目录
1 为什么要有集合
数组的长度不可变
集合的长度可变,添加元素后会自动扩容
集合存储数据类型的特点
数组可以存储引用数据类型,也可以存储基本数据类型
但是集合只能存储引用数据类型,如果想要存储基本数据类型,需要将其变成对应的包装类
创建集合的对象
java
在JDK7的写法:
ArrayList<String> arrayList = new ArrayList<String>();
JDK7后的写法:
后面的数据类型可以省略,但是<>需要保留
ArrayList<String> arrayList = new ArrayList<>();此时我们创建的是ArrayList的对象,而ArrayList是java已经写好的一个类,这个类在底层做了一些处理,打印对象不是地址值,而是集合中存储数据的内容,在展示的时候会拿[]把所有的数据进行包裹
2 集合体系结构
集合分为单列集合和双列集合
Collection和Map
单列集合:每次只能添加一个数据
双列集合:每次添加一对数据
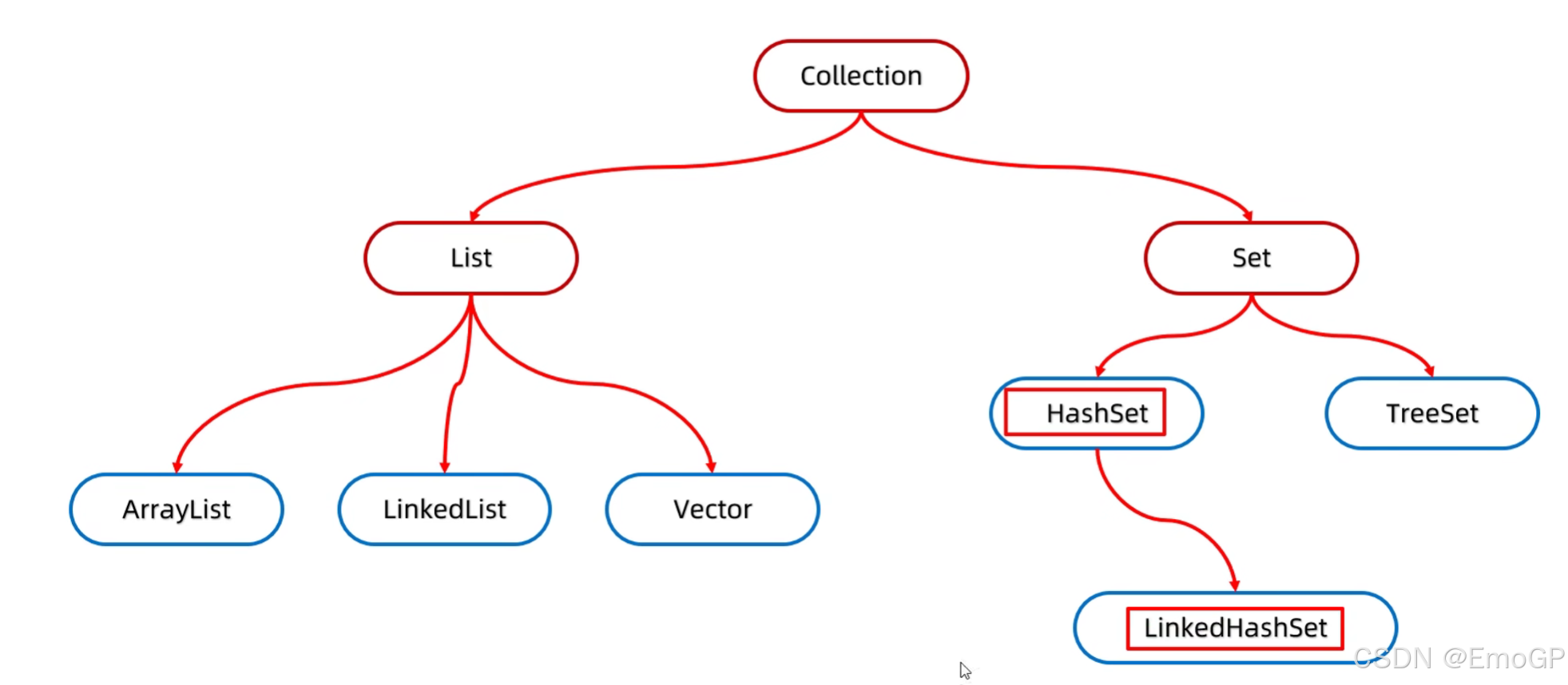
其中红框是接口,蓝框是实现类
Vector在1.2版本时已经被市场淘汰
List系列集合:添加的元素是有序,可重复,有索引
(有序:存和取的顺序一致)
Set系列集合:添加的元素是无序、不重复、无索引
(无序:存和取的顺序可能不一致)
Collection是单列集合的祖宗接口,它的功能是全部单列集合都可以继承使用的
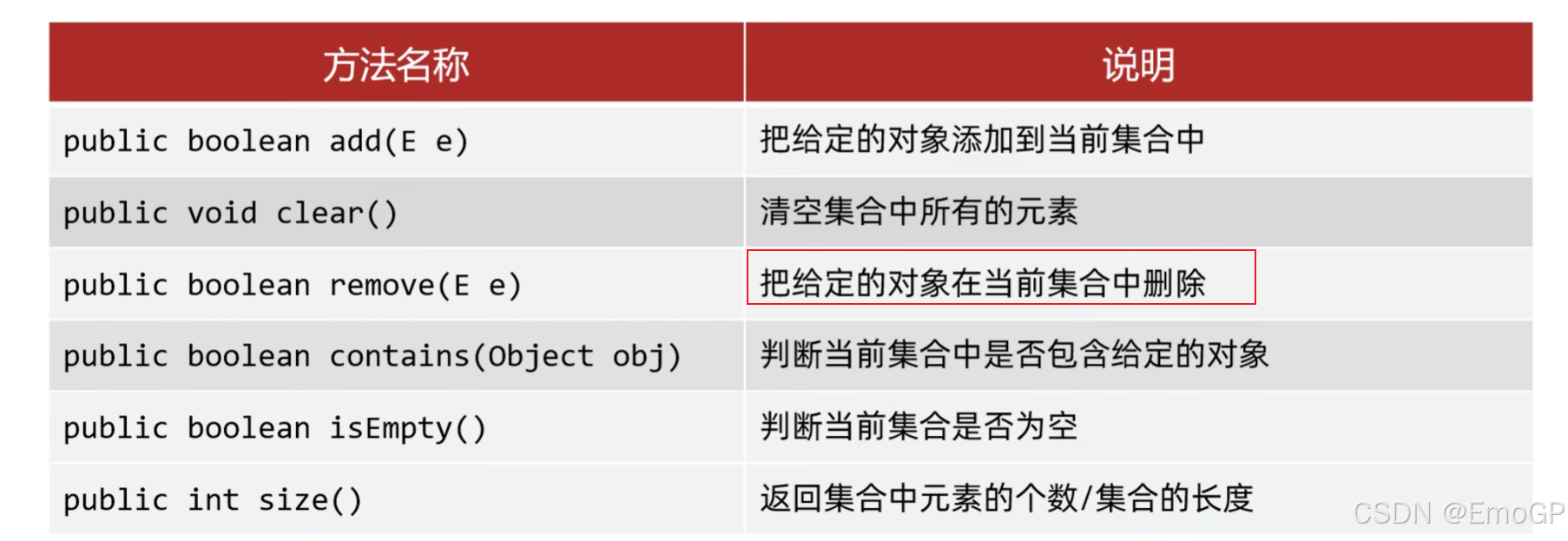
常见方法如下:
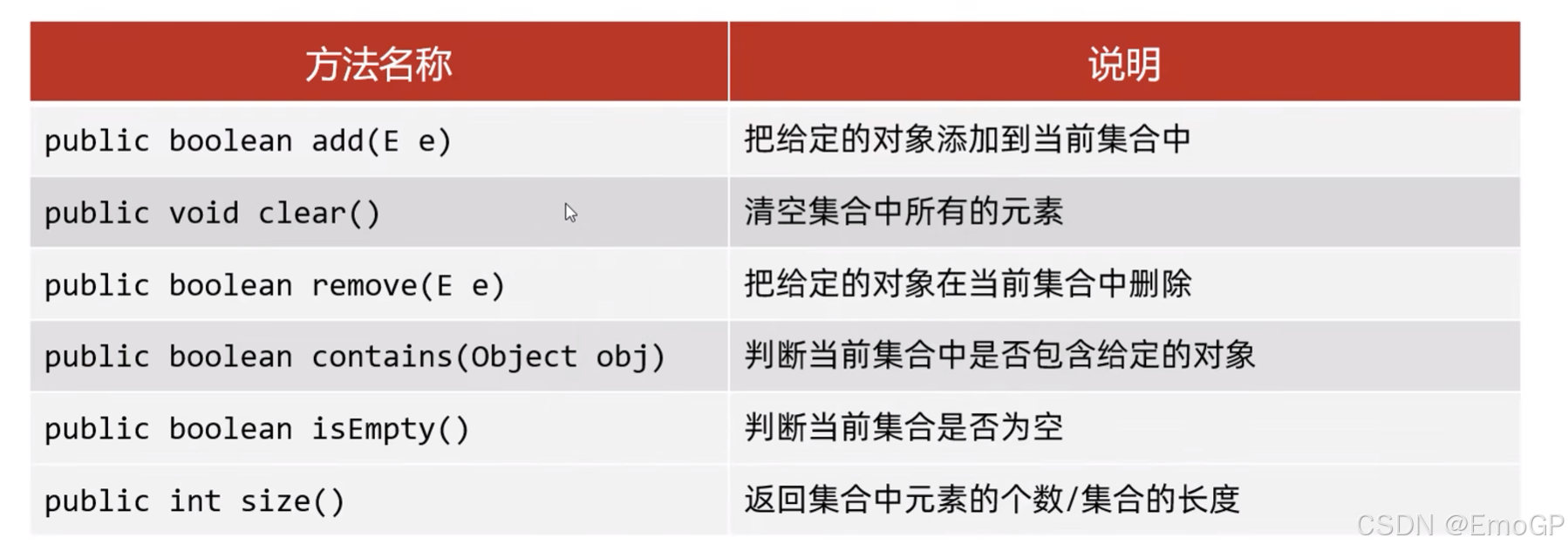
添加元素
如果我们要往List系列集合中添加数据,那么方法永远返回true,因为List系列的是允许元素重复的
如果我们要往Set系列集合中添加数据,如果当前要添加元素不存在,方法返回true,表示添加成功,如果当前要添加的元素已经存在,方法返回false,表示添加失败,因为Set系列的集合不允许重复
删除
因为Collection里面定义的是共性的方法,所以此时不能通过索引进行删除,只能通过元素的对象进行删除
如果删除的元素不存在,就删除失败,删除成功返回true,失败返回false
判断元素是否包含
底层是依赖equals方法进行判断是否存在的
所以,如果集合中存储的是自定义对象,也想通过contains方法来判断是否包含,那么在javabean类中,一定要重写equals方法
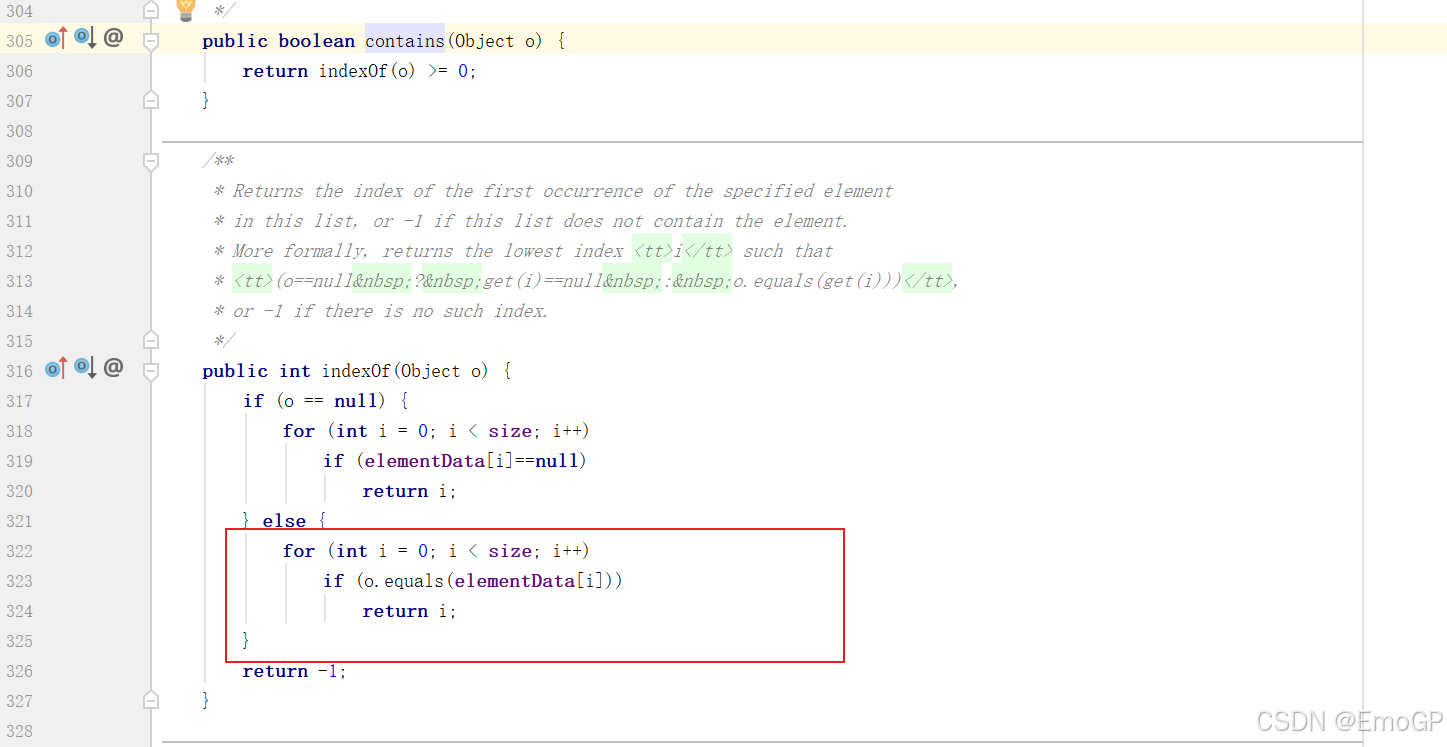
如果比较的是字符串,由于String已经重写过,可以直接用
Set系列集合
- 无序:存取顺序不一致
- 不重复:可以去除重复
- 无索引:没有带索引的方法,所以不能使用普通for循环遍历,也不能通过索引来获取元素
Set集合的实现类
- HashSet:无序、不重复、无索引
- LinkedHashSet:有序、不重复、无索引
- TreeSet:可排序、不重复、无索引
Set接口中的方法基本上与Collection的API一致
HashSet
底层原理
HashSet集合底层采取哈希表存储数据
哈希表是一种对于增删改查数据性能都较好的结构
哈希表组成
JDK8之前:数组 + 链表
JDK8开始:数组 + 链表 + 红黑树
哈希值:对象的整数表现形式
- 根据hashCode方法算出来的int类型的整数
- 该方法定义在Object类中,所有对象都可以调用,默认使用地址值进行计算
- 一般情况下,会重写hashCode方法,利用对象内部的属性值计算哈希值
对象的哈希值特点
- 如果没有重写hashCode方法,不同对象计算出的哈希值是不同的
- 如果已经重写hashCode方法,不同的对象只要属性值相同,计算出的哈希值就是一样的
- 在小部分情况下,不同的属性值或者不同的地址值计算出来的哈希值也有可能一样(哈希碰撞)
LinkedHashSet
- 有序、不重复、无索引
- 这里的有序指的是保证存储和取出的元素顺序一致
- 底层数据结构依然是哈希表,只是每个元素又额外的多了一个双链表的机制记录存储的顺序
在以后如果要数据去重,我们使用哪个?
默认使用HashSet
如果要求去重且存取有序,才使用LinkedHashSet
TreeSet
不重复、无索引、可排序
可排序:按照元素的默认规则(由小到大)排序
TreeSet集合底层是基于红黑树的数据结构实现排序的,增删改查性能都较好
双列集合
双列集合的特点
- 双列集合一次需要存一对数据,分别为键和值
- 键不能重复,值可以重复
- 键和值是一一对应的,每一个键只能找自己对应的值
- 键 + 值 这个整体 我们称之为 "键值对" 或者 "键值对对象",在Java中叫做 "Entry对象"
Map的常见API
Map是双列集合的顶层接口,它的功能是全部双列集合都可以继承使用的
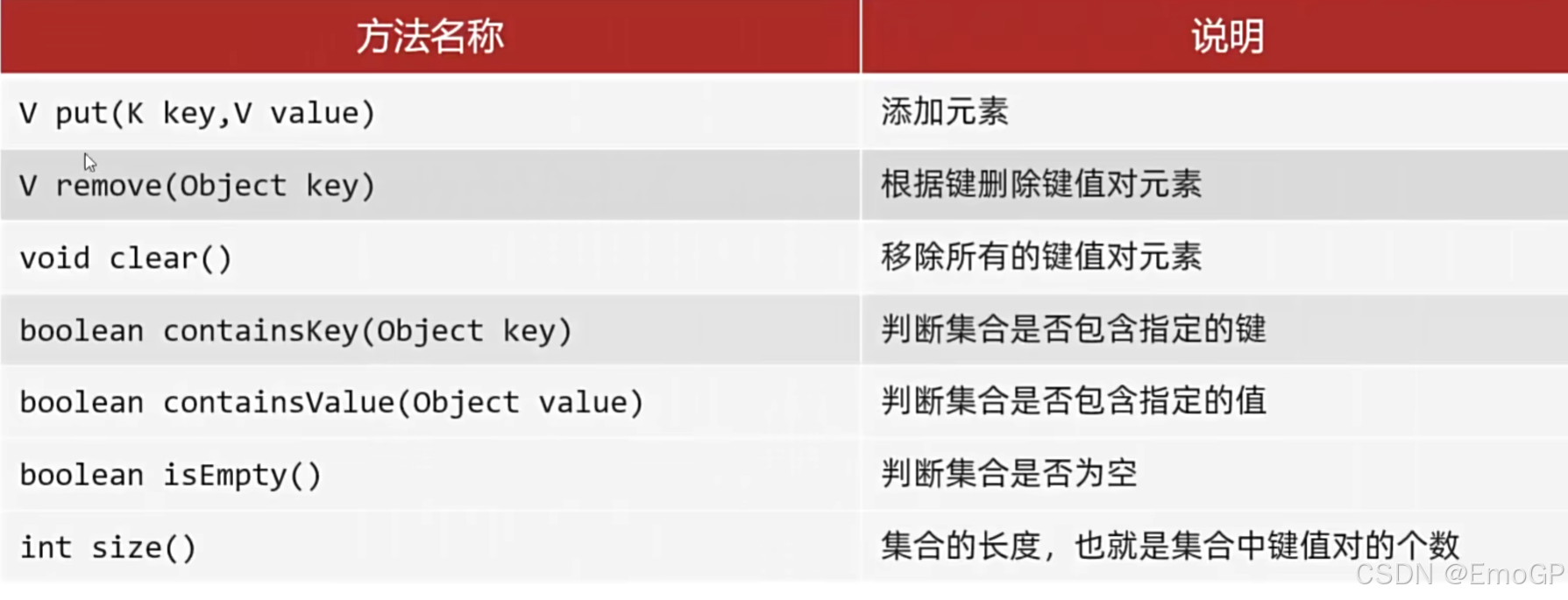
添加元素
在添加数据的时候,如果键不存在,那么直接把键值对对象添加到map集合当中,方法返回null
如果键是存在的,那么会把原有的键值对对象覆盖,会把覆盖的值进行返回
遍历方式
键找值
获取所有的键,把这些键放到一个单列集合当中
遍历单列集合,得到每一个键

通过键值对对象进行遍历
通过一个方法获取所有的键值对对象,返回一个Set集合
遍历这个集合,去得到每一个键值对对象
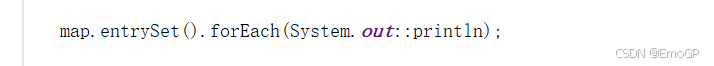
lambda表达式遍历

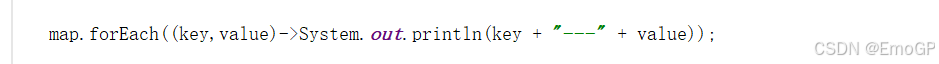
HashMap
- HashMap是Map里面的一个实现类
- 特点都是由键决定的:无序、不重复、无索引
- HashMap跟HashSet底层原理是一模一样的,都是哈希表结构
HashMap底层原理
Node<K,V>[] table 哈希表结构中数组的名字
DEFAULT_INITIAL_CAPACITY 数组默认长度16
DEFAULT_LOAD_FACTOR 默认加载因子 0.75HashMap里面每一个对象包含以下内容
链表中的键值对对象
包含:
int hash; //键的哈希值
final K key; //键
v value; //值
Node<K,V> next; //下一个节点的地址值红黑树中的键值对对象
包含:
int hash; //键的哈希值
final K key; //键
V value; //值
TreeNode<K,V> parent //父节点的地址值
TreeNode<K,V> left; //左子节点的地址值
TreeNode<K,V> right; // 右子节点的地址值
boolean red; // 节点的颜色数组里面的键值对对象内部包含的属性需要分情况讨论(作为链表头节点或者红黑树根节点)
LinkedHashMap
由键决定:有序、不重复、无索引
这里的有序指的是保证存储和取出的元素顺序一致
原理:底层数据结构依然是哈希表,只是每个键值对元素又额外的多了一个双链表的机制存储的顺序
TreeMap
TreeMap跟TreeSet底层原理一样,都是红黑树结构的
由键决定特性:不重复、无索引、可排序
可排序:对键进行排序
注意:默认按键的从小到大进行排序,也可以自己规定键的排序规则
代码书写两种排序规则
实现Comparable接口、指定比较规则
创建集合时传递Comparator比较器对象,指定比较规则