| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 论文名称 | VOTE |
| 2 | 发表时间/位置 | 2025 |
| 3 | Code | LukeLIN-web/vote: Vision-Language-Action Optimization with Trajectory Ensemble Voting |
| 4 | 创新点 | 1:Tokenizer-free Fine-tuning 引入特殊 Token <ACT>: 在图文指令末尾加一个占位符。这个 Token 不代表具体含义,而是作为"触发器",其对应的Hidden State(隐藏状态) 汇聚了所有上下文信息。 直接回归预测(直接回归描述的是输出值的类型是回归任务,也就是 直接预测连续动作数值,不经过文字/token化。)Direct Regression:在 <ACT> 后面挂一个 MLP(多层感知机) ,直接把隐藏状态映射为 7维动作向量。 并行输出 Parallel Prediction:一次性算出未来 N 步的所有动作数值,而不是像说话一样一个字一个字生成。 2:轨迹集成投票 (Trajectory Ensemble Voting) 利用 Chunking 机制,把过去时间步对"当前时刻"所做的历史预测都找出来(比如 1 秒前预测的现在,和现在预测的现在)。把这些预测组成一个委员会。 余弦相似度投票 :以最新的预测为基准 ,计算历史预测的相似度。 一致的(Inliers):保留并取平均,平滑轨迹。 不一致的(Outliers) :视为预测错误,直接剔除。 实现了隐式纠错 ,显著提升了模型在未见物体和新环境下的泛化能力和稳定性。 3:Lightweight Design 故意不使用扩散模型(Diffusion)和额外的视觉模块。证明了只要优化好输出方式(潜空间预测)和采样策略(投票),仅靠标准的 VLM 主干就能达到 SOTA(最先进)水平。 |
| 5 | 引用量 | 投票机制和<act>连续动作直接回归一次性生成7维的动作向量,并行输出未来N步的动作(非自回归)。 |
一:提出问题
现在的视觉-语言-动作(VLA)大模型(比如谷歌的 RT-2)在机器人听懂自然语言指令并执行操作方面表现不错。但是存在泛化能力差,一丹遇到没有见过的物体或新的环境,模型就容易出错。而且现有的方案模型都显得重,之前的方法通常会引入如深度估计(Depth)、分割模块(Segmentation)或者扩散模型(Diffusion)。虽然效果好了,但计算量激增,推理速度变慢,导致机器人反应迟钝。
本文主要是探究如何设计一种高效 的动作预测方法,不需要 依赖那些沉重的额外视觉辅助(如深度图)或扩散技术,就能实现快速且准确的控制。提出了一个名为 VOTE 的框架,主要探究如何提升模型快且准的能力。
-
无分词器微调与并行预测 (Tokenizer-free Fine-tuning & Parallel Prediction) -> 解决"慢"
传统的 VLA 模型(如 RT-2)通常把机器人的动作(坐标 x, y, z 等)看作"单词",使用 Tokenizer(分词器)将其离散化,然后一个接一个地(自回归)生成。这非常慢。
VOTE 的做法:
-
Tokenizer-free(无需分词器):直接预测动作数值,不进行繁琐的文本离散化。
-
Parallel Action Prediction(并行预测):一次性输出所有动作维度,而不是像说话一样一个字一个字蹦。
-
-
轨迹集成投票 (Trajectory Ensemble Voting) -> 解决"泛化差"
单次预测可能会有偏差,特别是面对陌生环境时。因此,在模型在进行动作采样时,不只生成一条轨迹,而是利用集成(Ensemble) 策略生成多条可能的动作轨迹,然后通过**投票(Voting)**机制选出最优的动作。通过这种集体决策,平滑了预测噪声,显著提高了模型在未见过场景下的表现(泛化能力)。
总的来说,为了解决解决现阶段方案存在的问题,必须追求轻量且高效的模型:为了提高吞吐量和速度,作者故意排除 (deliberately exclude)了额外的视觉模块和基于扩散的技术。模型完全基于 VLM 主干构建。有两个核心的技术,
-
移除分词器与直接预测
传统方法使用动作分词器(Action Tokenizer),需要多次顺序解码,速度慢。而VOTE选择移除动作分词器,并且引入直接动作预测头(Direct-action prediction head),使用一个特殊的 <ACT> token 来代表一整块动作(entire action chunks)。从而显著减少生成的token数量,避免了多次顺序解码,降低了训练成本加快了推理的速度。
-
集成投票机制,提升准确率和泛化性
VLA 模型如果只依赖最近的输入(most recent multimodal inputs),容易出错。VOTE构建一个机制,把之前步骤预测的动作(actions predicted in previous steps)也纳入考虑,根据之前的预测积累"票数"进行加权,来决定当前的动作。从而实现了隐式纠错(Implicit error correction),降低了预测错误的可能性,提高了测试时的性能。
1. 什么是"动作分词器" (Action Tokenizer)?
在理解"动作分词器"之前,我们需要先达成一个共识:大语言模型(LLM/VLM)本质上是用来"成语接龙"的,它只能处理离散的"字"或"词"(Token)。 但是,机器人的动作不是"字",而是一串连续的数值。例如,控制一只机械臂移动,可能需要输出 7 个数字(7-DoF):
x=0.25, y=-0.1, z=0.5, 旋转1=..., 旋转2=..., 旋转3=..., 夹爪开合=1
传统 VLA 模型(如 RT-2)它们强行把这些数字变成了"字",这就是动作分词器的工作。
离散化(造字典):把 0 到 1 之间的数值切分成 256 份(比如),每一份对应一个 Token。
0.25 变成了 Token_64
-0.1 变成了 Token_25
序列化(排排坐) :LLM 无法一次性说完一句话,它必须一个字一个字地蹦(这在原文中被称为 "Sequential decoder passes",顺序解码)。
要输出那 7 个动作数值,模型需要运行 7 次:
第 1 步:输出 Token_64 (代表 x)
第 2 步:输出 Token_25 (代表 y)
...
第 7 步:输出 Token_255 (代表夹爪)
动作分词器就是 把机器人的连续动作数值,强行翻译成 LLM 能读懂的一个个"单词"。
2. VOTE 为什么要移除它?(以及移除后的做法)
原文中提到:
"introduce a special token <ACT> to represent entire action chunks... avoids multiple sequential decoder passes" (引入一个特殊的 <ACT> token 来代表整个动作块......避免了多次顺序解码过程)
VOTE 的做法(Tokenizer-free): VOTE 觉得让大模型像"挤牙膏"一样一个数一个数地蹦太慢了。于是它改用了**回归(Regression)**的方式。
不翻译了,不再把数字变成 Token。
打包处理 ,模型只需要输出一个特殊的 Token,叫做 <ACT>。
外挂解码头 ,这个 <ACT> Token 后面直接挂在一个"预测头(Prediction Head)"上。当模型输出 <ACT> 时,预测头会一次性并行算出所有 7 个维度的数值。
3. 移除后的作用是什么?(核心收益)
结合原文,移除分词器带来了两个巨大的改变:
- 极大的速度提升(解决"慢"的问题)
传统方法(有分词器) :如果你要控制机器人动一下,模型需要推理 7 次(因为有 7 个维度,要生成 7 个 Token)。这叫"自回归生成",非常耗时。
VOTE 方法(无分词器) :模型只需要推理 1 次(生成 1 个 <ACT> Token)。后面的 7 个数值是跟着这个 Token 一瞬间并行算出来的。
<font color=red>也就是区别于之前的工作,通过动作向量(连续) → 分词器 → action tokens(离散) → 大模型预测 token → 查字典 → 转回向量,现在是在VLM的decoder额外加上一个action head(一个 MLP(线性层 → 激活 → 线性层)),用
<ACT>作为"动作的触发词,将隐藏层的状态通过MLP映射为一个连续的动作。
二:解决方案
现阶段模型推理慢的根本原因是VLM 的解码过程(Decoding)太复杂了,占用了绝大部分时间。CogACT 为什么慢? 它在输出端用了 "diffusion process"(扩散过程) 。(扩散模型虽然画图好,但生成一步往往需要迭代几十次,所以原文说它 "suffers from significantly higher latency"(遭受显著更高的延迟)。 )。SpatialVLA为什么慢? 这个模型认为缺少了3D信息导致效果不好,因此在输入端加了太多料。原文说它依赖 "3D information" ,导致 "feeding a larger number of input tokens"(喂入更多的输入 token) 。输入的字(token)越多,模型读得就越慢,推理自然就卡顿。综上,VOTE 既不要扩散模型(输出端简化),也不要额外的 3D 视觉输入(输入端简化)。
其次就是,现阶段为了效果好,大家都在疯狂的堆数据,SpatialVLA 和 CogACT 因为架构里加了 "extra modules"(额外模块) ,导致它们变得很"挑食"------它们 "require significantly more additional data"(需要显著更多的额外数据) 才能训练好。结果导致,数据需求大 -> 训练时间长 -> "substantially higher computational costs"(计算成本大幅增加) 。作者的目标是设计一个结构简单 的模型,去掉那些花里胡哨的额外模块,这样模型就能 "minimizing the training overhead"(最小化训练开销) ,并且只用 "limited data"(有限的数据) 就能学会新任务。
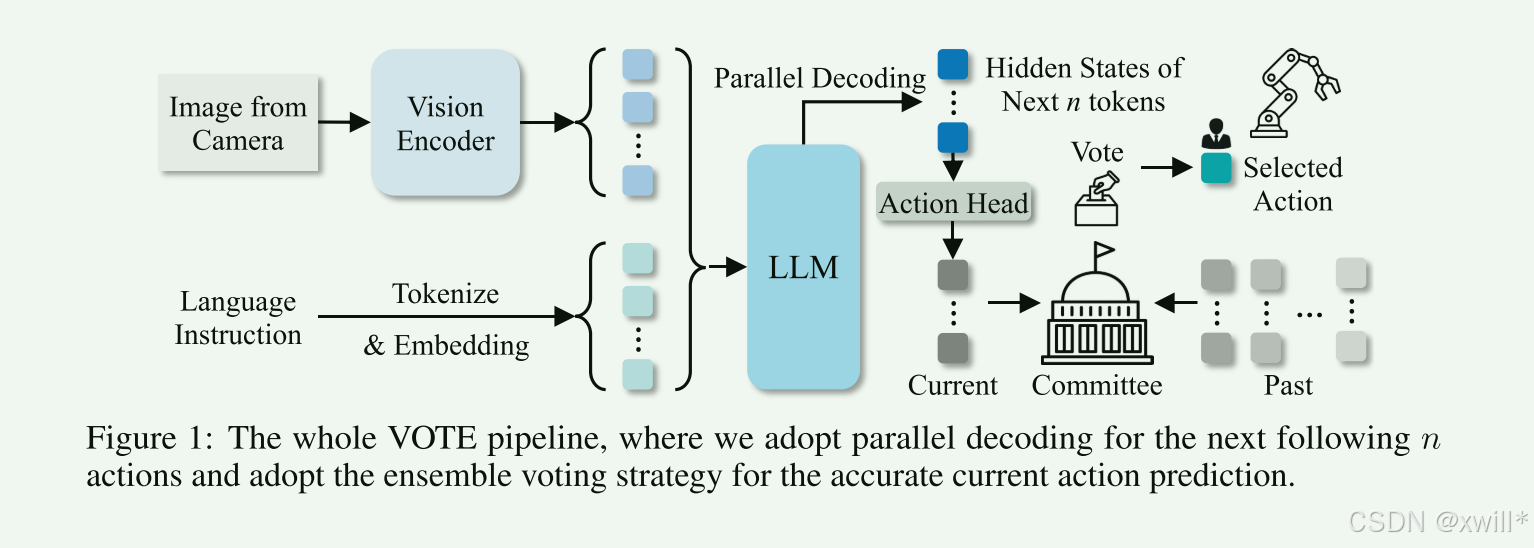
1 VOTE
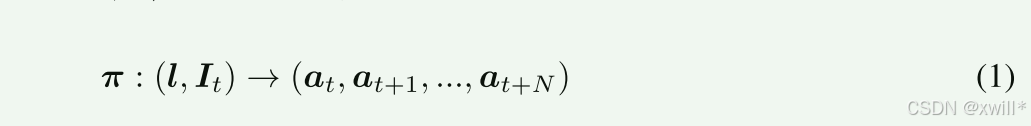
基于图像 I∈RW×H×3 和语言指令 l 生成动作。使用模型π 来预测一个时间动作序列。at可以描述具有不同控制模式和末端执行器的各种机器人动作。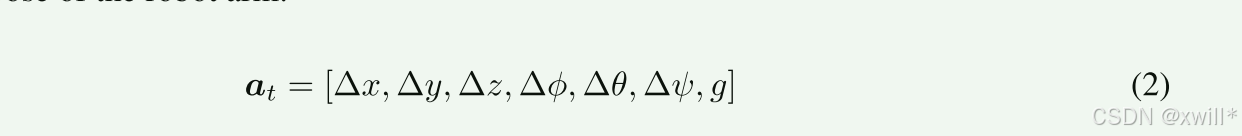
Δx,Δy,Δz 是末端执行器的相对平移偏移量,Δϕ,Δθ,Δψ表示旋转变化,g∈{0,1} 指示夹爪的开/合状态。这种动作空间实现了对机械臂运动和末端执行器行为的连续控制。
1.1VOTE核心流程,从<ACT> 到动作
在 LLM 的分词器中引入了一个特殊的 token <ACT>,以显式地发出动作预测任务的信号。具体来说,将这个 <ACT> token 追加到每个语言指令序列的末尾作为目标 token 标签,记为 ytoken。
step 1 :第一步是让VLM听懂指令
模型读入图片和文字,处理完后,在末尾生成一个 token:<ACT>。此时,模型内部产生了一个隐藏状态向量 h<ACT>。
- 输入阶段:把"图"和"文"变成"排好队的数字"
首先,给机器人看了一张图片(比如桌上有个苹果),并说了一句指令:"把苹果拿起来"。模型并不是直接看图听音,它需要先把这些信息"数字化"并排成一队:
图片:被切成很多小方块(Patches),变成一串数字序列。
文字:被切成 Token(比如 把 苹果 拿 起来),也变成一串数字。
然后,这些数字被拼接成一条长长的队伍,送进模型的大脑(Transformer):输入序列: 图片片段1 图片片段2 ... 把 苹果 拿 起来
2. 思考阶段:模型内部的"化学反应"
当这条"数字队伍"进入模型(VLM Backbone)后,经过了几十层的计算。每一层都在做一件事:融合信息。
模型会把"文字里的'苹果'"和"图片里'红色的圆东西'"对应起来。
它会理解"拿起来"意味着需要移动手臂。
关键点来了: 模型是按顺序 阅读的。当它读完 起来 这个词后,它会根据之前的训练习惯,预测下一个词应该是什么。
在 VOTE 的训练中,我们强制教导模型:"嘿,兄弟,每当你读完指令,下一个词必须是 <ACT>。"
所以,当模型处理到序列末尾时,它心里非常清楚:"指令结束了,该我动手了,下一个词是 <ACT>(一个特殊的token,)。当模型决定输出 <ACT> 这个 Token 的前一刹那 ,在模型的最后一层神经网络 里,产生了一个向量(Vector) 。这个向量就是 h<ACT>(Hidden State of <ACT>)。虽然它只是一串数字(比如 4096 个浮点数),但它高度浓缩了以下信息:
语义:"我要做'抓取'这个动作。"
视觉:"苹果在图片右上方坐标 (0.8, 0.2) 的位置。"
现状:"我现在手是张开的。"
step 2 :第二步是MLP 动作头接力
这个向量 h<ACT>被送入一个 MLP(多层感知机)。
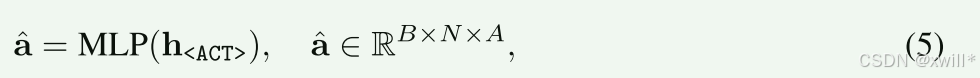
MLP 的结构 :原文公式 (6) 展示了这个 MLP 不是简单的线性层,而是一个带有 ResNet 风格(残差连接) 的深层网络。

注意公式里的 x2 = x1 + ...。这种"跳跃连接"让梯度更容易传播,训练更稳定,能从向量中榨取更精确的动作信息。
并行输出:这个 MLP 的输出 a^ 也是一个矩阵,形状是 RB×N×A。
N表示:未来 N 步(机器人动作的步数,Chunk size)。 A:每步 7 个维度。
这意味着一次计算,直接吐出未来 N 步的所有 7×N 个数值!
2 训练
为了让模型既懂语言又会动作,本文设计了两个"考试科目"(Loss function):
-
语文考试 ( Ltoken):用 Cross-Entropy(交叉熵)。
检查模型是否正确地在指令结束时生成了 <ACT> 这个 token。这保证模型知道"什么时候该动手"。
-
**数学/体育考试 (**Laction):
用 L1 Loss(绝对误差)。
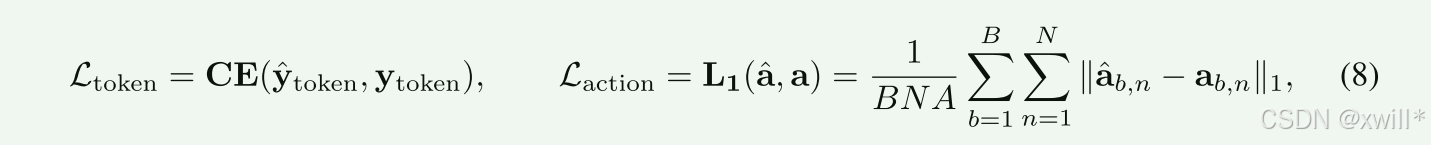
 意思就是:预测的坐标和真实坐标之间的距离。如果机器人预测 x=0.5,实际是 0.6,误差就是 0.1。模型通过最小化这个误差来学习精准控制。
意思就是:预测的坐标和真实坐标之间的距离。如果机器人预测 x=0.5,实际是 0.6,误差就是 0.1。模型通过最小化这个误差来学习精准控制。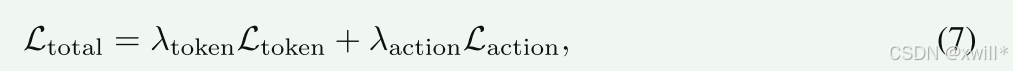
相较于传统方法,OpenVLA :假设你要预测未来 N步,每步 7 个维度。你需要模型运行 N×7次。而且通常需要填充(padding)很多空数据,浪费显存。
VOTE (新方法) :只需要模型运行 1 次 (生成 <ACT>)。那个 MLP 动作头虽然有几层,但在 GPU 上运算是瞬间完成的(并行计算)。
3 集成投票 (Ensemble Voting)
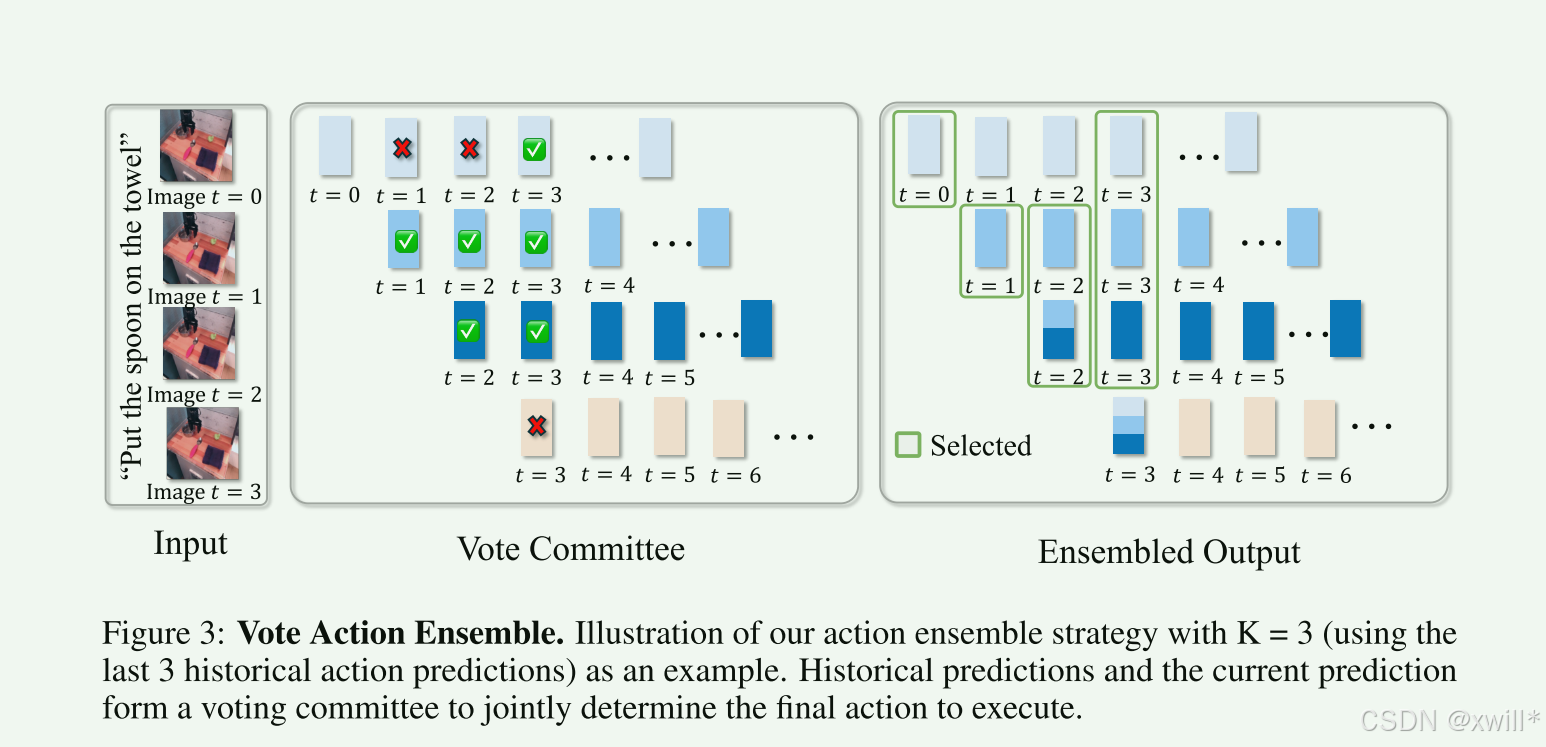
在预测动作的过程中,模型往往给会预测一个动作快,来防止动作出现**"手抖"或者"抽风"** 。这也就是之前方法采用的 Chunking(动作块) 机制。模型不是只预测"下一步",而是一次预测"未来 N 步"。例如现在是第10秒:
-
第 8 秒时 :模型预测了未来(8, 9, 10 , 11...秒)的动作。-> 这是老预测 A。
-
第 9 秒时 :模型预测了未来(9, 10 , 11, 12...秒)的动作。-> 这是老预测 B。
-
第 10 秒时 :模型预测了未来(10 , 11, 12, 13...秒)的动作。-> 这是新预测 C。
针对 "第 10 秒该干什么" 这一件事,我们其实手里有 A、B、C 三个版本的答案。而传统方法:只听 C 的(喜新厌旧)。VOTE 方法:把 A、B、C 叫到一起开个会。
(1) VOTE 的机制:分组 PK
作者设计了一个很有意思的规则来决定听谁的。
-
基准 (Anchor) :以 最新的预测 C 为标准。
-
判决标准 :余弦相似度 (Cosine Similarity)。
- 通俗说就是看"方向一致不一致"。如果两个动作向量夹角很小,说明意见相同。
过程演示: 假设我们要决定第 10 秒的手臂位置。
-
新预测 C 说:往左移 5 厘米。
-
老预测 A 说:往左移 4.8 厘米。(和 C 很像 -> 归入 M 组)
-
老预测 B 说:往右移 10 厘米。(完全反了,可能是当时眼花了 -> 归入 N 组)
投票结果:
-
M 组(赞成派):2 票(C自己 + A)。
-
N 组(反对派):1 票(B)。
什么不直接把 A, B, C 加起来除以 3(平均法)?
原文解释了原因(Advantages ii):
- 抗干扰 : 如果刚才那个例子里,我们直接取平均:(5 + 4.8 - 10) / 3,结果会非常离谱。 通过投票,我们发现 B 是个异类(Outlier),直接把它踢出去,不让它坏了一锅汤。
为什么不无脑相信最新的 C?
平滑轨迹: 有时候最新的观测可能有噪声(比如摄像头晃了一下),导致 C 是错的,而之前的 A 和 B 都是对的。 这时候:
C 说:往右。
A 说:往左。
B 说:往左。
计算相似度时以 C 为准,A 和 B 都会被归入 N 组(反对派)。
结果:N 组(2票) > M 组(1票)。
模型决定不听最新的 C,而是听老前辈 A 和 B 的。这就是**"隐式纠错"**。
三:实验
实验在以下两个测试上进行:
-
LIBERO:这是一个标准的模拟基准,用来测通用的操作能力。
-
SimplerEnv:这个更难,它包含 WidowX 和 Google Robot 两种具体的机器人形态,使用的是真实的机器人数据集(BridgeDataV2 和 Fractal)在模拟器里跑。
baseline model:
-
Google 派系:RT-1, RT-2-X(这是之前的行业标杆)。
-
开源派系:OpenVLA, Octo。
-
高性能竞品:SpatialVLA(主打空间理解)、CogACT(主打扩散模型)。
四:总结
本文提出了一个轻量级的 VLA 模型,通过在隐藏潜空间(hidden latent space)*中预测动作来增强效率。我们的方法利用了一种新颖的* 无分词器(tokenizer-free)*训练方法,该方法*同时预测多个动作 ,显著减少了训练和推理期间的计算需求。此外,我们的方法保持了与新兴且更强大的视觉语言模型(VLM)主干的兼容性** 。进一步地,我们提出了一个简单但有效(straightforward yet effective)*的动作集成算法,优化了动作采样。*
1 什么叫"在隐藏潜空间预测"?
以前的方法:在"显式空间"预测(即输出具体的 Token ID,查字典)。
VOTE 的方法 :在"潜空间"预测。那个 h<ACT>就是潜空间里的表示。
- VOTE 直接利用这个看不见的内部向量来回归算出动作,跳过了"变成文字"这一步。
2 并行与无分词器
Tokenizer-free :去掉了那个像打字员一样的分词器。(分词器从字面上理解就是单词拆分为一个个的token,然后映射为embedding。旧方法就是动作(连续值) → 离散 token → 再由 LLM 逐 token 生成 。需要把一个动作拆分为十几个动作token,拆分后也必须要通过 tokenizer 做动作编码,而模型必须 逐 token 生成动作 token(很慢)。本文就是把动作生成不拆分为一个离散的序列,而是直接用一个特殊标记来输出动作序列,避免了逐个token生成的问题。)
Simultaneously:指的是那个 MLP 动作头,一次性把未来 N 步的动作全算出来了。这直接导致了计算需求(computational requirements)的大幅下降。
3 兼容性 (Compatibility)
VOTE 的这套架构(加个 <ACT> token + 挂个 MLP 头)非常通用且简单。如果明天 Meta 发布了更强的 Llama-4 或者 Google 发布了更强的 Gemini,VOTE 的方法可以很容易地"移植"过去,让机器人变得更聪明。
4 简单且有效的投票策略
集成投票策略"。只是需要计算余弦相似度,没有什么复杂的扩散模型或高深数学。但它"effective"(有效)**,因为它成功解决了机器人"手抖"的问题,实现了自我纠错。