摘要
在分布式系统中,缓存的高可用与扩展性是永恒的话题。单机 Redis 再强,也面临着内存上限与单点故障的风险。最近,我在生产环境标准下深度实践了 Redis 7.0 Cluster ,从底层的 Hash Slot 分片原理 ,到开发端的 Redisson 跨 Slot 难题破解 ,再到运维侧的 故障转移(Failover)实测。本文将跳过枯燥的 API 调用,直接复盘 Redis Cluster 架构中最核心、最硬核的知识点。
一、 架构之美:去中心化与 16384 个槽位
与哨兵(Sentinel)模式不同,Redis Cluster 采用的是**无中心化(Decentralized)**架构。这里没有所谓的"代理层",客户端直接与数据节点通信。
1. 数据的归宿:Hash Slot(哈希槽)
很多初学者会问:"在这个集群里,我的 Key 到底存在哪台机器上?"
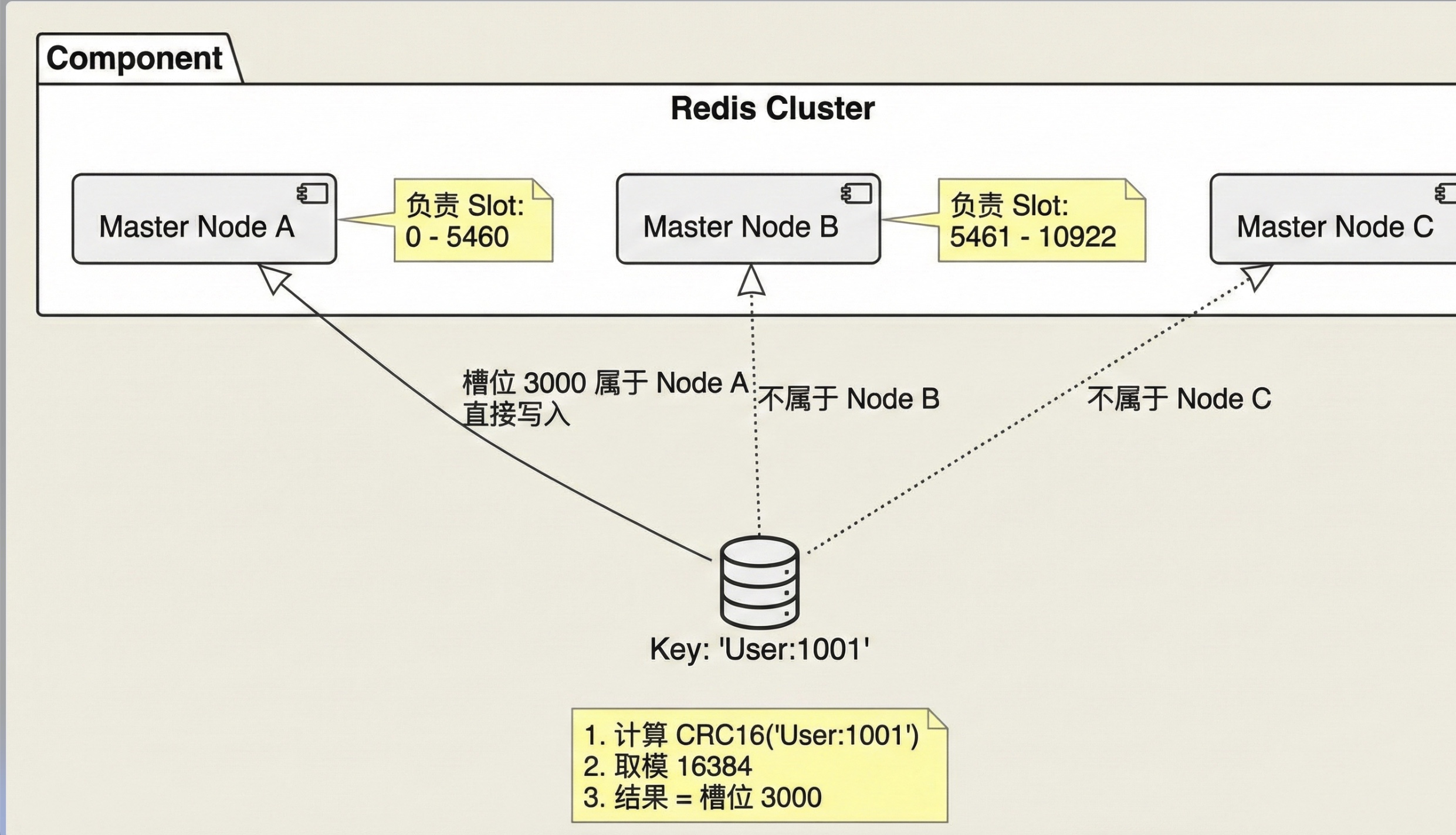
Redis Cluster 没有使用一致性哈希,而是引入了 哈希槽 (Hash Slot) 的概念。整个集群被逻辑上切分为 16384 个槽位。
- 算法 :
CRC16(key) % 16384 - 分布 :假设有 3 个 Master 节点(A, B, C),它们"分赃"如下:
- 节点 A:负责槽位
0 ~ 5460 - 节点 B:负责槽位
5461 ~ 10922 - 节点 C:负责槽位
10923 ~ 16383
- 节点 A:负责槽位
架构原理图 :
2. 节点的八卦:Gossip 协议
集群中的每个节点都与其他节点保持连接,它们通过 Gossip 协议 不断地"说悄悄话"。
- "喂,即使我不负责这个 Key,我也知道 Slot 10000 在节点 B 那里。"
- "喂,节点 C 好像 3 秒没回我消息了,是不是挂了?"
这种机制使得集群状态在网络中快速收敛,也是客户端能够实现 Smart Client(智能路由) 的基础。
二、 编码避坑:Redisson 与 跨 Slot 难题
在 Java 生态中,Redisson 是连接集群的神器。它会在本地缓存一份 Slot -> Node 的映射表,大请求直接打到正确的节点,效率极高。
但是,在集群模式下开发,有一个巨大的坑 :CROSSSLOT 错误。
1. 什么是跨 Slot 问题?
Redis Cluster 规定:涉及多个 Key 的原子操作(如 MGET、MSET、Lua 脚本、事务),所有 Key 必须映射到同一个 Slot 上。
如果你试图在一个 Lua 脚本里同时修改 Order:A 和 Order:B,而它们恰好被分到了不同的机器上,Redis 会直接报错:
(error) CROSSSLOT Keys in request don't hash to the same slot
因为 Redis 无法在跨机器的情况下保证原子性(分布式事务的代价太大)。
2. 解决方案:Hash Tag {...}
为了解决这个问题,Redis 提供了一个"后门":Hash Tag。
如果在 Key 中包含花括号 {},Redis 就只会计算 {} 内部字符串的 Hash 值。
-
普通情况:
Order:1001-> Hash("Order:1001") -> Slot 100Order:1002-> Hash("Order:1002") -> Slot 5000- 结果:跨 Slot,报错。
-
使用 Hash Tag:
{OrderGroup}:1001-> Hash("OrderGroup") -> Slot 888{OrderGroup}:1002-> Hash("OrderGroup") -> Slot 888- 结果 :Slot 一致,操作成功!
实战心得:在设计数据结构时,如果预见到需要原子性批量操作,务必在 Key 的设计上引入 Hash Tag,这能避免后期 90% 的重构工作。

三、 极致体验:亲历故障转移 (Failover)
Redis Cluster 的高可用性(HA)不是嘴上说说的,我通过手动模拟故障,亲眼见证了它的自愈能力。
实验拓扑:3 主 3 从。
- Master-3 负责一部分热点数据。
- Slave-3 是它的备份。
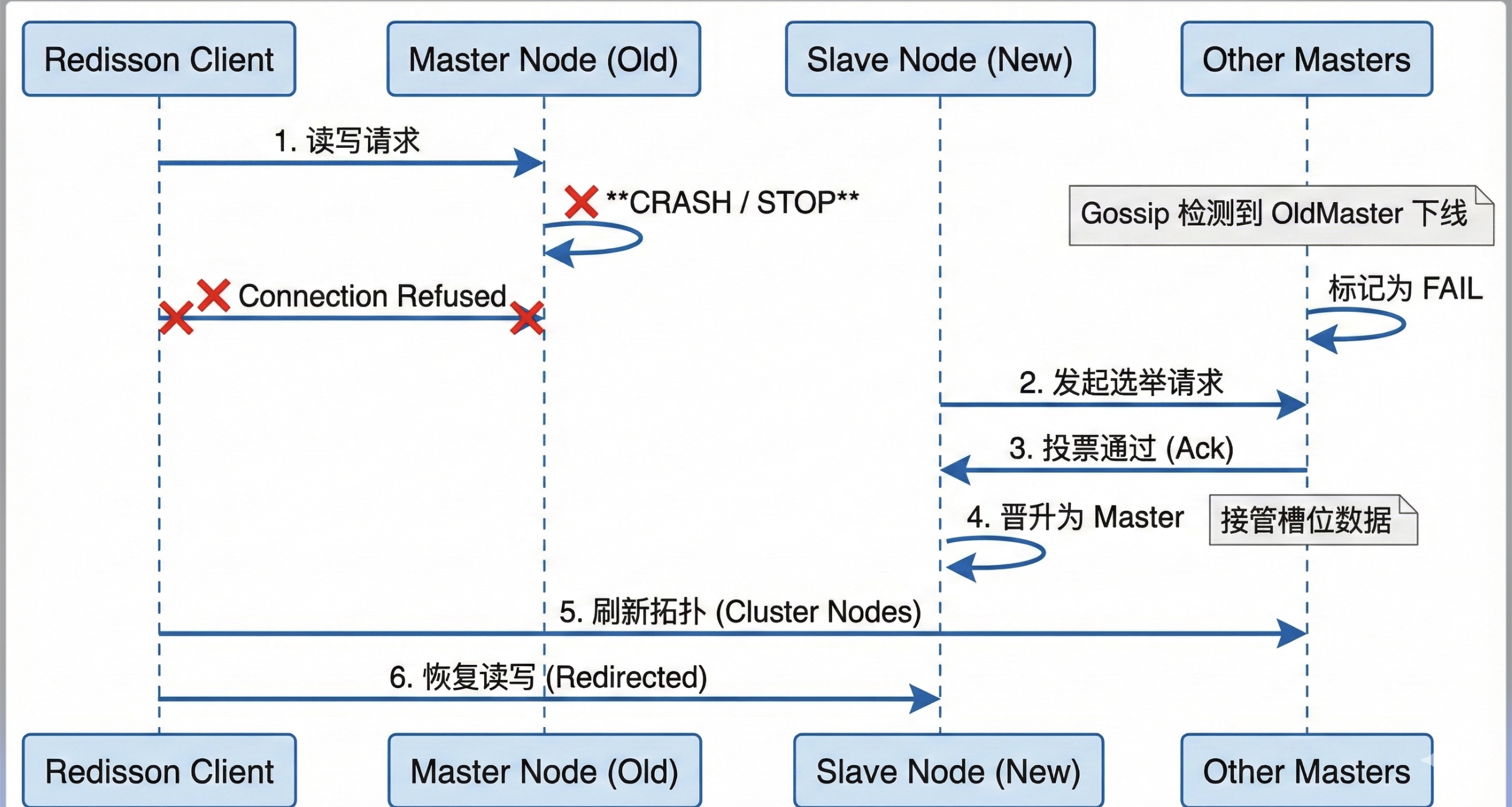
1. 刺杀 Master
我通过运维命令强制停止了 Master-3 容器。此时,集群瞬间失去了一部分槽位的服务能力。
2. 故障判定 (PFAIL -> FAIL)
剩下的 Master 节点通过 Gossip 协议发现:"哎?Master-3 怎么失联了?"
当超过半数的 Master 都认为 Master-3 挂了,它就被标记为 FAIL。
3. 选举与晋升 (Election)
Master-3 的"遗孤" Slave-3 发现主节点挂了,立刻发起选举请求。
其他 Master 投票同意:"好,你行你上。"
Slave-3 晋升为新的 Master,并接管了原本属于 Master-3 的槽位。
4. 客户端自适应
最神奇的是 Redisson 客户端的表现。在短暂的连接报错(毫秒级)后,它迅速收到了集群拓扑变更的通知,自动将后续请求重定向到了新的 Master。整个过程对上层业务几乎无感。
故障转移时序图:
四、 总结与思考
通过这次对 Redis Cluster 的系统性实战,我最大的感悟是:
- 原理决定上限 :不理解 Hash Slot,就永远搞不懂为什么
keys *查不到数据,为什么批量操作会报错。 - 工具选型很重要:Redisson 封装了大量底层细节(如自动重连、拓扑刷新),是 Java 开发者连接集群的首选。
- 高可用是设计出来的:3 主 3 从不仅仅是 6 台机器,更是对 CAP 理论中 Partition Tolerance(分区容错性)的最佳实践。
掌握这些,才算是真正跨过了 Redis 从"入门"到"精通"的分水岭。