目录
[3.4.1 FastGPT的存储结构](#3.4.1 FastGPT的存储结构)
[3.4.2 知识库搜索模式](#3.4.2 知识库搜索模式)
3.4.1 FastGPT的存储结构
如图3-5所示,在FastGPT中,整个知识库由库、集合和数据三部分组成。集合可以简单理解为一个文件。一个库中可以包含多个集合,一个集合中可以包含多组数据。最小的搜索单位是库,也就是说,知识库搜索时,是对整个库进行搜索,而集合仅是为了对数据进行分类管理,与搜索效果无关。向量就是将人类的语言(文字、图片、视频等)转换为计算机可识别的语言(数组)。计算两个向量之间的相似度,表示两种语言的相似程度。
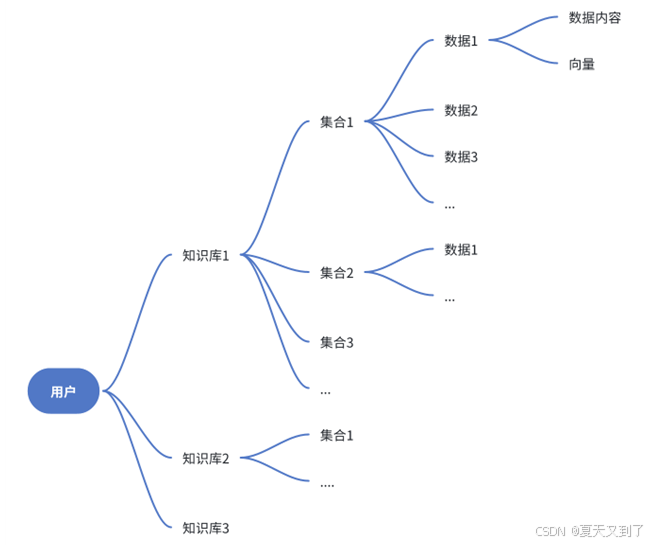 图3-5 FastGPT存储结构
图3-5 FastGPT存储结构
FastGPT默认采用了PostgresSQL的PG Vector插件作为向量检索器,且PostgresSQL仅用于向量检索(该引擎也可以替换成其他数据库,如开源向量数据库Milvus),而MongoDB用于其他数据的存取。在MongoDB的dataset.datas表中,会存储向量原数据的信息,同时有一个indexes字段,记录其对应的向量ID,这是一个数组,也就是说,一组数据可以对应多个向量。在PostgresSQL的表中,设置一个vector字段用于存储向量。在检索时,会先召回向量,再根据向量的ID在MongoDB中寻找原数据内容,如果对应同一组原数据,则进行合并,向量得分取最高得分。
在一组向量中,内容的长度和语义的丰富度通常是矛盾的,无法兼得。因此,FastGPT采用了多向量映射的方式,将一组数据映射到多组向量中,从而保障数据的完整性和语义的丰富度。你可以为一组较长的文本添加多组向量,从而在检索时,只要其中一组向量被检索到,该数据就被召回。这意味着,你可以通过标注数据块的方式,不断提高数据块的精度。
3.4.2 知识库搜索模式
语义检索是通过向量距离计算用户问题与知识库内容的距离,从而得出"相似度"。当然,这并不是语文上的相似度,而是数学上的。它的缺点是依赖模型训练效果,精度不稳定,且受关键词和句子完整度影响。而全文检索是采用传统的全文检索方式,适合查找关键的主谓语等。
通常我们会选择混合检索,即同时使用向量检索和全文检索,并通过RRF公式将两个搜索结果合并,一般情况下搜索结果会更加丰富和准确。RRF(Reciprocal Rank Fusion,倒数排名融合)是一种用于融合多个检索结果列表的算法。它的核心思想是将不同检索方法的排名结果结合起来,生成一个更全面、更准确的最终排名。
混合检索能够结合不同检索技术的优势,以获得更好的召回结果。不过由于混合检索后的查找范围很大,可能无法直接进行相似度过滤,通常需要利用ReRank重排模型进行一次结果重新排序。重排模型通过将候选文档列表与用户问题的语义匹配度进行重新排序,从而改进语义排序的结果。其原理是计算用户问题与给定的每个候选文档之间的相关性分数,并返回按相关性从高到低排序的文档列表。重排后可以得到一个0~1的得分(最低相关度),代表着搜索内容与问题的相关度,该分数通常比向量的得分更加精确,可以根据得分进行过滤。
