📚推荐阅读
面试官:为什么 Adam 在部分任务上会比 SGD 收敛更快,但泛化性更差?如何改进?
面试官:你能讲讲 BatchNorm、LayerNorm、GroupNorm、 InstanceNorm 有什么本质区别吗?
很多同学肯定对这三个方法都很熟悉,但是一时间竟然不知道该怎么组织语言回答他们之间的区别,也不知道该从哪些方面进行对比,今天我们就来一次彻底拆解,不背定义、不绕术语,争取讲清楚三者的核心思想和差异本质。
所有相关源码示例、流程图、模型配置与知识库构建技巧,我也将持续更新在Github:AIHub,欢迎关注收藏!
一、为什么需要"Norm"?
我们都知道深度网络训练的时候,经常会出现两种极端情况:
- 前向时:激活值爆炸或消失;
- 反向时:梯度爆炸或消失。
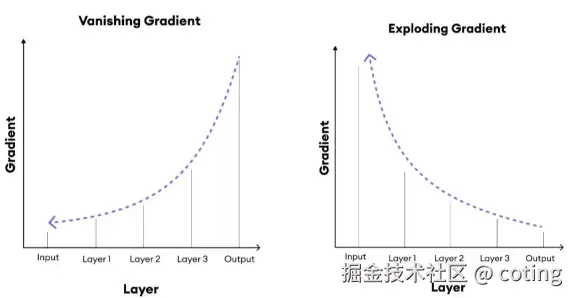
这两种情况都会让训练不稳定,模型收敛困难。而 "Normalization" 的核心目标就是让每一层的分布保持稳定,保证梯度流动顺畅。
二、BatchNorm 的本质:跨样本的统计归一化
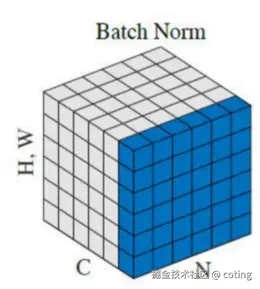
Batch Normalization(BN)是最早被广泛使用的归一化方式,它的思想非常直白:在每一层里,把一个 batch 中的所有样本的均值和方差对齐。
公式如下:
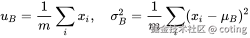

BN 通过在 batch 维度上计算均值与方差,让输入保持"零均值、单位方差",从而稳定了分布。
BatchNorm 可以缓解梯度消失和梯度爆炸,加快收敛速度,并且可以起到轻微的正则化作用 (因为 batch 统计会引入噪声);但是BatchNorm对 batch size 敏感,小 batch 会导致统计方差不准 ,在 RNN / 在线推理中不方便(统计量难以同步),并且推理阶段需要固定全局均值与方差,增加了复杂度。
在梯度流动性方面, 由于使用批内统计量,BN 在反向传播时会引入样本间的梯度耦合,这会在一定程度上"平滑"梯度更新,有助于稳定训练。
三、LayerNorm 的本质:跨特征的归一化
Layer Normalization(LN)不看 batch,而是在单个样本的特征维度上归一化:
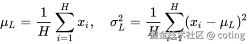
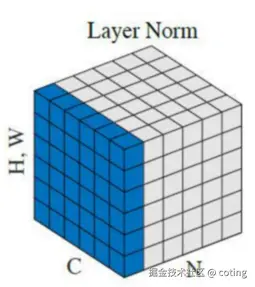
它只看当前样本本身的特征分布,不依赖 batch 内的其他样本。
LayerNorm对 batch size 不敏感,可用于 Transformer、RNN 等任务,在小批量或在线推理中表现稳定。但是因为通道特征统计不同,在 CNN 上效果不如 BN, 对空间信息不敏感。
在梯度流动性方面, LN 不依赖 batch,梯度更新完全独立于其他样本,这使得训练更加稳定,但也减少了梯度的"扰动探索",但是泛化性略弱。
四、GroupNorm 的本质:在通道维上分组归一化
Group Normalization(GN)就是 BN 和 LN 的折中方案。
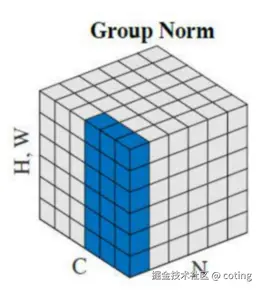
它将通道分成多个组(group),在每组内部做归一化:
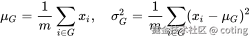
组数 G 是一个可调超参:
G = 1→ LayerNorm;G = C(每通道一组)→ InstanceNorm。
Groupnorm不依赖 batch size, 在小 batch、检测、分割等任务中效果好,保留了部分空间结构。
梯度流动性方面, GN 保留了一定的"局部耦合",因此既不像 BN 那样噪声大,也不像 LN 那样独立,
是两者的平衡方案。
五、InstanceNorm:每通道独立归一化
Instance Normalization 是 GroupNorm 的极端形式,每个样本的每个通道独立归一化(不依赖其他样本):
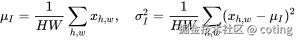
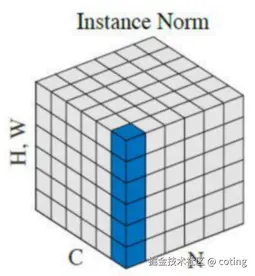
InstanceNorm对图像风格迁移、生成任务(如 GAN)特别有用,能有效去除样本间风格差异,保留结构特征,完全独立于 batch;但是会破坏样本间统计特征(不利于分类任务),泛化能力弱于 BN/GN。
在梯度流动性方面,InstanceNorm 几乎完全隔离样本间梯度信息,梯度传播最稳定、最独立,但也最容易陷入局部最优。
以上的内容如果你看懂了,相信你也对开始的问题有了清晰的答案了!
关于深度学习和大模型相关的知识和前沿技术更新,请关注公众号 coting!