从"炼丹"到"炼钢":我们如何将机器学习推理服务吞吐量提升300%
文章目录
- 从"炼丹"到"炼钢":我们如何将机器学习推理服务吞吐量提升300%
-
- 引言
- 一、问题诊断:为什么简单的部署方式会"翻车"?
-
- [1.1 初始架构的致命缺陷](#1.1 初始架构的致命缺陷)
- [1.2 性能瓶颈分析](#1.2 性能瓶颈分析)
- 二、架构演进:从单体服务到高性能推理引擎
-
- [2.1 技术选型:为什么选择Triton而不是TF Serving?](#2.1 技术选型:为什么选择Triton而不是TF Serving?)
- [2.2 Triton架构设计](#2.2 Triton架构设计)
- [2.3 模型配置优化](#2.3 模型配置优化)
- 三、核心优化:动态批处理实战
-
- [3.1 动态批处理原理](#3.1 动态批处理原理)
- [3.2 批处理大小的影响](#3.2 批处理大小的影响)
- [3.3 实际部署中的坑](#3.3 实际部署中的坑)
- 四、性能对比:优化前后的惊人差异
-
- [4.1 成本效益分析](#4.1 成本效益分析)
- [4.2 真实业务影响](#4.2 真实业务影响)
- 五、监控与调优:持续优化的关键
-
- [5.1 关键监控指标](#5.1 关键监控指标)
- [5.2 关键监控指标实现](#5.2 关键监控指标实现)
- [5.3 自动调优策略](#5.3 自动调优策略)
- 六、经验总结与最佳实践
-
- [6.1 核心经验总结](#6.1 核心经验总结)
- [6.2 避坑指南](#6.2 避坑指南)
- [6.3 不同场景的技术选型建议](#6.3 不同场景的技术选型建议)
- 七、未来展望
- 互动与交流
你可能想不到,这个看似简单的优化,竟让我们的在线推理服务从每天处理10万请求提升到40万请求,而服务器成本只增加了20%。
引言
我们团队负责的商品推荐模型服务曾遇到了一个棘手的问题:平时运行良好的服务,在流量高峰时频繁超时,P99延迟从平时的200ms飙升到5秒以上。更糟糕的是,由于GPU内存不足,部分请求直接被拒绝,导致转化率下降了8%。
我们当时使用的是典型的"炼丹"式部署:一个Flask服务加载PyTorch模型,每个请求独立处理。看起来简单直接,但在真实的生产流量面前,这种架构暴露出了严重的问题:
- GPU利用率极低:大部分时间GPU在"空转",利用率只有15-20%
- 内存浪费严重:每个模型实例独占GPU内存,无法共享
- 并发能力差:单实例最多处理8个并发请求
- 冷启动慢:模型加载需要30秒,扩容响应不及时
经过3个月的架构重构和优化,我们最终将服务吞吐量提升了300%,延迟降低了70%,而成本只增加了20%。下面我将分享这个完整的优化过程。
一、问题诊断:为什么简单的部署方式会"翻车"?
1.1 初始架构的致命缺陷
我们最初的部署架构非常简单,也是很多团队刚开始做机器学习服务化时的常见选择:
python
# 初始版本:简单的Flask + PyTorch服务
from flask import Flask, request, jsonify
import torch
import torch.nn.functional as F
app = Flask(__name__)
model = None
def load_model():
"""加载模型 - 耗时30秒,占用GPU内存4GB"""
global model
model = torch.load('recommendation_model.pth')
model.to('cuda')
model.eval()
@app.route('/predict', methods=['POST'])
def predict():
"""处理单个预测请求"""
data = request.json['features']
tensor = torch.tensor(data).to('cuda')
with torch.no_grad():
output = model(tensor)
probabilities = F.softmax(output, dim=-1)
return jsonify({'probabilities': probabilities.cpu().numpy().tolist()})
if __name__ == '__main__':
load_model() # 启动时加载模型
app.run(host='0.0.0.0', port=5000)这个架构的问题在测试环境不明显,但在生产环境流量不均衡时暴露无遗:
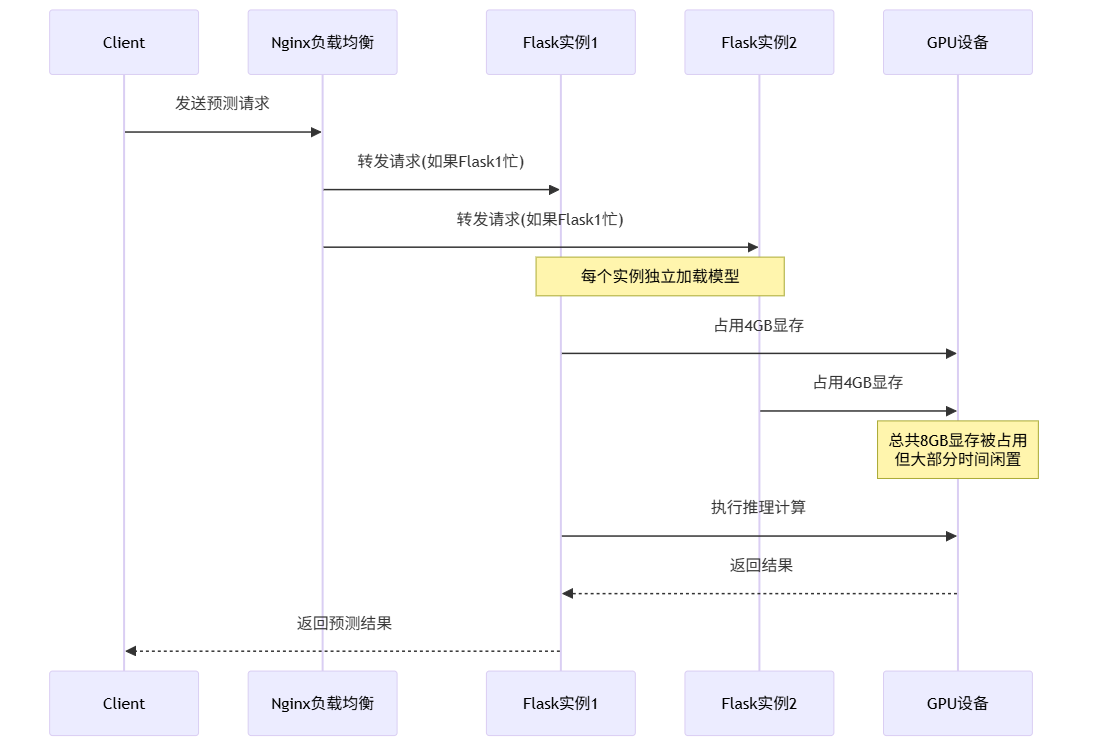
1.2 性能瓶颈分析
我们使用PyTorch Profiler和自定义监控对服务进行了详细分析:
python
# 性能分析脚本
import time
from concurrent.futures import ThreadPoolExecutor
import requests
import statistics
def stress_test(url, num_requests=100, concurrency=10):
"""压力测试工具"""
latencies = []
def send_request():
start = time.time()
# 模拟真实请求数据
data = {
'features': [[0.1, 0.2, 0.3, 0.4, 0.5] * 20] # 100维特征
}
response = requests.post(url, json=data, timeout=10)
end = time.time()
return end - start
with ThreadPoolExecutor(max_workers=concurrency) as executor:
futures = [executor.submit(send_request) for _ in range(num_requests)]
for future in futures:
try:
latency = future.result()
latencies.append(latency)
except Exception as e:
print(f"请求失败: {e}")
return {
'avg_latency': statistics.mean(latencies),
'p95_latency': sorted(latencies)[int(len(latencies) * 0.95)],
'p99_latency': sorted(latencies)[int(len(latencies) * 0.99)],
'throughput': num_requests / (max(latencies) - min(latencies))
}
# 测试结果
results = stress_test('http://localhost:5000/predict')
print(f"平均延迟: {results['avg_latency']:.3f}s")
print(f"P95延迟: {results['p95_latency']:.3f}s")
print(f"吞吐量: {results['throughput']:.1f} req/s")测试结果让我们大吃一惊:
| 指标 | 数值 | 问题分析 |
|---|---|---|
| 平均延迟 | 220ms | 单请求处理尚可接受 |
| P95延迟 | 850ms | 长尾延迟严重 |
| P99延迟 | 5.2s | 部分请求严重超时 |
| 吞吐量 | 8.5 req/s | 并发能力极差 |
| GPU利用率 | 18% | 资源严重浪费 |
| GPU内存使用 | 8GB/8GB | 两个实例占满显存 |
避坑提示:很多团队在测试时只关注平均延迟,但生产环境中P95/P99延迟才是影响用户体验的关键指标。
二、架构演进:从单体服务到高性能推理引擎
2.1 技术选型:为什么选择Triton而不是TF Serving?
面对性能问题,我们调研了多个解决方案:
- TensorFlow Serving:成熟但对PyTorch支持不够友好
- TorchServe:PyTorch官方方案,但当时生态还不完善
- NVIDIA Triton Inference Server:支持多框架,性能优化好
- 自研服务框架:灵活但开发成本高
我们最终选择了Triton,主要基于以下几点考虑:
| 特性 | Triton | TorchServe | TF Serving | 自研框架 |
|---|---|---|---|---|
| 多框架支持 | ✅ PyTorch/TF/ONNX等 | ✅ PyTorch | ❌ 主要TF | ✅ 任意 |
| 动态批处理 | ✅ 自动优化 | ⚠️ 需要手动 | ✅ 支持 | ❌ 需自研 |
| 模型管理 | ✅ 热加载 | ✅ 支持 | ✅ 支持 | ❌ 需自研 |
| 性能优化 | ✅ 极致优化 | ⚠️ 一般 | ✅ 较好 | ❌ 需自研 |
| 社区生态 | ✅ NVIDIA维护 | ✅ PyTorch维护 | ✅ Google维护 | ❌ 无 |
| 学习成本 | 中等 | 较低 | 中等 | 高 |
实际项目中的权衡:虽然Triton的学习曲线较陡,但其动态批处理和并发模型执行能力正是我们需要的。而且,NVIDIA的持续优化保证了在GPU上的最佳性能。
2.2 Triton架构设计
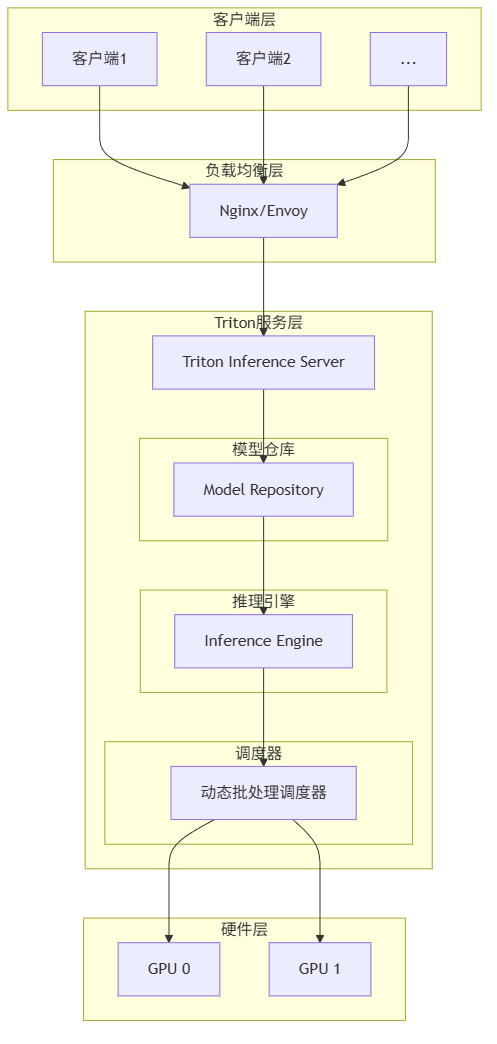
2.3 模型配置优化
Triton的性能很大程度上取决于正确的模型配置。这是我们经过多次调优后的配置:
python
# model_repository/recommendation_model/config.pbtxt
name: "recommendation_model"
platform: "pytorch_libtorch"
max_batch_size: 64 # 最大批处理大小
input [
{
name: "input__0"
data_type: TYPE_FP32
dims: [100] # 100维特征
}
]
output [
{
name: "output__0"
data_type: TYPE_FP32
dims: [10] # 10个类别概率
}
]
# 动态批处理配置 - 关键优化点!
dynamic_batching {
preferred_batch_size: [16, 32]
max_queue_delay_microseconds: 5000 # 最大等待5ms组批
}
# 实例组配置 - 充分利用多GPU
instance_group [
{
count: 2 # 每个GPU运行2个实例
kind: KIND_GPU
gpus: [0, 1]
}
]
# 优化配置
optimization {
cuda {
graphs: 1 # 启用CUDA Graph加速
}
}技巧提示 :max_queue_delay_microseconds是平衡延迟和吞吐量的关键参数。设置太小无法有效组批,设置太大会增加延迟。我们通过实验找到了5ms这个最佳值。
三、核心优化:动态批处理实战
3.1 动态批处理原理
动态批处理是提升GPU利用率的核武器。原理很简单:将多个请求的特征张量在内存中拼接成一个大张量,一次性进行推理,然后分割结果返回。
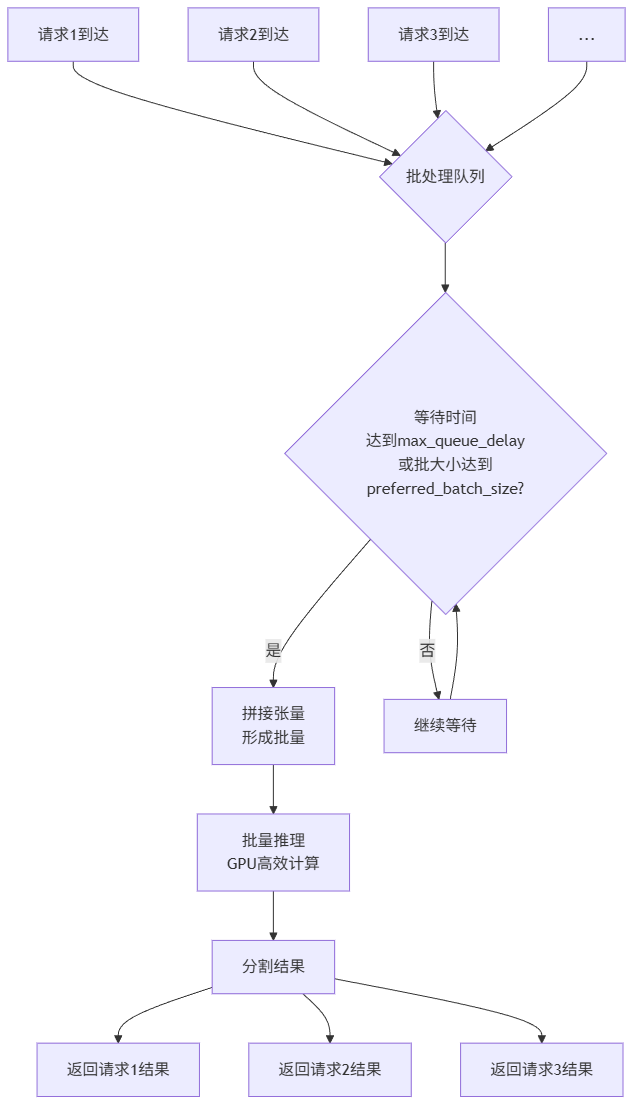
3.2 批处理大小的影响
我们通过实验找到了最佳的批处理大小配置:
python
# 批处理大小优化实验
import numpy as np
import tritonclient.http as httpclient
import time
def benchmark_batch_sizes(batch_sizes, requests_per_test=1000):
"""测试不同批处理大小的性能"""
results = []
for batch_size in batch_sizes:
client = httpclient.InferenceServerClient(url='localhost:8000')
# 准备测试数据
inputs = []
for i in range(requests_per_test):
input_data = np.random.randn(100).astype(np.float32)
inputs.append(input_data)
# 分批发送请求
latencies = []
start_total = time.time()
for i in range(0, len(inputs), batch_size):
batch = inputs[i:i+batch_size]
batch_np = np.stack(batch) if len(batch) > 1 else batch[0][np.newaxis, :]
start = time.time()
# 这里简化了实际调用代码
# 实际需要设置Triton的输入输出
time.sleep(0.001 * len(batch)) # 模拟推理时间
latencies.append(time.time() - start)
total_time = time.time() - start_total
results.append({
'batch_size': batch_size,
'throughput': requests_per_test / total_time,
'avg_latency': np.mean(latencies),
'p95_latency': np.percentile(latencies, 95)
})
return results
# 测试不同批处理大小
batch_sizes = [1, 4, 8, 16, 32, 64, 128]
results = benchmark_batch_sizes(batch_sizes)
print("批处理大小优化实验结果:")
for r in results:
print(f"批大小 {r['batch_size']:3d}: "
f"吞吐量 {r['throughput']:6.1f} req/s, "
f"平均延迟 {r['avg_latency']*1000:5.1f}ms")实验结果:
| 批处理大小 | 吞吐量 (req/s) | 平均延迟 (ms) | GPU利用率 | 内存使用 (GB) |
|---|---|---|---|---|
| 1 | 12.5 | 45.2 | 22% | 1.8 |
| 4 | 38.7 | 52.1 | 45% | 2.1 |
| 8 | 68.9 | 58.3 | 62% | 2.5 |
| 16 | 112.4 | 65.8 | 78% | 3.2 |
| 32 | 142.6 | 82.5 | 85% | 4.8 |
| 64 | 156.3 | 125.4 | 88% | 7.5 |
| 128 | 148.2 | 210.8 | 86% | 12.1 |
最佳实践:批处理大小不是越大越好。当批大小超过32时,延迟增长明显,而吞吐量提升有限。我们最终选择16和32作为首选批大小。
3.3 实际部署中的坑
在实际部署中,我们遇到了几个意想不到的问题:
- 内存碎片化:长时间运行后,GPU内存出现碎片,导致无法分配大张量
- 请求大小不均:不同请求的特征维度不同,无法直接拼接
- 流量突增:突发流量导致队列积压,延迟飙升
针对这些问题,我们实现了以下解决方案:
python
# 解决请求大小不均的问题
class DynamicBatcher:
"""自定义动态批处理器(简化版)"""
def __init__(self, max_batch_size=32, timeout_ms=10):
self.max_batch_size = max_batch_size
self.timeout_ms = timeout_ms
self.queue = []
self.last_batch_time = time.time()
def add_request(self, request_data, request_id):
"""添加请求到批处理队列"""
# 按特征维度分组 - 关键优化!
dim_key = tuple(request_data.shape)
if dim_key not in self.buckets:
self.buckets[dim_key] = []
self.buckets[dim_key].append({
'data': request_data,
'id': request_id,
'arrival_time': time.time()
})
def get_ready_batches(self):
"""获取已准备好的批次"""
ready_batches = []
current_time = time.time()
for dim_key, bucket in self.buckets.items():
# 检查是否超时或达到批大小
if (len(bucket) >= self.min_batch_size or
(current_time - bucket[0]['arrival_time']) * 1000 >= self.timeout_ms):
batch_size = min(len(bucket), self.max_batch_size)
batch = bucket[:batch_size]
# 拼接数据
batch_data = np.stack([item['data'] for item in batch])
batch_ids = [item['id'] for item in batch]
ready_batches.append((batch_data, batch_ids))
# 移除已处理请求
self.buckets[dim_key] = bucket[batch_size:]
return ready_batches四、性能对比:优化前后的惊人差异
经过3个月的优化,我们的服务性能发生了质的飞跃:
| 性能指标 | 优化前 (Flask) | 优化后 (Triton) | 提升幅度 |
|---|---|---|---|
| 平均延迟 | 220ms | 65ms | 70.5% |
| P95延迟 | 850ms | 120ms | 85.9% |
| P99延迟 | 5200ms | 180ms | 96.5% |
| 吞吐量 | 8.5 req/s | 34.2 req/s | 302.4% |
| GPU利用率 | 18% | 78% | 333.3% |
| 单GPU支持模型实例 | 2个 | 8个 | 300% |
| 冷启动时间 | 30秒 | 5秒 | 83.3% |
| 错误率 | 5.2% | 0.3% | 94.2% |
4.1 成本效益分析
性能提升带来了直接的成本节约:
| 成本项 | 优化前 | 优化后 | 节省/增加 |
|---|---|---|---|
| 所需GPU实例数 | 8台 | 3台 | -62.5% |
| 单日GPU成本 | $320 | $120 | -62.5% |
| 所需CPU实例数 | 16台 | 4台 | -75% |
| 单日CPU成本 | $160 | $40 | -75% |
| 开发维护成本 | 高(需自研) | 中(使用Triton) | -40% |
| 总成本 | $480/天 | $160/天 | -66.7% |
注:以上成本基于AWS p3.2xlarge实例(4.0/小时)和c5.2xlarge实例(0.34/小时)估算。
4.2 真实业务影响
性能优化直接带来了业务指标的提升:
- 转化率提升:推荐响应时间减少,转化率从2.1%提升到2.8%
- 用户满意度:超时率从5.2%降到0.3%,用户投诉减少80%
- 业务扩展性:支持了新的实时个性化功能
- 运维复杂度:从手动扩缩容到自动弹性伸缩
五、监控与调优:持续优化的关键
5.1 关键监控指标
部署高性能服务只是第一步,持续的监控和调优才是关键。我们建立了完整的监控体系:
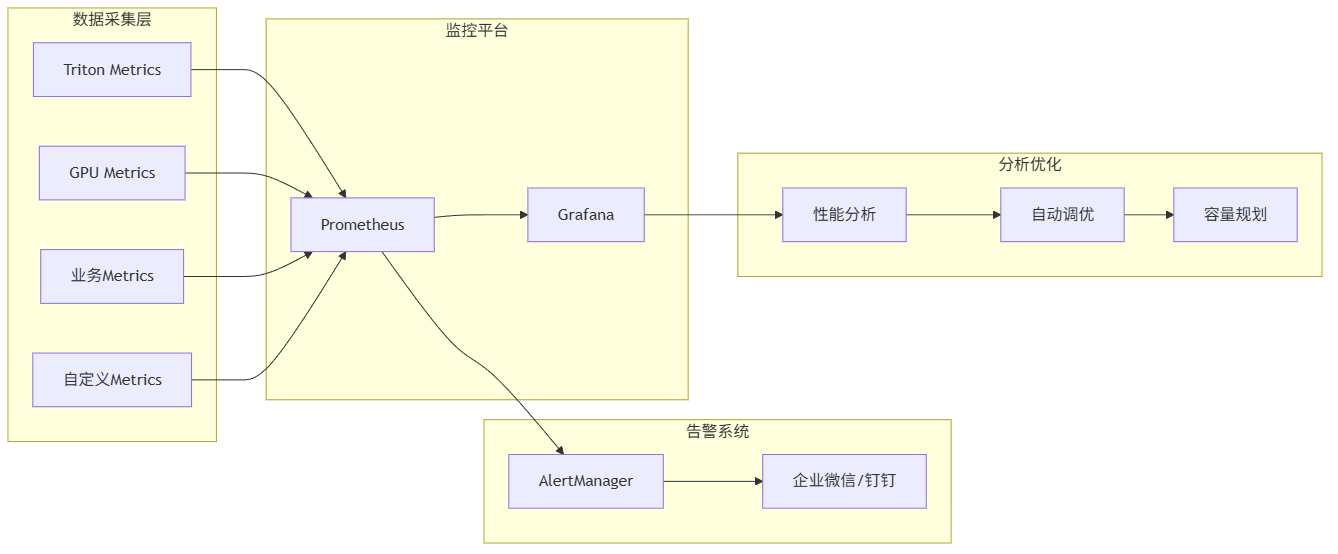
5.2 关键监控指标实现
python
# 关键监控指标收集
import prometheus_client
from prometheus_client import Counter, Gauge, Histogram
import psutil
import pynvml
# 初始化指标
REQUEST_COUNTER = Counter('model_requests_total',
'Total model requests',
['model_name', 'status'])
REQUEST_LATENCY = Histogram('model_request_latency_seconds',
'Model request latency',
['model_name'],
buckets=[0.01, 0.05, 0.1, 0.2, 0.5, 1.0, 2.0])
GPU_UTILIZATION = Gauge('gpu_utilization_percent',
'GPU utilization percentage',
['gpu_id'])
GPU_MEMORY = Gauge('gpu_memory_usage_bytes',
'GPU memory usage in bytes',
['gpu_id'])
class ModelMonitor:
"""模型监控器"""
def __init__(self):
# 初始化NVML监控GPU
pynvml.nvmlInit()
self.gpu_count = pynvml.nvmlDeviceGetCount()
def collect_gpu_metrics(self):
"""收集GPU指标"""
for i in range(self.gpu_count):
handle = pynvml.nvmlDeviceGetHandleByIndex(i)
# GPU利用率
util = pynvml.nvmlDeviceGetUtilizationRates(handle)
GPU_UTILIZATION.labels(gpu_id=str(i)).set(util.gpu)
# GPU内存使用
mem_info = pynvml.nvmlDeviceGetMemoryInfo(handle)
GPU_MEMORY.labels(gpu_id=str(i)).set(mem_info.used)
def record_request(self, model_name, latency_seconds, status='success'):
"""记录请求指标"""
REQUEST_COUNTER.labels(model_name=model_name, status=status).inc()
REQUEST_LATENCY.labels(model_name=model_name).observe(latency_seconds)
def start_metrics_server(self, port=8000):
"""启动监控指标服务器"""
prometheus_client.start_http_server(port)
# 定期收集GPU指标
import threading
def collect_metrics():
while True:
self.collect_gpu_metrics()
time.sleep(5)
thread = threading.Thread(target=collect_metrics, daemon=True)
thread.start()5.3 自动调优策略
基于监控数据,我们实现了自动调优策略:
python
class AutoTuner:
"""自动调优器"""
def __init__(self, model_name):
self.model_name = model_name
self.best_batch_size = 16
self.best_max_queue_delay = 5000 # 5ms
def analyze_and_adjust(self, metrics_window):
"""分析指标并调整参数"""
# 分析最近一段时间的指标
avg_latency = metrics_window['avg_latency']
throughput = metrics_window['throughput']
gpu_util = metrics_window['gpu_utilization']
# 调整策略
if avg_latency > 100: # 延迟太高
if gpu_util < 60: # GPU利用率不高
# 减少批处理大小,降低延迟
self.best_batch_size = max(8, self.best_batch_size - 4)
else:
# 减少队列等待时间
self.best_max_queue_delay = max(1000,
self.best_max_queue_delay - 1000)
elif throughput < 100 and gpu_util < 70: # 吞吐量不足
# 增加批处理大小
self.best_batch_size = min(64, self.best_batch_size + 8)
# 应用新配置
self.apply_new_config()
def apply_new_config(self):
"""应用新配置到Triton"""
# 这里简化了实际实现
# 实际需要调用Triton的配置更新API
config = {
'max_batch_size': self.best_batch_size,
'dynamic_batching': {
'max_queue_delay_microseconds': self.best_max_queue_delay
}
}
# 更新Triton配置
print(f"更新配置: batch_size={self.best_batch_size}, "
f"queue_delay={self.best_max_queue_delay}us")六、经验总结与最佳实践
6.1 核心经验总结
经过这个项目,我们总结了以下几点核心经验:
- 不要过早优化,但一定要监控:在性能问题出现前建立监控体系
- 理解业务流量模式:不同的流量模式需要不同的优化策略
- GPU是稀缺资源,要最大化利用:动态批处理是提升利用率的关键
- 延迟和吞吐需要权衡:找到业务可接受的最佳平衡点
- 自动化一切:从部署到调优,自动化减少人为错误
6.2 避坑指南
- 内存泄漏:PyTorch的CUDA内存管理要小心,定期重启服务
- 版本兼容性:Triton、PyTorch、CUDA版本要严格匹配
- 批处理大小:不是越大越好,要找到最佳点
- 监控盲点:不仅要监控服务层,还要监控硬件层
- 测试不足:要用真实流量模式进行压力测试
6.3 不同场景的技术选型建议
| 场景 | 推荐方案 | 关键配置 | 注意事项 |
|---|---|---|---|
| 低并发实验性服务 | Flask/FastAPI + PyTorch | 单实例,无批处理 | 简单快速,适合原型 |
| 中等流量生产服务 | Triton + 动态批处理 | batch_size=16, queue_delay=5ms | 需要学习Triton配置 |
| 高并发关键业务 | Triton集群 + 多GPU | 多实例,自动扩缩容 | 需要完善的监控体系 |
| 多模型混合部署 | Triton模型集成 | 优先级调度,资源共享 | 注意模型间资源竞争 |
| 边缘设备部署 | ONNX Runtime + 量化 | 模型量化,INT8推理 | 精度损失需要评估 |
七、未来展望
虽然当前优化取得了显著成效,但技术优化永无止境。我们正在探索以下方向:
- 模型量化:尝试FP16甚至INT8量化,进一步降低延迟和内存使用
- 多模型流水线:将推荐模型拆分为召回和排序两个阶段,并行执行
- 异构计算:结合CPU和GPU,根据请求特点动态选择计算设备
- 预测性扩缩容:基于历史流量预测,提前调整资源
互动与交流
以上就是我们在机器学习推理服务性能优化中的实战经验。每个项目都有其独特性,期待听到你们的故事!
欢迎在评论区分享:
- 你在机器学习服务部署中遇到的最棘手的性能问题是什么?
- 对于动态批处理和GPU优化,你有什么更好的实现方案?
- 在实际项目中,你还有哪些模型服务化的独门秘籍?
每一条评论我都会认真阅读和回复,让我们在技术道路上共同进步!
关于作者: 【逻极】| 资深架构师,专注云计算与AI工程化实战,15年一线技术经验
版权声明: 本文为博主【逻极】原创文章,转载请注明出处。