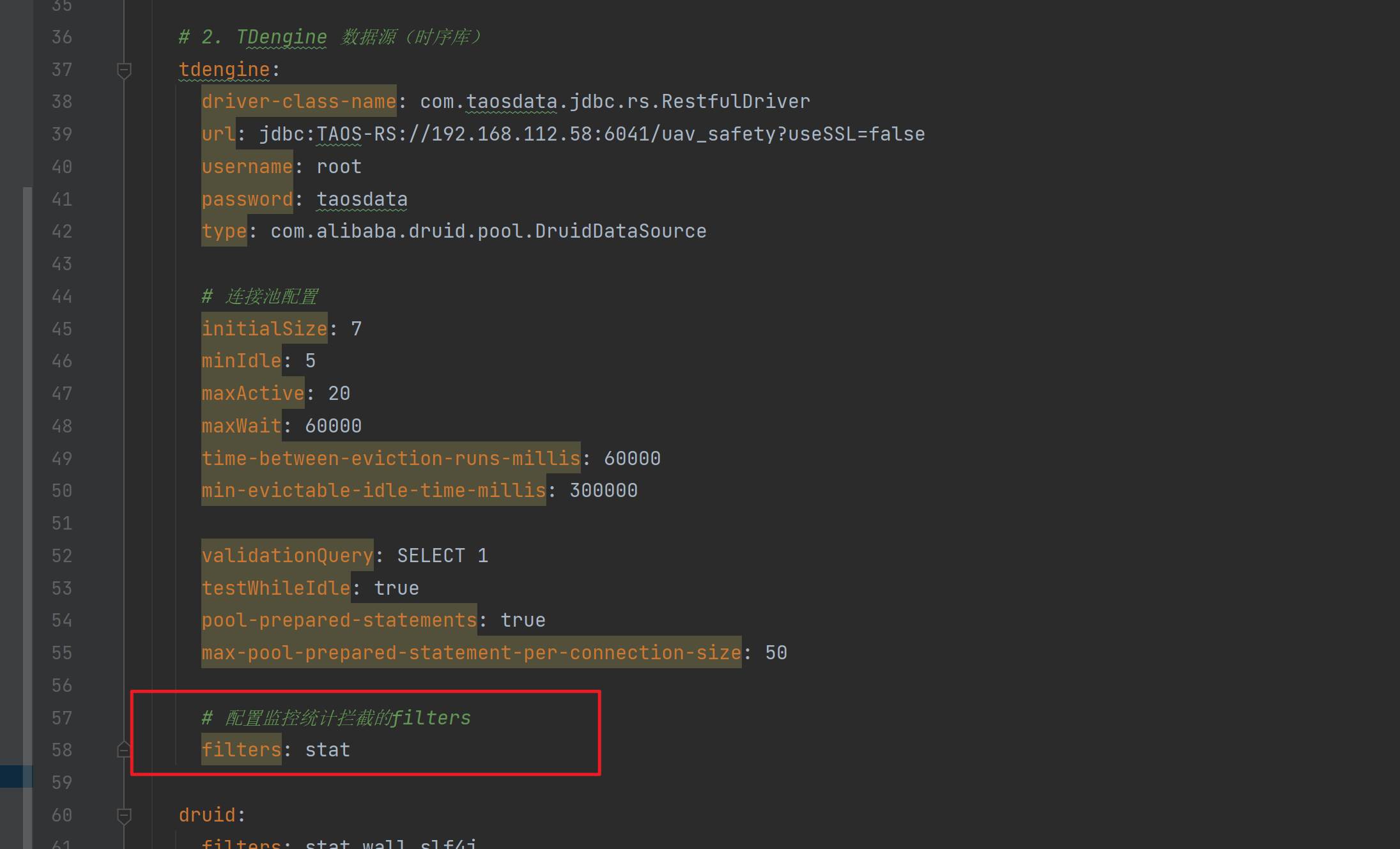
但记得像 wall 啥的就别配了,会空指针。
这是因为:wall 是为 SQL 注入检测设计的,但数据库语法只适配 MySQL 等关系型数据库,不兼容 TDengine 的 SQL 方言。
2,Invalid bound statement (not found):
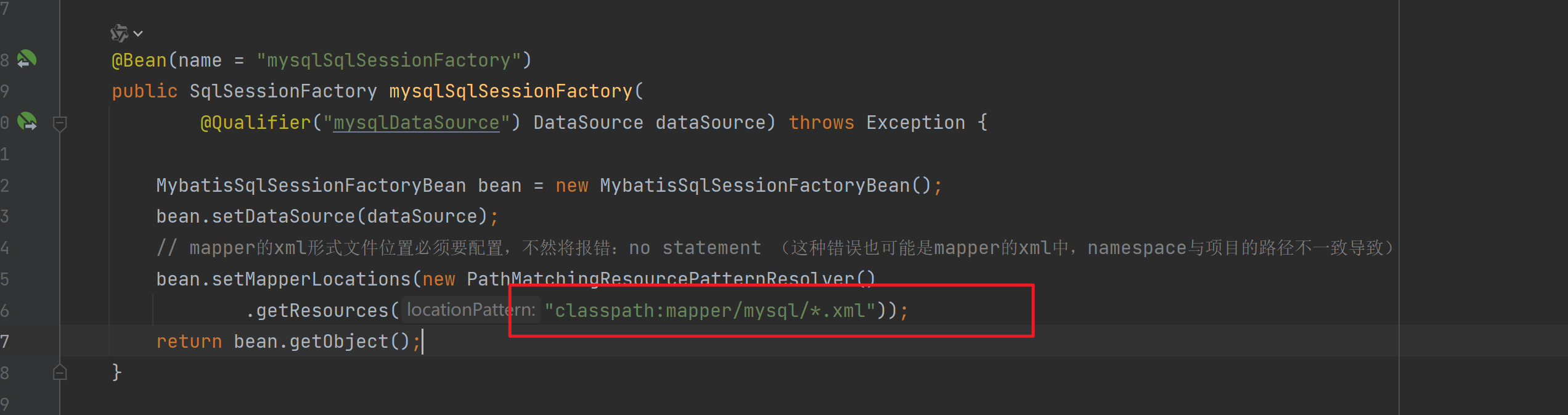
检查一下这个。记得要被扫描到。看看class文件里面,没有的话就mvn clean一下再build一遍。
然后就是 检查 Mapper 接口方法名和 XML id 是否一致。
还有就是
然后还有一种是MyBatisPlus的,记得要用 MybatisSqlSessionFactoryBean。
java
@Bean(name = "mysqlSqlSessionFactory")
public SqlSessionFactory mysqlSqlSessionFactory(@Qualifier("mysqlDataSource") DataSource dataSource) throws Exception {
MybatisSqlSessionFactoryBean bean = new MybatisSqlSessionFactoryBean();
bean.setDataSource(dataSource);
bean.setMapperLocations(new PathMatchingResourcePatternResolver()
.getResources("classpath:mapper/mysql/*.xml"));
return bean.getObject();
}总结一下
很多人一开始接触多数据源,脑子里只有一个问题:
怎么切换?
于是第一反应就是动态数据源、AbstractRoutingDataSource、ThreadLocal、AOP......
但在真实项目里,你更应该先问的其实是:
到底需不需要切换?还是各司其职就够了?
所以这两种方案解决的核心问题是完全不同的:
✅ 动态数据源解决的是「怎么切换」
-
本质:对外只有一个 DataSource
-
内部:通过 ThreadLocal + 路由规则自动切换
-
常见场景:读写分离、多租户、分库分表
-
核心难点:上下文传递准确性、事务一致性、调试困难
✅ 多数据源并存解决的是「怎么各司其职」
-
本质:多个 DataSource 同时存在
-
每个数据源拥有自己独立的
-
Mapper 扫描
-
SqlSessionFactory
-
TransactionManager
-
-
通过 Bean 名称区分,不做切换,只做分工
不同场景下都有每个解决方案的优劣,在真实系统中,提高系统稳定性的,往往不是复杂技巧,而是清晰边界。主要是要知道各个方案的注意点,在项目中才不会给自己埋雷。