InfiniSynapse 可以把藏匿在文档中的小二维表格和实际的业务结构化数据做联合分析,实现了一种真正意义的"数据挖掘",极大的扩大了数据的提取质量。
前言
数据分析其实大概是两种大的类型。 一个是文档,我们简称 docs,文档里面可能还有少量表格。比如某个公司的财务报告的PDF里就有很多二维表格数据。所以非结构化数据往往蕴含了大量的结构化数据。
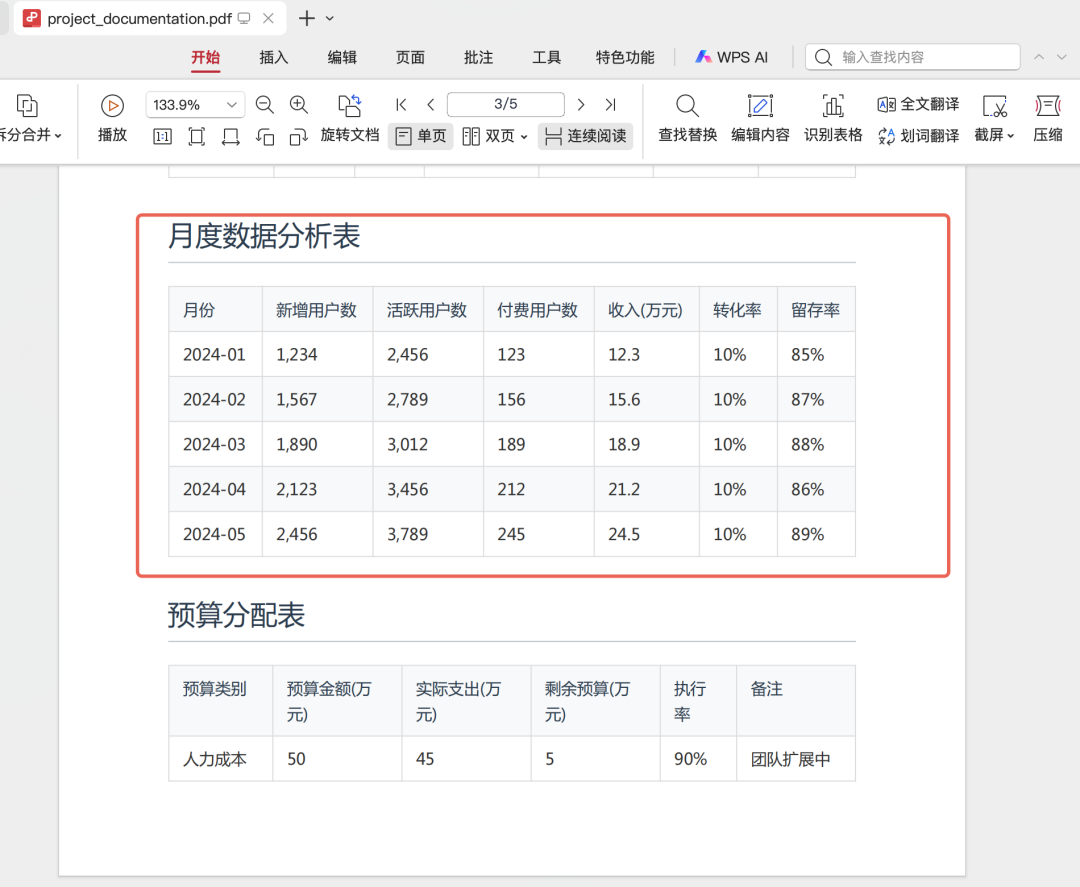
第二类就是结构化数据,我们简称为data. 也就是大家常见的 Excel数据,业务数据库、数仓里的数据。
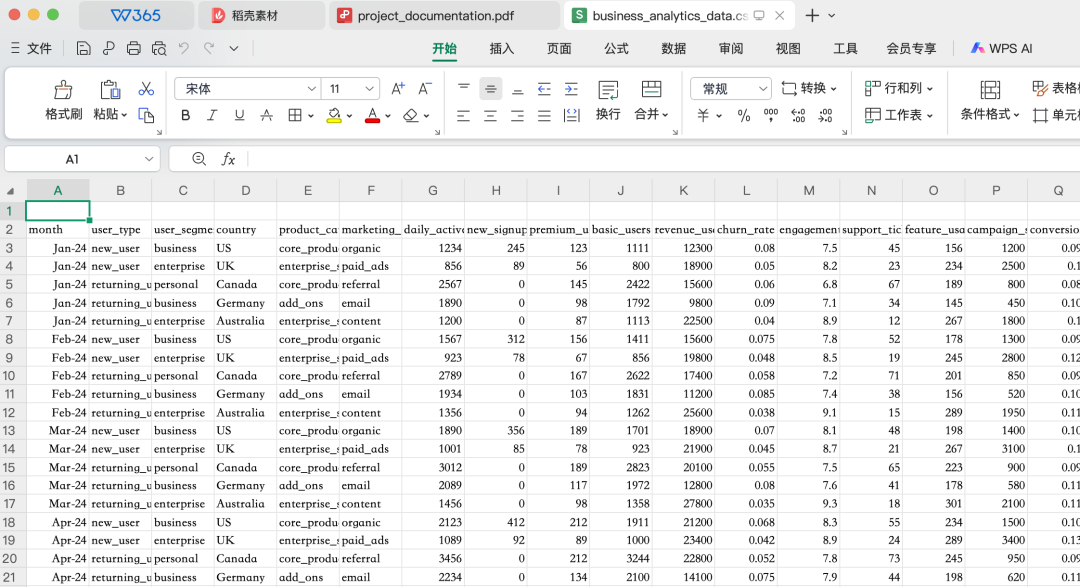
或者这样的:
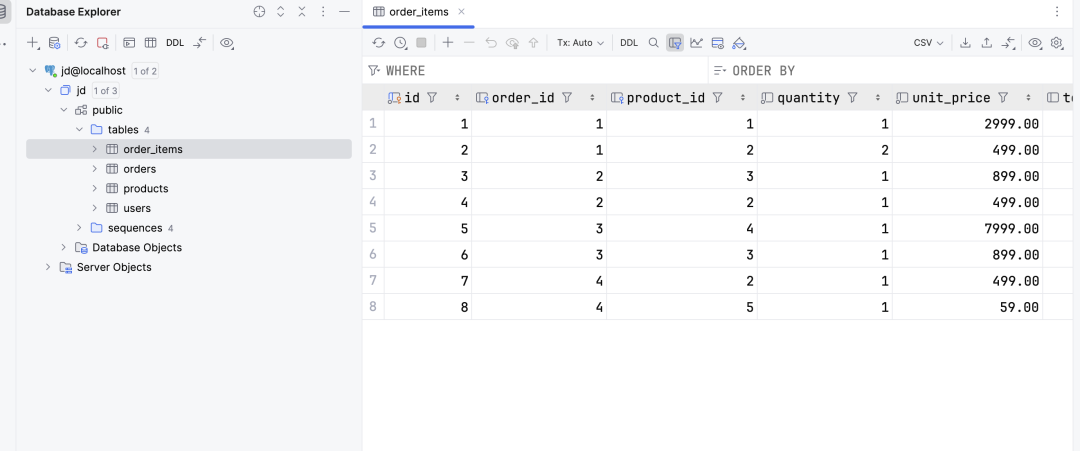
Data 数据里其实也有大量非结构化数据,比如某个某个字段其实是一个大文本字段。
InfiniSynapse 对两类数据分别做了映射,docs 数据映射到知识库,data 类的数据放在数据源。
如前所述,在实际场景里,我们可能希望从知识库获取一个小的二维表格,然后和数据集里的实际数据做关联分析。 InfiniSynapse 支持这种融汇贯通。我们一个一个来。
知识库里的表格数据单独使用
先创建个知识库:
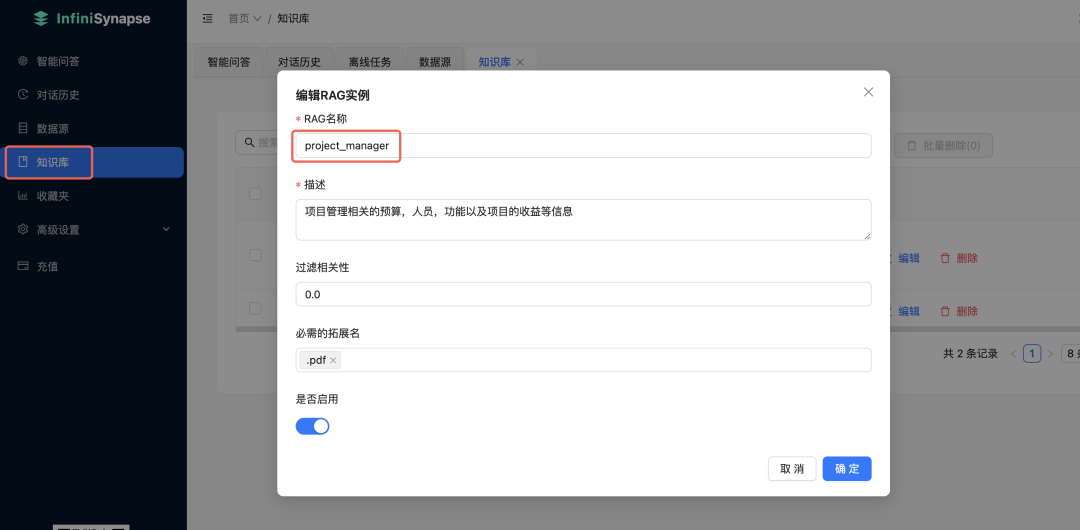
然后上传PDF文档:
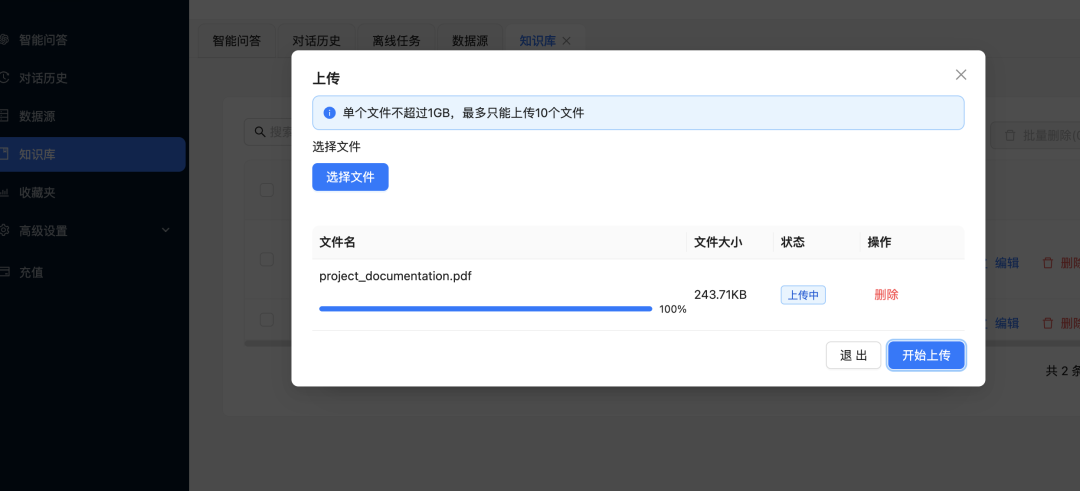
文档里有这样的表格:
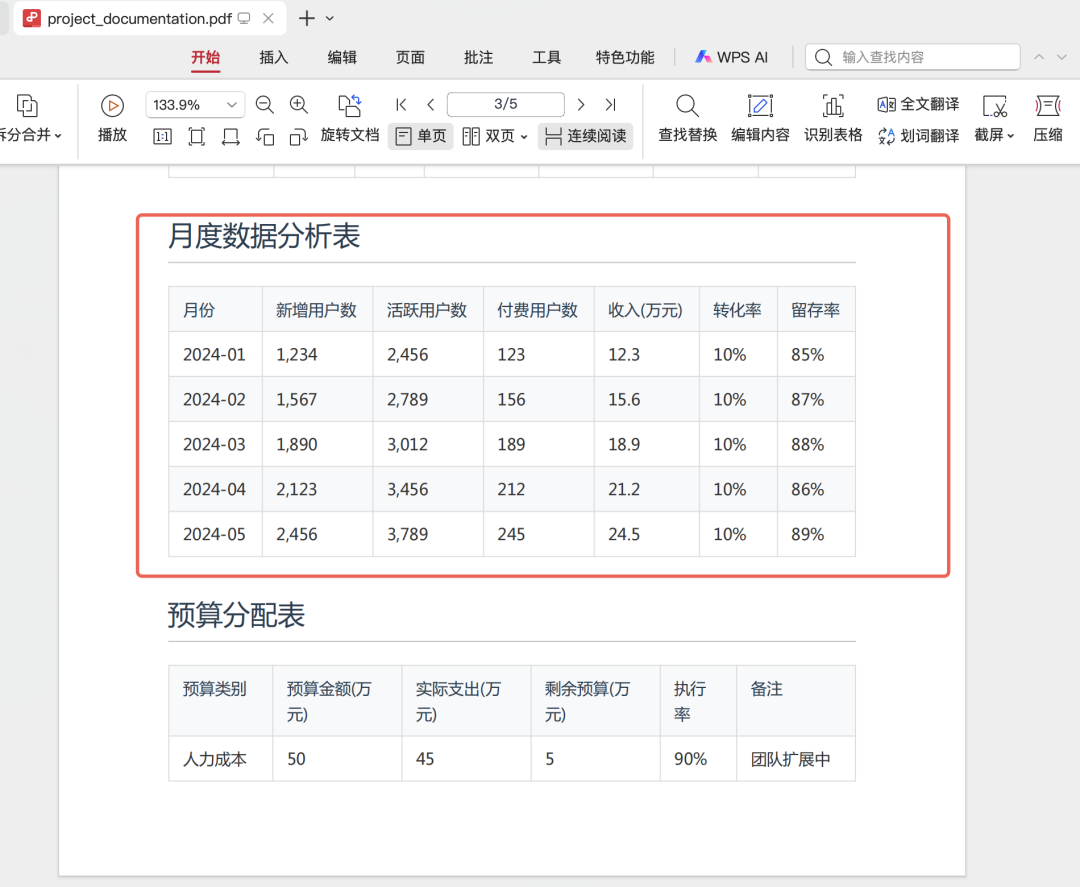
现在,可以直接在问了:
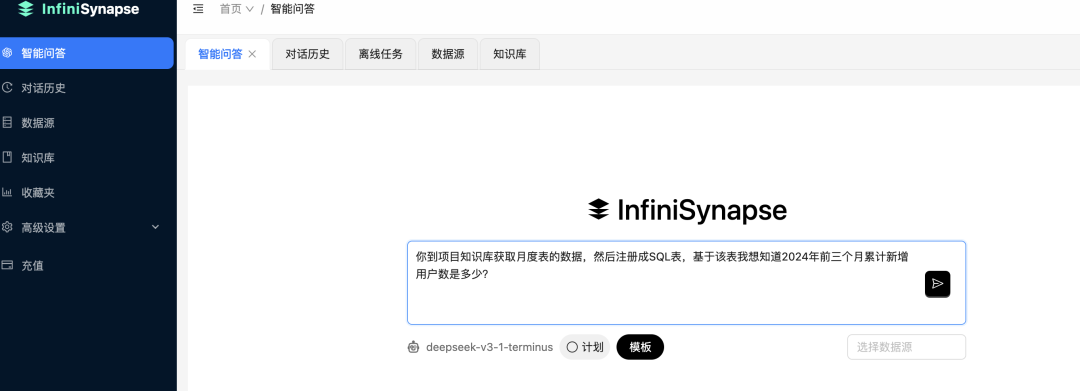
系统就会从知识库获取信息,注册成表,然后做计算:
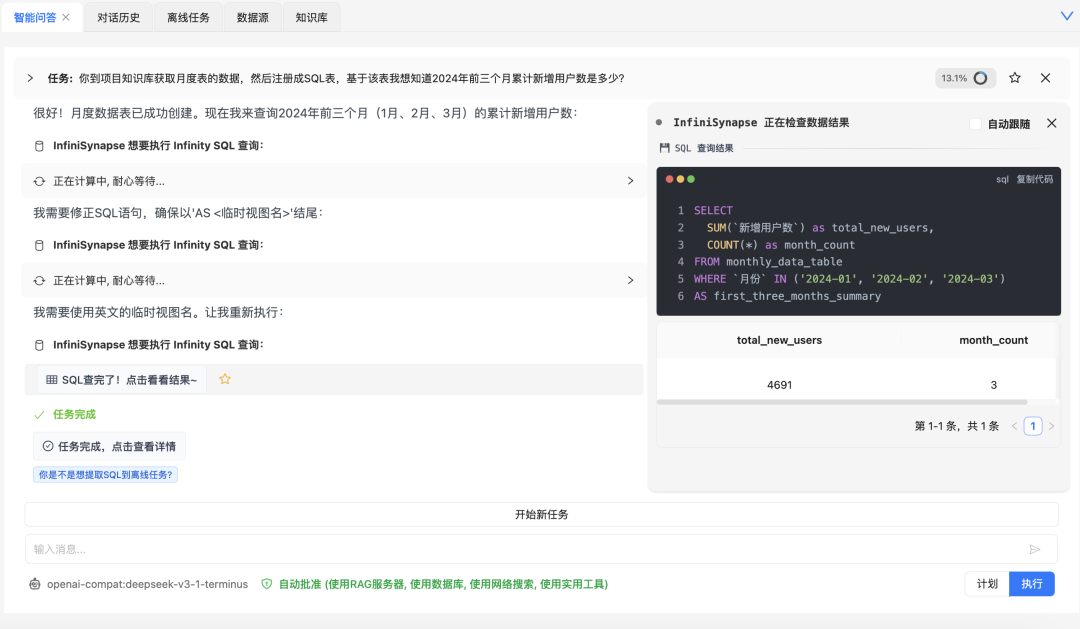
注意,这里我们的是通过SQL做计算的,而不是AI自己做的计算,所以准确度有保障,绕过AI不太会做计算的问题。
把PDF里的表格和Excel/业务数据联合分析
现在就到了今天的重点,我如何把 PDF 里的表格和csv里的数据做关联分析呢?创建数据源:
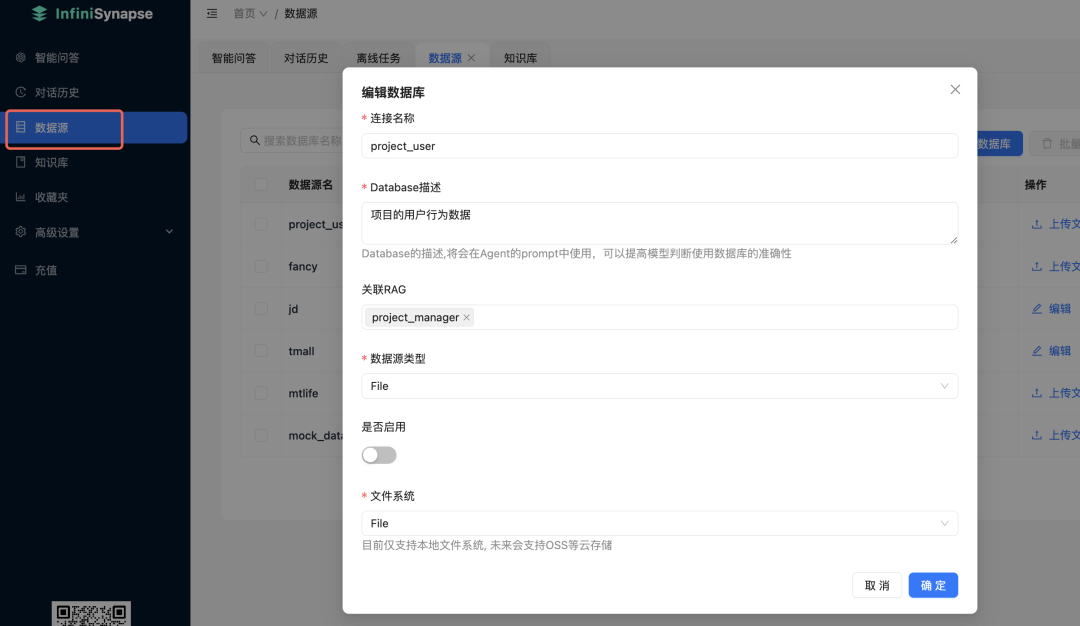
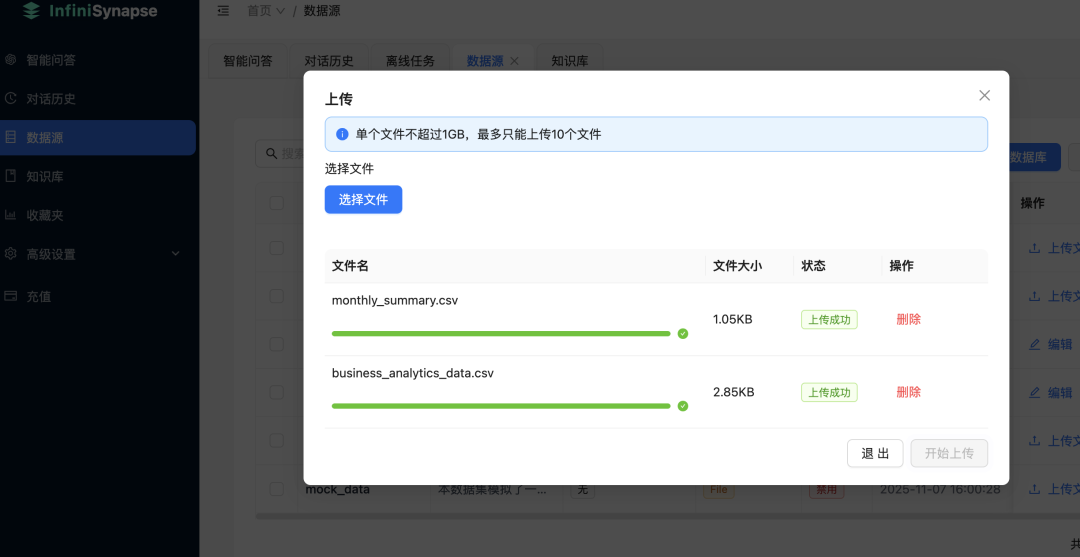
然后 RAG 关联那,选择我们前面建的知识库。接着上传数据:
在智能问答页面添加数据源:
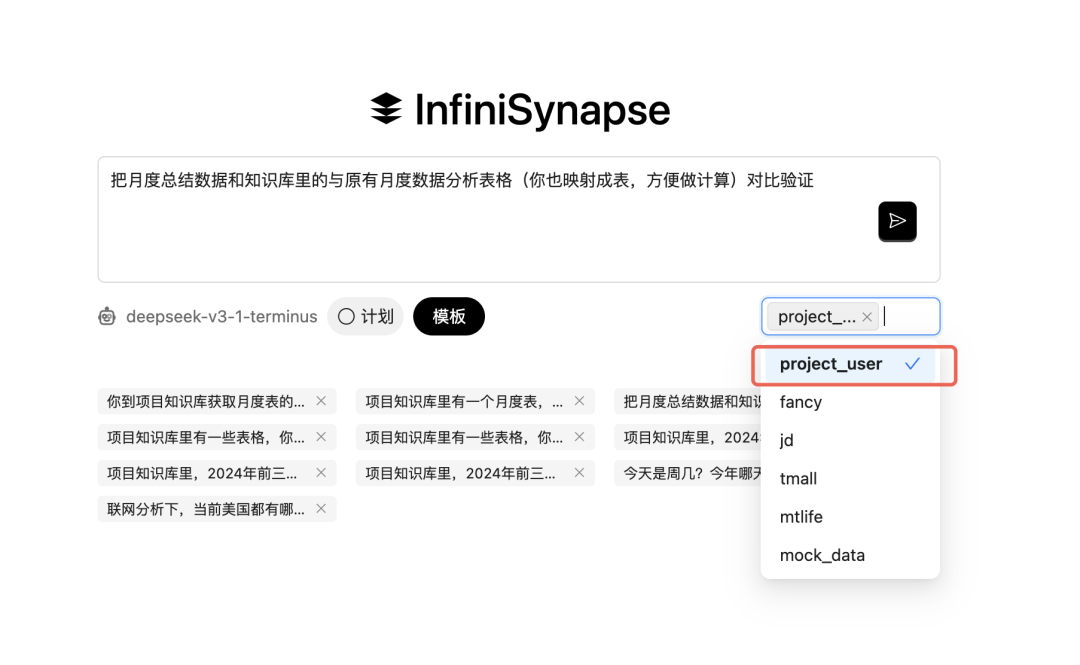
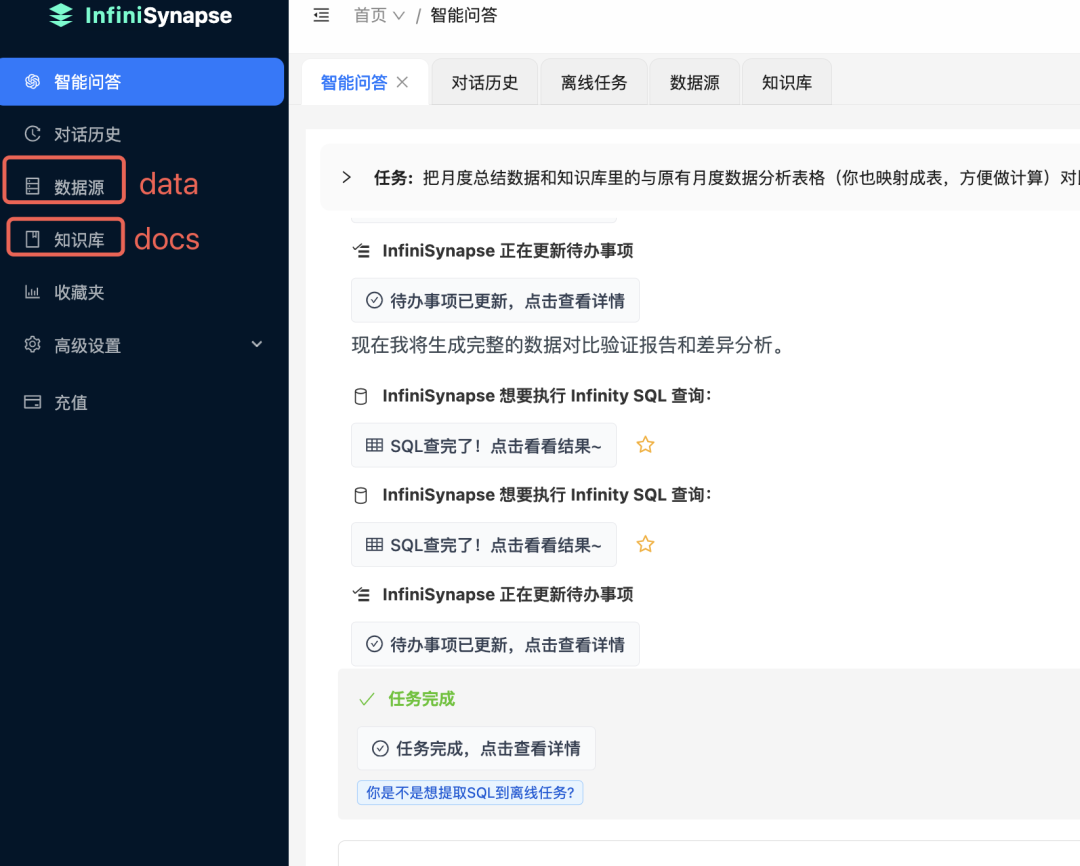
然后询问问题。这里,我们希望把知识库里的月度数据和csv里的数据做一个对比验证。最后执行结果如下:
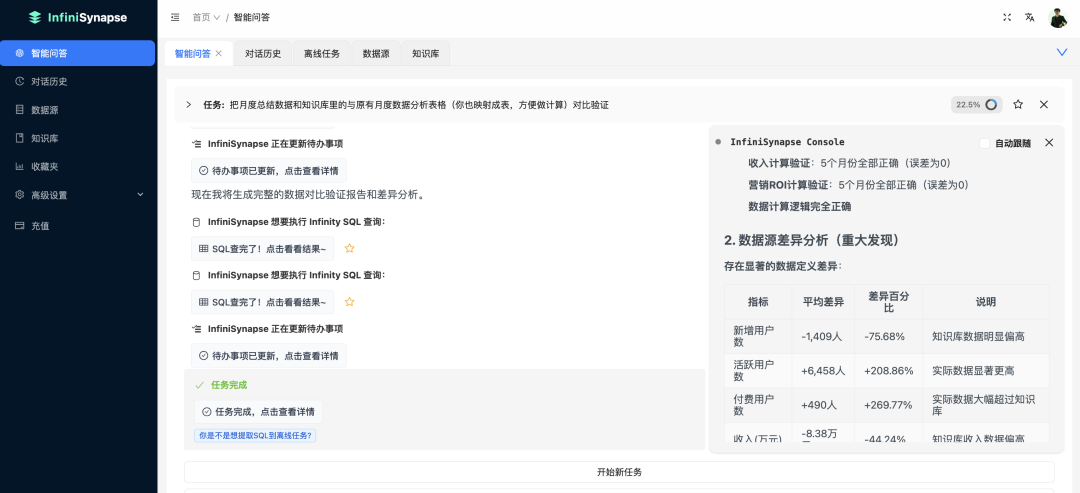
在这里,InfiniSynapse 汇报知识库里的小表格注册成一张表:
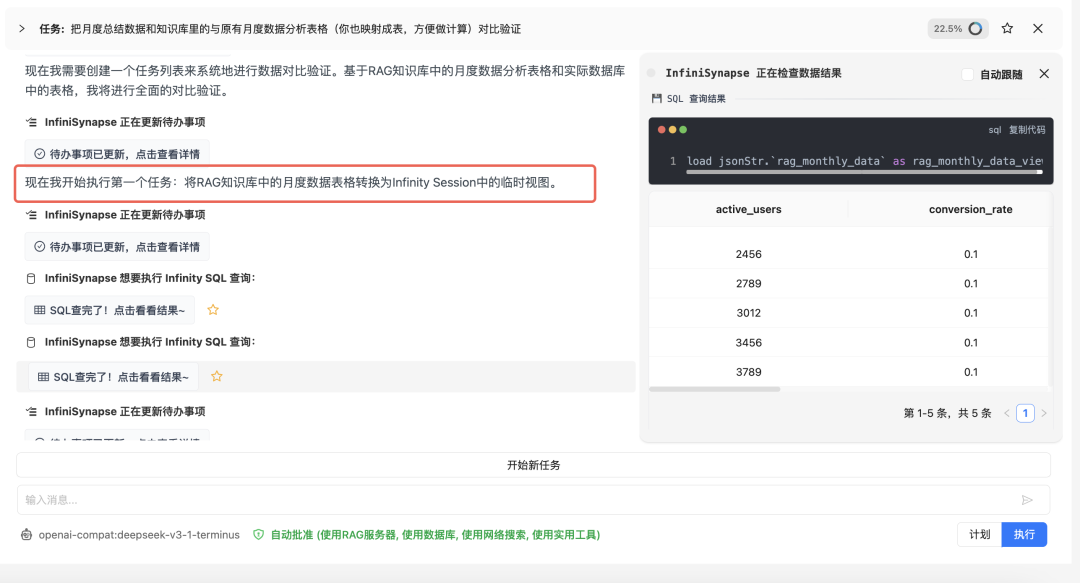
然后和csv的数据集做关联分析。
总结
InfiniSynapse 可以把藏匿在文档中的小二维表格和实际的业务结构化数据做联合分析,实现了一种真正意义的"数据挖掘",极大的扩大了数据的提取质量。
想查看文章的最新版本,可以点击原文链接。