论文名字:UniMODE: Unified Monocular 3D Object Detection
地址:https://arxiv.org/abs/2402.18573v1
代码:https://github.com/Lizhuoling/UniMODE/blob/master/configs/UniMODE.yaml
主要内容
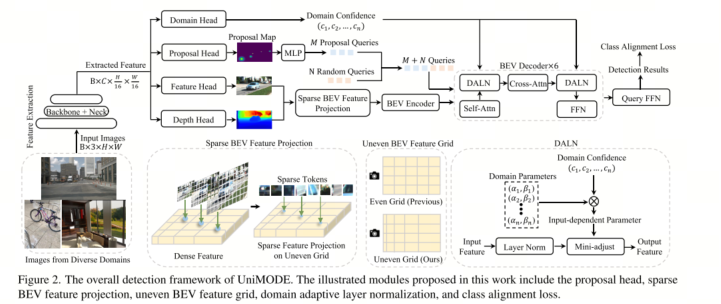
1、针对多种数据集的处理
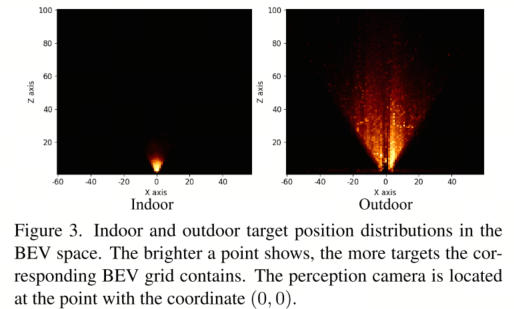
实验基于六种数据集进行,每个都是不用的检测范围,如图3室内和室外的范围.也有不同的类别。
- KITTI
- nuScenes
- Sun RGB-D
- ARKitScenes
- Hypersim
- Objectron
方案:
- 采用 deformable DETR architecture ,应对geometry property difference
- 采用 two-stage detection。
- 采用了可变化的网格 Uneven BEV Grid
2、BEV 投影(解决单目3D)
采用 corresponding depth confidence 深度阈值,筛选需要投影的特征点。
3、设计的Domain adaptive LN层 应对跨数据集
训练数据来自多个不同的域(如不同数据集、不同相机参数、不同场景),这些域的数据分布(颜色、风格、物体外观等)存在巨大差异。直接混合训练会导致模型性能下降。UniMODE 通过 "特征视角" 和 "损失函数视角" 来解决这个问题。
要求1(泛化性):模型在推理时,即使遇到训练时没见过的新域图像,也要能正常工作。
要求2(高效性):引入的域自适应机制不能增加太多计算开销。
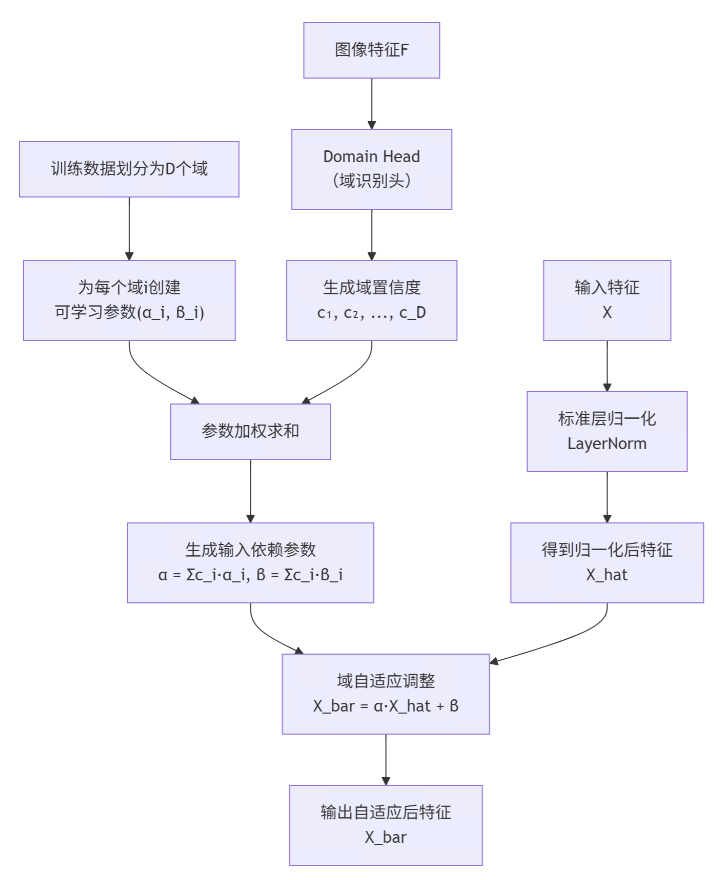
工作原理
划分域:首先将训练数据划分为 D个域(例如,D=4,分别对应4个不同的子数据集)。
创建可学习参数:为每个域 i创建一对专属的可学习参数 (α_i, β_i)。初始化时,所有 α_i=1,所有 β_i=0。这样,初始状态下DALN等同于标准LayerNorm,保证训练稳定性。
Domain Head(域识别头):如图2所示,Domain Head是一个小的卷积网络,以图像特征 F为输入。它的任务是预测当前输入图像属于这 D个域的置信度分数 {c_i}(一个概率分布,如图2中的 (c1, c2, ..., cn))。
根据预测出的置信度 {c_i},对 D个域的专属参数进行加权求和,得到针对当前输入图像的、独一无二的归一化参数 (α, β)。
公式:α = Σ (c_i * α_i), β = Σ (c_i * β_i)。
这正是图中 "Domain Confidence" -> "Domain Parameters" -> "Mini-adjust" 的数学实现。
自适应归一化X:
X 的表示 x(b,l,c)
b、l、c 通常是深度学习(尤其是处理序列数据的模型中)用来表示张量不同维度的索引。结合上下文 Xl ∈ RB×L×C,这很可能是一个具有 Batch大小、序列长度 和 特征维度 的三维张量。
下表详细解释了每个索引的常见含义:
索引符号 通常代表的维度 具体含义与上下文
b Batch Size (批次大小) 表示一次同时处理的独立样本(如图像、句子)的数量。例如,b=0 代表这一批数据中的第一个样本。
l Length / Position (序列长度/位置) 表示序列中元素的位置。在处理文本时,这可以是一个句子中的第 l 个单词;在处理时间序列时,则代表第 l 个时间点。
c Channel / Feature (特征维度) 表示每个序列点(或单词)对应的特征向量的维度。例如,在词嵌入中,c 遍历一个单词的 C 维向量表示中的每一个数值。
💡 一个直观的例子
假设我们有一个包含8个句子的批次(B=8),每个句子被填充或截断到50个单词的长度(L=50),每个单词用一个300维的向量表示(C=300)。那么,输入张量 Xl 的形状就是 8, 50, 300。
此时,x(b,l,c) 就指向了这个大张量中的一个具体数值:
• x(0, 4, 255) 表示:这个批次中第一个句子(b=0)里的第五个单词(l=4,因为索引通常从0开始)的第256维特征值(c=255)。
操作
先用标准LayerNorm处理输入特征 X,得到 X_hat。
然后用计算出的 (α, β)对 X_hat进行缩放和偏移:X_bar = α * X_hat + β。
X_bar就是经过域自适应调整后的输出特征。

4、类别对齐损失(Class Alignment Loss)
不同数据集的标注类别空间不同。例如,数据集A标注了"窗户",但数据集B没有标注"窗户"。
当把数据集A和B合并时,总的类别空间是它们所有类别的并集。对于数据集B的一张图,其中可能包含"窗户",但这个"窗户"没有被标注(在数据集B的标注里,它不属于任何目标)。
在训练时,模型可能会把这个"窗户"检测为某个物体,但由于数据集B的标注里没有"窗户",这个检测结果会被错误地视为"背景"上的假阳性目标而受到惩罚。这会严重干扰模型收敛。
解决方案:Class Alignment Loss
这个损失函数的逻辑非常巧妙:
判断类别是否在数据集的标注范围内:对于当前样本(来自第 i个数据集),如果其真实标签 y_bar是背景(B),并且这个背景所对应的真实类别(即模型可能预测的那个类别)y并不属于第 i个数据集的标注空间 Ω_i。
减轻惩罚:当上述条件满足时,就认为这个"错误"是由于标注冲突造成的,而不是模型真的判断错了。因此,计算损失时,对这个样本的惩罚会乘以一个缩小因子 γ (0 < γ < 1),从而减轻对这类情况的惩罚力度。
正常惩罚:对于其他情况(例如,模型把猫误判成狗,而猫和狗都在数据集的标注范围内),则按正常损失计算。
总结一下:这个损失函数教会模型"知之为知之,不知为不知"。对于一个数据集未标注的类别,即使模型没检测对,也不会受到严厉的惩罚,从而避免了标注不一致带来的训练干扰。