这篇文章介绍了一个名为 Rex-Omni 的多模态大型语言模型(MLLM),它在目标检测任务上取得了显著的性能提升,同时具备强大的语言理解能力。以下是文章的主要研究内容概括:
研究背景与动机
-
目标检测的挑战:传统的目标检测方法主要依赖于坐标回归模型,如 YOLO、DETR 和 Grounding DINO。虽然这些方法在性能上已经取得了很好的结果,但在处理复杂语义描述和开放词汇目标检测时存在局限性。
-
MLLM 的潜力与挑战:多模态大型语言模型(MLLM)具有强大的语言理解能力,理论上可以更好地处理复杂的语义描述。然而,现有的基于 MLLM 的目标检测方法在性能上往往不如传统的回归模型,主要面临召回率低、重复预测、坐标错位等问题。
Rex-Omni 的设计与实现
-
任务公式化:Rex-Omni 将多种视觉感知任务(如目标检测、指代、提示等)统一到一个坐标预测框架下,使用量化坐标表示,并通过特殊标记来降低学习难度和提高效率。
-
数据引擎:为了提供高质量的训练数据,作者开发了多个数据引擎,包括接地数据引擎、指代表达数据引擎、指点数据引擎和 OCR 数据引擎,生成了大量语义丰富的视觉监督信号。
-
训练管道:Rex-Omni 采用两阶段训练策略。第一阶段是监督微调(SFT),在大规模标注数据上训练模型以获得基本的坐标预测能力。第二阶段是基于 GRPO(Generalized Reward-based Optimization)的强化后训练,通过几何感知奖励和行为感知优化来提升模型性能,纠正 SFT 阶段的不足。
实验与结果
-
基准测试:Rex-Omni 在多个基准测试上进行了评估,包括 COCO、LVIS、VisDrone、RefCOCOg、HumanRef 等,涵盖了常见的目标检测、长尾目标检测、密集目标检测、目标指代表达理解、视觉提示、GUI 接地、OCR 和关键点检测等任务。
-
性能提升:Rex-Omni 在零样本设置下,在 COCO 和 LVIS 等基准测试上取得了与传统回归模型相当或更好的性能。在其他任务上,Rex-Omni 也一致地优于现有的 MLLM 方法,展示了其在精确目标定位和语言理解方面的优势。
-
GRPO 的有效性:通过对比 SFT 和 GRPO 后训练的模型,作者证明了 GRPO 在纠正重复预测、大框预测等行为缺陷方面的有效性,显著提升了模型的整体性能。
关键结论
-
性能突破:Rex-Omni 通过合理的任务公式化、高效的数据引擎和创新的两阶段训练管道,成功地将 MLLM 的语言理解能力与精确的视觉感知能力结合起来,在多种视觉感知任务上实现了突破性的性能。
-
通用性与适应性:Rex-Omni 不仅在常见的目标检测任务上表现出色,还在长尾、密集、小目标等更具挑战性的场景中展现了强大的适应性,证明了其作为一种通用视觉感知模型的潜力。
-
未来方向:尽管 Rex-Omni 在性能上取得了显著进展,但作者也指出了其在推理速度等方面的局限性,并提出了模型加速和先进采样策略作为未来研究的方向。
总的来说,这篇文章展示了如何通过精心设计的模型架构和训练策略,使 MLLM 在目标检测等视觉任务上达到甚至超越传统方法的性能,同时保持其在语言理解方面的优势,为未来多模态视觉 - 语言模型的发展提供了新的思路和方向。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

官方项目主页地址在这里,如下所示:
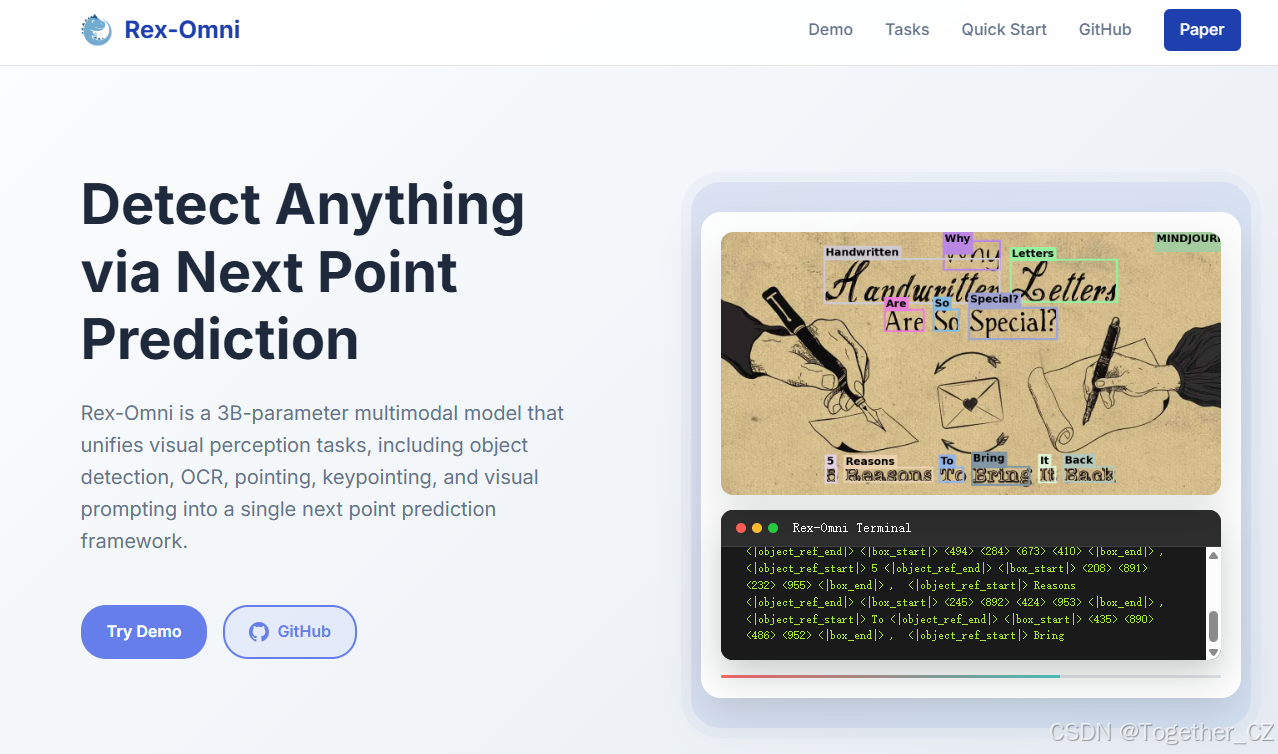
线上Demo地址在这里,如下所示:
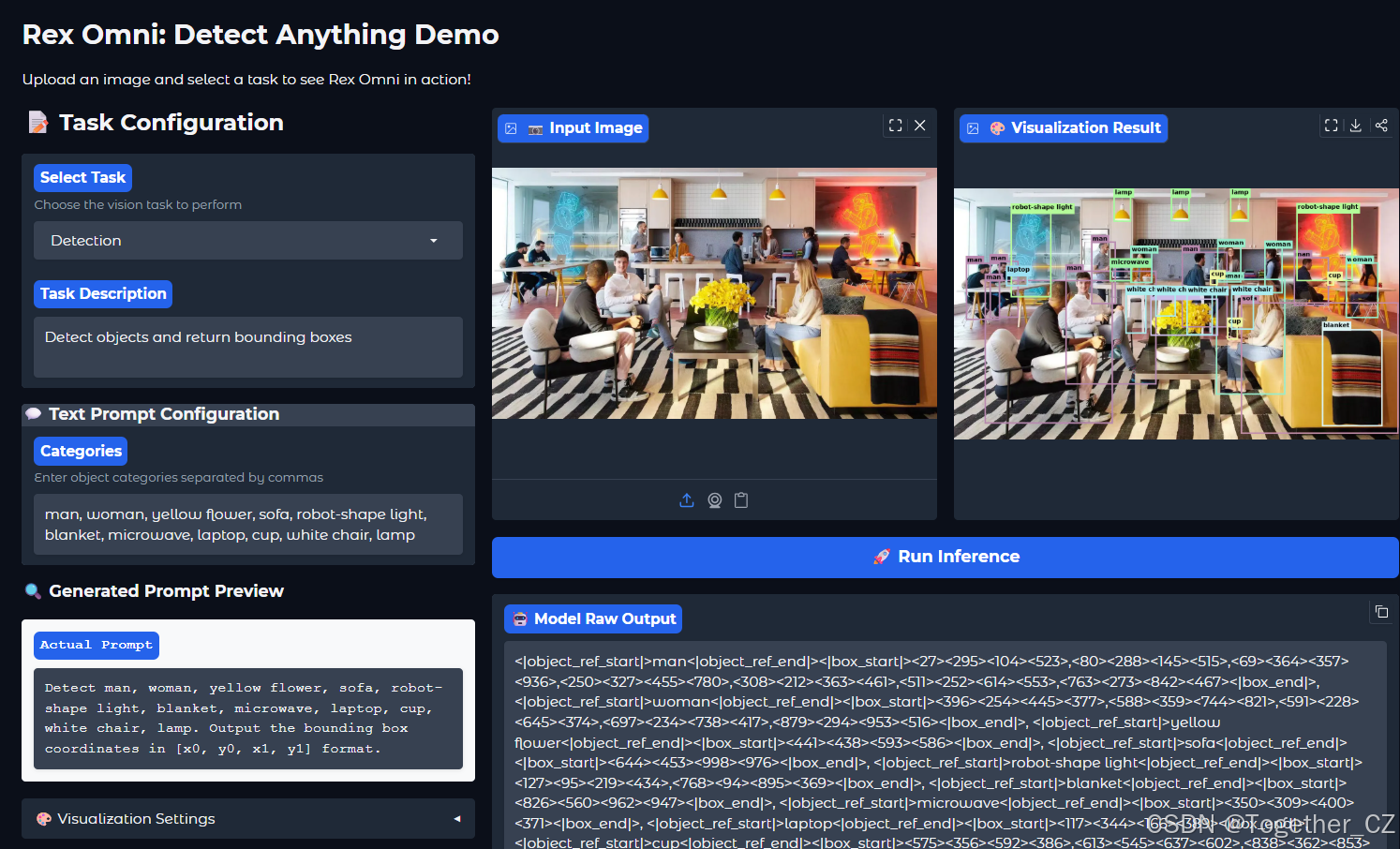
使用实例如下所示:
项目地址在这里,如下所示:
CodeBooks教程集如下:
| Task | Applications | Demo | Python Example | Notebook |
|---|---|---|---|---|
| Detection | object detection |
 |
code | notebook |
object referring |
 |
code | notebook | |
gui grounding |
 |
code | notebook | |
layout grounding |
 |
code | notebook | |
| Pointing | object pointing |
 |
code | notebook |
gui pointing |
 |
code | notebook | |
affordance pointing |
 |
code | notebook | |
| Visual prompting | visual prompting |
 |
code | notebook |
| OCR | ocr word box |
 |
code | notebook |
ocr textline box |
 |
code | notebook | |
ocr polygon |
 |
code | notebook | |
| Keypointing | person keypointing |
 |
code | notebook |
animal keypointing |
 |
code | notebook | |
| Other | batch inference |
code |
Rex-Omni应用如下:
| Application | Description | Demo | Documentation |
|---|---|---|---|
| Rex-Omni + SAM | Combine language-driven detection with pixel-perfect segmentation. Rex-Omni detects objects → SAM generates precise masks |  |
README |
| Grounding Data Engine | Automatically generate phrase grounding annotations from image captions using spaCy and Rex-Omni. |  |
README |
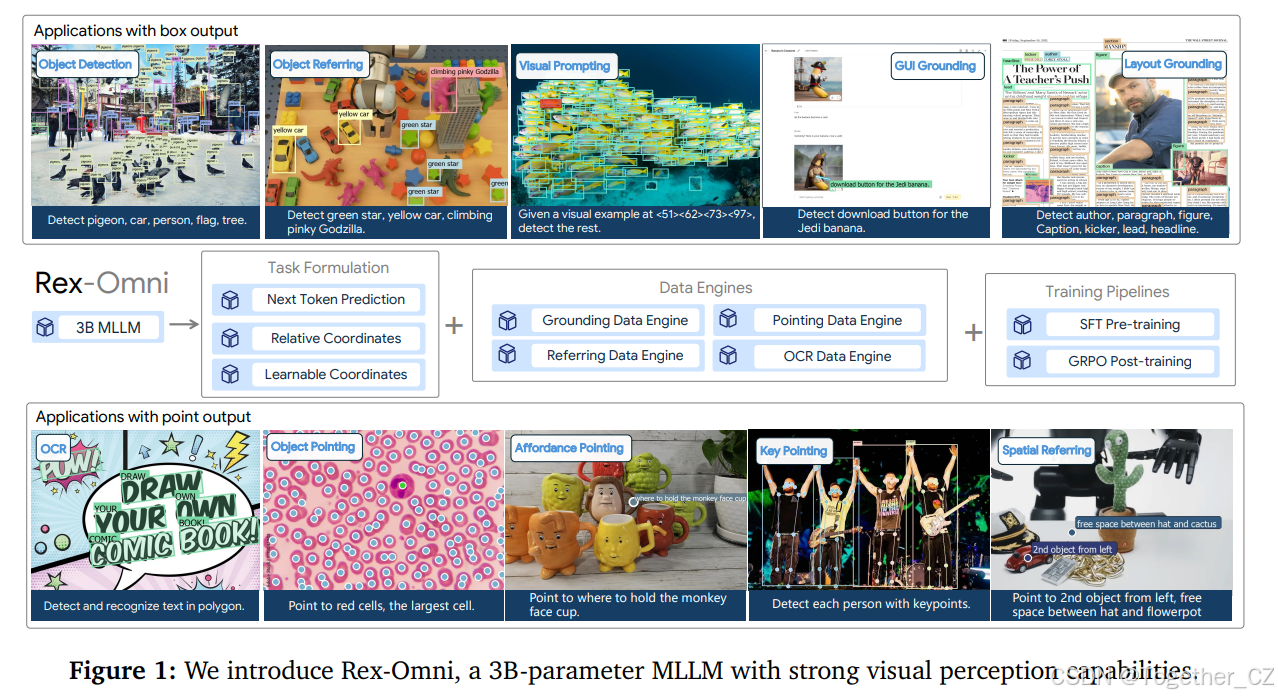
图 1:我们介绍 Rex-Omni,这是一个具有强大视觉感知能力的 3B 参数 MLLM
目标检测长期以来一直由传统的基于坐标回归的模型主导,例如 YOLO、DETR 和 Grounding DINO。尽管最近的努力尝试利用 MLLM 来解决这一任务,但它们面临着诸如召回率低、重复预测、坐标错位等问题。在这项工作中,我们弥合了这一差距,并提出了 Rex-Omni,这是一个 3B 规模的 MLLM,在目标感知性能上达到了最先进的水平。在 COCO 和 LVIS 等基准测试中,Rex-Omni 的性能与回归模型(例如 DINO、Grounding DINO)相当或超过,处于零样本设置中。这一成果得益于三个关键设计:1)任务公式化:我们使用特殊标记来表示从 0 到 999 的量化坐标,降低了模型的学习难度,并提高了坐标预测的标记效率;2)数据引擎:我们构建了多个数据引擎,以生成高质量的接地、指代和指点数据,为训练提供了语义丰富的监督;3)训练管道:我们采用两阶段训练过程,将 2200 万数据上的监督微调与基于 GRPO 的强化后训练相结合。这种强化后训练利用几何感知奖励,有效地弥合了离散到连续坐标预测的差距,提高了框的准确性,并减轻了由于初始 SFT 阶段的教师指导性质而导致的重复预测等不良行为。除了传统的检测外,Rex-Omni 与生俱来的语言理解能力使其具备了多种能力,例如目标指代、指点、视觉提示、GUI 接地、空间指代、OCR 和关键点检测,所有这些都在专门的基准测试中进行了系统评估。我们相信,Rex-Omni 为更通用和更具语言感知能力的视觉感知系统铺平了道路。

1.引言
目标检测23,87,86,85,8,122,102,60,58,127,38,99,20长期以来一直是计算机视觉的一个基础任务,由于其广泛的应用。该领域从早期的基于 CNN 的架构,如 YOLO86和 Faster R-CNN87,发展到基于 Transformer 的模型,如 DETR8和 DINO122,而任务本身也从传统的封闭集检测发展到开放集检测59,49,29,13,72,88,35,71,72,以更好地处理现实世界中出现的新兴事物。
在目标检测中,一个主要的目标是开发能够识别任意对象和概念的模型。一种常见的方法是开放词汇目标检测,其中像 Grounding DINO59和 DINO-X88这样的模型利用文本编码器(例如,BERT37或 CLIP81)来表示目标类别,并执行类别级别的开放集检测。尽管这些方法有效,但它们从根本上受到其相对浅薄的语言理解能力的限制,这限制了它们处理复杂语义描述(在图 2 中,Grounding DINO 检测到了所有苹果,尽管输入提示是红色苹果)的能力。因此,这些方法在完全解决这一问题上存在固有的限制。
相比之下,多模态大型语言模型(MLLM)74,101,65,107,11,1,44,18,105从其底层 LLM 的强大语言理解能力中受益,为将先进的语言理解能力整合到目标检测中提供了一条有希望的途径。一种常见的基于 MLLM 的方法9,116,106,120,123,30,69,33,133,24,4是将坐标表示为离散标记10,并通过下一个标记预测来预测边界框。虽然概念上很优雅,但现有的基于 MLLM 的方法很少在 COCO 等基准测试中达到传统回归检测器的性能。如图 2 所示,即使是像 Qwen2.5-VL4这样的先进 MLLM 也难以精确地定位目标,此外还面临着诸如召回率低、坐标漂移和重复预测等限制。
我们认为,基于 MLLM 的目标检测性能差距主要源于其当前公式化和训练中固有的两个基本挑战。首先,MLLM 通常将坐标预测视为一个离散分类任务,直接生成绝对坐标值,并依赖交叉熵损失进行监督。虽然传统的回归模型受益于连续的、几何感知的损失(例如,L1、GIoU),这些损失对小的几何偏移直接敏感,但 MLLM 在准确地将一组固定的离散标记映射到连续像素空间方面面临着显著的学习困难。如图 2 所示,即使在离散坐标预测中只有微小的像素错位,也可能导致不成比例的大的交叉熵损失,阻碍了精确的定位。这一固有挑战突显了减少坐标学习复杂性和为这一任务提供大量数据的必要性。
其次,MLLM 通常采用监督微调(SFT)进行教师指导的下一个标记预测训练79。虽然这种方法效率很高,但它在训练和推理之间造成了一个基本的不匹配。在 SFT 中,模型总是基于真实前缀进行条件训练,即教师强制,这意味着它从未接触到自己可能不完美的预测。这种训练设置未能捕捉到模型在自主生成设置中的真实性能。这本质上阻止了模型发展出强大的行为意识。因此,在没有这种直接指导的自由形式推理中,模型往往难以调节自己的输出结构。这导致了异常的坐标序列生成,例如产生重复预测或遗漏对象等异常行为,从而削弱了其整体性能。解决这两个相互关联的挑战对于推进基于 MLLM 的目标检测至关重要。
为了克服这些固有限制并释放 MLLM 在精确和多功能目标感知中的全部潜力,我们提出了 Rex-Omni,这是一个 3B 规模的 MLLM,在性能上与传统检测器相当,同时在语言理解能力上明显胜出。我们通过三个核心设计原则来解决上述挑战:
•任务公式化:我们将视觉感知任务统一到一个坐标预测框架下,其中每个任务被公式化为生成一系列坐标。具体来说,指点预测一个点,检测使用两个点形成一个边界框,多边形使用四个或更多点来表示目标轮廓,关键点任务输出多个语义点。我们采用量化坐标表示,将每个坐标值映射到 1000 个离散标记中的一个,对应于 0 到 999 的值。这种方法显著降低了坐标学习复杂性,简化了优化,同时提高了空间表示的效率。 •数据引擎:为了促进模型学习 1000 个离散坐标标记与像素级位置之间的映射,并培养对复杂自然语言表达的稳健理解,我们设计了多个专门的数据引擎,用于接地、指代和指点任务。这些引擎生成高质量、语义丰富的视觉监督信号,用于坐标预测。 •训练管道:我们采用两阶段训练范式。在第一阶段,我们在 2200 万数据上进行监督微调,以教授模型基本的坐标预测技能。在第二阶段,我们应用基于 GRPO 的92强化后训练,使用三个几何感知奖励函数。这一强化阶段有两个目的:它通过连续的几何监督提高了坐标预测的精度,并且至关重要的是,它减轻了由于初始 SFT 阶段的教师指导性质而产生的不良行为(例如重复预测)。
经过这种两阶段训练后,Rex-Omni 在各种感知任务中实现了卓越的性能,如图 1 所示,包括目标检测、目标指代、视觉提示、GUI 接地、布局接地、OCR、指点、关键点检测和空间指代。所有这些任务都是通过直接预测坐标点来实现的。为了定量评估其性能,Rex-Omni 首先在 COCO53上进行了评估,这是目标检测的一个核心基准。在零样本设置中(没有在 COCO 数据上进行训练),Rex-Omni 展示了优于传统坐标回归模型(例如 DINO-ResNet50、Grounding DINO)和其他 MLLM(例如 SEED1.5-VL24)的 F1 分数性能。除了 COCO,Rex-Omni 的性能还在多种任务上进行了进一步基准测试,例如长尾检测、指代表达理解、密集目标检测、GUI 接地和 OCR。Rex-Omni 一致地优于传统检测器和 MLLM,从而建立了一个统一的框架,将精确的定位与稳健的语言理解能力相结合。
总之,Rex-Omni 是朝着将稳健的语言理解能力与精确视觉感知能力统一起来的重要一步。通过精心整合合理化的任务公式化、先进的数据引擎和复杂的两阶段训练管道,我们证明了 MLLM 有深刻的潜力来定义下一代目标检测模型,提供前所未有的多功能性和真正以语言为导向的视觉感知方法。

2.任务公式化
在本节中,我们介绍 Rex-Omni 的任务公式化设计,涵盖其坐标表示、不同任务的具体输出格式以及其模型
2.1.坐标公式化
我们首先定义坐标预测的输出公式化。利用 MLLM 进行这一任务的现有方法可以大致分为三种范式,如图 3a 所示:1)直接坐标预测:受 Pix2Seq10范式的启发,这些方法9,116,106,120,123将坐标值视为语言模型词汇表中的离散标记,使模型能够直接生成坐标输出;2)基于检索的方法:这种方法30,69,31,33纳入了一个额外的提议模块。LLM 被训练来预测候选区域或边界框的索引,从而将输出表示为对预定义提议的检索任务;3)外部解码器:在这种策略121,108,42,61中,LLM 预测特殊标记,其对应的嵌入随后被传递给一个外部解码器,负责产生最终坐标。我们为 Rex-Omni 采用直接坐标预测策略,动机在于其简单性、灵活性以及不依赖外部模块或额外
在直接坐标预测范式中,存在几种变体,如图 3b 所示:1)带特殊标记的相对坐标:坐标被量化为 0 到 999 之间的值,每个坐标由 LLM 词汇表中的一个特殊标记表示。模型因此被训练来预测这 1000 个标记,以表示坐标。代表性模型是 Pix2Seq10。2)不带特殊标记的相对坐标:坐标同样被量化为 1000 个区间;然而,它们由多个原子标记而不是一个特殊标记来表示。代表性模型是 SEED1.5-VL24。3)绝对坐标:这种方法使用绝对坐标,例如将坐标值 1921 分解为单个数字(1,9,2,1)。代表性模型是 Qwen2.5-VL4。我们选择带特殊标记的相对坐标建模方法,主要有两个原因:首先,选择相对坐标而不是绝对坐标,本质上降低了学习复杂性,将分类任务限制在 1000 个类别的范围内。其次,为坐标使用专门的特殊标记显著减少了每个坐标所需的标记长度。例如,一个边界框仅用四个特殊标记表示,与没有这种方案时的 15 个原子标记(包括分隔符)相比。这显著提高了标记效率和推理速度,尤其是在密集目标
2.2.输入格式
Rex-Omni 采用统一的基于文本的接口来处理所有视觉感知任务。每个任务都以自然语言查询的形式表达,指定要在图像中识别的目标对象或关系。这种设计允许模型无缝地将多种视觉 - 语言任务整合到一个单一的指令驱动
文本提示。对于大多数任务,模型接收一个图像,配有一个以自然语言形式制定的文本提示。文本提示可以描述一个或多个目标。当指定多个目标时,它们的相应类别或指代表达式用逗号连接。例如:
多目标检测的文本提示示例
请在图像中检测鸽子、人、卡车、雪。以框格式返回输出。
对于不同的任务,我们设计了不同的查询风格,以指导模型进行
视觉提示。尽管文本提示具有强大的泛化能力和可解释性,但它们在处理缺乏清晰语言描述的对象时面临限制------尤其是罕见或视觉复杂的类别。如先前工作(例如 T-Rex232)所示,某些对象本质上难以通过文本单独表达。为了应对这一问题,Rex-Omni 支持视觉提示,允许用户提供边界框作为额外的、直观的形式
与现有方法32,88,28将视觉提示视为特征匹配问题(通过从指定区域提取嵌入并与检测查询进行比较)不同,Rex-Omni 采用统一的基于文本的接口。给定一个框格式的视觉提示,相应的区域首先被转换为量化坐标标记。然后通过自然语言指令引导模型识别与指定区域属于同一类别的所有对象。这种设计无缝地将视觉提示整合到生成式文本框架中,使模型能够通过推理视觉对应关系来
一个视觉提示的示例在 Rex-Omni 中
这里有一些示例框,指定了图像中几个对象的位置:"对象 1":"\<12\>\<412\>\<339\>\<568\>","\<92\>\<55\>\<179\>\<378\>"。请检测所有具有相同类别的对象,并以 x0,y0,x1,y1 格式返回它们的边界框
2.3.每个任务的输出格式
每个视觉任务的输出统一表示为一个结构化的标记序列,包括描述性短语、坐标标记和用于分隔的特殊标记,组织如下:
Rex-Omni 的基本输出格式 <|object_ref_start|>PHRASE<|object_ref_end|><|box_start|> COORDS<|box_end|>
在这里,PHRASE 表示由坐标序列所代表的对象的类别或描述,而 COORDS 指的是坐标序列。Rex-Omni 基于 Qwen2.5-VL-3B 构建,我们保留了 Qwen2.5-VL 原始的特殊标记,用于任务格式化,包括短语开始标记(<object_ref_start>)、短语结束标记(<object_ref_end>)、坐标开始标记(<box_start>)和坐标结束标记(<box_end>)。
对于涉及输出框的任务,例如目标检测,COORDS 由 x0,y0,x1,y1 格式的坐标序列组成,按 x0 升序排列。例如:
输出边界框任务的示例 <|object_ref_start|>person<|object_ref_end|><|box_start|><12><42><512><612>, <24><66><172><623>, ...<|box_end|>, ...(更多短语)
对于涉及输出点的任务,例如目标指点,COORDS 由 x0,y0 对组成。例如:
输出点任务的示例 <|object_ref_start|>button<|object_ref_end|><|box_start|><100><150>,<200><250>,...<|box_end|>, ...(更多短语)
对于涉及输出多边形的任务,例如 OCR,COORDS 由 x0,y0,x1,y1,x2,y2,... 格式的坐标序列组成。例如:
输出多边形任务的示例 <|object_ref_start|>text<|object_ref_end|><|box_start|><10><20>...<|box_end|>, ... (更多短语)
对于关键点检测任务,我们以结构化的 JSON 格式输出,包括对象的边界框及其相关的关键点。
关键点检测任务的示例 {"person1": {"box": <0><123><42><256>, "keypoints": {"left_eye": <32><43>, "right_eye": <66><55>, ...}}, {"person2": {"box": <51><116><72><522>, "keypoints": {"left_eye": <342><23>, "right_eye": <16><571>, ...}}}}
对于同时检测多个短语的情况,对应于不同短语的预测输出用逗号连接。如果特定短语所指的对象在图像中不存在,则相应的 COORDS 字段被 "None" 替换。
2.4.模型架构
如图 4 所示,Rex-Omni 基于 Qwen2.5-VL-3B-Instruct 模型构建,进行了最小的架构修改。虽然原始的 Qwen2.5-VL 采用绝对坐标编码方案,但我们调整模型以支持相对坐标表示,而无需引入额外参数。具体来说,我们将模型词汇表的最后 1000 个标记重新用于特殊标记,每个标记对应于从 0 到 999 的量化坐标。
<footer>6</footer><header>通过下一个点预测检测任何事物</header>
<figure><span>Ppers0n P/C<23><123><52><77>,<123><621><999><999>..C/ 2 seagullP/C<27><61>,<69><33>,<231><612>.<332><129>...C/ 个 Qwen2.5-3B P Phrase start token Native Resolution ViT TextTokenizer P/ Phrase end token 个 "Detect person and return in C Coordinate start token box format. Point to seagull and return in point format. C/Coordinate end token</span><figcaption>图 4:Rex-Omni 模型架构概览。Rex-Omni 基于 Qwen2.5-VL-3B 主干构建,进行了最小的架构修改。值得注意的是,原始词汇表的最后 1000 个标记被重新用于作为专用特殊标记,代表从 0 到 999 的量化坐标值。</figcaption></figure>

3.训练数据
为了使 Rex-Omni 兼具精确的坐标预测能力和强大的语言理解能力,我们使用了两类训练数据:公开可用的数据集和我们定制设计的数据引擎自动生成的注释数据
3.1.公开数据集
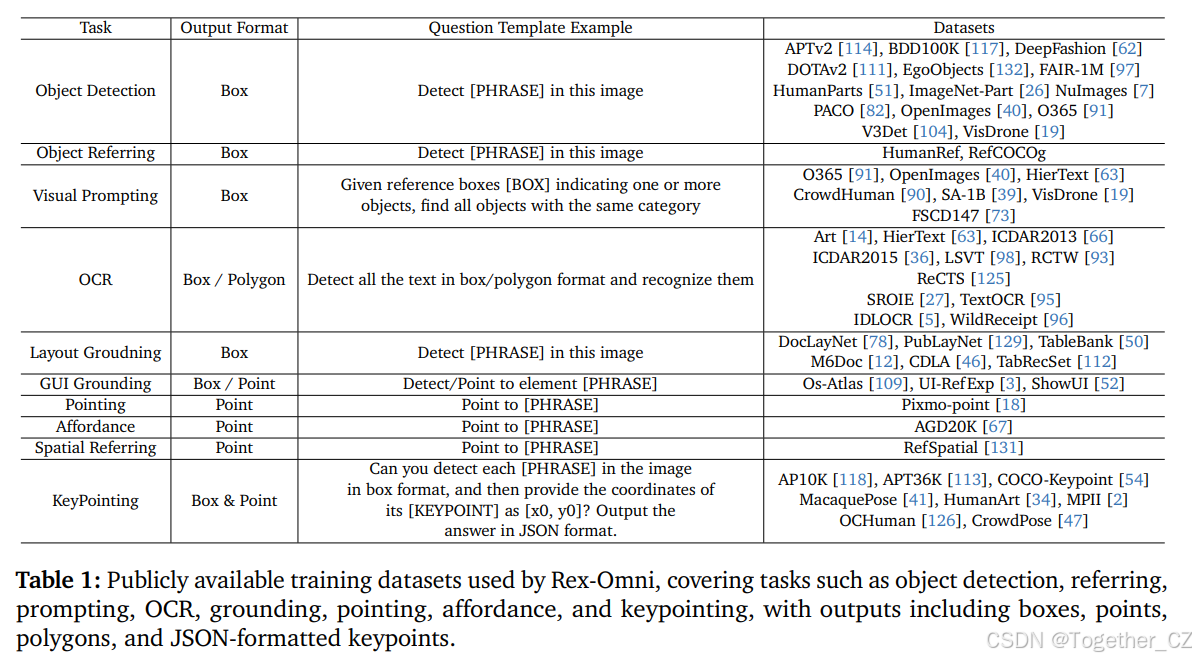
在表 1 中,我们列出了用于 Rex-Omni 训练的各种子任务的公开可用数据集,包括目标检测、目标指代、视觉提示、OCR、布局接地、GUI 接地、指点、可操作性接地、空间指代和关键点检测。对于每个任务,我们定义了一组问题模板,以构建相应的问题 - 答案(QA)对。总共,大约有 890 万公开数据样本被
3.2.数据引擎
有效训练 Rex-Omni 需要学习其 1000 个量化坐标标记与图像的连续像素空间之间的精细映射。这一能力需要比现有公开数据集常规提供的大量高质量训练数据。此外,虽然许多公开数据集提供类别级别的注释,但提供更丰富实例级语义接地(例如,指代表达)的数据集在规模和多样性方面都很少。为了应对这些限制,我们开发了一套专门的数据引擎,用于生成针对精细空间推理和复杂语言接地的高质量、大规模训练数据
3.2.1.接地数据引擎
构建大规模检测数据集的常见策略是开发一个接地数据引擎29,88,89,13,77,通常涉及生成图像标题、提取候选短语,并使用接地模型(例如,Grounding DINO)为这些短语分配边界框。与以往方法不同,我们在管道中引入了一个短语过滤阶段,以<footer>7</footer>通过下一个点预测检测任何事物
表 1:Rex-Omni 使用的公开训练数据集,涵盖目标检测、指代、提示、OCR、接地、指点、可操作性、空间指代和关键点检测等任务,输出包括框、点、多边形和 JSON 格式的
接地数据引擎 这是一个摆满柠檬的桌面。在桌面柠檬中,其中一些是切片的黄色柠檬。第一步 图像标题生成 桌面柠檬,其中一些是切片的黄色柠檬。第二步 短语提取 切片的黄色柠檬。第三步 短语过滤 第四步 接地 柠檬。柠檬放置在透明玻璃中。工具 SpaCy 透明玻璃中的柠檬。模型 规则 只有类别名称 碗 模型 OINOX 绿色柠檬在绿色柠檬碗中,碗在背景中。原始图像 接地框 w/ 类别名称</span><figcaption>图 5:我们两个主要数据引擎的流程图。图中展示了接地数据引擎(顶部)和指代表达数据引擎(底部)的流程,这些是为 Rex-Omni 定制设计的,以产生大量高质量的接地和指代表达数据。
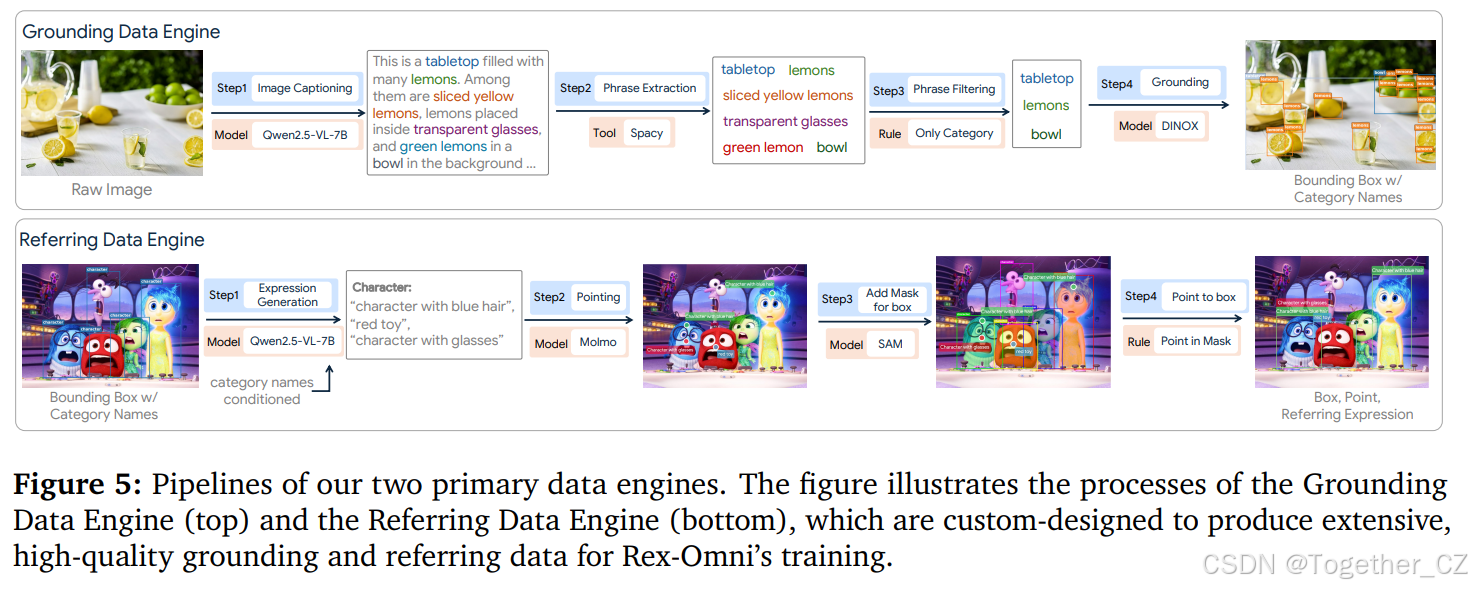
提高注释质量。具体来说,我们的注释过程包括以下四个阶段:
•图像标题生成:我们首先使用 Qwen2.5-VL-7B-Instruct 为每张图像生成描述性标题。这些标题提供了场景中多个对象的自然语言描述。 •短语提取:然后,我们应用 SpaCy1NLP 工具包从生成的标题中提取名词短语。这些短语可能包括基本类别名称(例如,桌面、柠檬)以及更具体的描述(例如,切片的黄色柠檬、绿色柠檬)。 •短语过滤:这一步标志着与以往方法的关键区别。为了最小化数据的模糊性,我们移除了包含描述性属性(例如,形容词)的名词短语(例如,绿色柠檬被丢弃,而柠檬被保留)。原因是当前的接地模型难以准确解释这种描述性表达,通常会检测出该类别的所有实例,而不管修饰语是什么。例如,短语"绿色柠檬"可能会错误地
•短语接地:最后,我们使用 DINO-X88,一个开放词汇目标检测器,为过滤后的短语生成对应的边界框。
对于这个数据引擎,图像主要来自 COYO6和 SA-1B39数据集。我们应用严格的预处理,包括丢弃低分辨率图像和过滤标记为 NSFW 的内容。这一过程产生了一个经过策划的数据集,大约有 300 万张图像,每张图像都标注了高质量的接地
3.2.2.指代表达数据引擎
与主要强调对象类别名称的检测或接地数据不同,指代表达数据需要语义更丰富的自然语言描述,例如"一个穿着蓝色衬衫的人"。RexSeek33研究表明,高质量的指代表达注释应该允许一个指代表达映射到多个实例,从而促进模型学习灵活且上下文感知的参考接地。然而,RexSeek 依赖人工注释,这使得它劳动密集且本质上不可扩展。为了解决这一限制,我们设计了一个完全自动化的指代表达数据引擎,能够在没有人工
•表达生成:给定一个标注了边界框和对应类别标签的图像,我们用图像和类别信息提示 Qwen2.5-VL-7B,以生成一组指代表达。每个表达旨在自然地描述图像中存在的对象类别,模仿人类的描述。 •指点:对于每个生成的指代表达,我们使用 Molmo18,一个最先进的指代表达模型,来产生对应的空间点。尽管 Molmo 只输出点级预测,但它在理解和接地指代表达方面表现出色。 •掩码生成:我们应用 SAM39为图像中的每个真实边界框生成掩码。 •点到框关联:Molmo 产生的每个点与 SAM 生成的掩码对齐。当一个点位于掩码内时,相应的边界框与指代表达相关联,从而将语言与对象实例对齐。
对于这个数据引擎,我们使用来自 O36591、OpenImages40的图像,以及我们接地数据引擎生成的额外数据。通过这个流程,我们获得了大约 300 万张带有自动生成指代表达的图像。
3.2.3.其他数据引擎
除了接地和指代表达数据外,我们还开发了两个相对轻量级的数据引擎,用于生成指点和 OCR 数据集。
•指点数据引擎:点级监督为边界框监督提供了一种高效替代方案,尤其是在对象边界模糊或难以界定的情况下(例如,边缘、空白处或细小结构)。为了从框级监督中推导出点注释,我们采用了一种几何感知策略。给定一个边界框,SAM 首先用于获得对应的分割掩码。然后,我们计算掩码的最小面积外接旋转矩形,并将其对角线的交点作为候选点。如果这个点位于掩码内,它就被指定为该边界框的点注释。通过这种转换,我们从现有的检测数据集以及我们接地和指代表达数据引擎的输出中获得了大约 500 万个点级样本。
•OCR 数据引擎:利用 PaddleOCR2 对包含文本内容的图像进行注释,提取文本区域的多边形边界及其对应的转录内容。对于每个提取的多边形,随后计算其最小外接轴对齐矩形,以作为其边界框表示。图像来源于 COYO 数据集,产生了大约 200 万个带有 OCR 注释的图像。
总共,结合公开可用的数据集和我们注释流程生成的数据,我们获得了 2200 万张高质量的标注图像,用于训练 Rex-Omni。
4.训练管道
我们采用两阶段训练策略,如图 6 所示。在第一阶段,对 2200 万标注样本进行监督微调(SFT),采用教师指导的方法,使模型获得基本的坐标预测能力。在第二阶段,我们应用基于 GRPO 框架的强化学习,进一步通过结合几何感知奖励与行为感知优化来完善模型性能,从而解决 SFT 阶段的局限性,提升整体预测的准确性。
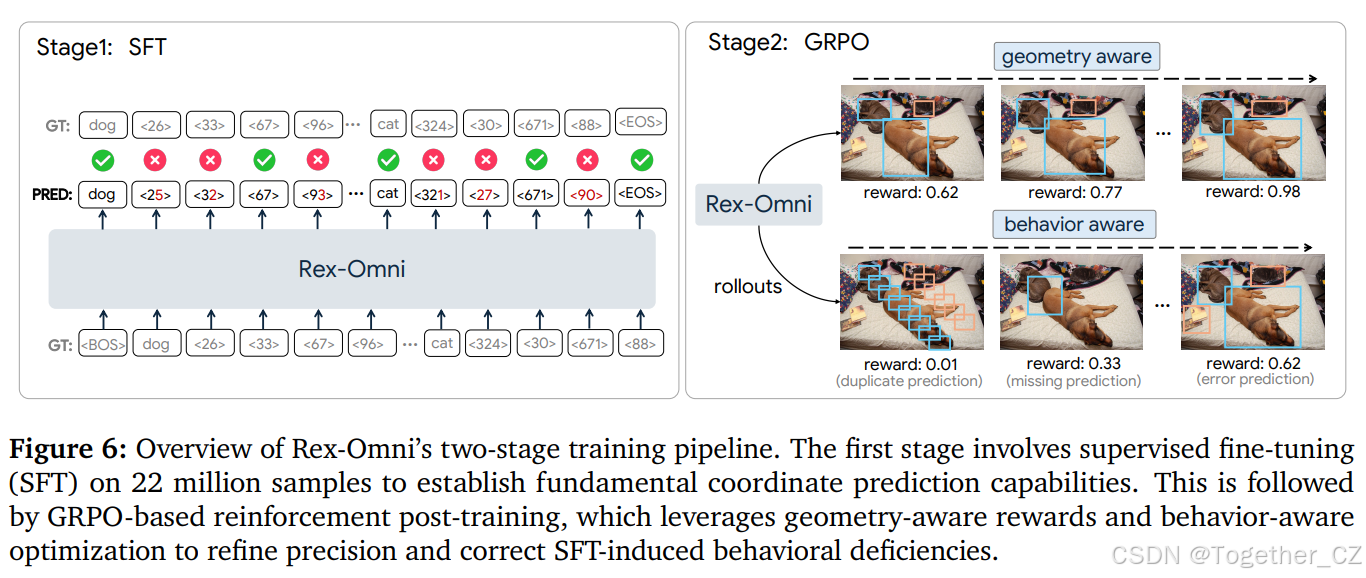
4.1.第一阶段:监督微调
由于模型以 0 到 999 的量化标记形式预测坐标,因此它首先必须学会如何准确地将这些离散值映射回图像内的连续像素位置。这对应于一个 1000 类别的分类问题,需要大量的监督才能实现可靠的性能。因此,我们从教师指导的监督微调阶段开始,在大规模标注数据上进行训练,使模型获得解释和预测空间位置的基本能力。
我们采用以下在线策略构建 SFT 对话数据:
•对话模板:针对每个训练任务,我们使用 GPT-4o 构建多个问题模板,以模仿真实用户场景。这些模板包含 PHRASE 关键词的占位符,这些占位符在训练期间被数据中的实际短语替换。 •多短语查询:在实际设置中,用户可能希望在单张图像中检测多个对象类别。为了反映这一点,如果图像包含 N 个标注短语,我们随机采样 1 到 N 个短语来形成训练查询。 •视觉提示训练:遵循 T-Rex232,对于每个由图像及其标注类别特定边界框组成的训练样本,我们模拟视觉提示场景。具体来说,对于图像中的每个类别,我们随机采样 1 到 N 个边界框(其中 N 表示该类别的最大标注实例数)。这些采样的框被视为视觉提示,并转换为与我们的坐标公式化一致的量化坐标标记。然后,模型通过自然语言查询被指示检测与给定视觉提示属于同一类别的所有对象。
我们采用标准的交叉熵损失进行训练。模型在 8 个节点上进行训练,每个节点配备 8 个 A100 GPU,总训练时间约为 8 天。所有模型参数在训练期间都得到更新。我们为不同组件使用不同的学习率:视觉编码器为 2e-6,投影层和 LLM 均为 2e-5。使用 AdamW64 优化器进行优化,学习率预热为 3%,权重衰减为 0.01。按照 Qwen2.5-VL 的架构,Rex-Omni 也采用原生分辨率的 Vision Transformer 作为其视觉编码器。我们将输入像素的数量限制在最小 16×28×28 到最大 2560×28×28 之间。鉴于 ViT 的块大小为 28,这限制了图像标记的数量在 16 到 2560 之间。
4.2.第二阶段:强化后训练
4.2.1.SFT 的局限性
尽管 SFT 让模型能够通过利用大量标注数据快速获得基本的坐标预测能力,但它存在两个关键局限性:
几何离散化问题。在坐标预测中使用交叉熵损失本质上引入了一个离散化问题。坐标被表示为类别标记(从<0>到<999>),模型被训练为精确分类每个标记。然而,这种公式化与空间任务中几何的连续性不一致。例如,如果真实标记是<33>,但模型预测为<32>,像素空间中的差异可能微不足道,但 CE 损失却将其视为完全错误的预测。相反,如果真实标记是<0><0><100><100>,而模型预测为<0><0><100><1000>,只有一个标记被错误分类。在这种情况下,CE 损失仍然相对较小,尽管导致的边界框严重错位,几何误差
行为调节缺陷。在 SFT 阶段,教师强制训练依赖于完整的真值序列,以实现高效的并行学习。这种设置将预测框的数量固定为真实值数量,防止模型自主学习要预测多少个对象。因此,在推理时,模型往往无法调节输出数量,导致两种典型错误:(1)预测的框少于所需数量(漏检),或(2)预测的框多于所需数量(重复预测,坐标略有偏移)。这些行为反映了模型在有效输出调节方面的缺乏。这些行为反映了模型在有效输出调节方面的缺乏。
4.2.2.基于 GRPO 的后训练

这个框架自然地缓解了几何和行为的局限性:1)奖励可以是几何感知的,例如 IoU 或 L1 距离度量,直接鼓励超出标记级正确性的准确空间对齐;2)通过允许可变长度的输出,模型可以学会避免重复或过度生成。重复或冗余的预测会获得较低的奖励,从而导致更简洁且行为对齐的响应。
4.2.3.几何感知奖励
为了对预测的空间质量提供信息反馈,我们设计了三种几何感知奖励函数,以适应不同任务:边界框 IoU 奖励、点在掩码内奖励和点在框内奖励。这些奖励类型反映了预测输出相对于真实标注的结构正确性。
边界框 IoU 奖励。该奖励适用于需要边界框预测的任务,包括目标检测、接地、指代和 OCR。该奖励鼓励准确的定位和正确的对象类别对齐。

其中 ϵ 是一个小常数,以防止除以零。这种公式化奖励了空间准确性和标签正确性。它惩罚了未匹配或错误分类的预测,并通过 F1 风格的奖励信号平衡过度和不足的预测。
点在掩码内奖励。该奖励适用于模型通过点预测定位对象的任务,如基于点的检测、接地和指代。它评估预测点是否位于对象掩码内。

点在框内奖励。该奖励专门设计用于 GUI 接地任务,模型需要预测一个点,指示图形用户界面(例如,按钮)上的可点击位置。如果预测点落在目标 GUI 元素的真实边界框内,则分配 1 的奖励;否则,奖励为 0。这种简单的二元奖励有效地鼓励了在 GUI 场景中所需的精确点级交互行为。
4.2.4.实现细节
我们从 SFT 数据集中采样 66K 数据,作为 GRPO 阶段的训练数据。我们重用了 SFT 阶段的相同对话模板。GRPO 训练在 8 个 A100 GPU 上进行,大约持续 24 小时。我们将 rollout 大小设置为 8,KL 惩罚系数 β 设置为 0.01,并使用 64 的批量大小。在这一阶段,所有模型参数都得到更新。
5.基准测试结果
本节介绍了 Rex-Omni 在多个视觉感知任务上的评估结果,例如常见的目标检测、长尾目标检测、密集目标检测、目标指代表达理解以及目标指点。对于每个任务,我们概述了基准数据集、实验设置和评估指标。
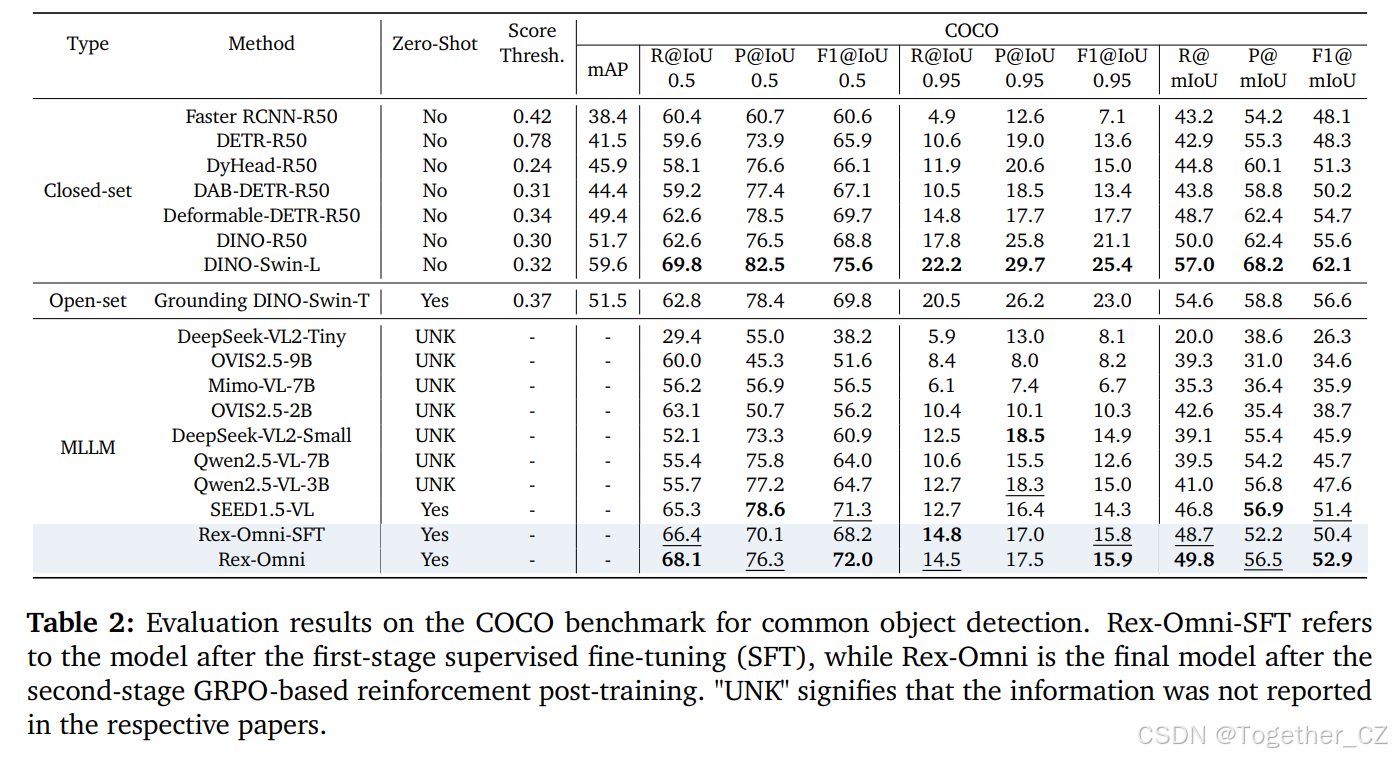
5.1.常见目标检测
常见目标检测是指从预定义的类别集合中检测频繁出现在现实世界场景中的对象。这一任务的目标是评估模型识别和定位这些常见对象的基本能力。
基准测试:我们在 COCO54 数据集上进行评估,这是目标检测领域中最广泛使用的基准之一。该数据集包括 5000 张测试图像,涵盖 80 个不同的目标类别,代表了一系列常见的对象。
评估设置:我们评估了我们提出的模型的两个变体:仅经过第一阶段监督微调的 Rex-Omni-SFT,以及经过两阶段训练(包括 GRPO 强化后训练)的完整 Rex-Omni 模型。我们将这些变体与以下三类模型进行比较:1)在 COCO 上训练的封闭集检测模型,包括 Faster R-CNN87、DETR8、DyHead17、DAB-DETR58、Deformable-DETR134 和 DINO122;2)未在 COCO 上训练的开放集检测模型 Grounding DINO59;3)多模态大型语言模型(MLLM),包括 DeepSeek-VL2110、Ovis2.565、MiMo-VL100、Qwen2.5-VL4 和 SEED1.5-VL24。对于封闭集检测模型,我们输入图像,并仅保留预测边界框中类别与每张图像中的真实标签匹配的结果。对于开放集模型,我们提供所有真实类别作为文本提示,并保留相应结果。对于 MLLM,我们采用两种提示策略:(1)一次查询一个真实类别(例如,"在图像中检测狗"),以及(2)同时查询所有真实类别(例如,"在图像中检测狗、猫、人")。尽管后者在现实世界场景中更具实用性,但大多数 MLLM 在同时处理多个类别时性能会下降。因此,除了 SEED1.5-VL 和 Rex-Omni 之外,我们使用单类别策略。所有对 Rex-Omni(包括 SFT 和完整版本)的评估均在采样温度为 0 的情况下进行,以最小化
评估指标:在目标检测中,标准指标是平均精度(AP),它依赖于置信度分数来计算不同阈值下的精确率和召回率。然而,多模态模型通常缺乏可靠的置信度估计,使得 AP 不适用。因此,我们采用召回率、精确率和 F1 分数作为评估指标。给定预测和真实边界框,按类别计算召回率和精确率,然后取平均值,F1 分数则是它们的调和平均值。按照 COCO 的惯例,交并比(IoU)在 0.5 到 0.95(步长 0.05)的阈值范围内进行评估,并在 IoU=0.5、IoU=0.95 和所有阈值的平均值处报告结果。为了与 MLLM 公平比较,我们还计算了封闭集和开放集检测模型在 0 到 1(步长 0.01)的置信度阈值范围内的 F1 分数,并将最高的 F1 分数作为最终

结果:结果如表 2 所示。首先,在 MLLM 中,Rex-Omni 超越了现有方法,包括之前在检测方面保持最佳性能的 SEED1.5-VL。在 IoU 阈值为 0.5 时,Rex-Omni 展示了卓越的性能,超过了开放集检测模型 Grounding DINO-SwinT 和封闭集检测模型 DINO-R50。至关重要的是,Rex-Omni 在零样本设置中(未在 COCO 数据上进行训练)实现了这一点,这表明基于 MLLM 的检测方法确实可以在精确边界框定位不是唯一关键因素的情况下超越传统的回归模型。然而,在更严格的 IoU 阈值 0.95 下,尽管 Rex-Omni 的表现仍然强劲,但仅略微超过了 DAB-DETR,这表明 MLLM 可能在需要极高精确度的边界框定位场景中仍然落后于传统的回归模型。
尽管存在这一细微的局限性,但所实现的性能通常足以满足广泛的现实世界应用需求。我们在图 7 中展示了一些可视化结果。此外,通过 GRPO 后训练,完整 Rex-Omni 模型与仅 SFT 版本(Rex-Omni-SFT)相比有了显著提升。这清楚地突显了我们强化学习的有效性。
5.2.长尾目标检测
长尾目标检测旨在解决识别具有高度不平衡实例分布的类别的挑战,其中大多数类别很少出现。这一任务要求模型能够有效地泛化并稳健地检测现实世界中的罕见对象。
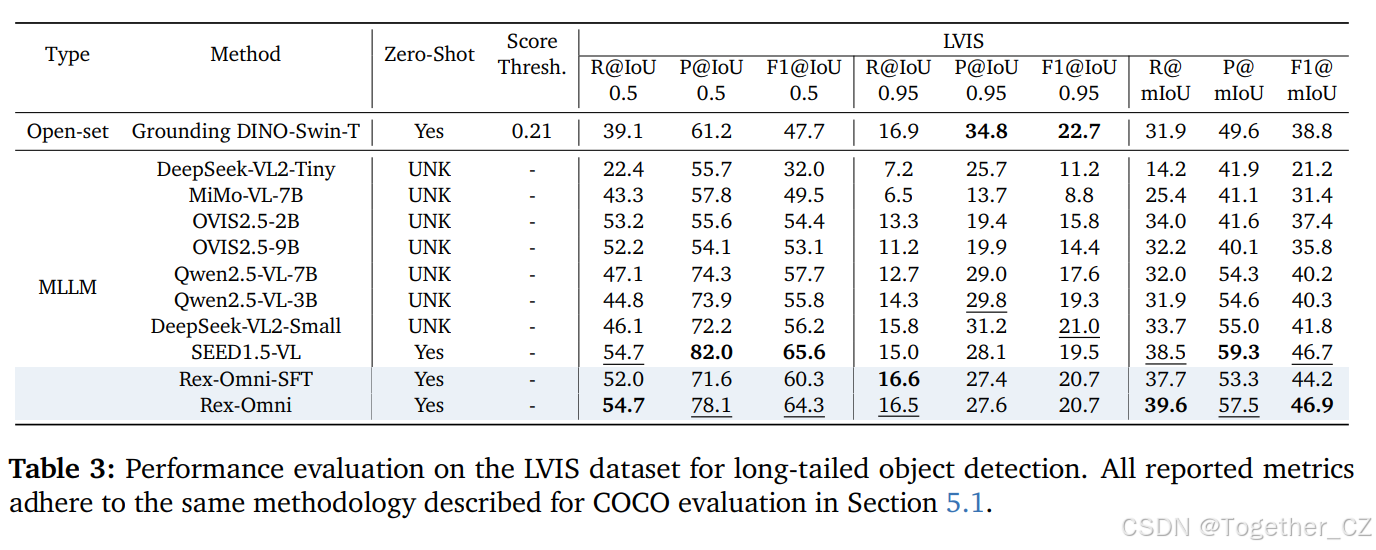
基准测试:我们在广泛使用的 LVIS25 数据集上进行评估。LVIS 包含 1203 个类别,显著多于 COCO 的 80 个类别,拥有 19626 张测试图像。其类别源自 WordNet 同义词集,并且有意按照现实世界的频率分布,导致许多类别只有很少的
评估设置和指标:我们按照第 5.1 节中描述的相同评估设置和指标对开放集检测模型和 MLLM 进行评估
结果:结果如表 3 所示。在 LVIS 上,MLLM 通常优于传统的开放集检测模型,如 Grounding DINO,因为它们的 LLM 组件相比传统文本编码器(例如,CLIP 或 BERT)具有更强的语言理解能力,从而能够更好地泛化到低频类别。
在零样本设置中,Rex-Omni 实现了具有竞争力的性能,其在 IoU=0.5 时的 F1 分数仅次于 SEED1.5-VL,这可能是因为后者具有更大的模型规模和更强的语言理解能力。值得注意的是,Rex-Omni 在 mIoU 指标上取得了最佳结果,反映了其在不同阈值下边界框精度的优越性。此外,从 Rex-Omni-SFT 到完整 Rex-Omni 模型的显著提升进一步证明了基于 GRPO 的强化后训练在提升目标定位方面的有效性。定性结果如图 7 和图 19 所示。
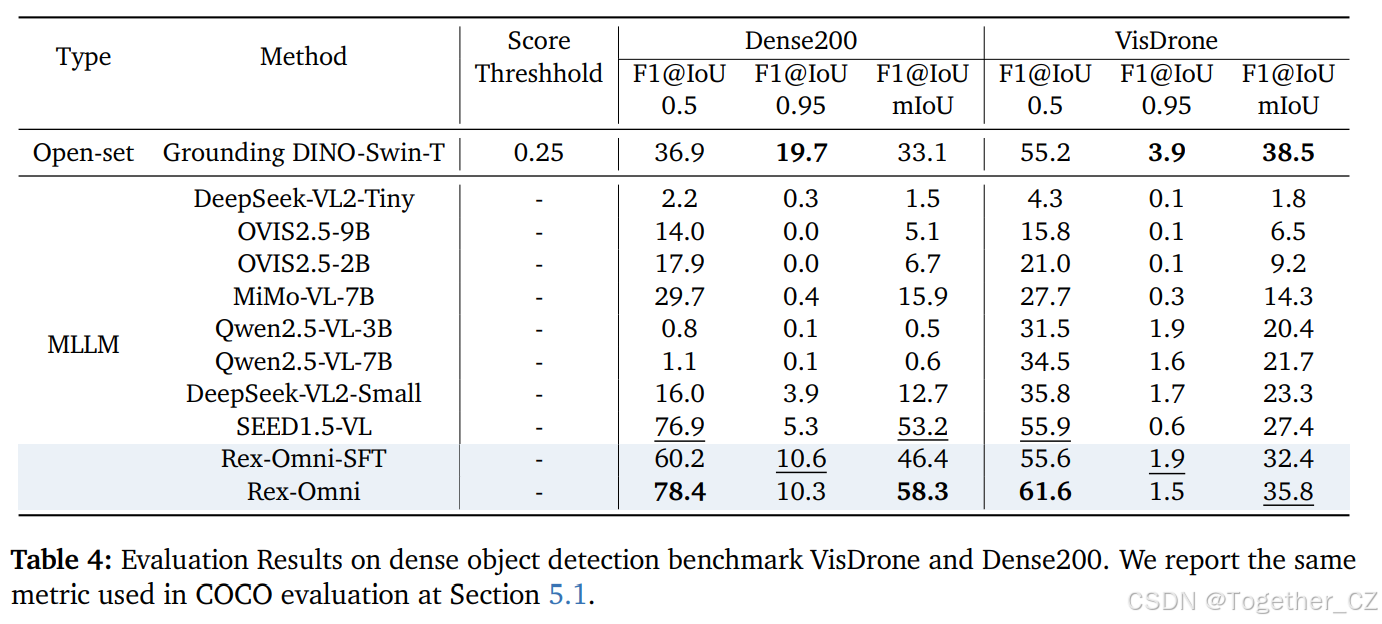
5.3.密集和微小目标检测
密集和微小目标检测对于遥感和目标计数等应用至关重要,它要求能够准确地定位拥挤场景中的大量小目标。对于 MLLM 来说,这一任务尤其具有挑战性:它不仅要求对微小的像素变化敏感的精确、扩展的坐标预测,还暴露了传统回归检测器所利用的多尺度特征机制(例如,特征金字塔55)的缺失,这些机制用于处理尺度多样性。因此,MLLM 通常在密集和微小目标检测场景中面临重复预测和坐标偏移等问题。

基准、设置和指标:我们在两个专门用于密集和微小目标检测的数据集上评估开放集检测模型和 MLLM。第一个数据集是 VisDrone19,包含 1610 张航拍交通图像,涵盖 10 个类别,每个框的平均大小约为 30.7×32.4 像素。此外,我们引入了 Dense200,这是一个手动收集的数据集,包含 200 张密集标注的图像,涵盖 109 个类别。在 Dense200 中,每张图像平均包含 91.2 个边界框,平均大小为 66.8×64.5 像素。这两个数据集结合了小目标尺寸和高目标密度,对精确的空间推理和准确的定位提出了重大挑战,要求模型具备精细的空间推理和准确的定位能力。评估设置和指标与第 5.1 节中用于 COCO 评估的相同。
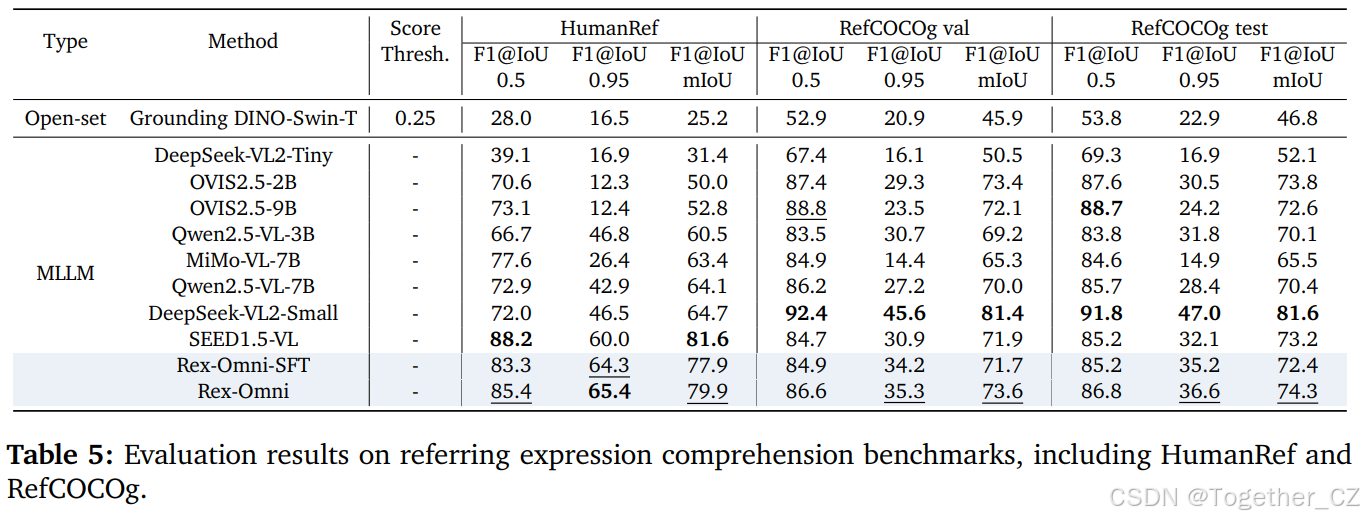

结果:结果如表 4 所示,代表性可视化结果如图 8 和图 20 所示。正如预期的那样,MLLM 在密集和微小目标检测方面表现不佳,大多数模型的性能都很差。我们识别出两个关键的失败模式:(1)大框预测,一个过大的边界框错误地覆盖了多个相邻对象;(2)结构化重复预测,生成了一系列仅略有偏移的重复坐标,而不是独立的对象实例。
我们归因于 SFT 阶段。教师强制训练依赖于完整的真值序列,限制了模型在推理时自主调节输出结构的能力。在没有这种指导的情况下,模型无法决定对象数量或避免冗余预测。值得注意的是,我们在仅 SFT 变体中也观察到了这种重复预测的问题。至关重要的是,在基于 GRPO 的强化后训练之后,这些重复问题基本消失,有力地证明了我们的两阶段管道在纠正 SFT 引起的缺陷以及在密集和微小目标检测场景中实现更连贯、准确的预测方面的有效性。
5.4.目标指代表达理解
目标指代表达理解要求模型能够识别并定位由自然语言表达描述的对象。与主要关注类别级别识别的标准目标检测不同,这一任务要求对语言描述进行细粒度的理解,并在视觉内容中找到与之匹配的对象实例。
基准测试:我们在两个已建立的公共基准测试上进行评估:1)RefCOCOg(val/test):RefCOCOg70 基于 COCO 图像构建,包含 4889 个验证和 9577 个测试指代表达。每个表达式映射到一个真实边界框,这使得该基准测试相对简单,便于评估。2)HumanRef:HumanRef33 是一个专注于人物的基准测试,包含 6000 个测试表达式,分为六个子集:属性、位置、交互、推理、名人和拒绝。我们使用前五个子集(5000 张图像)进行评估。与 RefCOCOg 不同,HumanRef 中的一个表达式可能对应多个真实框,平均每个表达式对应两个。这种设计提出了更大的挑战,要求模型具备细粒度的语言理解和稳健的视觉
评估设置和指标:我们按照第 5.1 节中描述的相同设置和指标对开放集检测模型和 MLLM 进行评估,唯一的区别是:在测试期间,模型一次仅用一个指代表达式进行查询。对于开放集检测器 Grounding DINO,我们采用其官方演示的置信度阈值
结果:结果如表 5 所示。开放集检测模型在这一任务上表现不佳,这从 Grounding DINO 在各个基准测试中持续的低性能表现中可以看出。相比之下,MLLM 凭借其固有的强大语言理解能力,在这一任务上表现出色。在 HumanRef 上,Rex-Omni 取得了具有竞争力的结果,仅排在 SEED1.5-VL 之后。这表明,尽管 Rex-Omni(3B 参数)具备足够的语言理解能力以实现有效的 REC,但像 SEED1.5-VL 这样更大的模型从更大的容量中受益,能够进行更精细的推理。总体而言,Rex-Omni 在所有数据集上的强劲表现证明了其将自然语言与视觉内容对齐的能力,使其在现实世界的指代场景中极具实用性。可视化示例如图 9 和图 17 所示。
5.5.视觉提示
尽管文本提示被广泛应用于许多任务,但它们存在固有的局限性,尤其是在某些对象难以用语言描述时。在这种情况下,视觉提示可以为对象检测提供一种更有效的替代方法。在本节中,我们将视觉提示定义为一个任务:给定一张图像以及图像中的几个示例边界框,模型需要检测出与这些示例框指示的类别相同的其他所有对象。
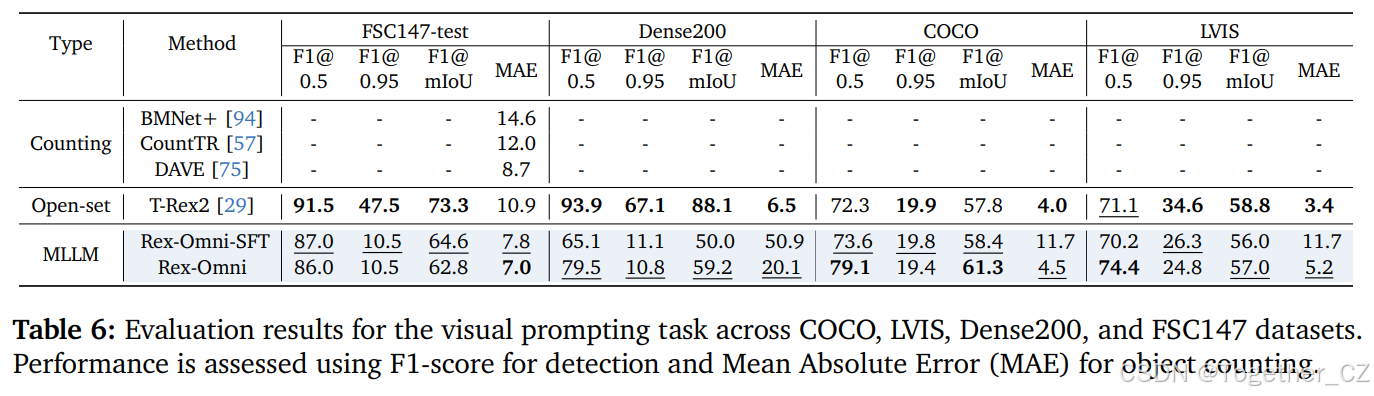
基准和评估设置:我们在 FSC14783 数据集上评估视觉提示,该数据集包含 1190 张图像,每张图像都包含一个单一类别的密集对象集合以及三个示例边界框,这些边界框用作视觉提示以进行检测。对于 COCO、LVIS 和 Dense200,我们遵循 T-Rex229 的方法,即对于图像中的每个真实类别,随机采样一个边界框作为该类别的视觉提示。为了与 Rex-Omni 进行交互,将选定的视觉提示框的坐标转换为特殊标记,并嵌入到查询中,例如:"给定参考框 <12><52><212><337>,指示一个或多个对象,找出图像中属于同一类别的所有对象。"
评估指标:我们主要采用在第 5.1 节中描述的 F1 分数来评估对象检测的性能。此外,我们引入了平均绝对误差(MAE)指标,以评估模型的对象计数能力。MAE 通过计算预测对象数量与真实对象数量之间的绝对差值,并在整个数据集上取平均值,从而为模型准确计数对象的能力提供了额外的衡量标准。
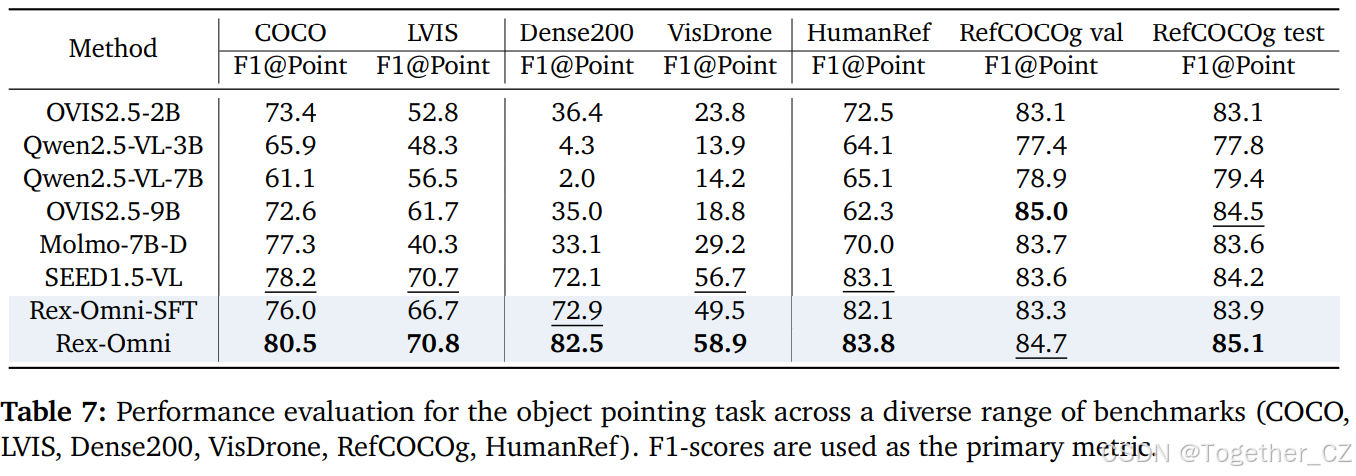
结果:尽管 Rex-Omni 的整体性能仍然不及传统的专家模型T-Rex2,但它展示了强大的视觉提示能力。特别是,Rex-Omni 在密集场景和长尾场景中表现良好,突显了其在应对高目标密度和严重类别不平衡问题方面的有效性。代表性可视化结果如图 17 所示。
5.6.目标指点
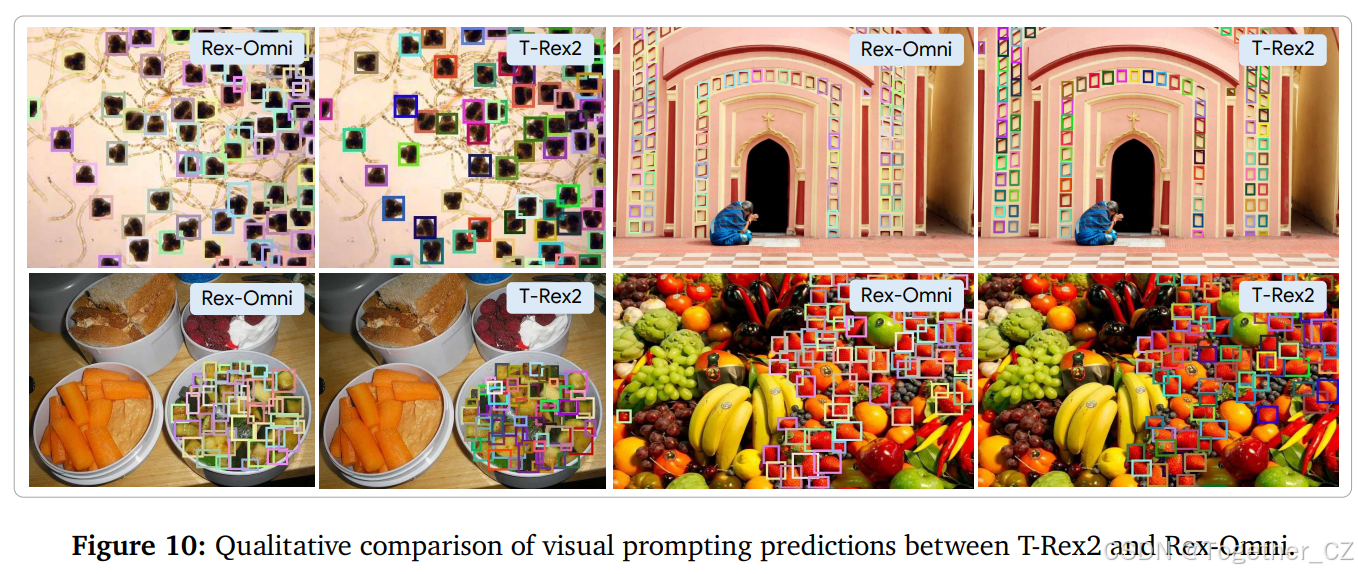
目标指点任务要求模型为指定的目标对象预测精确的点坐标。与边界框不同,点注释在定位方面提供了更大的灵活性,因为模型可以指示对象的中心或任何代表位置。

基准、评估设置和指标:为了评估目标指点,我们将之前用于基于框检测的数据集整合起来,包括 COCO、LVIS、Dense200、VisDrone、RefCOCOg 和 HumanRef。这一集合涵盖了从常见和长尾目标到密集小目标以及复杂指代表达式的广泛视觉场景。评估协议遵循早期检测任务的协议。对于大多数模型,除了 SEED1.5-VL 和 Rex-Omni 之外,每张测试图像一次仅用一个真实类别进行查询。我们采用与基于边界框检测相同的 F1 分数评估指标,唯一的修改是匹配标准。对于每个真实边界框,我们使用 SAM 生成一个分割掩码,如果预测点位于相应的掩码内,则认为该预测点是正确的。然后,类似地计算召回率、精确率和 F1 分数。
结果:所有评估模型的性能如表 7 所示。尽管大多数 MLLM 在常见目标类别上实现了合理的指点精度,但在密集或小规模实例上,它们表现不佳,尤其是在 Dense200 和 VisDrone 上。Rex-Omni 在涵盖一般和挑战性数据集的 F1 分数上均取得了最高分,突显了其强大的空间定位能力。代表性可视化结果如图 11 和图 22 所示。
5.7.GUI 接地
图形用户界面(GUI)接地评估模型根据自然语言查询定位特定 UI 元素的能力。这一任务对于智能代理、自动化 UI 交互和软件测试等应用至关重要,因为它要求视觉感知和语言理解的无缝整合。
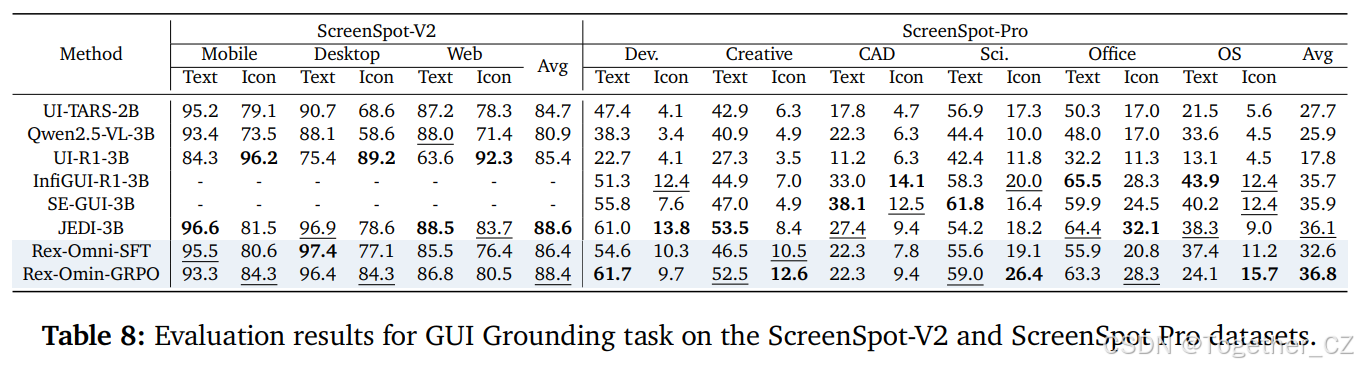
基准、评估设置和指标:我们在两个数据集上评估模型:ScreenSpot-V2109 和 ScreenSpot-Pro48。ScreenSpot-V2 涵盖移动、桌面和网络场景,包含 1272 张图像,具有多样化的 UI 布局。ScreenSpot-Pro 则专注于超高分辨率界面,旨在测试模型在极具挑战性的视觉条件下定位 UI 元素的精度,包含 1581 张图像。Rex-Omni 使用其基于点的预测能力进行评估,为每个查询输出目标 UI 元素内的一个点。按照标准协议,我们报告准确率,如果预测点落在真实边界框内,则认为该预测是正确的。
结果:如表 8 所示,Rex-Omni 在 GUI 接地任务上表现出色。具体来说,在 3B 参数模型中,Rex-Omni 在 ScreenSpot V2 和 ScreenSpot Pro 上均实现了最高的准确率。这突显了其将强大的语言理解能力与精细的视觉定位能力无缝整合的卓越能力,即使在多样化和超高分辨率的 UI 场景中也是如此。
5.8.布局接地
布局接地要求模型能够定位并解释文档中元素的空间关系,例如标题、段落、章节和图表。这一任务对于文档布局分析和网页理解等应用至关重要,因为它不仅需要目标检测,还需要对结构安排和语义关系进行推理。
基准、评估设置和指标:我们在 DocLayNet78 和 M6Doc12 数据集上评估我们的模型。DocLayNet 从 PDF 文档中收集,包含 11 个类别,如脚注、图片、表格和标题,测试集包含 6480 张图像。M6Doc 数据集更为复杂,涵盖多个领域(例如,科学文章、教科书、试卷、杂志、报纸、笔记、书籍)的数据,共有 74 个类别,2724 张测试图像。对于评估,我们将这一任务视为目标检测问题,遵循用于 COCO 常见目标检测的相同评估协议。
结果:结果如表 9 所示。Rex-Omni 在布局接地任务上大幅领先于其他 MLLM。尽管与封闭集模型相比仍有性能差距,但 Rex-Omni 在开放集布局接地方面的独特优势使其能够处理未见领域和新布局结构,使其成为现实世界布局理解任务中更具通用性和适应性的解决方案。代表性可视化结果如图 12 和图 17 所示。

5.9.OCR
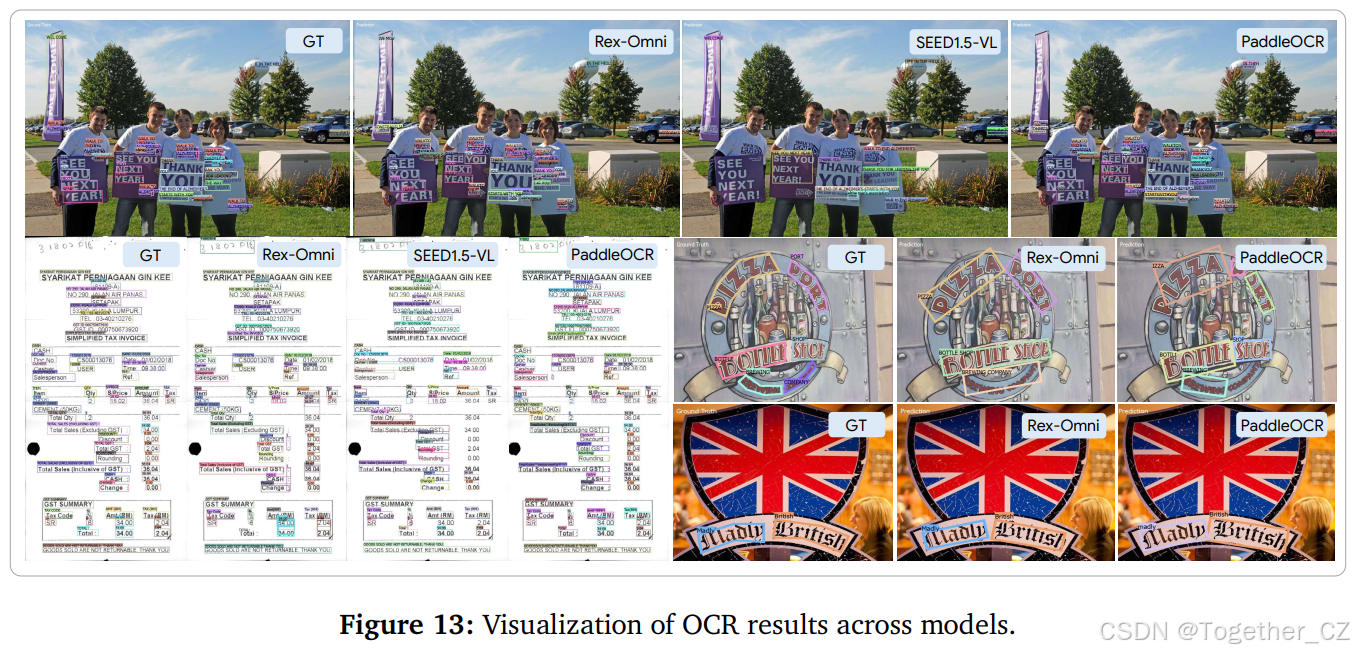
光学字符识别(OCR)涉及文本检测和识别,模型需要从图像或文档中识别并提取文本。该任务要求模型检测文本区域,然后识别这些区域内的字符或单词,从而将扫描的文档或图像转换为机器可读的格式。
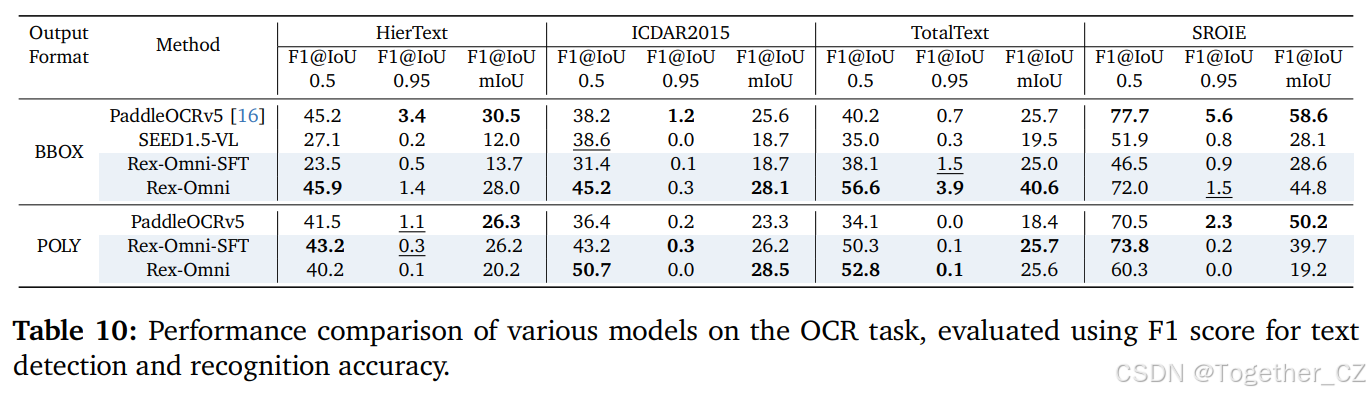
基准、评估设置:我们在四个多样化的数据集上评估 PaddleOCR、SEED1.5-VL 和 Rex-Omni 的性能。这些数据集包括 HierText(3446 个实例,主要是密集文本)、TotalText(600 个实例,场景文本,主要是弯曲文本)、ICDAR2015(1000 个实例,场景文本)和 SROIE(720 个实例,主要是水平文本的打印收据数据)。这些数据集涵盖了从密集和弯曲的场景文本到结构化文档文本的广泛 OCR 挑战。对于 PaddleOCR 和 Rex-Omni,预测边界框(BBOX)和多边形(POLY)文本区域,并报告两种格式的性能,以全面评估文本定位。
评估指标:我们将 OCR 视为目标检测任务,遵循 COCO 评估协议,将类别替换为识别的文本。如果(1)预测和真实区域匹配,且(2)识别的文本与真实文本完全匹配,则认为预测是正确的。性能使用 F1 分数报告,平衡精确率和召回率。
结果:OCR 任务的评估结果如表 10 所示。对于边界框(BBOX)输出,Rex-Omni 展示了强大的竞争力。它在所有指标和数据集上均显著优于 SEED1.5-VL,并在几个关键方面实现了与专门的 OCR 专家模型 PaddleOCRv5 相当或更好的结果。这突显了 Rex-Omni 在使用边界框进行文本检测和识别方面的强大能力。在多边形(POLY)输出格式中,Rex-Omni 也展示了竞争力。完整版的 Rex-Omni 模型在 ICDAR2015 等具有挑战性的数据集上实现了领先的多边形文本区域检测结果,表明了我们方法在处理更复杂文本几何形状方面的多功能性。从 Rex-Omni-SFT 到 Rex-Omni 的持续改进进一步验证了我们的两阶段训练管道在提升 OCR 性能方面的有效性。代表性可视化结果如图 13 和图 24 所示。
5.10.空间指点
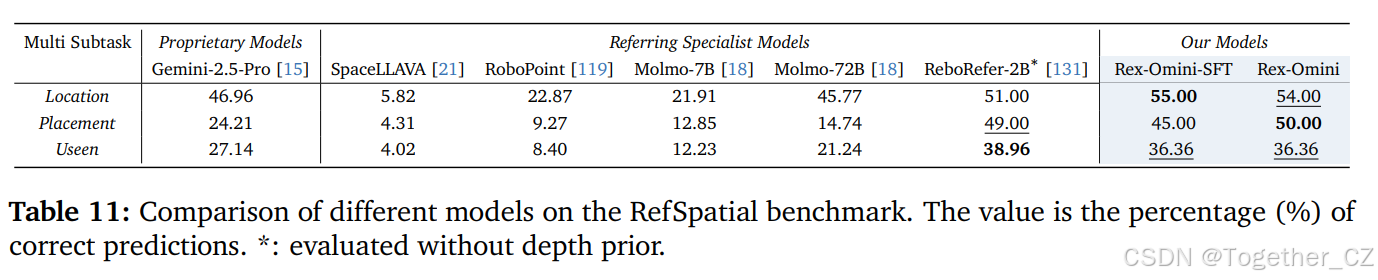
该任务侧重于对复杂场景中描述空间关系的自然语言表达式进行接地。与主要匹配对象类别名称或简单属性的标准指代表达理解不同,空间接地要求模型解释相对位置、锚点和自由空间等关系线索。
基准和指标:RefSpatial-Bench131 在复杂室内场景中评估空间指代和推理,涵盖两个任务:位置和放置,每个任务包含 100 个精心策划的样本。每个样本包括一张图像、一个自然语言指代表达式和精确的掩码标注。位置任务要求模型根据可能涉及颜色、形状、空间顺序或基于锚点的参考等属性的指代表达式,预测目标对象对应的 2D 点。放置任务要求在表达式描述的自由空间内识别一个合适的 2D 点,通常涉及多个锚点或层次化的空间关系。为了评估泛化能力,基准还提供了 77 个未见样本,包含训练中不存在的新空间关系组合。评估使用真实掩码进行,准确率定义为落在掩码内的预测百分比。
结果:如表 11 所示,Rex-Omni 显著领先于先前的专有模型和指代表达专家模型。其在位置和放置任务上的强劲表现表明,其在下游场景(如机器人操作中准确抓取和放置)中的适用性增强。此外,Rex-Omni 在未见案例上的卓越泛化能力突显了其在处理新空间关系方面的稳健性。代表性可视化结果如图 17 所示。

5.11.关键点检测
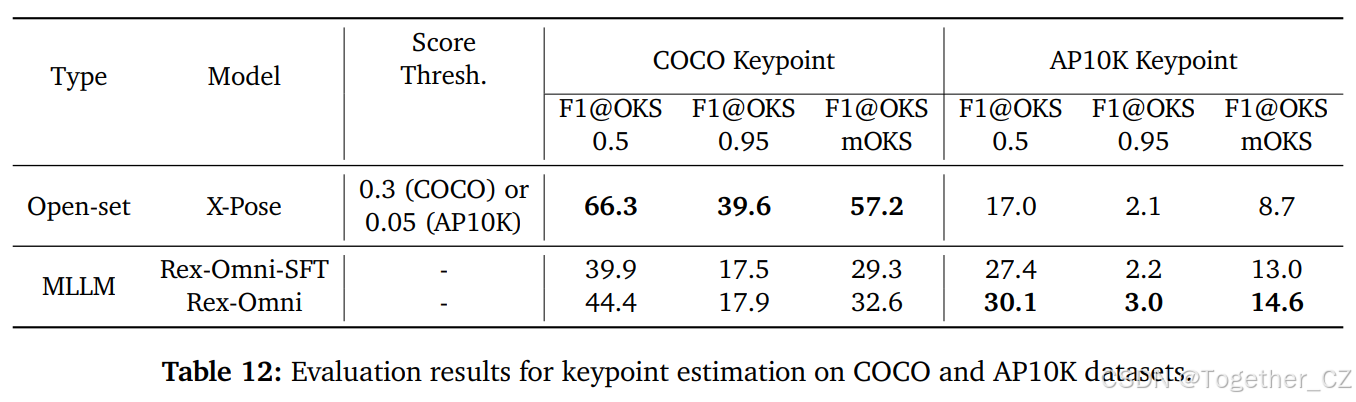
基准、评估设置和指标:COCO 是一个旨在评估复杂自然场景中 2D 人体姿态估计和实例级关键点检测能力的基准数据集。它包含大量图像,涵盖多样化的人体姿态。每个标注的人体实例包括一组 17 个预定义的身体关节,形成标准人体骨架。AP10K 是一个旨在推动 2D 动物姿态估计领域发展的基准,解决了跨物种的解剖学变化挑战。该基准统一定义了哺乳动物、爬行动物和鸟类的 17 个身体关键点的标注。遵循 COCO 协议,我们采用目标关键点相似度(OKS)作为评估指标。我们在 OKS 阈值为 0.5、0.95 以及从 0.5 到 0.95(增量为 0.05)的平均阈值上报告 F1 分数。
结果:如表 12 所示,开放集专家模型 X-Pose 在 COCO 关键点检测方面实现了最强性能,尤其是在较低的 OKS 阈值下。然而,它在 AP10K 上的泛化能力较差,性能急剧下降。相比之下,Rex-Omni 在人类和动物关键点基准测试中均实现了更平衡的结果。尽管其在 COCO 上的绝对分数落后于 X-Pose,但 Rex-Omni 在 AP10K 上大幅领先于 X-Pose,突显了其在跨领域泛化方面的优势。此外,从 Rex-Omni-SFT 到完整 Rex-Omni 模型的一致改进进一步验证了我们的两阶段训练管道在提升关键点推理方面的有效性。代表性可视化结果如图 15 所示。

6.对 Rex-Omni 的深入分析
在本节中,我们进行全面分析,以调查并阐明 Rex-Omni 的关键设计组件的有效性。我们的目标是深入了解每个架构选择、训练策略(包括 GRPO 的作用)以及数据设计如何共同影响模型在各种视觉感知任务中的整体性能。
6.1.为什么 GRPO 起作用
Rex-Omni 采用两阶段训练策略,首先进行监督微调(SFT),然后是基于 GRPO 的强化学习。在所有坐标预测基准测试中,经过 GRPO 增强的模型始终优于仅经过 SFT 的模型。为了探究这些改进的来源,我们分析了模型的行为,并强调 GRPO 有效纠正的关键错误模式。
6.1.1.训练动态
为了更好地了解 Rex-Omni 如何获得视觉感知能力,我们分析了 SFT 和 GRPO 阶段的性能轨迹,随着训练的进行(以数据量衡量)。图 16 展示了随着训练步骤的增加(以数据量衡量),模型在代表性基准测试上的性能。
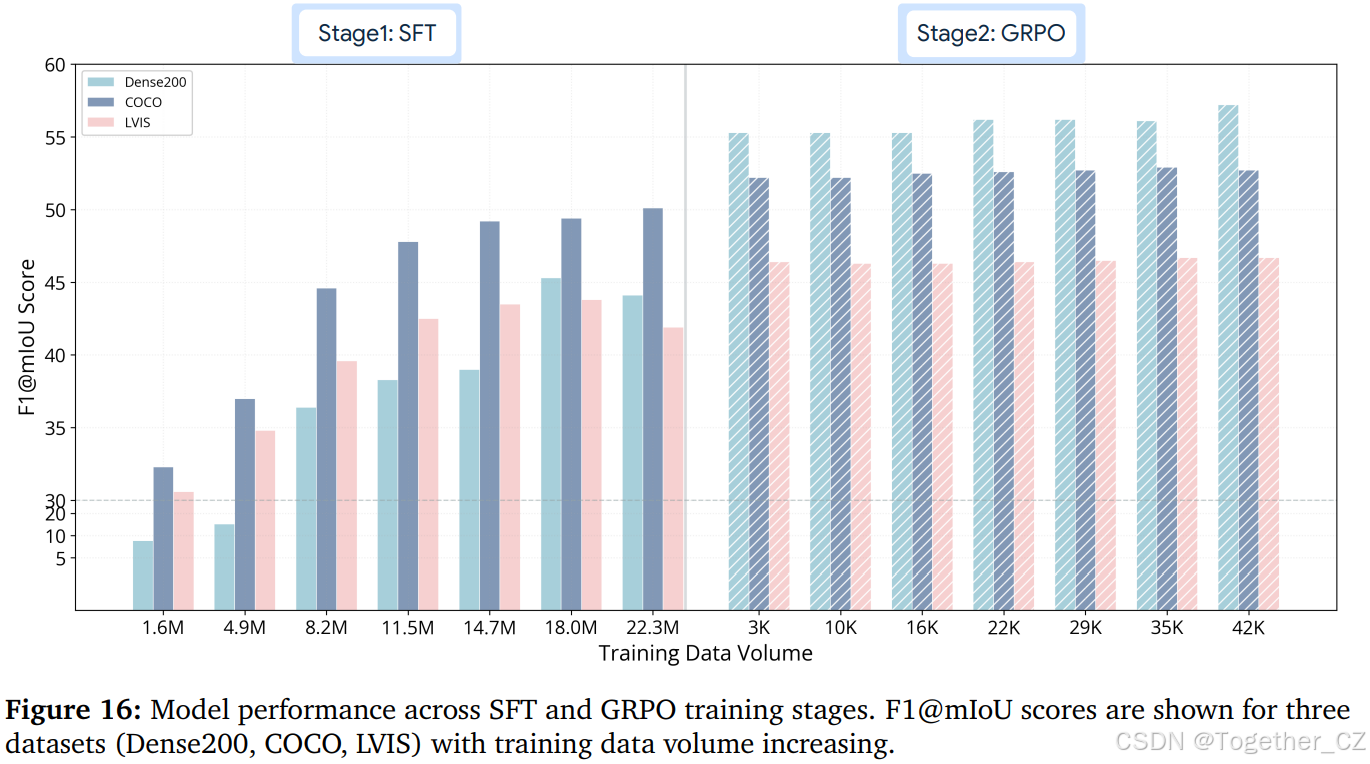
在 SFT 阶段,性能呈现出稳定且逐渐的提升。随着模型接触更多训练数据,它逐步学会将视觉输入与坐标输出对齐,从而在各个基准测试中实现一致但逐步的增益。然而,一旦 SFT 结束,性能趋于平稳,表明通过额外的监督暴露实现的进一步改进有限。相比之下,GRPO 阶段产生了截然不同的轨迹。

在仅进行少量训练步骤后,模型在各基准测试中经历了快速的性能提升。值得注意的是,这种改进不可能仅归因于更多的数据暴露,因为 GRPO 阶段涉及的样本数量远少于 SFT。相反,结果表明,经过 SFT 训练的模型已经具备强大的潜在能力,但这些能力未得到充分利用。GRPO 通过引入行为感知奖励和序列级反馈,有效解锁了这一隐藏潜力,使模型在几乎没有额外数据的情况下实现了显著的性能飞跃。
综上所述,这些动态表明 GRPO 的优势不在于延长监督学习,而在于重塑模型行为,以更好地利用现有能力。在接下来的小节中,我们将更深入地探讨这种改进背后的特定机制,首先从纠正 SFT 学习过程中出现的问题行为开始。
6.1.2.通过 GRPO 进行行为纠正
重复预测。一个主要的错误模式是倾向于生成重复预测。在 SFT 阶段,模型以完整的教师强制方式接受训练,这意味着它很少遇到或纠正这类问题。相比之下,GRPO 要求模型自主生成序列,并提供基于奖励的反馈。重复的坐标会获得较低的奖励,从而有效阻止重复行为,并促进更连贯的预测。
为了验证这种效应,我们分析了仅 SFT 模型和经过 GRPO 训练的模型的预测,专注于重复输出。重复预测被定义为坐标序列中相同值至少连续出现 10 次的情况,且预测框的总数超过真值数量的两倍。我们移除这些重复项,并重新评估 F1 分数。如表 13 所示,仅 SFT 模型在移除重复项后表现出显著的性能提升(例如,在 COCO 上提升了 1.38%,在 LVIS 上提升了 15.3%,而在 VisDrone 上提升了 15.3%),而 GRPO 模型的提升微乎其微(例如,在 COCO 上提升了 0.08%,在 VisDrone 上提升了 0.1%)。这表明 SFT 训练的模型比 GRPO 训练的模型产生更多的重复预测。移除重复项后,SFT 和 GRPO 之间的性能差距大幅缩小,在密集数据集(如 VisDrone)上几乎可以忽略不计。图 17(左侧)直观地展示了这些差异。这些发现证实了 GRPO 在抑制重复预测方面的有效性,这是 Rex-Omni 总体性能提升的一个关键因素。
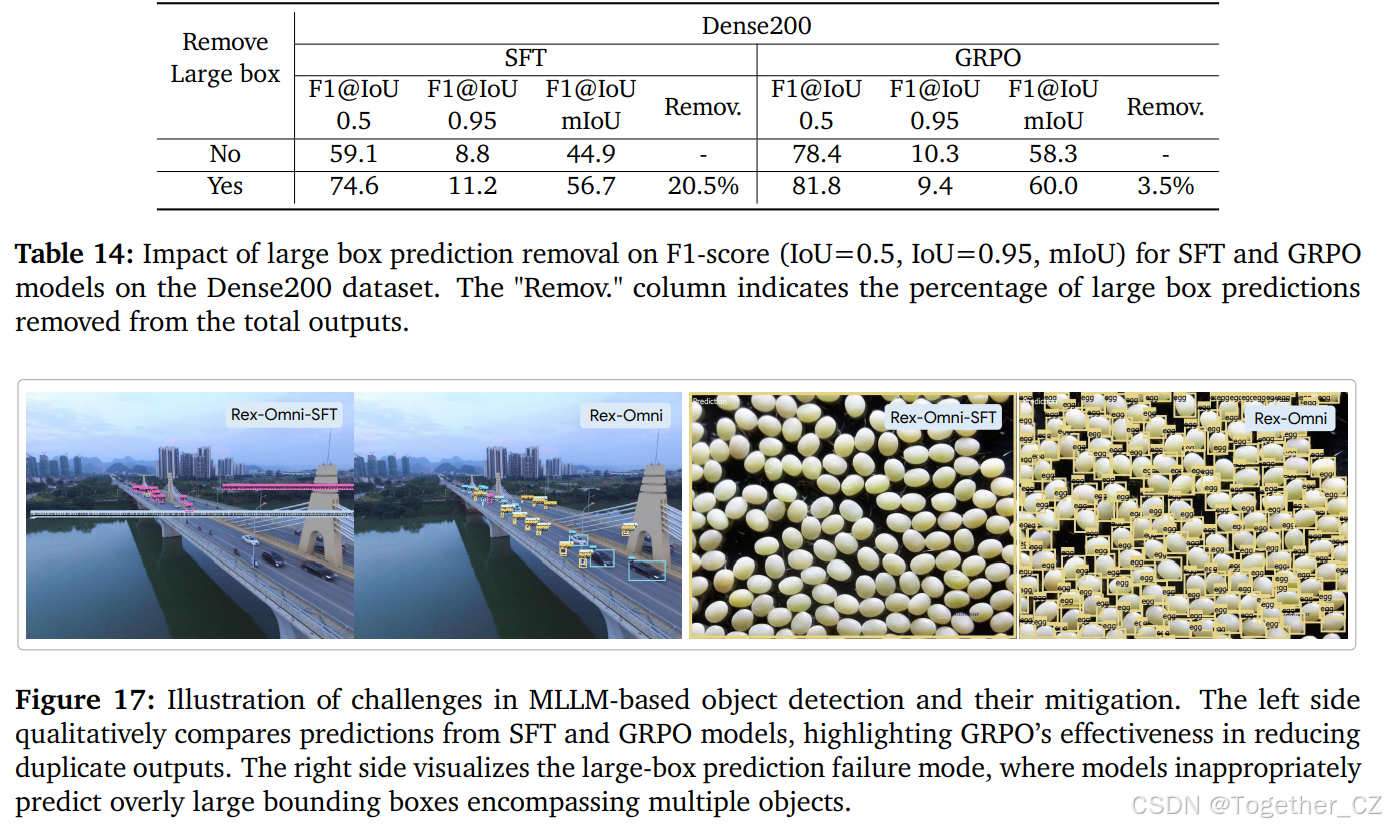
大框预测。另一个在密集目标检测场景中观察到的行为问题是,模型倾向于预测一个单一的大边界框,该框覆盖了多个密集对象。这一失败模式也在我们对密集目标检测的基准测试(第 5.3 节)中被突出强调。为了调查这一问题,我们在 Dense200 数据集上进行了实验。大框预测被定义为图像中仅预测出一个边界框,且其面积超过图像总面积 95% 的情况。然后,我们分析了仅 SFT 和 GRPO 训练模型的此类大框预测实例,并从样本总数中移除这些样本。
如表 14 所示,仅 SFT 模型在其总预测中有高达 20.5% 的预测为大框预测,这导致在移除这些大框预测后,F1 分数(例如,F1@IoU=mIoU 从 44.9 提升至 56.7)有显著提升。相比之下,经过 GRPO 训练的模型仅有 3.5% 的预测被归类为大框预测,因此在其移除后,性能变化非常小(例如,F1@IoU=mIoU 从 58.3 提升至 60.0)。这清楚地表明 GRPO 的行为感知优化有效阻止了模型在密集场景中产生过度覆盖的大边界框。图 17(右侧)以视觉方式展示了这种失败模式的示例。
6.1.3.坐标精度提升?
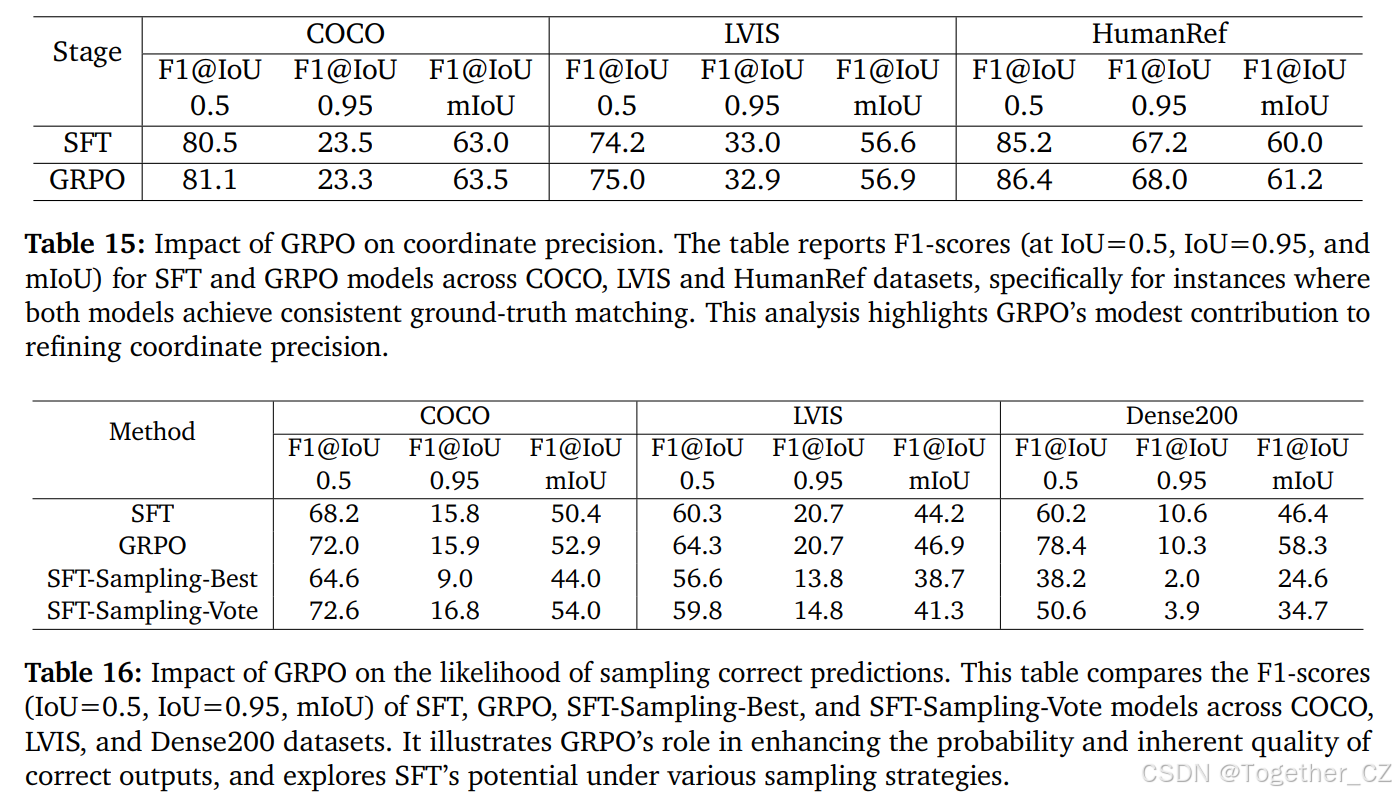
我们假设 SFT 中使用的交叉熵损失缺乏几何感知性,而 GRPO 可以利用几何感知奖励来优化坐标精度。为了验证这一点,我们在 COCO、LVIS 和 HumanRef 数据集上评估了坐标精度,具体是在 SFT 和 GRPO 模型之间进行比较,仅针对那些两个模型都能够与真值准确匹配的实例进行分析。这种过滤策略允许我们将分析重点完全放在坐标精度的细微差异上。
具体而言,对于每个测试样本,我们只包括那些 SFT 和 GRPO 模型产生的预测框数量与真值数量完全匹配的样本。此外,对于这些选定的样本,每个模型的每个预测框都必须与对应的真值框达到超过预定义匹配阈值的 IoU。通过这种方式,我们可以有效地将分析范围限定在那些仅涉及坐标精度差异的样本上。如表 15 所示,GRPO 在坐标精度方面的提升相对有限。例如,在 COCO 上,F1@mIoU 仅从 63.0 略微提升至 63.5;在 LVIS 上,从 56.6 略微提升至 56.9。这些结果表明,SFT 已经为学习准确的坐标和紧密的定位提供了足够的能力。因此,GRPO 的主要优势并不在于提升原始坐标精度,而是在于纠正行为缺陷,如重复预测和大框输出,正如我们在前面所讨论的那样。
6.1.4.提升正确预测的可能性
除了行为纠正和坐标精度提升之外,我们还从采样概率的角度来考察 GRPO 的影响。我们假设 SFT 模型本身就具备生成准确预测的能力,但其推理时的随机性降低了持续采样最佳输出的可能性。相比之下,GRPO 通过基于奖励的探索来增加这一可能性。
为了实证测试这一点,我们对 COCO、LVIS 和 Dense200 数据集上的 SFT 模型进行了高温度采样实验。我们通过使用温度 1.2、top-k 50 和 top-p 0.99 来模拟 GRPO 的 rollout,为每个测试实例采样 8 个候选预测。在此基础上,我们推导出两个基于 SFT 的指标:SFT-Sampling-Best:通过 8 次独立的全数据集测试运行 SFT 模型所获得的最高 F1 分数。SFT-Sampling-Vote:对于每个测试样本,从其 8 个采样输出中选择最佳预测(与真值的 F1 分数最高)。然后,将这些样本级的最佳预测汇总以评估整体性能。这估计了如果能够在样本级可靠地选择最优预测,SFT 的最大性能。如表 16 所示,SFT-Sampling-Vote 在 COCO 上的分数(72.6 F1@0.5)超过了 GRPO(72.0)和基础 SFT(68.2),这表明 SFT 具有生成准确预测的潜在能力,并且 GRPO 主要提高了简单数据集上采样的一致性。然而,在 LVIS 和 Dense200 上,无论是 SFT-Sampling-Best 还是 SFT-Sampling-Vote 都未能接近 GRPO 的性能,这表明对于复杂任务,GRPO 扮演了更深层次的角色,它不仅提高了采样概率,还从根本上提升了预测的质量。这些发现表明,GRPO 的好处根据任务的复杂性而有所不同:在较简单的设置中增加采样概率,并且在更具挑战性的任务中从根本上提升预测的质量。
6.2.推理效率和速度
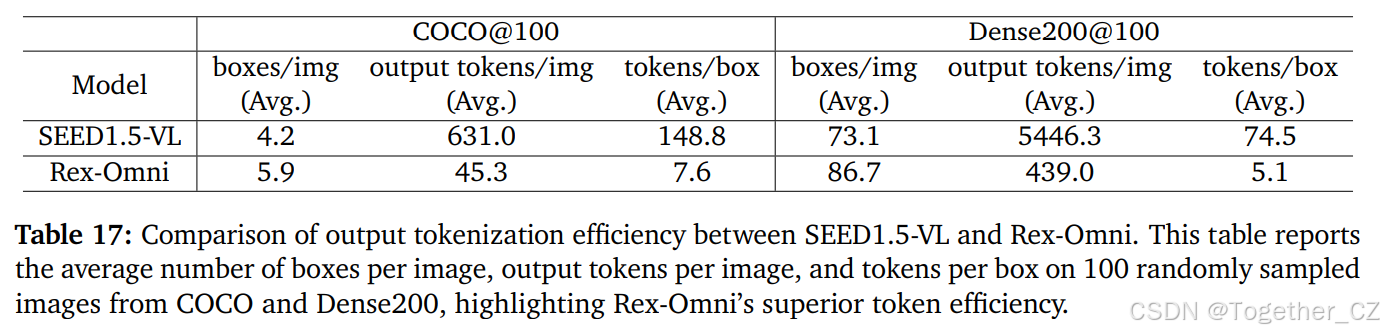
坐标表示的效率至关重要,因为它直接影响输出长度和推理速度。我们比较了 Rex-Omni(使用特殊标记对量化坐标进行编码)和 SEED1.5-VL(不使用特殊标记表示相对坐标)。为了评估这一点,我们从 COCO 和 Dense200 中各抽取了 100 张图像,并测量了每张图像的平均边界框数量、每张图像的总输出标记数量以及每个边界框的标记数量。如表 17 所示,Rex-Omni 在标记化效率方面远远超过了 SEED1.5-VL。例如,在 COCO 上,它平均每张图像只需要 7.6 个标记来表示一个边界框,而 SEED1.5-VL 需要 148.8 个标记,总输出长度从每张图像 631.0 个标记减少到 45.3 个标记。在 Dense200 上也观察到了类似的改进,这进一步证实了专用特殊标记在提高效率方面的巨大作用,尤其是在密集目标检测场景中。
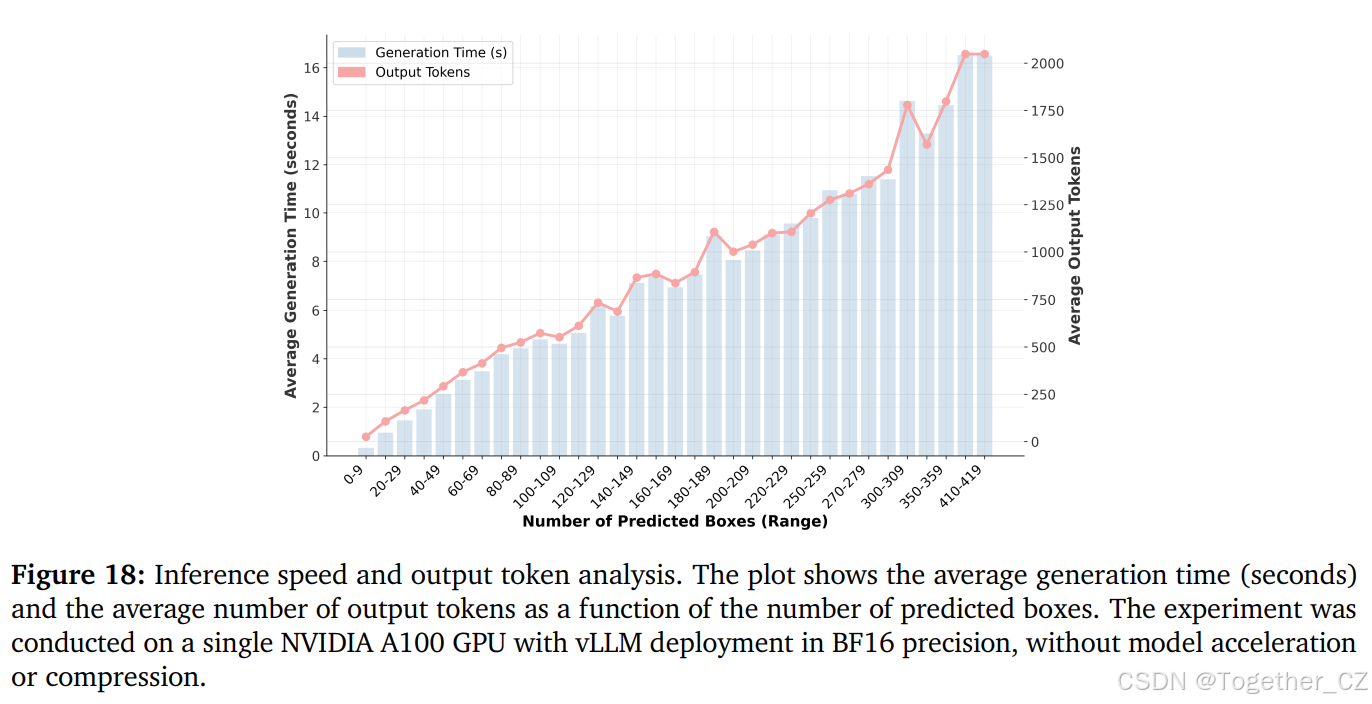
除了标记化效率之外,我们还进一步考察了实际的推理速度。图 18 描绘了预测边界框数量、输出标记长度和平均生成时间之间的关系,该实验在单个 NVIDIA A100 GPU 上使用 vLLM 以 BF16 精度进行(未应用模型加速或压缩)。边界框数量、输出标记数量和平均生成时间都大致呈线性增长。检测少量目标(0-29 个)的时间少于 2 秒,而检测数百个目标(例如 410-419 个)的时间则超过 16 秒。这些发现表明,与传统优化过的检测器相比,当前基于 MLLM 的检测器速度较慢,且速度与检测到的目标数量直接相关。然而,这种局限性可以通过量化等加速策略来缓解。
7.结论
在本工作中,我们介绍了 Rex-Omni,这是一个 3B 参数的 MLLM,系统地解决了基于 MLLM 的目标检测所面临的挑战。通过高效的坐标标记化(使用特殊标记)、通过定制引擎进行大规模数据生成以及新颖的 SFT+GRPO 两阶段训练管道,我们在精确定位和深度语言理解之间架起了桥梁。我们广泛的实验表明,Rex-Omni 在一系列视觉感知任务中实现了最先进的或极具竞争力的零样本性能。至关重要的是,我们的分析验证了尽管 SFT 提供了坚实的基础,但基于 GRPO 的后训练对于纠正 SFT 引起的行为缺陷至关重要,例如重复和大框预测,这是朝着稳健的基于 MLLM 的检测器迈出的关键一步。尽管其性能强劲,但诸如推理速度等局限性仍然存在。我们相信,未来在模型加速和先进的基于奖励的采样方面的研究将是至关重要的下一步。总之,Rex-Omni 代表了一个重要的进步,证明了 MLLM 的行为和几何局限性可以系统地克服,从而为下一代多功能、以语言为导向的感知系统铺平了道路。
8.相关工作
基于回归的目标检测方法。目标检测长期以来一直是计算机视觉的一个基石任务,基于回归的方法在历史上一直主导着该领域。这些方法的核心原则是通过回归边界框的属性(通常是中心坐标(x,y)和维度(宽度、高度))来预测边界框,这些属性通常是从预定义的参考点开始的归一化偏移量。多年来,这些方法经历了显著的发展,从早期的基于锚点的 CNN 模型(如 YOLO86、SSD60 和 Faster R-CNN87)发展到无锚点的方法,如 CornerNet43、CenterNet20 和 FCOS102。随着 Transformer 基检测器的引入,如 DETR8,目标检测领域发生了重大的范式转变,该方法将目标检测视为一个直接的集合预测问题。这一研究方向随后被 Deformable DETR134 和 DINO122 等模型进一步推进,这些模型显著提高了性能和收敛速度。除了这些范式转变之外,回归检测器的持续改进还受益于众多渐进式但至关重要的创新。这些创新包括架构改进(如特征金字塔网络FPN55)、损失函数的进步(如焦点损失56)以及复杂的数据增强技术(如 MixUp124 和 Mosaic)。正是这些广泛而持续的努力的累积效应,推动了回归检测器达到当前的高性能和实用性水平。
开放集目标检测方法。目标检测的一个长期目标是开发能够识别任意数量目标类别的模型,而无需针对特定任务进行微调,从而应对现实世界中动态场景的挑战。开放集目标检测代表着朝着这一目标迈出的重要一步,它超越了封闭集检测的限制,赋予模型识别超出预定义类别集的能力。处理这一挑战的主流方法是基于文本提示的开放词汇目标检测49,59,35,115,130,88,22,13,68。这些方法通常利用强大的预训练视觉 - 语言模型(如 CLIP80 或 BERT37)来对齐文本描述与视觉表示,展现出令人印象深刻的零样本识别能力。然而,这些模型在处理复杂或细微的描述时面临挑战,因为它们的语言理解能力有限。为了克服这一问题,引入了视觉提示32,28,88,103,84,39,135,45,使模型能够通过视觉示例(如边界框或点)来识别对象。视觉提示对于识别罕见或难以描述的对象非常有效,但它们的通用性不如文本提示。最近的模型,如 T-Rex232,结合了文本和视觉提示,通过对比学习利用每种提示的优势。这种整合使模型能够在更广泛的目标类别和现实世界场景中表现良好。尽管传统的开放集检测器实现了类别级别的泛化,但它们仍然缺乏更深层次的语言理解能力,这使得它们在处理现实世界中丰富的语义信息时面临挑战。
基于 MLLM 的目标检测方法。为了克服传统开放集检测器浅层次语言理解的局限性,一个有前景的方向是直接利用多模态大型语言模型(MLLM)的强大推理能力来进行目标级别的感知。核心思想是将目标检测重新构架为一个语言建模任务。受 Pix2Seq10 的启发,大量工作开始出现,将边界框坐标表示为一系列离散的量化标记76,9,116,106,120。这些模型(包括 Kosmos-2、Shikra、Ferret 和 CogVLM)直接通过 LLM 的标准下一个标记预测机制生成坐标序列。这种优雅的方法将目标检测与语言模型的原生能力巧妙地统一起来。然而,正如我们在引言中所讨论的,这一概念上优雅的方法在实践中面临显著的挑战。尽管 MLLM 在高级图像理解方面表现出色,但它们通常在目标检测所需的目标级空间精度方面存在困难。现有方法经常面临诸如召回率低、坐标漂移和虚假重复预测等问题。我们认为,这些问题源于两个基本挑战:使用交叉熵损失学习从离散标记到连续像素空间的精确映射的内在困难,以及监督微调(SFT)的教师指导性质所引发的行为缺陷。解决这些挑战是设计Rex-Omni 的主要动机。