DeepSeek-V3.2:开源大语言模型的新里程碑,在推理与智能体任务中突破性能边界
DeepSeek-V3.2作为最新开源大语言模型,通过创新的稀疏注意力机制、可扩展的强化学习框架和大规模智能体任务合成管道,成功缩小了开源与闭源模型之间的性能差距。该模型不仅在多个推理基准测试中与GPT-5表现相当,其高性能变体DeepSeek-V3.2-Speciale更在IMO 2025和IOI 2025等国际顶级竞赛中获得金牌水平表现,标志着开源LLM进入全新发展阶段。
论文标题 :DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
来源 :DeepSeek-AI research team
链接 :https://huggingface.co/deepseek-ai/DeepSeek-V3.2
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 AI极客熊 」 即刻免费解锁
文章核心
研究背景
近年来,大型语言模型领域出现了明显的分化趋势。尽管开源社区持续取得进展,但闭源专有模型的发展速度明显加快,导致两者之间的性能差距不断扩大。通过深入分析,研究者识别出限制开源模型复杂任务能力的三个关键缺陷:架构上对vanilla attention机制的依赖严重制约了长序列处理效率;资源分配上后训练阶段计算投资不足限制了模型在困难任务上的表现;在AI智能体场景中,开源模型在泛化和指令遵循能力方面明显滞后于专有模型。
研究问题
- 计算效率瓶颈 :传统注意力机制在长序列处理中存在 O ( L 2 ) O(L^2) O(L2)的计算复杂度,严重制约了模型的部署效率和后训练能力
- 后训练计算不足:开源模型在后训练阶段的计算预算有限,难以解锁高级推理能力
- 智能体能力滞后:开源模型在工具使用场景中的泛化能力和指令遵循鲁棒性不足,影响实际部署效果
主要贡献
- DeepSeek Sparse Attention (DSA) :引入高效注意力机制,将核心注意力复杂度从 O ( L 2 ) O(L^2) O(L2)降低至 O ( L k ) O(Lk) O(Lk),其中 k ≪ L k \ll L k≪L为选择的token数量,在保持长上下文性能的同时显著提升计算效率
- 可扩展强化学习框架:开发了稳定的RL协议,将后训练计算预算提升至预训练成本的10%以上,使DeepSeek-V3.2在多个推理基准测试中与GPT-5表现相当
- 大规模智能体任务合成管道:创新性地整合推理与工具使用能力,生成超过1,800个不同环境和85,000个复杂提示,显著提升了模型在复杂交互环境中的泛化和指令遵循能力
方法论精要
DeepSeek-V3.2的技术架构包含三个核心创新组件,共同解决了开源模型面临的效率、计算和智能体能力挑战。
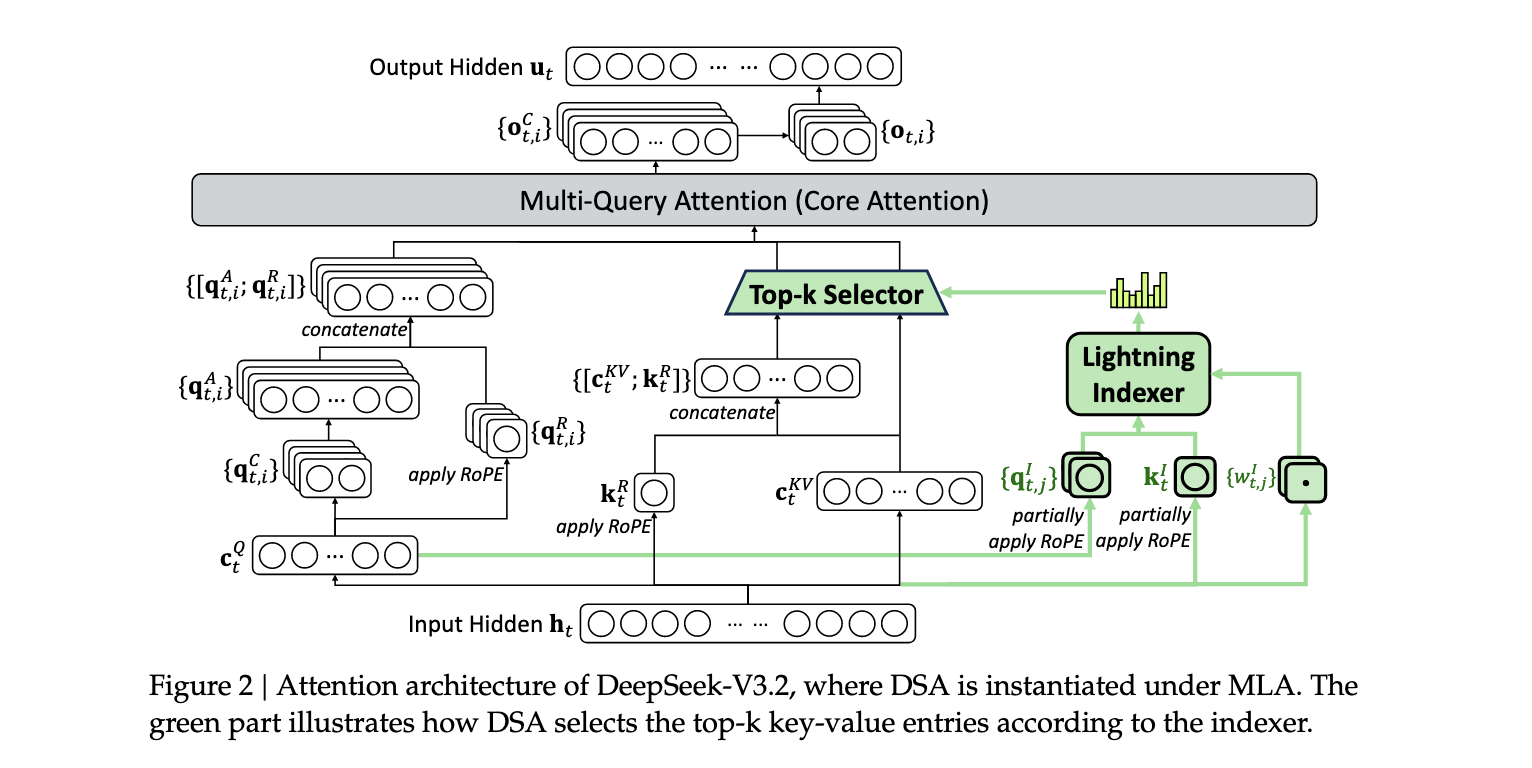
DeepSeek Sparse Attention (DSA)机制
DSA的设计包含两个关键组件:lightning indexer和细粒度token选择机制。Lightning indexer计算查询token h t ∈ R d h_t \in \mathbb{R}^d ht∈Rd与先前token h s ∈ R d h_s \in \mathbb{R}^d hs∈Rd之间的索引分数 I t , s I_{t,s} It,s:
I_{t,s} = H_I \\sum_{j=1} w_{I_{t,j}} \\cdot \\text{ReLU}(q_{I_{t,j}} \\cdot k_{I_s})
其中 H I H_I HI表示索引器头的数量, q I t , j ∈ R d I q_{I_{t,j}} \in \mathbb{R}^{d_I} qIt,j∈RdI和 w I t , j ∈ R w_{I_{t,j}} \in \mathbb{R} wIt,j∈R从查询token h t h_t ht导出, k I s ∈ R d I k_{I_s} \in \mathbb{R}^{d_I} kIs∈RdI从先前token h s h_s hs导出。基于索引分数 { I t , s } \{I_{t,s}\} {It,s},细粒度token选择机制仅检索对应于前k个索引分数的键值条目 { c s } \{c_s\} {cs},然后通过注意力机制计算输出:
u_t = \\text{Attn}(h_t, {c_s} \| I_{t,s} \\in \\text{Top-k}(I_{t,:}))
DSA的训练采用两阶段策略:密集预热阶段和稀疏训练阶段。预热阶段使用KL散度损失对齐索引器输出与主注意力分布:
L_I = \\sum_t D_{\\text{KL}}(p_{t,:} \|\| \\text{Softmax}(I_{t,:}))
稀疏训练阶段则针对选定的token集 S t S_t St进行优化:
L_I = \\sum_t D_{\\text{KL}}(p_{t,S_t} \|\| \\text{Softmax}(I_{t,S_t}))
可扩展强化学习框架
DeepSeek-V3.2采用Group Relative Policy Optimization (GRPO)作为RL训练算法,其目标函数为:
J GRPO ( θ ) = E q ∼ P ( Q ) , { o i } i = 1 G ∼ π old ( ⋅ ∣ q ) 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ min ( r i , t ( θ ) A \^ i , t , clip ( r i , t ( θ ) , 1 − ε , 1 + ε ) A \^ i , t ) − β D KL ( π θ ( o i , t ) ∣ ∣ π ref ( o i , t ) ) J_{\text{GRPO}}(\theta) = \mathbb{E}{q \sim \mathcal{P}(Q), \{o_i\}{i=1}^G \sim \pi_{\text{old}}(\cdot|q)} \left \\frac{1}{G} \\sum_{i=1}\^G \\frac{1}{\|o_i\|} \\sum_{t=1}\^{\|o_i\|} \\min(r_{i,t}(\\theta)\\hat{A}_{i,t}, \\text{clip}(r_{i,t}(\\theta), 1-\\varepsilon, 1+\\varepsilon)\\hat{A}_{i,t}) - \\beta D_{\\text{KL}}(\\pi_\\theta(o_{i,t}) \|\| \\pi_{\\text{ref}}(o_{i,t})) \\right JGRPO(θ)=Eq∼P(Q),{oi}i=1G∼πold(⋅∣q)G1∑i=1G∣oi∣1∑t=1∣oi∣min(ri,t(θ)A\^i,t,clip(ri,t(θ),1−ε,1+ε)A\^i,t)−βDKL(πθ(oi,t)∣∣πref(oi,t))
为了稳定RL扩展,研究者引入了多项创新策略:
无偏KL估计:通过重要性采样比率修正K3估计器,消除系统性估计误差:
D KL ( π θ ( o i , t ) ∣ ∣ π ref ( o i , t ) ) = π θ ( o i , t ∣ q , o i , < t ) π old ( o i , t ∣ q , o i , < t ) ( log π ref ( o i , t ∣ q , o i , < t ) π θ ( o i , t ∣ q , o i , < t ) − log π ref ( o i , t ∣ q , o i , < t ) π θ ( o i , t ∣ q , o i , < t ) − 1 ) D_{\text{KL}}(\pi_\theta(o_{i,t}) || \pi_{\text{ref}}(o_{i,t})) = \frac{\pi_\theta(o_{i,t}|q,o_{i,<t})}{\pi_{\text{old}}(o_{i,t}|q,o_{i,<t})} \left( \log\frac{\pi_{\text{ref}}(o_{i,t}|q,o_{i,<t})}{\pi_\theta(o_{i,t}|q,o_{i,<t})} - \log\frac{\pi_{\text{ref}}(o_{i,t}|q,o_{i,<t})}{\pi_\theta(o_{i,t}|q,o_{i,<t})} - 1 \right) DKL(πθ(oi,t)∣∣πref(oi,t))=πold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)(logπθ(oi,t∣q,oi,<t)πref(oi,t∣q,oi,<t)−logπθ(oi,t∣q,oi,<t)πref(oi,t∣q,oi,<t)−1)
离策略序列掩码 :引入二元掩码 M i , t M_{i,t} Mi,t来过滤引入显著策略分歧的负向序列:
M i , t = { 0 A ^ i , t < 0 , 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ log π old ( o i , t ∣ q , o i , < t ) π θ ( o i , t ∣ q , o i , < t ) > δ 1 otherwise M_{i,t} = \begin{cases} 0 & \hat{A}{i,t} < 0, \frac{1}{|o_i|}\sum{t=1}^{|o_i|} \log\frac{\pi_{\text{old}}(o_{i,t}|q,o_{i,<t})}{\pi_\theta(o_{i,t}|q,o_{i,<t})} > \delta \\ 1 & \text{otherwise} \end{cases} Mi,t={01A^i,t<0,∣oi∣1∑t=1∣oi∣logπθ(oi,t∣q,oi,<t)πold(oi,t∣q,oi,<t)>δotherwise
保持路由:在MoE模型中保持采样期间使用的专家路由路径,确保训练和推理期间激活相同的参数子空间,从而稳定优化过程。
大规模智能体任务合成
为了将推理能力整合到工具使用场景中,研究者开发了冷启动机制和大规模智能体任务合成管道。
冷启动阶段:利用DeepSeek-V3方法统一推理和工具使用,通过精心设计的提示使模型能够将工具执行整合到推理过程中。系统提示明确指导模型在最终答案之前进行推理,并使用特殊标签标注推理路径。
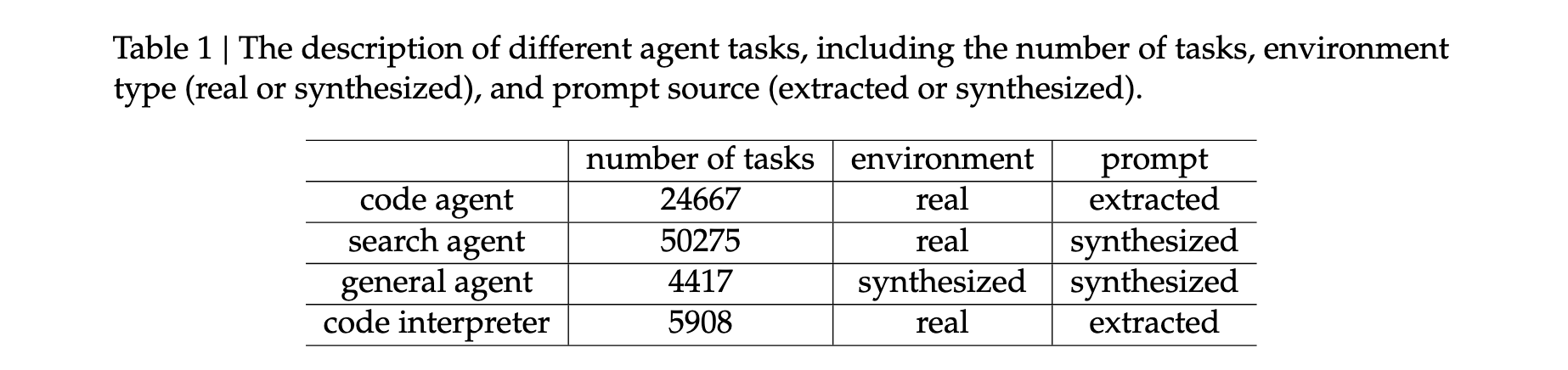
大规模任务合成:通过自动环境合成代理创建了1,827个面向任务的环境,这些任务难以解决但易于验证。合成工作流程包括环境和工具集构建、任务合成和解决方案生成。对于每个任务类别,代理首先使用工具从互联网生成或检索相关数据并存储在沙箱数据库中,然后合成一组特定于任务的工具,最后创建既具挑战性又可自动验证的任务。
上下文管理:针对工具调用场景开发了专门的上下文管理策略,仅在新用户消息引入对话时才丢弃历史推理内容。如果仅追加工具相关消息,推理内容会在整个交互过程中保留,从而显著提高token效率。
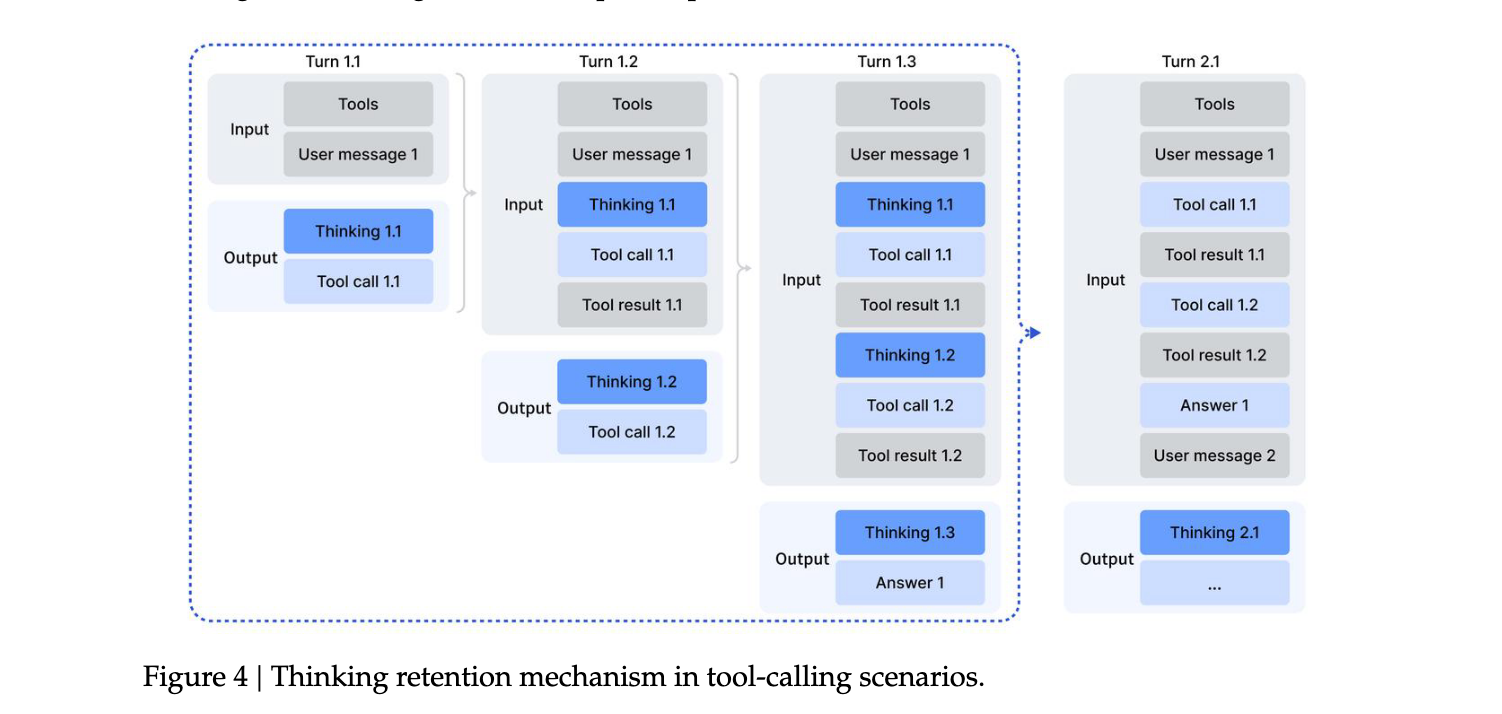
实验洞察
DeepSeek-V3.2在多个基准测试中表现出色,特别是在推理和智能体任务方面显著缩小了与闭源模型的差距。
推理能力评估
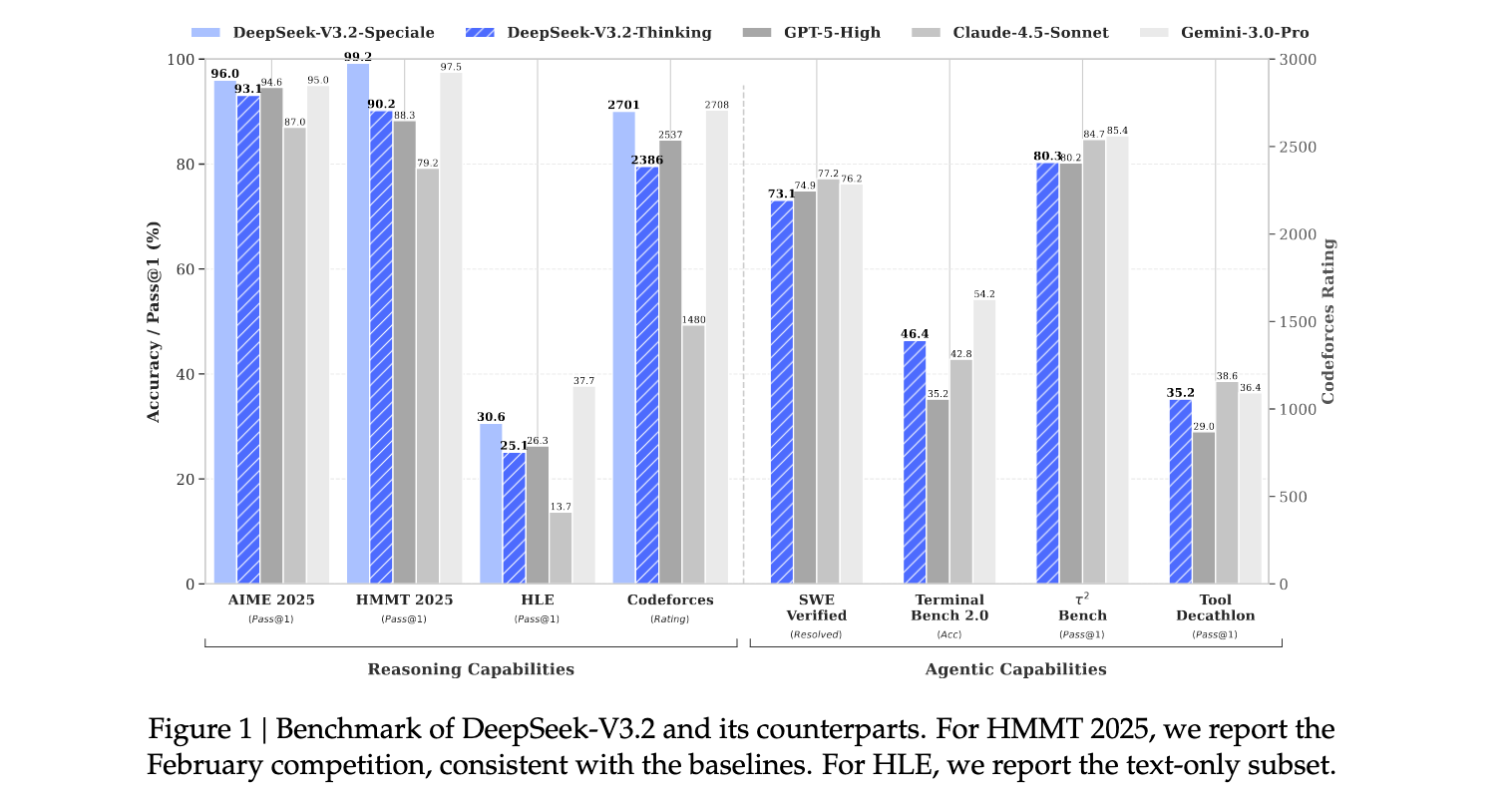
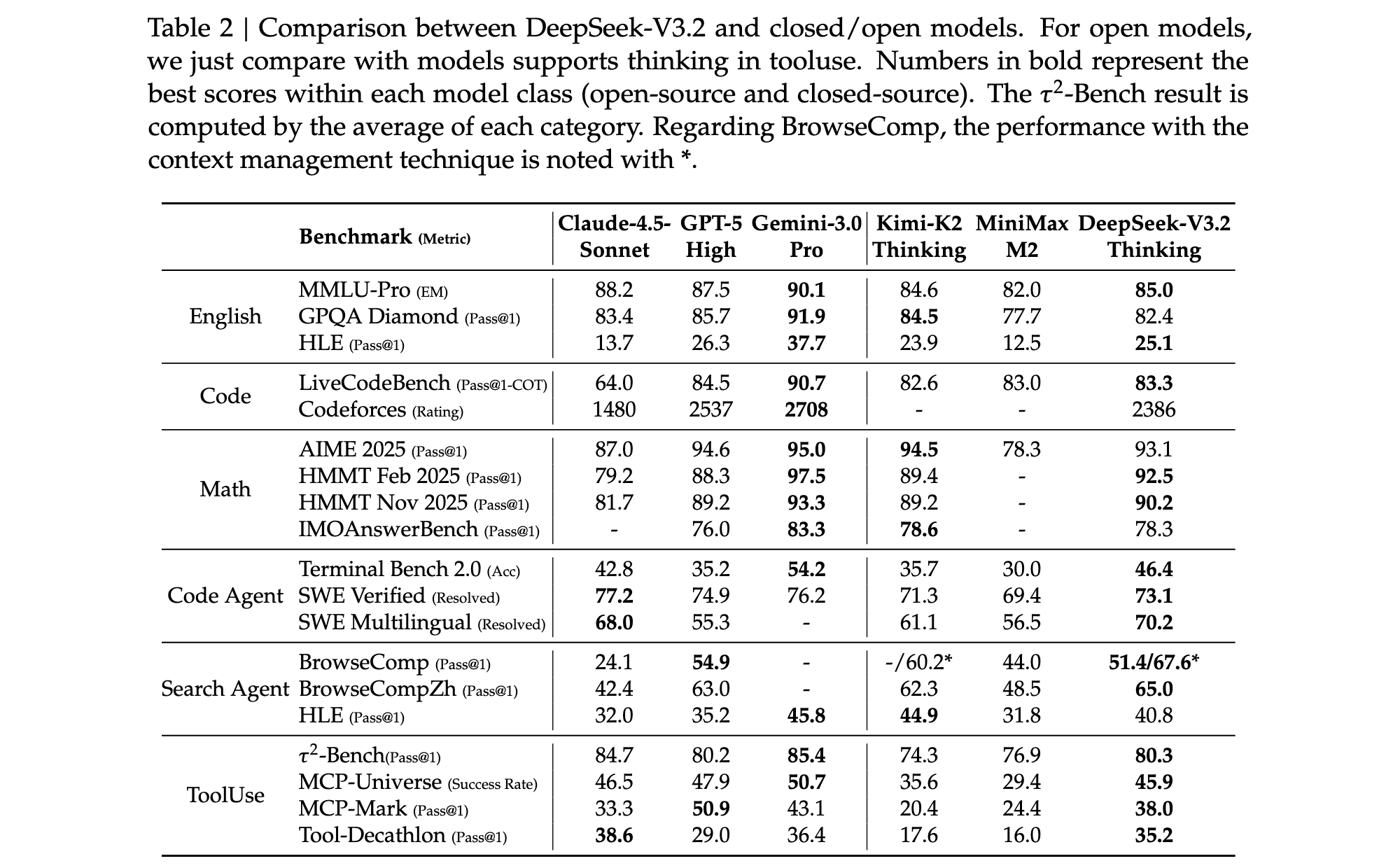
在数学竞赛基准测试中,DeepSeek-V3.2表现优异:AIME 2025达到93.1%的准确率,HMMT 2025 February达到92.5%,HMMT 2025 November达到90.2%。这些成绩与GPT-5-High(分别为94.6%、88.3%、89.2%)相当,虽然略低于Gemini-3.0-Pro(分别为95.0%、97.5%、93.3%)。在编程能力方面,DeepSeek-V3.2在Codeforces评分中达到2386分,显著优于Claude-4.5-Sonnet的1480分,接近GPT-5-High的2537分。
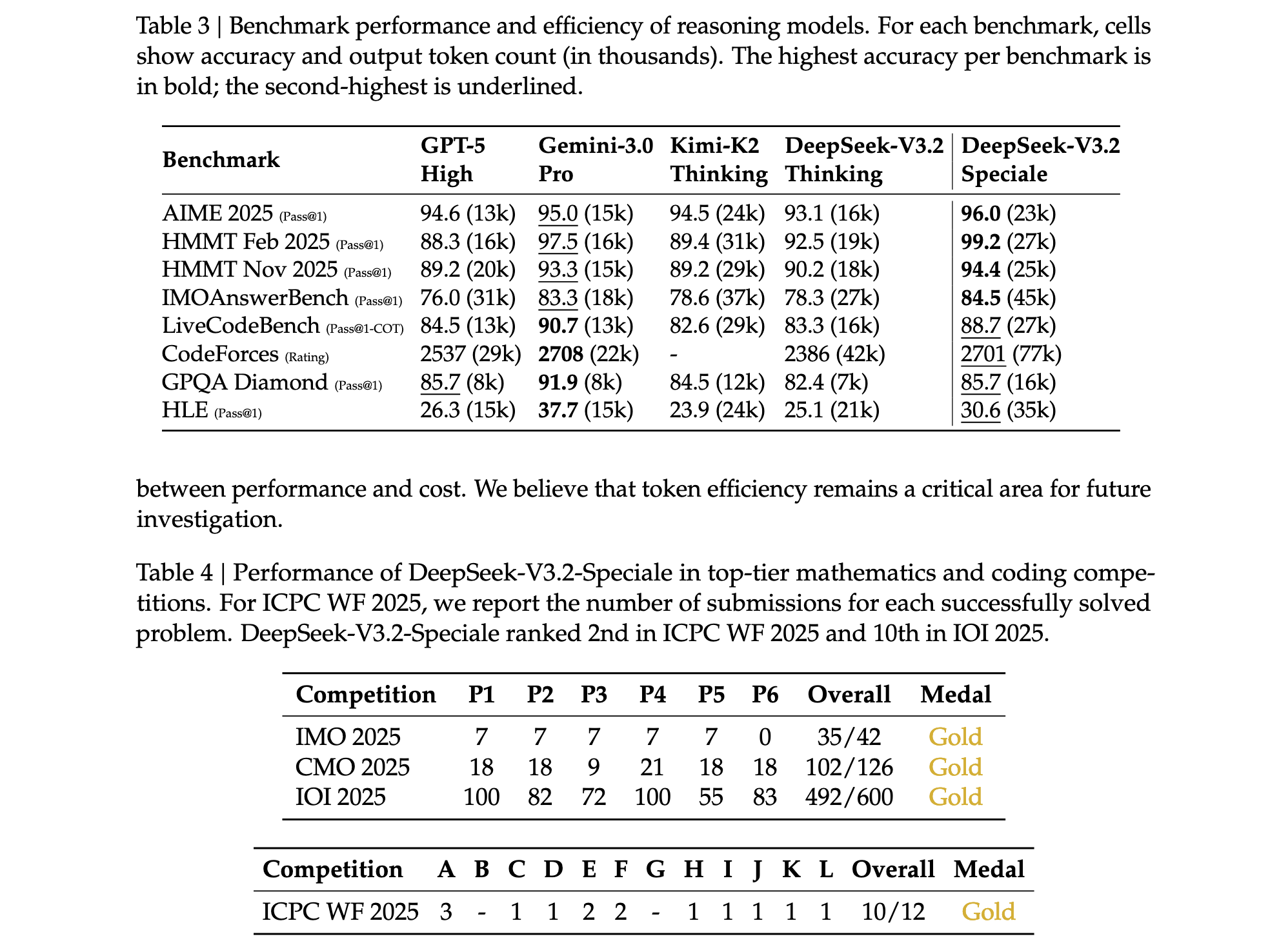
特别值得注意的是,DeepSeek-V3.2-Speciale通过放宽长度约束获得了更优异的性能:AIME 2025达到96.0%,HMMT 2025 February达到99.2%,IMOAnswerBench达到84.5%,在多项指标上超越了Gemini-3.0-Pro。该模型还在2025年国际数学奥林匹克(IMO)和国际信息学奥林匹克(IOI)中获得金牌水平表现,这是开源LLM的里程碑式成就。
智能体能力评估
在代码智能体任务中,DeepSeek-V3.2在Terminal Bench 2.0上达到46.4%的准确率,显著优于其他开源模型,接近GPT-5-High的35.2%和Gemini-3.0-Pro的54.2%。在SWE-Verified基准测试中,DeepSeek-V3.2解决了73.1%的问题,与GPT-5-High的74.9%和Gemini-3.0-Pro的76.2%相当。
在搜索智能体评估中,DeepSeek-V3.2在BrowseComp上达到51.4%的准确率(使用上下文管理技术后提升至67.6%),在BrowseCompZh上达到65.0%,表现优于GPT-5-High的54.9%和63.0%。在工具使用基准测试中,DeepSeek-V3.2在τ²-bench上达到80.3%的通过率,在MCP-Universe上达到45.9%的成功率,在MCP-Mark上达到38.0%的通过率,虽然仍低于最前沿的闭源模型,但显著缩小了性能差距。
效率分析
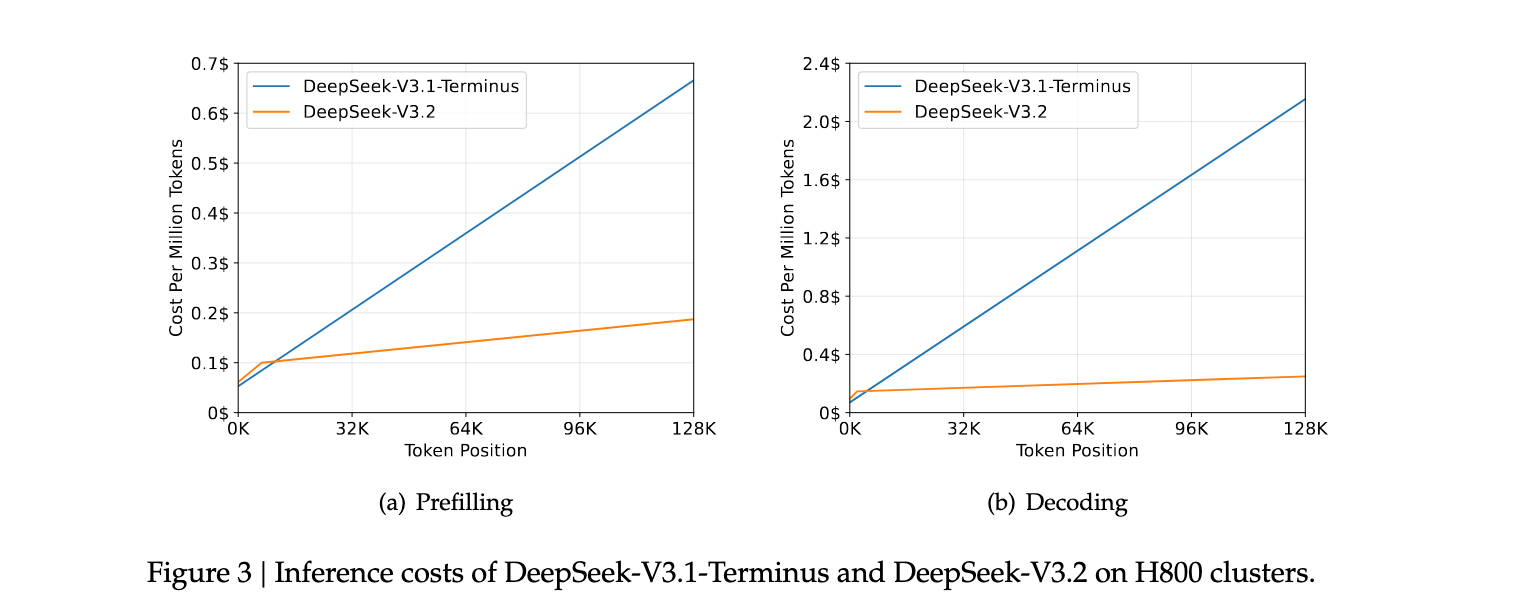
DSA机制显著降低了长序列处理的计算成本。在H800 GPU集群上,DeepSeek-V3.2在128K token位置的预填充成本仅为每百万token约0.2美元,而DeepSeek-V3.1-Terminus需要约0.7美元。在解码阶段,DeepSeek-V3.2在128K位置的成本约为每百万token1.6美元,而DeepSeek-V3.1-Terminus需要约2.4美元,实现了约33%的成本节约。
然而,DeepSeek-V3.2的token效率仍有提升空间。与Gemini-3.0-Pro相比,DeepSeek-V3.2通常需要更长的生成轨迹(即更多token)才能匹配其输出质量。例如,在HMMT 2025 February测试中,Gemini-3.0-Pro使用16k token达到97.5%的准确率,而DeepSeek-V3.2需要19k token达到92.5%的准确率。
上下文管理策略
研究者在BrowseComp基准测试上评估了不同的测试时计算扩展策略。结果表明,上下文管理策略通过允许模型扩展测试时计算,显著提升了性能。例如,Summary策略将平均步数从140扩展到364,性能从53.4提升到60.2。Discard-all策略在效率和可扩展性方面表现良好,达到67.6的分数,与并行扩展相当但使用的步骤显著更少。
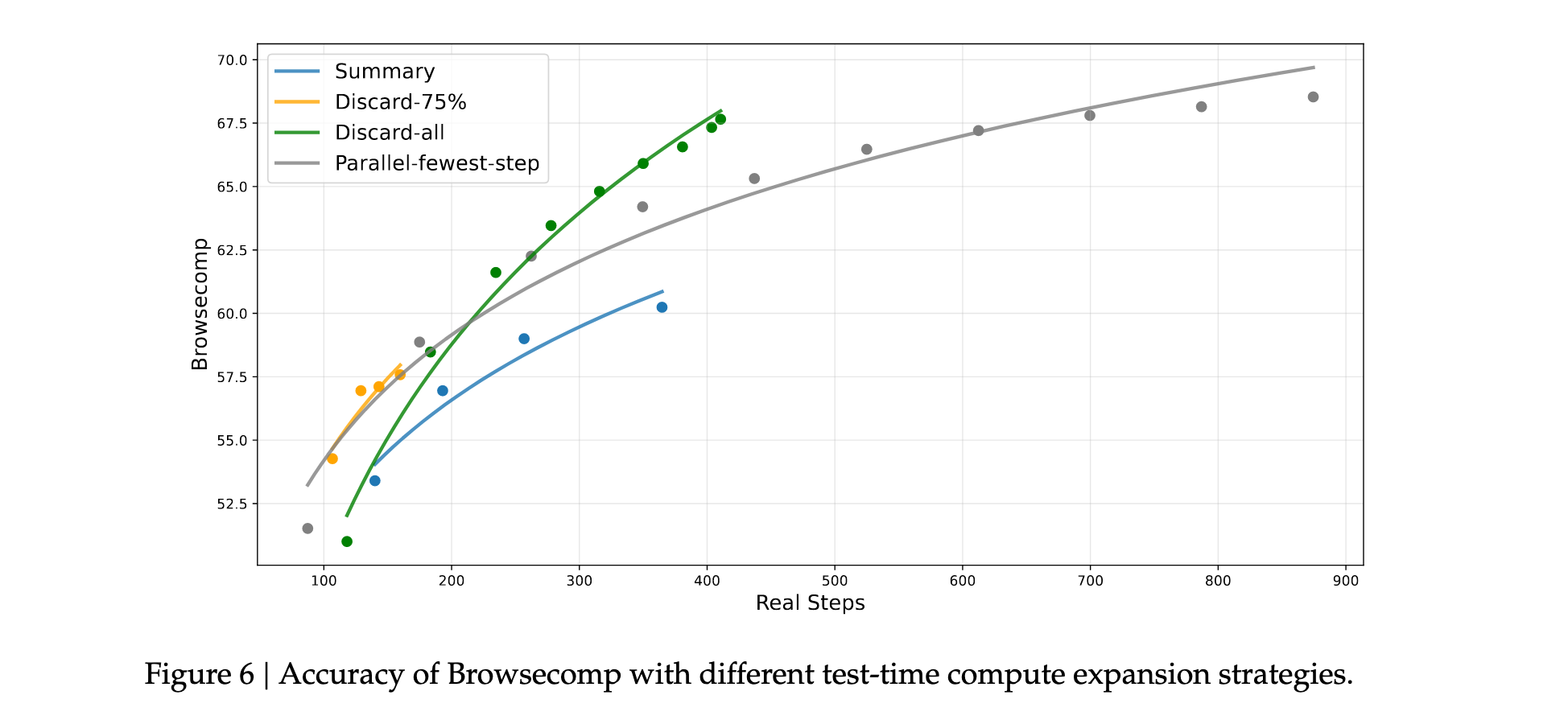
这些实验结果验证了DeepSeek-V3.2架构设计的有效性,特别是在平衡计算效率和模型性能方面的成功。同时,也指出了未来改进的方向,包括提高token效率和优化复杂任务解决能力。