论文:https://arxiv.org/pdf/2508.20722
代码:rStar
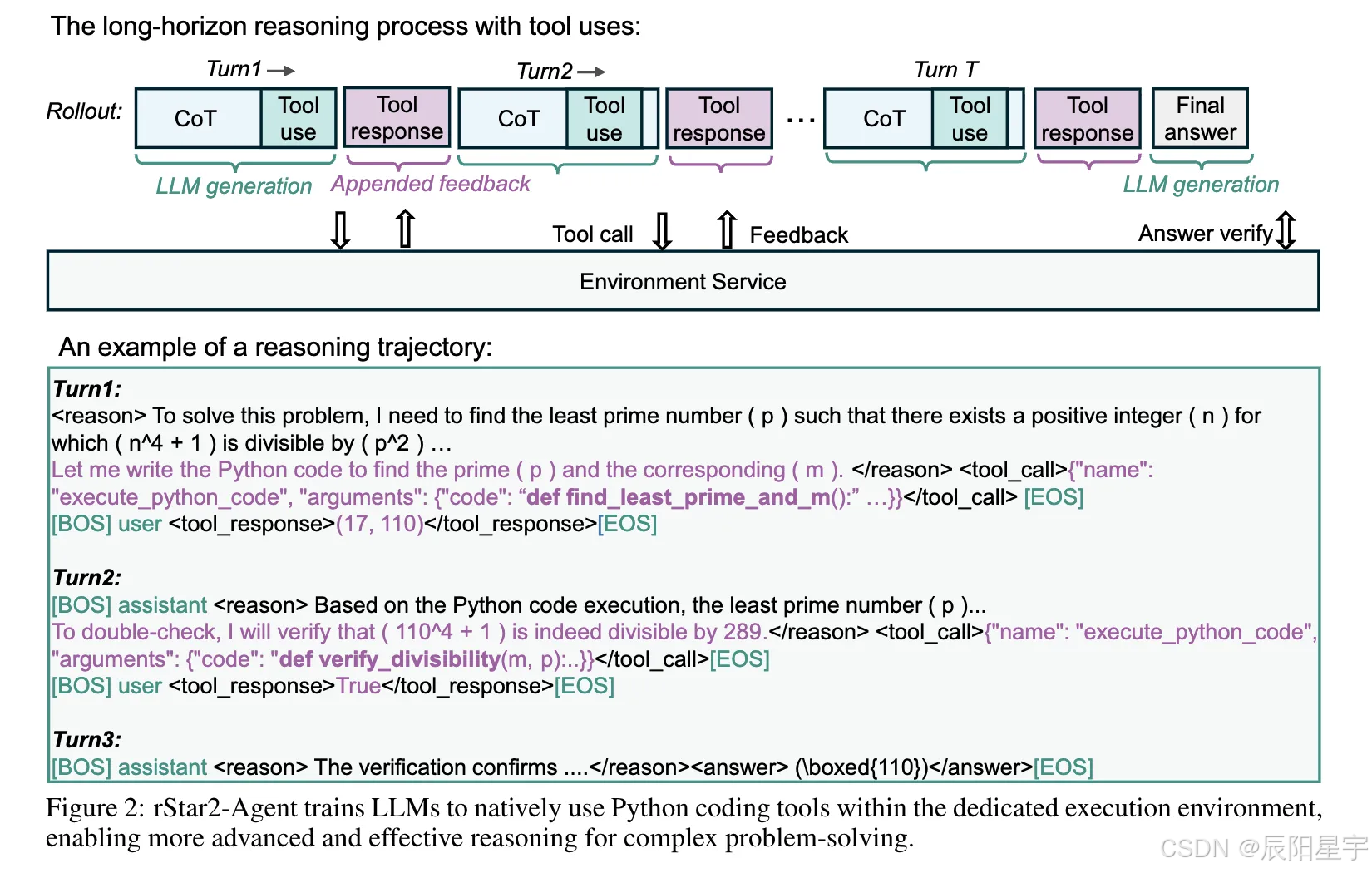
简介:rStar2-Agent 是微软研究院推出的 14B 数学推理模型,通过智能体强化学习(agentic RL)实现前沿性能,核心是让模型 "更智能思考" 而非仅 "更长思考"。
其关键创新包括三点:一是高效 RL 基础设施,支持 45K 并发 Python 工具调用,平均延迟 0.3 秒,搭配负载均衡调度器提升 GPU 利用率;二是 GRPO-RoC 算法,通过 "正确轨迹重采样" 策略过滤代码环境噪声,解决仅结果奖励导致的低质量推理问题;三是高效训练方案,以 "非推理 SFT(仅培养工具使用和指令遵循)+ 三阶段 RL(8K→12K→12K 长度逐步提升)" 推进,仅用 64 块 MI300X GPU、510 个 RL 步骤、1 周完成训练。
性能上,该模型在 AIME24(80.6%)、AIME25(69.8%)等数学基准上超越 671B 的 DeepSeek-R1,且响应更短(AIME25 平均 10943.4 token);同时泛化能力突出,在科学推理(GPQA-Diamond 60.9%)、工具使用(BFCL v3 60.8%)等任务上表现优异。
分析显示,模型通过 "分支探索 token" 和 "工具反馈反思 token" 实现类人推理,且证明了小模型结合精准 RL 设计,可在有限资源下超越大模型性能。
1. 一段话总结
Microsoft Research提出rStar2-Agent ,这是一个基于14B预训练模型、通过智能体强化学习(agentic RL) 训练的数学推理模型,核心创新包括GRPO-RoC算法 (结合重采样策略解决代码环境噪声问题)、支持45K并发工具调用且平均延迟0.3秒的大规模RL基础设施 ,以及"非推理SFT+多阶段RL"的高效训练方案(仅用64块MI300X GPU、510个RL步骤、1周完成训练)。该模型在数学推理任务上表现卓越,AIME24 pass@1达80.6%、AIME25达69.8%,超越671B的DeepSeek-R1且响应更短,同时在科学推理(GPQA-Diamond)、工具使用(BFCL v3)等任务上展现出强泛化能力。
2. 思维导图(mindmap)
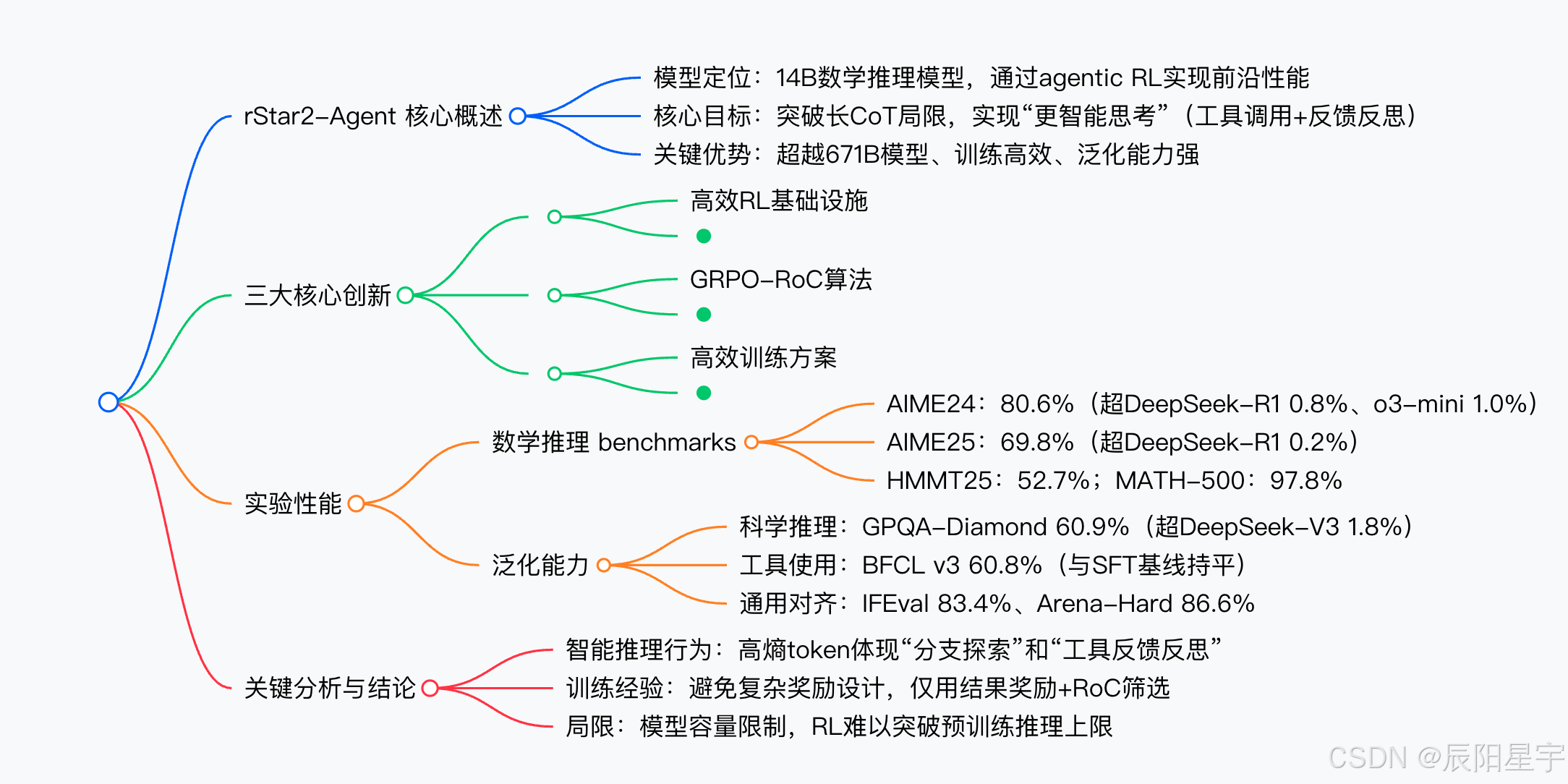
3. 详细总结
一、研究背景与目标
- 长CoT的局限性:当前领先模型(如OpenAI o系列、DeepSeek-R1)依赖"更长思考链(长CoT)"提升推理性能,但面对复杂问题时,易因中间错误或推理思路偏差失效,且内部自反思难以检测/修正错误。
- 核心目标 :通过智能体强化学习(agentic RL) 让模型"思考更智能"------自主使用Python工具验证中间步骤、利用环境反馈优化推理,而非仅"思考更长"。
- 技术挑战 :
- 代码环境噪声:模型生成的错误代码会导致反馈干扰,浪费token修正错误而非推进推理;
- 基础设施压力:大规模RL需处理数万并发工具调用,传统静态调度导致GPU idle率高;
- 训练效率:需在有限计算资源下实现高性能(避免依赖超大规模模型或超长训练周期)。
二、三大核心技术创新
1. 大规模Agentic RL基础设施
- 高可靠高吞吐代码环境 :
- 架构:分布式设计,主节点含32个发送worker和任务队列,工作节点含1024个执行worker;
- 性能:支持45K并发工具调用/训练步骤 ,平均执行延迟仅0.3秒(含调度+执行);
- 额外功能:将答案验证(CPU密集型)卸载至环境服务,避免阻塞训练。
- 负载均衡rollout调度器 :
- 解决问题:传统静态分配导致的KV缓存溢出、GPU负载不均、同步延迟;
- 策略:基于各GPU的实时KV缓存容量动态分配rollout任务,工具调用异步调度,最大化GPU利用率。
2. GRPO-RoC算法(智能体RL核心)
- 基础:GRPO算法 :
- 目标:通过分组rollout(每组G个轨迹)优化策略,奖励仅基于最终答案正确性(0/1二元奖励,避免奖励黑客);
- 改进:移除KL惩罚(释放探索空间)、采用Clip-Higher(ε_high从0.2提至0.28,鼓励高熵token探索)、删除熵损失(避免训练不稳定)。
- 关键优化:Resample-on-Correct(RoC) :
- 流程:先超采样2G个轨迹,再筛选至G个用于训练;
- 正轨迹(奖励=1):按"工具错误率(p_err)+格式违规率(p_format)"评分,优先保留低 penalty 轨迹;
- 负轨迹(奖励=0):均匀下采样,保留多样失败模式;
- 效果:降低正轨迹中工具错误率(Qwen3-14B从10%持续下降),提升推理效率且避免奖励黑客。
- 流程:先超采样2G个轨迹,再筛选至G个用于训练;
3. 高效训练方案
-
阶段1:非推理SFT(冷启动):
- 数据:165K函数调用数据(ToolACE、APIGen-MT等)+30K指令遵循数据(Tulu3)+27K对话数据(LLaMA-Nemontron);
- 目标:仅培养指令遵循、JSON格式工具调用能力,不增强推理(避免SFT过拟合,保留预训练能力);
- 效果:工具使用(BFCL v3)从0→63.1%,数学推理能力与基础模型持平(AIME24 3.33%)。
-
阶段2:多阶段RL训练:
-
训练参数:学习率1e-6,批次大小512,每组超采样32个轨迹(RoC筛选至16个);
-
三阶段设计:
阶段 最大响应长度 训练数据 核心目标 关键成果 1 8K 42K高质量数学题(整数答案) 基础推理能力培养 AIME24从3.33%→72.1%,AIME25从0→64.2% 2 12K 同阶段1 突破长度限制,提升性能 AIME24→77.0%,AIME25→64.8% 3 12K 17.3K难题(过滤8次全对的简单题) 攻克高难度任务 AIME24→80.6%,AIME25→69.8% -
训练成本:仅用64块MI300X GPU ,共510个RL步骤,1周内完成训练。
-
三、实验结果与泛化能力
1. 数学推理性能(核心benchmark)
| 模型 | 模型规模 | 是否推理SFT | MATH-500 | AIME24 | AIME25 | HMMT25 |
|---|---|---|---|---|---|---|
| OpenAI o3-mini (medium) | - | - | 98.0 | 79.6 | 77.0 | 53.0 |
| DeepSeek-R1 | 671B | ✓ | 97.3 | 79.8 | 70.0 | 44.4 |
| Claude-Opus-4.0 (Think) | - | ✓ | 98.2 | 76.0 | 69.2 | - |
| rStar2-Agent-14B | 14B | ✗ | 97.8 | 80.6 | 69.8 | 52.7 |
- 关键结论:rStar2-Agent-14B在14B规模下,超越671B的DeepSeek-R1,且响应长度更短(AIME25平均10943.4 token,远低于DeepSeek-R1-Zero的17132.9 token)。
2. 泛化能力(跨领域任务)
| 任务类型 | benchmark | rStar2-Agent-14B(SFT后) | rStar2-Agent-14B(RL后) | DeepSeek-V3 |
|---|---|---|---|---|
| 科学推理 | GPQA-Diamond | 42.1% | 60.9% | 59.1% |
| 智能体工具使用 | BFCL v3 | 63.1% | 60.8% | 57.6% |
| 通用对齐 | IFEval (strict) | 83.7% | 83.4% | 86.1% |
| 通用对齐 | Arena-Hard | 86.8% | 86.6% | 85.5% |
- 关键结论:仅通过数学RL训练,模型在科学推理上超越DeepSeek-V3,工具使用和通用对齐能力保持与基线持平,证明泛化性强。
四、关键分析与结论
- 智能推理行为 :高熵token主要集中在两类------
- 分支探索token:如"check""But before""double-check",触发自反思;
- 工具反馈反思token:如分析代码执行结果、修正代码错误(如Fig.11中处理"GeneratorsNeeded"错误),体现类人推理。
- 训练经验教训 :
- 避免"过长过滤":丢弃截断轨迹会导致模型重复生成超长内容,保留截断轨迹并赋予负奖励更有效;
- 避免复杂奖励:n-gram重复检测会误判合法推理(如重复工具调用验证结果),仅用"结果奖励+RoC筛选"更稳健。
- 局限性:当模型达到预训练的推理容量上限后,继续RL训练会导致性能崩溃(尝试调整温度、长度等无效),证明RL难以突破基础模型的固有推理能力。
问题1:rStar2-Agent通过哪些设计实现"训练高效性"?相比传统RL方案,其在计算资源和训练周期上有何优势?
答案:rStar2-Agent的高效训练源于三大设计,优势显著:
- 非推理SFT冷启动:仅训练"指令遵循+工具调用格式",不引入推理数据,避免SFT过拟合,且初始响应短(约1K token),减少RL计算量;
- 多阶段RL长度控制:采用8K→12K→12K的逐步加长策略,而非传统方案的16K+固定长度,降低单步训练成本;
- GRPO-RoC算法+高效基础设施:RoC筛选高质量轨迹,减少无效训练;基础设施支持45K并发工具调用(0.3秒延迟)和动态负载调度,提升GPU利用率。
优势对比 :传统方案(如DeepSeek-R1、MiMo)需超大规模模型(671B)或超长训练步骤(>4K步),而rStar2-Agent仅用64块MI300X GPU、510个RL步骤、1周完成训练,14B规模超越671B模型性能。
问题2:GRPO-RoC算法如何解决"代码环境噪声"和"仅结果奖励导致的低质量轨迹"问题?其核心逻辑与传统RL方法有何不同?
答案:
- 解决代码环境噪声:代码环境中,模型可能生成语法/逻辑错误代码,错误反馈会干扰推理。GRPO-RoC通过"RoC重采样"筛选正轨迹------计算每个正轨迹的"工具错误率(p_err)"和"格式违规率(p_format)",优先保留低penalty的高质量轨迹,减少错误代码对训练的干扰;
- 解决仅结果奖励的缺陷:仅基于最终答案的奖励(0/1)会导致"中间步骤错误但最终答案正确"的轨迹被奖励,强化低质量推理。GRPO-RoC通过"超采样2G轨迹+筛选G轨迹",对正轨迹精准筛选(保留少错误、格式正确的),对负轨迹均匀采样(保留多样失败模式),确保训练信号高质量。
与传统RL的差异:传统RL(如GRPO、DAPO)要么直接使用所有rollout轨迹(包含大量低质量正轨迹),要么引入复杂步骤奖励(如工具错误 penalty,易导致奖励黑客);GRPO-RoC仅用"结果奖励+RoC筛选",既避免复杂设计,又解决环境噪声和低质量轨迹问题。
问题3:rStar2-Agent在数学推理之外的泛化能力如何?这种泛化性背后的原因是什么?对未来推理模型训练有何启示?
答案:
-
泛化能力表现:仅通过数学RL训练,模型在跨领域任务上表现优异------
- 科学推理(GPQA-Diamond):从SFT后的42.1%提升至60.9%,超越DeepSeek-V3(59.1%);
- 工具使用(BFCL v3):保持60.8%,与SFT基线(63.1%)接近,且优于DeepSeek-V3(57.6%);
- 通用对齐(IFEval/Arena-Hard):维持83.4%/86.6%,与SFT基线基本持平。
-
泛化原因:
- 核心推理能力迁移:数学推理所需的"逻辑拆解、工具验证、反馈反思"能力,是科学推理、工具使用的通用基础;
- 无偏训练信号:仅用"结果奖励+RoC筛选",未引入数学领域特定偏见,模型学到的是通用推理策略,而非领域特定技巧。
-
对未来的启示:
- 无需为每个领域单独训练:通过"核心领域(如数学)的agentic RL"培养通用推理能力,可迁移至其他领域;
- 高效训练路径:小模型(14B)+ 精准RL设计(如GRPO-RoC),可在有限资源下实现超越大模型的性能,降低推理模型的训练成本。