中国工业软件长期受困于"项目制"泥潭:场景极度碎片化、业务逻辑硬编码、系统烟囱林立。面对国产替代的迫切需求 与业务中间件匮乏 的现状,国产工业时序数据库DolphinDB将金融量化投研 领域验证过的读写极致性能与流批一体架构引入工业界。本文将深入剖析 DolphinDB 如何通过"存储+计算"的通用数字化底座+AI ,破解工业软件定制化僵局,重塑工业软件的开发范式,并详细拆解长江电力、中钢集团、中国空间技术研究院、中广核、核动力研究院的实战案例。
一、 困局:工业软件的"烟囱式"架构与定制化泥潭
在数智化转型深水区,工业企业面临着一个普遍的"不可能三角":高性能、低成本、快速迭代难以兼得。传统工业软件开发模式存在三大顽疾,导致工业软件定制化成本居高不下:
1.1 技术栈割裂,维护成本高昂 传统工业数字化系统常采用异构技术堆栈搭建:数据采集层依赖SCADA系统进行设备对接,时序数据存储选用InfluxDB/OpenTSDB等时序数据库或PI/IP21等实时数据库,实时计算层采用Flink流处理引擎,离线分析则通过ETL工具将数据导入Hadoop/Spark数仓,最终由Python技术栈完成算法建模。 这种"烟囱式"架构存在下面三个核心缺陷:
•**数据流断层:**原始数据需经历SCADA->TSDB->Flink->DataWarehouse->Python的多级搬运,物理传输带来的序列化/反序列化开销造成端到端延迟攀升至分钟级;
•**技术栈碎片化:**Java(Flink)、SQL(数仓)、Python(算法)等多语言混用,导致开发维护需要组建跨领域团队,知识传递成本呈几何级数增长;
•**系统熵增:**Zookeeper/Kafka/HDFS等中间件构成的复杂数据管道,使故障排查从单体系统的纵向追踪变为分布式系统的网状定位;
这些架构债务最终体现为:实时业务响应滞后于产线节拍,运维团队30%以上的精力消耗在组件间数据一致性校验,严重制约工艺优化的迭代速度。
1.2.业务逻辑硬编码,灵活性缺失 在高端制造场景(如卫星测试、核电监控等)中,复杂的业务规则(如"连续三个时间点温度上升且电压异常")往往被硬编码在底层代码中。一旦设备型号变更或工艺参数调整,开发人员必须重写代码、重新编译、重启服务,系统敏捷性严重不足。
1.3.缺乏统一底座,重复造轮子 相比于金融领域成熟的中间件体系,工业界长期缺乏架构完善的基础软件支撑。企业在开发工业物联网软件解决方案时,往往把大量精力耗费在底层数据的读写优化的"脏活累活"上,而非核心业务逻辑创新上。
二、 破局:将"金融级"能力降维打击至工业界
DolphinDB 起家于对性能要求极其苛刻的金融量化投研领域。在处理高频交易数据时练就的核心能力,恰好击中了工业大数据的痛点。
2.1. 读写极致性能:从微秒级交易到亿级测点
金融高频交易数据与工业时序数据在本质上具有高度的**"同构性"(Isomorphism)。DolphinDB 不仅将 PAX 行列混存、存算一体等底层技术引入工业,更关键的是,它将处理金融数据的核心算法范式**直接映射到了工业场景,解决了传统数据库难以处理的复杂计算问题。
1. 核心技术的降维打击
•存算一体(Data Localization): 计算任务可直接下推至存储节点执行,避免了存储层与计算层之间海量的网络传输开销。
•自适应压缩算法: 针对时序数据"时间连续、数值渐变"的特点,采用 Delta-of-Delta、LZ4 等专用算法,实现10:1~20:1的高压缩比,大幅降低存储成本。
2. "AsOfJoin ":解决多频数据对齐的杀手锏
在工业现场,不同传感器的采样频率往往天差地别(例如:振动传感器 10kHz,而温度传感器仅 1Hz)。传统 SQL 数据库在进行多维关联分析时,需要进行极其低效的插值填充(Resampling + Fill Forward)。
DolphinDB 将金融领域的 asof join(非同步连接) 算法引入工业界:
•金融场景: 用于将高频的逐笔成交(Tick)与低频的委托订单(Order)按时间戳模糊对齐。
•工业场景: 完美解决了异构频率数据的毫秒级对齐难题。 例如,将 1 秒采集 10000 次的振动数据与 1 秒采集 1 次的温度数据进行关联分析,无需任何 ETL 预处理,查询性能比传统 Join 提升 100 倍以上。
3. 业务逻辑的同构映射
DolphinDB 通过内置功能,实现了金融能力向工业场景的无缝迁移:
|------------------------|-------------------------|-------------------------------------|
| 金融场景 (Source) | 工业场景 (Target) | 核心价值 |
| K 线合成 (OHLC) | 数据降频 (Downsampling) | 将秒级原始波形实时聚合为分钟级趋势图,大幅降低渲染延迟。 |
| 盘口价差分析 | 多测点相关性分析 | 实时计算压力与温度的动态相关系数,精准定位故障根因。 |
| 历史回测 (Backtesting) | 工艺仿真 (Simulation) | 基于海量历史数据快速验证新的 PID 控制参数,实现"数字孪生"闭环。 |
成效验证: 在某电力物联网场景中,面对单机 百万级测点 的写入压力,DolphinDB 凭借上述技术实现了"写入不阻塞、查询毫秒级",彻底解决了传统时序数据库"写入快但复杂查询跑不动"的顽疾。
2.2. 流批一体:打破研发与生产的隔阂
DolphinDB 在计算引擎层面实现以下技术创新:
•**统一脚本语言:**使用 DolphinDB 脚本语言同时处理历史数据分析和实时流数据处理,消除技术栈分裂;
•**增量计算引擎:**基于数据版本管理,实现实时计算的增量更新,避免全量重复计算;
在量化金融中,投研人员用历史数据回测策略(批计算),交易员用实时数据执行策略(流计算)。传统架构下,这需要两套代码(Python 做研究,C++ 做实盘),转化成本极高。
DolphinDB 提出的流批一体 理念,允许工业用户使用同一套脚本语言(DLang)既处理历史数据分析,又处理实时流数据监控。研发与生产共用一套代码,开发成本可减少 90%。
2.3 算法集成框架
DolphinDB 内置 2000+ 专业函数与 100+ 专业插件,提供完整的算法集成能力:
•机器学习算法库:内置随机森林、梯度提升树、神经网络等常用算法;
•优化求解器:提供线性规划、整数规划、非线性规划等数学优化工具;
•信号处理函数:针对工业振动、声学等信号数据提供专业处理函数。
三、 解法:构建"模块化、可复用"的通用数字化底座
针对工业场景的碎片化问题,DolphinDB 并没有选择做垂直行业的定制应用,而是选择做"底座"。其核心逻辑是模块化、可复用,避免重复开发,提升效率。DolphinDB提供了2000+的内置函数 ,20+的流计算引擎 ,还提供了物联网点位管理引擎、规则引擎、复杂事件处理(CEP)引擎、工业实时监控引擎等专业引擎,便于低代码高效开发。
3.1. 点位管理引擎
在工业物联网(IIoT)场景中,设备点位数量庞大、数据类型复杂是普遍痛点。DolphinDB 点位管理引擎为海量点位数据进行高效管理提供了一个核心组件,如下图所示它由三部分构成:TSDB 引擎、点位最新值缓存表、点位静态信息表:
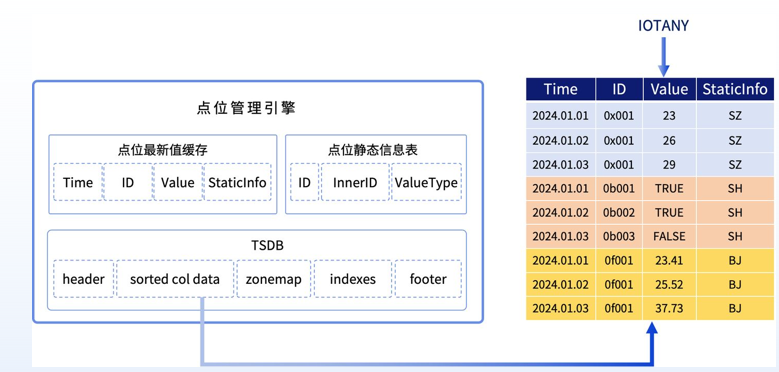
•TSDB 引擎: 负责底层存储。
•点位最新值缓存表: 系统实时更新,直接从内存读取最新数据,无需查盘。
•点位静态信息表: 映射内部 ID 与物理测点,通过 IOTANY 列(值类型可变的列,能够在单值模型的字段里存储不同类型的属性值)优化存储结构(如将开关状态等布尔值高效压缩)。
3.2.工业实时监控引擎:用配置替代代码
在典型的工业物联网场景中,设备数量巨大、信号频繁更新。过去,工程师需要为每种监控逻辑单独编写底层代码,例如:
•某温度传感器连续3次上升;
•某压力传感器读数超出阈值;
•当温度正常且压力稳定时触发联动告警。
这些规则写在代码中,编写难度高、修改困难。为此, DolphinDB 在流计算框架之上,开发了两类通用计算引擎------稀疏响应式状态引擎 (SparseReactiveStateEngine) 和 无状态响应式引擎 (ReactiveStatelessEngine),将复杂逻辑抽象为可配置规则表,实现低代码化的工业事件监控。
下表比较了两个核心引擎:
| 引擎类型 | 计算特点 | 使用场景 | 示例 |
|---|---|---|---|
| 稀疏响应式状态引擎(SparseReactiveStateEngine) | 需要时间窗口、历史状态计算 | 连续趋势监测,如"连续三次上升" | 设备A001的温度连续3次上升触发事件B |
| 无状态响应式引擎(ReactiveStatelessEngine) | 基于最新状态、跨指标逻辑判断 | 综合条件判断,如"多指标同时满足" | 当温度正常且压力正常时触发事件A |
可以简单地理解为:
•稀疏引擎是"单元格的内部逻辑"------ 处理每个传感器自身的时间变化;
•无状态引擎是"Excel面板上的公式" ------ 监控多个传感器的组合状态。
二者组合起来,即可覆盖"时间维度 + 横截面维度"的所有事件监控需求。
以下是典型的数据流示意图:
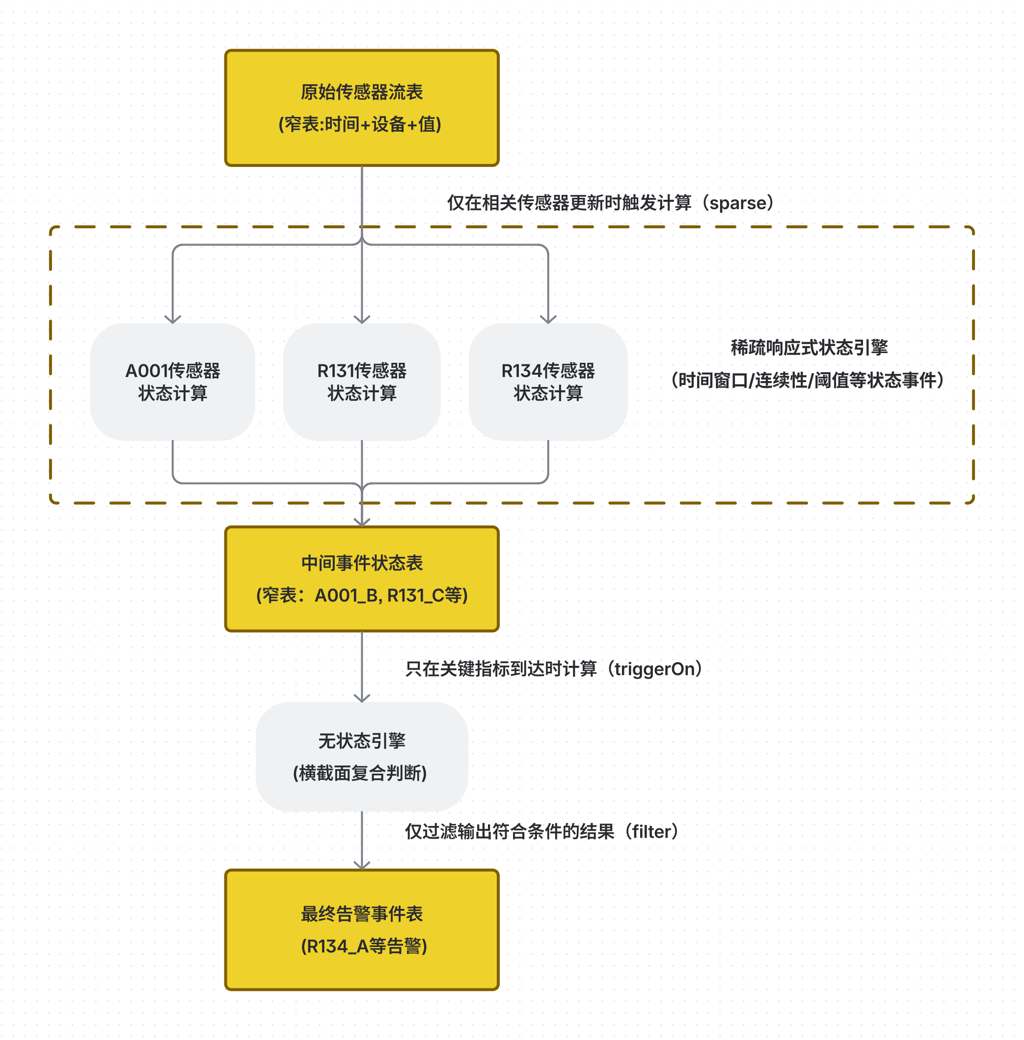 标题图:数据流程图
标题图:数据流程图
用户可以按需串联使用,一般为 "稀疏引擎 → 无状态引擎",也可反向组合,实现层层递进的复杂逻辑。
价值对比:传统 Flink 开发需要编写 Java 类、打包、上传集群、重启任务,耗时以'小时'计;DolphinDB 引擎仅需执行几行脚本即可热加载新规则,耗时以'秒'计。
四、 验证:标杆案例深度复盘
案例 1:长江电力------海量测点的"统一底座"
•背景挑战 : 作为国内最大水电企业,长江电力下辖三峡、白鹤滩等六座巨型电站,总测点数200余万点,日产生数据几百亿行。原有的"Flink + Java"架构开发效率低,且在多测点关联查询时存在严重的性能瓶颈。
•DolphinDB 方案:
· 存储层: 利用分布式存储引擎,支撑每天几百亿行数据的稳定写入,解决了海量历史数据的存储难题。
· 计算层: 利用内置的时间序列引擎,在数据库内部直接完成数据的秒级降频和聚合计算,避免了将海量原始数据拉取到应用层处理。 内置实时计算脚本,替代 Flink 复杂流处理逻辑,开发周期从数周压缩至数天。
•成效: 成功集成于统一的工业互联网平台。不仅解决了存储问题,更关键的是实现了对发电机组电压、电流、仪表数据的实时关联分析,方案可直接复用于各类发电场景。
案例 2:中钢集团------从"人工经验"到"算法寻优"
•背景挑战: 在焙烧工艺生产线中,为了保证球团质量,需要实时调整物料投放比例和风机功率、带式焙烧机温度等控制参数,以使生产达到稳态情况(球团质量达标、产线生产状态稳定)。传统方案依赖人工经验,单次产线调整耗时半年,且无法形成闭环优化。
•DolphinDB 方案:
·数据融合: 替代了原有的"SQL Server + InfluxDB"混合架构,统一存储产线与能耗数据。
· **编程语言统一:**替代了Flink + Spark + Python等多种语言,统一使用DolphinDB脚本编写。
· 算法赋能: 利用 DolphinDB 内置的机器学习插件(如随机森林、拟牛顿法),构建了参数寻优模型。系统结合流体力学公式(机理模型)和历史数据(数据模型),能根据目标产量实时计算出最优的生产参数集。
•成效: 实现了工艺参数的实时预测与自动寻优,大幅缩短了钢铁厂投产时间,节约了昂贵的物料与能源成本。用国产时序数据库软件DolphinDB替代了昂贵的施耐德 Ampla工业软件,方案也可复用于化工、冶金等流程工业。
案例 3:中国空间技术研究院------复杂规则的"低代码"实现
•背景挑战 : 卫星在发射前需要进行长周期的地面测试,涉及数十个子系统、2 万+ 指标、600类总计7000 余个规则,多个系统与多种指标的综合分析复杂度极高。原有 Java 系统代码臃肿,新增一个测试规则需要经历漫长的开发与测试周期。
•DolphinDB 方案:
· 引擎替代代码: 利用 DolphinDB 的工业实时监控引擎如稀疏状态引擎 和无状态响应式引擎,将复杂的 Java 逻辑转化为规则配置。
· 具体实现案例: 在卫星实验时,需要判读多个指标,而且有些指标是状态相关的复杂计算,比如有以下判读条件:
·事件 A:判断卫星是否处于加电状态,离散电压量在连续三个时间点上逐步递增;
·事件 B:判断激光终端 1CPA 反射镜 1 主份温度是否异常,温度在连续三个时间点上都大于 -40 度;
·事件 C:判断激光终端 10FA 反射镜 2 备份温度是否异常,当前温度是否处于 -10~42 度之间。若满足,进一步判断事件 A 与事件 B 是否成立;
· DolphinDB 工业实时监控引擎的主要代码实现:
· 状态引擎:
· 事件 A,参数 P001, 定义:msum(delta(P001), 3) == 3, 输出事件名称:P001_A
· 事件 B,参数 P002, 定义:msum(P002 > -40, 3) == 3, 输出事件名称: P002_B无状态引擎:
· 事件 C, 触发源 P003,定义: P003 > -10 and P003<42 and P001_A and P002_B,输出事件名称: P003_C
•成效: 新功能上线周期从数周压缩至数天,且系统性能满足了毫秒级实时监控的需求。
案例 4:中广核------核反应堆故障的智能诊断
背景挑战:核反应堆运行过程中,经常出现由首个监测点异常迅速影响多个关联点的故障工况,需结合一段时间内的全局数据表现,快速定位与判断异常点 。传统人工排查方式效率低下,由于大型设备设计复杂,相关监测点描述往往散落在上千页设计图纸的某段流程图里,人工难以高效定位。
DolphinDB 方案:
•数据相关性分析:例如蒸汽管道小破口泄露(SGTR)工况发生,引发一系列数据变化:一回路传感器压力下降->一回路管道温度传感器温度上升->引发二回路压力上升->自动启动应急措施(如高压安注系统、余热排出系统)。在6500+点位的条件下,需要快速进行故障诊断。以往用人工定位,费时费力。而使用DolphinDB数据相关性分析函数,只要下面一行核心代码:
correlationMatrix = corrMatrix(matrix(pivotTable[,1:]))
即可通过仿真机产生的数据找出所有其他异常点位,判断 SGTR 是否发生。
•任务相关性分析:需要判断任务的时长与人员分配是否合理,以优化资源配置,提升整体效率。通过DolphinDB的时序聚合引擎、响应式状态引擎,将任务表达式、触发条件固化到 DolphinDB 中,形成可执行、可监控的自动化任务链 。
成效:实现了蒸汽管道小破口泄露等典型故障的快速诊断与定位,显著提升核电站安全运行水平。
案例 5:核动力研究院------AI 智能体赋能工业知识管理
背景挑战:核电站故障处理需要快速定位故障源头,并从海量文档中精准检索操作规程,传统方式响应效率低下。
DolphinDB 方案:
•人机交互:故障发生时快速定位源头,并从海量文档中精准检索对应操作规程和应对措施,提升了应急响应效率。
•智能问数:针对大量点位数据,通过自然语言生成 SQL,降低技术门槛,实现数据统计分析的民主化;
•任务编排:在"预测温度传感器未来一小时温度"的场景中,通过智能体实现C++ 取数 → Python 预测 → 可视化展示的全流程自动化
成效:构建了集数据查询、故障诊断、知识检索于一体的智能运维平台,大幅提升应急响应效率。
五、 展望:AI 赋能的下一代工业底座
随着大模型与深度学习技术的爆发,DolphinDB 正在将其底座能力向 AI 全栈延伸,致力于解决从数据交互、模型训练、算力加速到模型部署的全流程难题:
1. AI Agent 与 RAG 支持:为大模型装上"工业记忆"
通过内置的 向量存储(VectorDB) 和文本检索能力,DolphinDB 已成为 RAG(检索增强生成)架构的理想底层支撑:
•构建高价值上下文(Context Window): 大模型虽然逻辑强大,但在工业现场往往面临"失忆"困境。DolphinDB 的价值在于,它能毫秒级从万亿级时序数据中检索出最相关的**"故障波形片段",并将其特征化投喂给模型。这不仅为 AI 提供了最近 24 小时的高频数据作为上下文,更有效抑制了模型的"幻觉"**,确保每一次推理都基于真实的现场数据。
•知识与数据融合: 工业知识库(如维修手册)与实时数据在库内打通。工程师通过自然语言即可交互:"当前 3 号风机振动异常可能的原因是什么?历史上有无类似情况?"AI 将结合实时读数与历史案例给出精准建议。
2. AI DataLoader:打通深度学习训练的"数据大动脉"
针对深度学习模型对海量因子数据(如技术指标、波动率)的训练需求,DolphinDB 推出了 AI DataLoader,解决了传统"落地成文件"模式面临的内存带宽瓶颈与存储空间焦虑:
•消除IO瓶颈: 传统流程需要将数据库中的 TB 级因子导出为 CSV/Parquet 文件,再由 Python 读取,效率极低且占用大量磁盘。DDBDataLoader 实现了数据库与 PyTorch/TensorFlow 等深度学习框架的直接对接。
•流式管道传输: 通过高效的内存共享与数据管道技术,AI DataLoader 能够以流式方式将因子数据"喂"给模型训练进程。这不仅打破了单机内存对训练数据量的限制,更大幅简化了工程链路,让数据科学家能专注于挖掘那些不可见的变量关系与新规律。
3. GPU 异构计算(Shark 平台):算力利用率的极致突破
针对工业仿真、遗传算法寻优等计算密集型任务,DolphinDB 推出了 异构计算平台。
•**无缝迁移,高效开发:**针对以往在 CPU 上执行时资源占用量大、耗时突出的计算任务,用户仅需在自定义函数前添加 @gpu 标签,即可实现向 GPU 计算的无缝迁移,显著提升运算效率。其核心优势在于能够自动解析自定义函数并将计算逻辑转化为可在 GPU 上执行的计算图,使开发者无需进行任何 CUDA 相关的二次开发,即可获得相较于 CPU 计算 10~100 倍以上的性能提升。
•成效: Shark 适用于子任务多、并行度高,输入输出数据量少、计算量大的各类 GPU 通用计算密集型需求,如科研中的蒙特卡洛仿真等场景。Shark相比传统 CPU 方案性能提升 数十倍,让原本需要数小时的计算任务在分钟级内完成。
4. 库内推理(In-Database Inference):数据不出库,模型跑进来
DolphinDB 支持通过插件直接加载 LibTorch (PyTorch) 或 TensorFlow 训练好的深度学习模型。
•流水线融合: 实现了从"数据清洗"到"特征工程"再到"模型推理"的全流程闭环。用户无需将海量历史数据导出到 Python 环境进行预测,彻底消除了数据移动带来的延迟与安全风险,特别适用于未来一小时负荷预测、实时质量检测等时效性要求极高的场景。
六、 核心价值问答(FAQ)
Q:为什么工业场景需要引入金融级时序数据库? A: 工业与金融在数据处理上具有同构性(高频、海量)。DolphinDB 将金融级的存算一体 和流批一体引入工业,解决了传统架构中数据搬运导致的延迟高、一致性差的问题。
Q:DolphinDB 如何替代 Flink + InfluxDB 架构? A: DolphinDB 通过All-in-One设计,在数据库内部内置了流计算引擎。用户无需维护 Flink 集群和 Kafka 管道,直接在库内完成清洗、聚合和告警,开发成本降低 90%。
结语
从金融交易的高频脉冲,到工业生产的机器轰鸣,DolphinDB 证明了底层数据逻辑的相通性。通过构建一个模块化、高复用、流批一体的通用数字化底座,DolphinDB 正在帮助工业企业摆脱无休止的软件定制化泥潭。这不仅是一次技术架构的升级,更是工业软件从"作坊式开发"向"平台化运营"转型的必经之路。
文章标签与关键词:
•核心产品: DolphinDB,Shark
•技术架构: 时序数据库 (TSDB), 流批一体, 存算一体, 矢量计算, 响应式状态引擎,库内推理 (In-Database Inference) ,实时数据库
•应用场景: 工业物联网 (IIoT), 智能制造, 能源电力, 核电监控, 故障诊断
•痛点解决: 工业软件国产替代, 数字化底座, 降本增效, 消除数据孤岛, 低代码开发,消除 IO 瓶颈
•AI 融合: AI Agent, RAG, 工业大模型, 异构计算 (Shark),AI DataLoader, 深度学习 (Deep Learning), PyTorch/TensorFlow 集成