1. RAG系统的评估
RAG的系统分为检索评估和响应评估.
- 对检索器的评估(也称为"检索评估")包含一定的主观因素,但我们仍可以采用信息检索领域的一些指标来进行衡量,例如准确率(Precision)、召回率(Recall)和排名准确度等。
- 生成器的评估(也称为"响应评估",实际上是针对 R A G 系统给出的最终结果进行的整体评估)则更加复杂。它不仅要求验证生成的答案是否基于事实(即与 上下文相关),以及是否有效地回答了用户的问题(即与查询相关),还需要判断答案 是否流畅、安全且符合人类价值观。为了评估生成内容的质量,我们会结合使用定量 指标(如 BLEU 或 ROUGE)和定性指标(如回答的相关性、语义一致性、语境契合度、 扎实性及忠实度)。此外,鉴于这些因素的复杂性,还需要依赖人类的主观评价来辅 助完成整个评估过程.
1.1 RAG的评估数据集
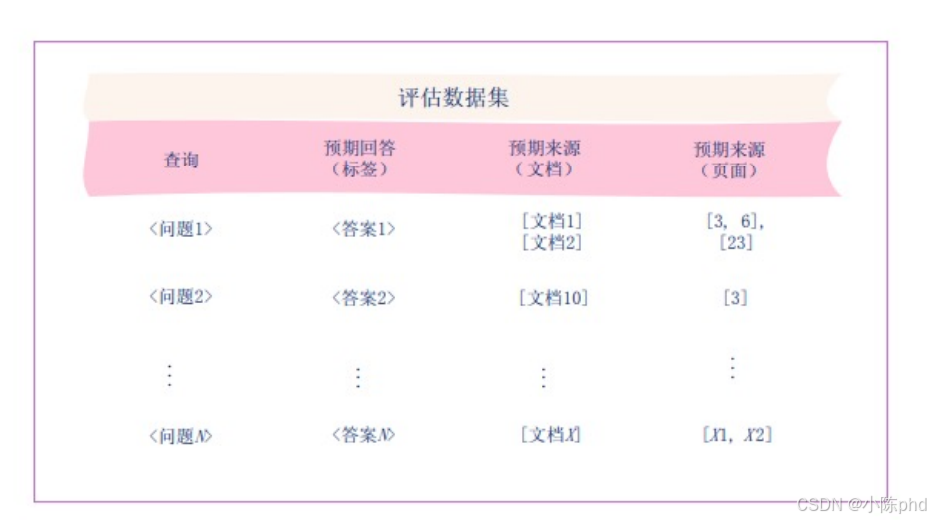
RAG(检索增强生成)系统专用的 "评估数据集" 结构------ 它是用来测试 RAG 系统性能的标准化数据模板,通过明确的 "问题、答案、来源" 对应关系,验证 RAG 的检索准确性和回答可靠性。
这个数据集包含4个关键列,每一列对应RAG评估的一个核心要素:
- 查询:用户提出的问题(比如"2025年AI芯片市场规模是多少"),是RAG系统需要处理的输入;
- 预期回答(标签):这个问题对应的标准答案(比如"1200亿美元"),用来判断RAG生成的回答是否准确;
- 预期来源(文档):这个问题的答案应该从知识库中的哪些文档里获取(比如"Gartner 2025年AI报告"),用来验证RAG检索的文档是否正确;
- 预期来源(页面):答案在对应文档中的具体页面位置(比如"第3页"),进一步精准验证RAG检索的信息位置是否准确。
用这个数据集测试RAG系统时,会对比"RAG的实际输出"和"数据集的预期内容":
- 看RAG检索到的文档/页面,是否和"预期来源"一致(验证检索准确性);
- 看RAG生成的回答,是否和"预期回答"一致(验证回答准确性);
- 看RAG的回答是否真的来自"预期来源"(验证回答的依据性,避免幻觉 )。
比如图中"问题1"的例子: - 给RAG输入"问题1",如果RAG检索到了"文档1、文档2"的第3、6、23页,且生成的回答和"答案1"一致,说明这个RAG的性能达标。
简单说,数据集里的"问题"是考题,"预期回答、预期来源"是标准答案,用它可以量化测试RAG系统的能力。
1.2 RAG评估三角
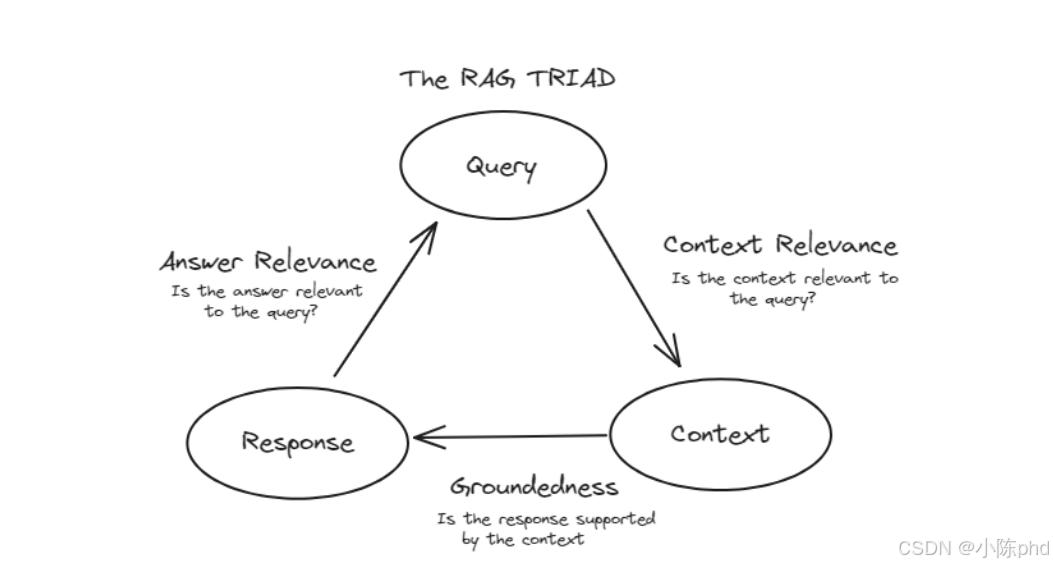
RAG(检索增强生成)系统的核心评估三角(The RAG TRIAD),它用三个维度定义了RAG系统输出质量的判断标准,相当于RAG的"质量体检表",三个维度环环相扣,缺一不可:
三角的三个节点对应RAG流程的三个关键环节:
- Query:用户的查询请求(比如"2025年AI芯片市场规模是多少");
- Context:RAG从知识库中检索到的外部信息(比如"Gartner 2025年AI芯片报告");
- Response :大模型基于Query和Context生成的最终回答。
每个维度对应一个"是否达标"的关键问题,共同决定RAG的输出质量:
(1)Context Relevance(上下文相关性)
- 核心问题:Is the context relevant to the query?(检索到的Context和用户Query相关吗?)
- 作用:判断RAG的"检索能力"------有没有找到和问题匹配的有效信息。
- 反例:用户问"2025年AI芯片市场",但RAG检索到"2023年手机芯片报告",则这一维度不达标。
(2)Groundedness(回答的依据性)
- 核心问题:Is the response supported by the context?(生成的Response是由Context支撑的吗?)
- 作用:判断RAG的"诚实性"------回答有没有编造信息(即"幻觉")。
- 反例:Context里写"2025年AI芯片市场规模1200亿美元",但Response说"1500亿美元",则这一维度不达标。
(3)Answer Relevance(回答的相关性)
- 核心问题:Is the answer relevant to the query?(生成的Response和用户Query相关吗?)
- 作用:判断RAG的"回答能力"------有没有真的解决用户的问题。
- 反例:用户问"2025年AI芯片市场规模",但Response讲"AI芯片的技术原理",则这一维度不达标。
三角的核心逻辑:三者必须同时达标
RAG要输出高质量结果,需要三个维度同时满足:
- 先确保Context和Query相关(检索到有用的信息);
- 再确保Response基于Context生成(没有幻觉);
- 最后确保Response和Query相关(回答了用户的问题)。
只要有一个维度不达标,RAG的输出就是"无效"或"低质量"的------比如检索到了相关Context,但回答偏离了问题,依然是失败的RAG结果。
简单说,这个三角是RAG的"质量铁三角":检索要准、回答要实、内容要对,三者共同保障RAG系统的可靠性。
2. 检索器的评估
2.1 精确率
- 精确度衡量检索到的文本块中有多少与查询相关,即检索到的相关文本块数量占总检 索文本块数
量的比例。精确度旨在回答这样一个问题:"在所有被检索出的文本块中,有 多少是真正相关的?" - 高精确率也意味着检索内容更加精准,有效减少了不必要的信息展示。这一指标在避 免无关信息
的呈现方面尤为重要,尤其在医疗、法律等专业领域,高精确率能够有效防止 误导性信息的传播。

2.2 召回率 Recall
- 召回率衡量系统检索到的相关文本块的全面性,即检索到的相关文本块数量占数据库 中所有相关
文本块数量的比例。召回率旨在回答这样一个问题:"在所有相关的文本块中, 系统成功检索了
多少? - 高召回率对避免遗漏关键信息至关重要。若召回率低,模型可能由于缺乏关键信息而 生成不完整
的回答或产生错误。例如,在法律文档检索中,遗漏相关信息可能会影响到案 例分析的完整性。

2.3 F1分数
- 在 RAG 系统中,提高精确率往往会导致召回率的降低,反之亦然。因此,为了获得 最佳的检索
性能,通常需要在精确率和召回率之间找到平衡。这一平衡通常使用 F1 分数 来量化,它是精确
率与召回率的调和平均数,用于在两者之间找到适合具体应用需求的最 优点。 F1 分数

2.4 平均倒数排名
平均倒数排名(MRR)是一项评估检索系统效率的指标,它特别关注第一个相关文本块的排名。
MRR 可以帮助我们衡量 RAG 系统能否快速返回第一个相关文本块,它的 值对用户体验有直接
影响。MRR 值越高,表示系统能越快地找到第一个符合需求的答案。
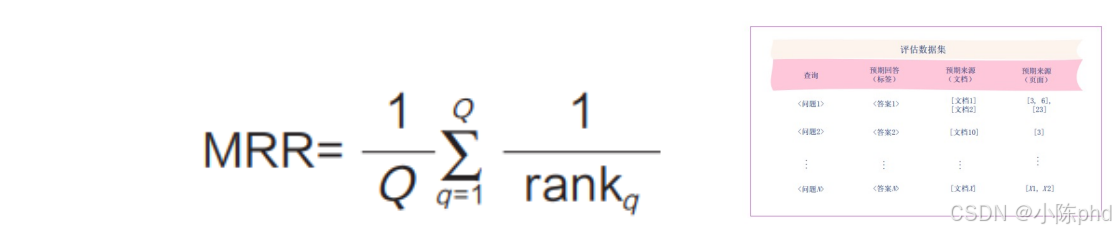
其中,Q 表示总查询数。rankq 表示查询 q 的第一个相关文本块的排名。该公式需要 取第一个
相关文本块排名的倒数,这意味着 MRR 只关注每个查询返回的第一个相关文本 块的位置。根据
这种计算方式,文本块排名越靠前,rankq 的倒数越大,MRR 也会越大。
2.5 平均精确率
- 平均精确率(MAP)是一项跨多个查询评估的精确率衡量指标,它不仅考虑了检索 结果的精确
率,还强调了文档排序的重要性。MAP 通过计算每个查询在不同排名的精确 率来评估检索效果,
确保重要的相关文档较为靠前,从而优化用户的搜索体验。 - 其中,Q 表示总查询数。而 Average Precision 是针对每个查询计算的平均精确度, 考虑了相
关文档的顺序。MAP 在搜索引擎等注重排名质量的系统中很实用,常用于电商平台的产品推荐系统 等场景。

2.6 P@K
- P@K 衡量的是前 K 个检索结果的精确率,确保在展示的前几项结果中尽可能多地包含相关信息。
- 其中,分子表示前 K 个结果中相关文档的数量,分母中的 K 是固定的返回数量。P@K 在用户特别关注前几项结果的场景中非常有用。例如,在新闻搜索系统中, P@K 可以确保用户在进行搜索时,查到的前几条新闻与查询主题高度相关,从而提升阅 读效率。

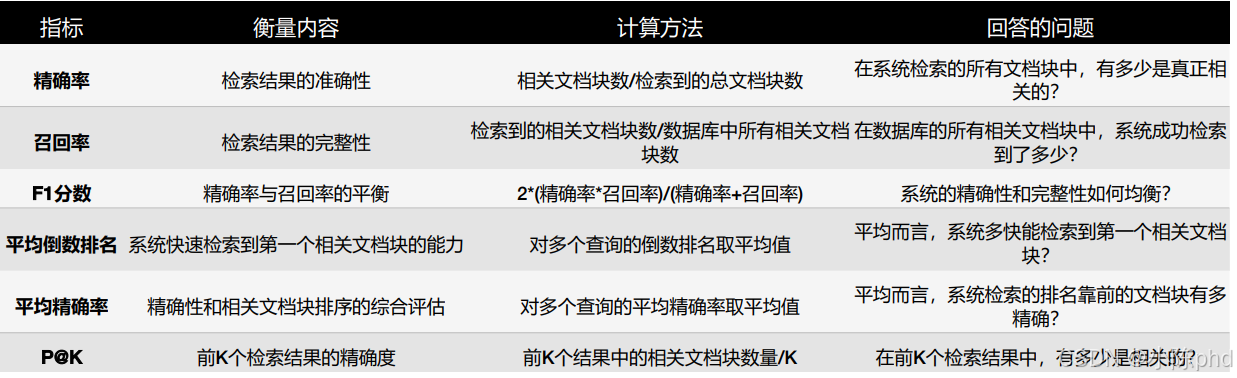
检索评估指标的简要说明及其特点
3. 生成器(响应)的评估
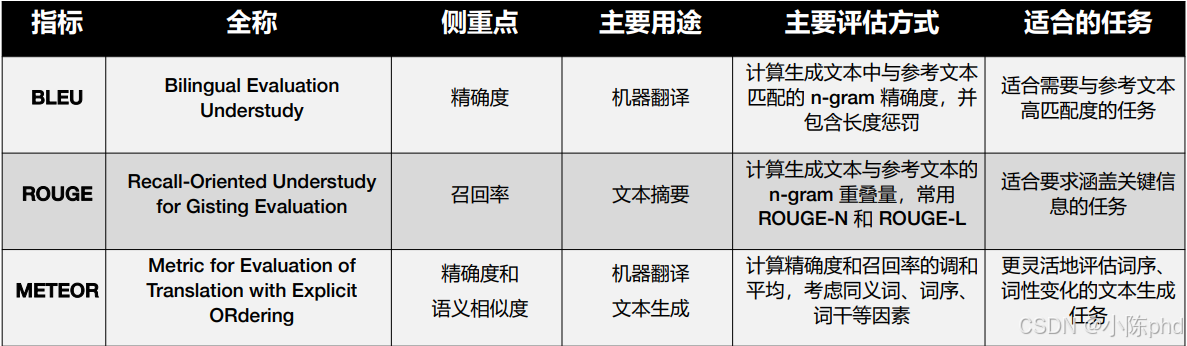
3.1 基于n-gram匹配程度的指标:BLEU
- BLEU(Bilingual Evaluation Understudy,可译为"双语评估替代工具")用于评 估生成的回
答与参考答案之间 n-gram 的重叠情况,强调精确率。它通过 n-gram(即连 续的 n 个 token
构成的序列,n 可以为 1、2、3、4 等)的精确匹配来计算分数。
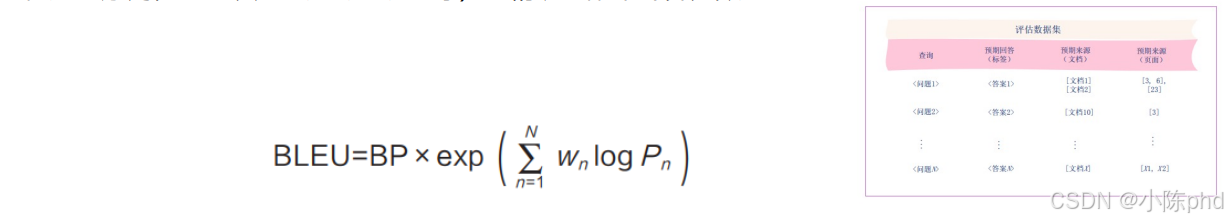
- 其中,BP 是长度惩罚(Brevity Penalty),用于防止生成的回答过短。若生成的回 答比参考答案短,则 BP 小于 1;否则,BP 等于 1。P n 是 n -gram 的精确率。w n 是每 个 n-gram 的权重,通常 w 1、w 2、w 3 和 w 4 的值相等。例如,假设参考答案为"the cat is on mat",而生成的回答为"the cat on mat"。 对 于BLEU-1(1-gram 精 确 度 ),1-gram( 单 词 ) 匹 配 项 包 括"the""cat""on""mat"4 个。生成的回答中有 4 个 1-gram。因此,1-gram 精确率 1。
3.2 基于n-gram匹配程度的指标:ROUGE
- ROUGE(Recall-Oriented Understudy for Gisting Evaluation,一般译为"面 向召回的摘要评估替代工具")用于计算生成的回答与参考答案之间 n-g ram 的重叠量, 并同时考虑了精确率和召回率,提供了较为平衡的评价方式。

继续使用前面的示例,假设参考答案为"the cat is on mat",而生成回答为"the cat onmat"。 对于 ROUGE-1(即 1-gram),匹配项包括"the""cat""on"和"mat"4 个。参考答案中有 5 个 1-gram。因此,ROUGE-1 为 0.8。 对于 ROUGE-2(即 2-gram),匹配项包括"the cat"和"on mat"2 个。参考 答案中有 4 个 2-gram。因此,ROUGE-2 为 0.5。
3.3 基于n-gram匹配程度的指标:METEOR
- METEOR(Metric for Evaluation of Translation with Explicit Ordering,一般 译为"具有显式排序的翻译评估指标")通过考量同义词、词干和词序等因素,提供了对 生成的回答与参考答案之间相似度更细致的评估。它不仅计算精确率和召回率的调和平均 值(F mean),还结合了一个惩罚机制来处理词序错误和其他不匹配的情况。METEOR 能 够比 BLEU 和 ROUGE 更好地捕捉语义特性。
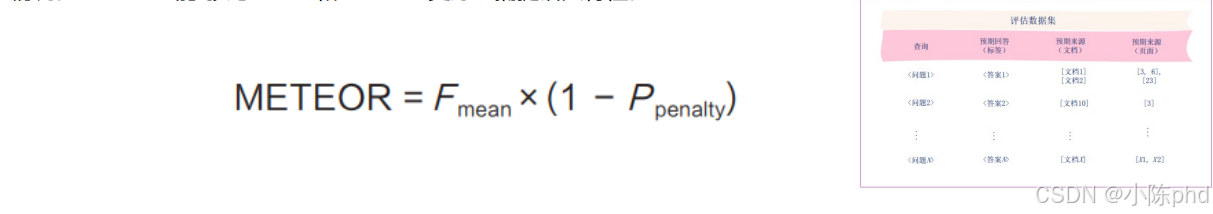
其中,F mean 是精确度和召回率的调和平均值,用于综合衡量生成的回答与参考答案 的匹配程度。P penalty 是一个惩罚项,用于惩罚词序错误及其他类型的错误。对于精确率,生成的回答包含 4 个单词,其中包含 4 个匹配项。因此,精确度为 1。 对于召回率,参考答案包含 5 个单词,其中包含 4 个匹配项。因此,召回率为 0.8。 对于调和平均值,F mean= (2×1×0.8) /(1+0.8) = 1.6/1.8 ≈ 0.89。 对于惩罚项,由于生成的回答中缺少了"is"这个单词,METEOR 会应用一个惩罚 项 P penalty。这个惩罚项的具体数值取决于具体的实现细节,但在本例中我们可以假定它为 0.1。 最终,METEOR 为 0.801。
BLEU、ROUGE和METEOR指标的总结比较
3.4 基于语义相似性的指标

3.5 基于忠实度或扎实性的指标
- 文档精确率和页面精确率:这些指标用于衡量大模型引用的文档和具体页面的准 确性。这要求大模型在生成回答时,必须清晰地标注其信息来源,以减少虚构信息的发生。
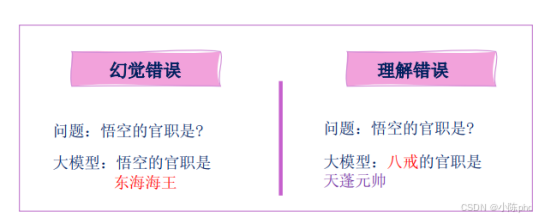
- 幻觉检测 / 一致性检查:这些指标旨在判断大模型生成的回答是否基于提供的上下文信息,或在不同查询中提供的事实信息是否一 致。在评估过程中,将采用二进制评估(0/1),如果生成的回答无法从给定的文档推导出,即便回答本身正确,也视为幻觉。
- 大模型评分量表:利用更强大的大模型对生成的回答进行评分,例如采用 0 到 5 分的评分标准。具体的评分标准可以根据业务需求进行定制,以便更灵活地适应不同的应用场景。
- 人工评估:由领域专家手动检查大模型生成的回答是否准确,并验证其是否合理引用了检索到的文档。
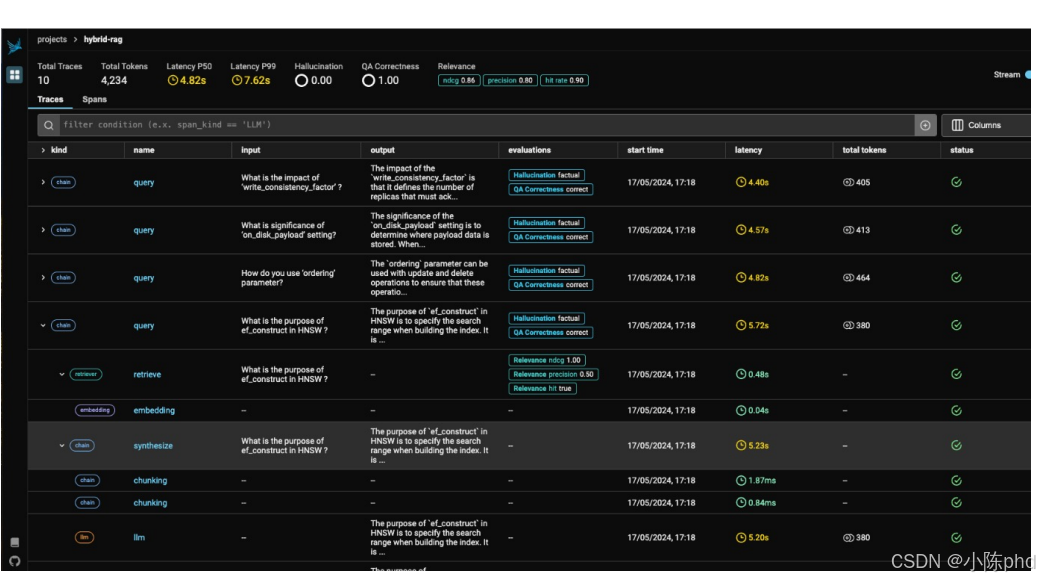
4. RAG评估框架/工具
4.1 RAGAS
4.2 Trulens

4.3 DeepEval

4.4 Phoenix提供的可视化界面