引言
在数字化浪潮席卷全球的今天,我们使用的每一个互联网应用背后,都隐藏着一套复杂的系统架构。从最初的单机服务器到如今的微服务云原生架构,分布式系统的演进之路如同一部技术进化史。本文将带您深入探索这一演进过程,揭示每个阶段背后的设计哲学与技术突破。
一、起点:单机架构的简单与局限
1.1 单机时代的架构模型
用户请求 单机服务器 应用程序 数据库 用户表 商品表 交易表
在互联网的早期阶段,单机架构是大多数应用的标准配置。这种架构将所有的组件------Web服务器、应用程序、数据库------都部署在同一台物理服务器上。
技术特点:
- 所有服务进程共享同一操作系统和硬件资源
- 数据存储使用本地文件系统或单实例数据库
- 开发简单,部署容易,维护成本低
1.2 单机架构的核心挑战
性能瓶颈日益凸显:
用户增长 请求量增加 CPU/内存过载 响应时间变慢 用户体验下降 业务损失
数据共享的天然缺陷:
- 内存变量仅限单进程访问
- 多进程间数据同步困难
- 服务器重启导致数据丢失风险
二、演进第一步:服务分离
2.1 应用与数据库分离
随着业务发展,第一个重要的架构决策是将应用服务与数据库服务分离。
架构演进:分离关注点 分离前 分离后 网络通信 应用服务器 数据库服务器 用户表 商品表 订单表 应用代码 单机服务器 数据库
分离带来的优势:
- 独立扩展:应用和数据库可按需独立扩容
- 故障隔离:数据库问题不影响应用服务运行
- 技术解耦:可选择不同的技术栈优化各自服务
三、应对流量:负载均衡的引入
3.1 负载均衡架构设计
当单台应用服务器无法承受用户增长时,负载均衡 成为关键解决方案。
负载均衡承担的分配工作,一般来说远低于业务带来的压力,所以负载均衡能够承担更多的请求,毕竟不用处理实际业务。
负载均衡算法 轮询算法 负载均衡器 加权轮询 最少连接数 IP哈希 用户请求 应用服务器1 应用服务器2 应用服务器3 数据库服务器
3.2 负载均衡技术实现
Nginx配置示例:
nginx
upstream backend_servers {
# 加权轮询配置
server 192.168.1.101:8080 weight=3; # 性能较好,权重高
server 192.168.1.102:8080 weight=2;
server 192.168.1.103:8080 weight=1; # 性能一般,权重低
# 健康检查
check interval=3000 rise=2 fall=3 timeout=1000;
}
server {
listen 80;
server_name example.com;
location / {
proxy_pass http://backend_servers;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
}3.3 流量分发策略对比
| 策略类型 | 工作原理 | 适用场景 | 优缺点 |
|---|---|---|---|
| 轮询(Round Robin) | 按顺序分配请求 | 服务器性能相近 | 简单公平,但忽略服务器负载 |
| 加权轮询(Weighted RR) | 按权重比例分配 | 服务器性能差异大 | 考虑性能差异,更合理 |
| 最少连接(Least Connections) | 选择连接数最少的服务器 | 长连接应用 | 动态均衡,但需实时监控 |
| IP哈希(IP Hash) | 按客户端IP哈希分配 | 需要会话保持 | 保证同一用户访问同一服务器 |
四、数据层优化:读写分离与缓存
4.1 数据库读写分离/主从分离架构
数据库如果性能还是不够,就可以将数据库的读写操作分离开,放到不同服务器上,读服务器、写服务器等,当然,要做好数据的同步,
一般来说读操作肯定是比写操作要多的,可以给读操作多分配一些服务器资源。
也就是写数据库作为主库,读数据库作为从库,主从分离了。
应用层路由 读操作集群 写操作集群 写操作 应用程序 读操作 读负载均衡器 从数据库 Slave 1 从数据库 Slave 2 从数据库 Slave 3 主数据库 Master 写请求 数据同步
4.2 缓存架构设计
现实中大部分的访问是符合"二八原则"的,大部分的高频访问的数据仅占20%的数据,
可以把访问频率高的热数据提取出来,备份到缓存中,当访问数据的时候,先从缓存服务器获取,
如果缓存服务器没有,就从读数据库中获取数据,替换到缓存服务器中。
缓存策略 是 否 热点数据预加载 缓存预热 LRU/LFU算法 缓存淘汰 布隆过滤器 缓存穿透 随机过期时间 缓存雪崩 客户端请求 缓存命中? 返回缓存数据 查询数据库 写入缓存
Redis缓存实践:
python
class CacheService:
def __init__(self):
self.redis = redis.Redis(host='redis', port=6379)
self.local_cache = {} # 本地二级缓存
def get_user(self, user_id):
# 1. 检查本地缓存
if user_id in self.local_cache:
return self.local_cache[user_id]
cache_key = f"user:{user_id}"
# 2. 检查Redis缓存
cached_data = self.redis.get(cache_key)
if cached_data:
user = json.loads(cached_data)
self.local_cache[user_id] = user
return user
# 3. 查询数据库
user = db.query_user(user_id)
# 4. 写入缓存(设置随机过期时间防雪崩)
import random
expire_time = 3600 + random.randint(0, 300) # 1小时±5分钟
self.redis.setex(cache_key, expire_time, json.dumps(user))
self.local_cache[user_id] = user
return user五、海量数据:分库分表策略
5.1 分库分表架构设计
当数据量太大了,数据库就会爆炸,数据太多了,查询起来就很慢(即使加了索引),
此时就可以分库分表。
也就是说把整个数据库给拆分开了,
每一个database或者一部分database都可以单独放到一台数据库服务器上,一台服务器,就负责这一个database,这样一台服务器能存储的数据就更多了。
同样的,表也可以拆分开,
每个数据库服务器,存储一张大表的一部分。不同的服务器union合并就是完整的一张表了。
水平分库 订单库1
用户ID尾数1-3 订单数据库集群 订单库2
用户ID尾数4-6 订单库3
用户ID尾数7-9 订单库4
用户ID尾数0
垂直分表 用户基本信息表 用户数据库 用户扩展信息表 用户行为日志表
分片策略 对分片键取模 哈希分片 按时间范围划分 范围分片 按地区划分 地理位置分片
5.2 分库分表挑战与解决方案
| 挑战 | 问题描述 | 解决方案 |
|---|---|---|
| 跨库查询 | 需要聚合多个库的数据 | 1. 建立全局索引表 2. 使用中间件聚合 3. 业务上避免跨库查询 |
| 分布式事务 | 多库操作需要事务一致性 | 1. 2PC/3PC协议 2. TCC模式 3. Saga模式 4. 最终一致性 |
| 数据迁移 | 已有数据需要重新分片 | 1. 双写方案 2. 数据同步工具 3. 灰度迁移 |
| 主键生成 | 需要全局唯一ID | 1. Snowflake算法 2. UUID 3. 数据库序列 |
六、终极形态:微服务架构
一个服务器的业务可能太复杂、太庞大了,
为了方便代码的维护,就可以把这样的服务器,拆分成一些功能更单一的、更轻量的服务器,
这就是微服务。
但是微服务也是有缺点的:
1、不同的子服务之间需要相互通信,这个通信是有性能消耗的。
2、同时系统的复杂度更高了,出现问题的概率就更大了。
微服务的优点:
1、解决了服务器过于复杂、难以开发和维护的问题,
2、同时子服务可以更方便的重用,
3、并且不同的子服务可以进行不同的部署。
6.1 微服务架构全景
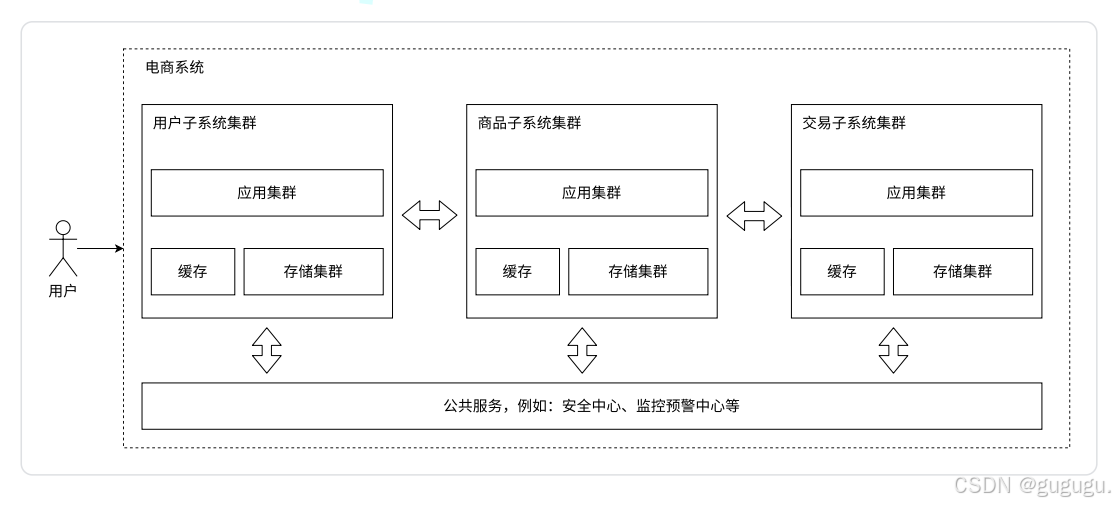
6.2 微服务通信模式
同步调用(REST/gRPC):
java
// Feign客户端示例
@FeignClient(name = "user-service")
public interface UserServiceClient {
@GetMapping("/users/{id}")
User getUserById(@PathVariable("id") Long id);
@PostMapping("/users")
User createUser(@RequestBody UserCreateRequest request);
}异步通信(消息队列):
python
# 订单创建后发送消息
class OrderService:
def create_order(self, order_data):
# 1. 创建订单
order = Order.create(**order_data)
# 2. 发送异步消息
message = {
'event_type': 'ORDER_CREATED',
'order_id': order.id,
'user_id': order.user_id,
'amount': order.amount,
'timestamp': datetime.now().isoformat()
}
# 发送到消息队列
self.rabbitmq_channel.basic_publish(
exchange='order_events',
routing_key='order.created',
body=json.dumps(message)
)
return order6.3 微服务治理体系
| 治理维度 | 核心组件 | 功能描述 |
|---|---|---|
| 服务发现 | Nacos, Eureka, Consul | 自动注册发现服务实例 |
| 配置管理 | Apollo, Nacos Config | 集中化配置管理,动态更新 |
| 流量治理 | Sentinel, Hystrix | 限流、熔断、降级保护 |
| 服务网关 | Spring Cloud Gateway | 统一入口,路由转发 |
| 链路追踪 | SkyWalking, Zipkin | 分布式调用链追踪 |
| 监控告警 | Prometheus, Grafana | 指标监控,异常告警 |
七、架构演进的核心指标
7.1 性能指标体系
架构演进目标 性能指标 可用性指标 扩展性指标 响应时间 RT 吞吐量 TPS/QPS 并发用户数 系统可用性 故障恢复时间 数据一致性 水平扩展能力 垂直扩展能力 弹性伸缩
八、演进路线总结
8.1 技术演进全景图
单机时代 (1990-2000)
├── 特点:All in One
├── 技术:LAMP栈
└── 局限:单点故障,扩展困难
Web 2.0时代 (2000-2010)
├── 演进:前后端分离
├── 技术:负载均衡,读写分离
└── 突破:水平扩展成为可能
云计算时代 (2010-2015)
├── 演进:服务化架构
├── 技术:SOA,分布式缓存
└── 突破:弹性伸缩能力
微服务时代 (2015-2020)
├── 演进:功能解耦
├── 技术:容器化,服务网格
└── 突破:独立部署,快速迭代
云原生时代 (2020至今)
├── 演进:基础设施即代码
├── 技术:K8s,Serverless
└── 突破:极致弹性,成本优化8.2 架构选择决策树
小型项目
<1000用户 中型项目
1000-10万用户 大型项目
10万-1000万用户 超大型项目
>1000万用户 是 否 开始新项目 预估用户规模 单机架构 分离架构+缓存 分布式架构 微服务架构 快速上线
成本最低 易于维护
适度扩展 高性能
高可用 极致扩展
团队协作 成功发展? 按需演进至下一阶段 保持当前架构优化
结语:架构演进的本质
分布式架构的演进不是技术的盲目堆砌,而是业务需求、技术可行性和成本效益三者之间的平衡艺术。每一个架构决策都应回答以下问题:
- 业务真的需要吗? - 避免过度设计
- 技术能支持吗? - 考虑团队技术栈
- 成本合理吗? - 评估开发维护成本
- 未来可演进吗? - 保留架构灵活性
没有最好的架构,只有最适合当前业务阶段的架构。架构设计是一个持续演进的过程,需要根据业务发展不断调整优化。在这个过程中,保持简单、保持灵活、保持可扩展,才是真正的智慧。
架构之路,始于需求,精于权衡,成于实践。愿每位技术人在架构演进的道路上,既能仰望星空,又能脚踏实地。