目录
-
-
- [4.1 STL](#4.1 STL)
- [4.2 序列容器](#4.2 序列容器)
-
4.1 STL
Standard Template Library 标准模板库
模板:
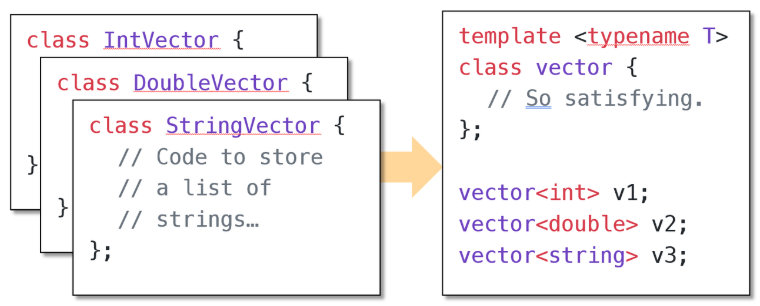
每个 C++ 容器都是一个模板!
std::vector<T>、std::map<K, V>、std::deque<T>、std::set<T>
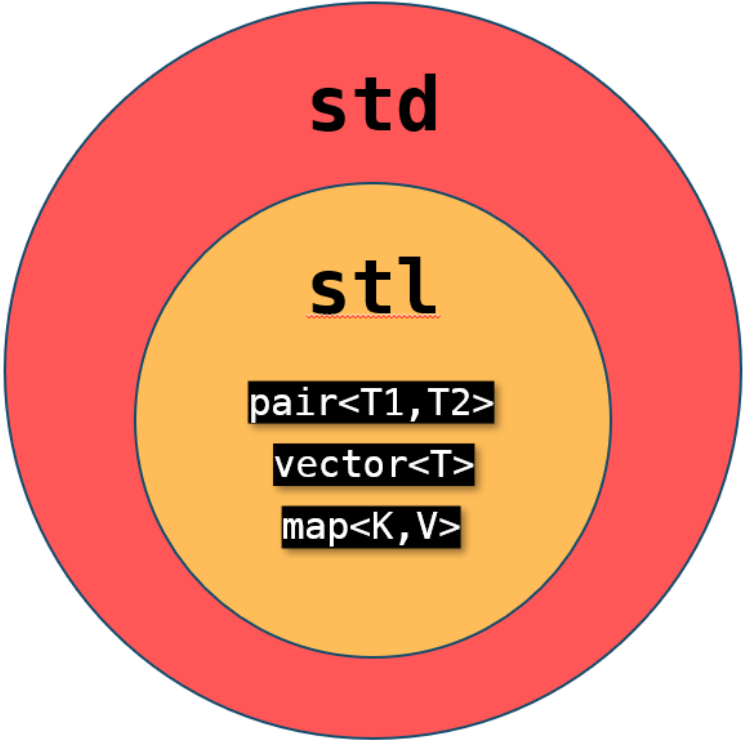
STD中不属于STL的部分:
- 输入输出流:如
iostream,fstream(它们比STL出现得更早)。 - 字符串类:
std::string(虽然它像一个容器,但它在STL之前就已存在)。 - 智能指针:如
std::unique_ptr,std::shared_ptr(C++11引入)。 - 多线程支持:如
std::thread,std::mutex(C++11引入)。 - 正则表达式:
std::regex(C++11引入)。等等。
STL包括:
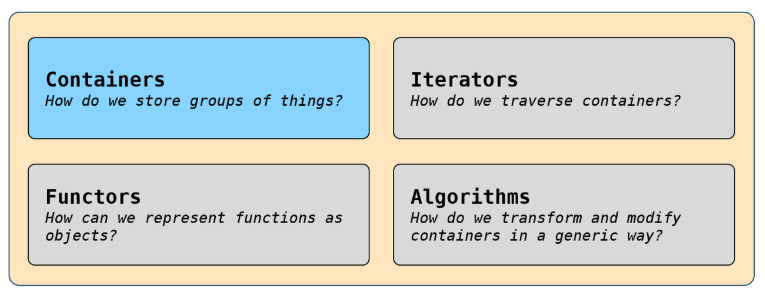
每个 STL 容器的迭代器都是前向迭代器(迭代器见第六节)
4.2 序列容器
序列容器是元素的线性集合。等同于Python 中list,或者 Java 中ArrayList。
std::vector<T>
T在这里代表类型
语法
| 表述 | 结果 |
|---|---|
std::vector v |
创建一个类型T的空向量。 |
std::vector v(n) |
创建n个类型T的向量。 |
std::vector v(n, e) |
创建n个值为e类型T的向量。 |
std::vector v{n, e} |
创建2个值的类型T的向量,元素为n和e。 |
v.push_back(e) |
在v结尾追加e |
v.pop_back() |
移除v的最后一个元素,v不能为空。注意:此方法不返回该元素,仅将其移除 |
v.empty() |
返回v是否为空。 |
T e = v[i] v[i] = e |
读取或写入索引为i的元素。不执行边界检查!( 零开销原则 )谨防越界!无性能损耗 |
T e = v.at(i) v.at(i) = e |
读取或写入索引为i的元素。如果 **i超出范围,则抛出错误!略微损耗性能** |
v.clear() |
清空v |
建议
- 可能的时候,用范围for循环(适用于所有可迭代容器)
cpp
// 一般循环
for (size_t i = 0; i < vec.size(); i++) {
std::cout << vec[i] << " ";
}
// 范围for
for (auto elem : vec) {
std::cout << elem << " ";
}- 可能的时候,用**const auto&**(适用于所有可迭代容器),避免对每个元素进行可能成本高昂的复制
cpp
std::vector<MassiveType> vec { ... };
// 一般情况
for (auto elem : vec) ...
// const auto&
for (const auto& elem : v)本质
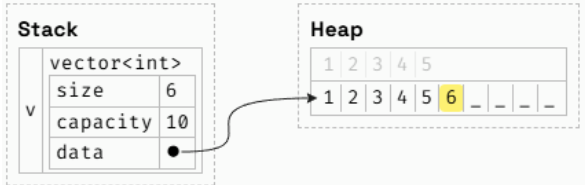
在任何时候, std::vector 都会管理一个足够大的单一内存块来容纳其所有元素,并且当需要更多空间时,它会分配一个新的内存块(并释放旧的内存块)。
cpp
std::vector<int> v { 1, 2, 3, 4 };
v.push_back(5);
v.push_back(6);行1:v的容量为5。在实际应用中,向量的初始容量取决于编译器。
行2:v有足够的剩余容量来插入5,因此它会被插入到向量末尾的data中。

行3:v已经耗尽了空间,因此它在堆上分配了一个新的内存块,复制了其元素,并释放了旧的内存块。通常情况下,向量在重新分配时会将其容量翻倍,但实际行为取决于编译器。
std::deque<T>
一个std::deque(发音为 "deck")表示一个双端队列,它支持在容器的前端和后端高效地插入 / 删除元素。
发明动机
std::vector<T>在头部插入元素效率太低
cpp
void receive_price(std::vector<double>& prices, double price) {
prices.push_front(price);
if (prices.size() > 100000)
prices.pop_back();
}
void std::vector<T>::push_front(const T& value) {
resize(size() + 1);
// 每次插入都得向前移动一位,低效!
for (size_t i = size() - 1; i > 0; --i)
(*this)[i] = (*this)[i - 1];
(*this)[0] = value;
}这是由std::vector的实现方式导致的:由于它始终维护着一整块连续的内存,试图在前端插入元素时,就需要将所有元素向前移动,为新元素腾出空间。
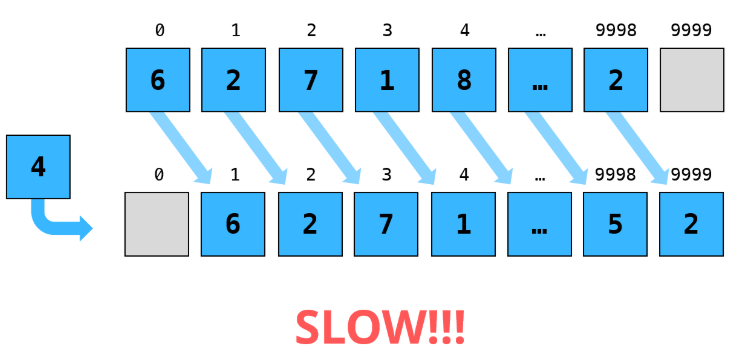
一个高效的替代方法
std::deque通过以一种略有不同、更适合前端插入的方式排列其元素来解决这个问题。在我们的receive_price函数中,我们可以改用std::deque:
cpp
void receive_price(std::deque<double>& prices, double price) {
prices.push_front(price);
if (prices.size() > 100000)
prices.pop_back();
}语法
std::deque支持std::vector所支持的所有操作,此外还多出一些操作:
| 表述 | 结果 |
|---|---|
d.push_front(e) |
在d最前端加入e. |
d.pop_front() |
移除d的第一个元素,d不能为空。注意:此方法不返回该元素,仅将其移除 |
本质
std::deque通过将分配拆分为多个固定大小的分配来解决前端插入问题。为了跟踪正在使用的区域的开始和结束位置,std::deque使用了一个start(起始)和finish(结束)索引。(实际上,这些是迭代器)
cpp
std::deque<int> d { 4, 5, 6, 7, 8, 9 };
d.push_front(3);
d.push_front(2);
d.push_front(1);
d.push_front(0);
d.push_front(-1);
d.push_front(-2);行1:
让我们假设这是初始元素的内存布局。已经分配了两个大小为4的固定大小块(实际大小和分配的块数将取决于编译器)。注意,start和finish指的是所有块 中的索引。blocks是一个数组的数组,而capacity指的是该数组的大小。
行2:
当我们调用d.push_front(3)时,双端队列首先会检查其第一个正在使用的块的前端是否有可用空间。在这种情况下是有的,所以该元素会被放置在那里。注意,start已被更新为0以反映这一点。

行3:
第一个正在使用的块已经没有空间了,所以我们必须分配一个新的块。但是,我们必须在blocks中记录指向新分配块的指针,而该块也已经没有空间了。与std::vector在调整大小时将其元素数组翻倍的方式类似,deque对blocks数组也会做类似的处理。一旦blocks被调整大小(复制旧指针,然后释放旧的blocks数组),就会分配一个新的块来存储2。
行4:
第一个正在使用的块在推入1、0和-1后耗尽了空间,因此为了执行d.push_front(-3),会按需分配一个新块来存储-3,并将其添加到blocks数组中。

同样是翻倍扩容数组,高效的原因
std::deque<T>扩容时也要像std::vector<T>那样扩容存储结构(blocks数组),为何仍比vector高效" ,可从以下两点简要解析:
1、 扩容对象的本质差异
std::vector<T>扩容时,需操作存储元素本身的连续内存块,也就是data数组 :扩容后要把旧内存中所有元素复制到新内存,元素数量越多,复制开销越大(比如存
1000 个int,就要复制 1000 次)。std::deque<T>扩容时,操作的是存储 "元素块指针" ,也就是blocks数组 :blocks数组里存的不是元素,而是指向各个小内存块(每个块存数百到数千个元素)的指针。扩容时只需复制这些 "指针",而非元素 ------ 即使blocks数组翻倍,复制的指针数量也极少(比如每个块存 1000 个元素,存 100 万个元素只需 1000 个指针,复制 1000 次远少于复制 100 万个元素)。
2、 效率差距的核心原因
由于deque的blocks数组存储的是 "轻量指针",而非 "重量级元素",其扩容时的复制操作量,比vector复制 "全量元素" 少数百到数千倍 (对应每个块的元素数量),因此整体扩容效率远高于vector。
注意
在实际应用中,start和finish实际上直接存储着指向双端队列中第一个和最后一个元素的指针,因此具体的实现细节可能有所不同,因此,对std::deque进行索引访问比std::vector稍慢,因为它必须通过两个指针(而不是一个)来查找元素。
除非你需要高效的前端插入移除,否则建议用vector。