一、打印内容说明
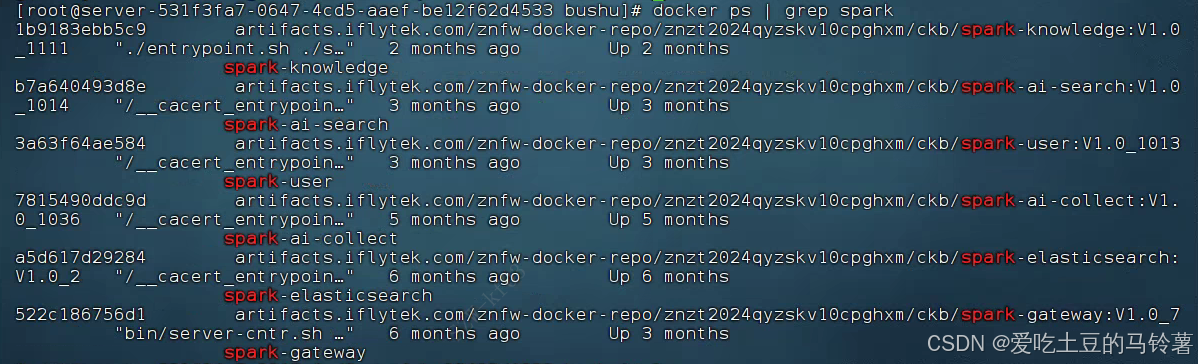
docker ps默认输出的核心列是:容器ID(CONTAINER ID) → 镜像名称(IMAGE) → 命令(COMMAND) → 创建时间(CREATED) → 状态(STATUS) → 容器名称(NAMES)。
对应到输出内容,每个服务的信息是:
| 容器ID | 镜像名称(IMAGE) | 容器名称(NAMES) |
|---|---|---|
| lb91183ebbc59(注:实际是1b9183ebbc59) | artifacts.iflytek.com/znfw-docker-repo/znzt2024qyzskv10cpg hxm/ckb/spark-knowledge:V1.0_1111 | spark-knowledge |
| b7a640493d8e | artifacts.iflytek.com/znfw-docker-repo/znzt2024qyzskv10cpg hxm/ckb/spark-ai-search:V1.0_1014 | spark-ai-search |
| 3a63f64ae584 | artifacts.iflytek.com/znfw-docker-repo/znzt2024qyzskv10cpg hxm/ckb/spark-user:V1.0_1013 | spark-user |
| 7815490ddc9d | artifacts.iflytek.com/znfw-docker-repo/znzt2024qyzskv10cpg hxm/ckb/spark-ai-collect:V1.0_1036 | spark-ai-collect |
| a5d617d29284 | artifacts.iflytek.com/znfw-docker-repo/znzt2024qyzskv10cpg hxm/ckb/spark-elasticsearch:V1.0_2 | spark-elasticsearch |
| 522c186756d1 | artifacts.iflytek.com/znfw-docker-repo/znzt2024qyzskv10cpg hxm/ckb/spark-gateway:V1.0_7 | spark-gateway |
二、镜像名称 vs 容器名称:核心区别
可以类比成"安装包"和"正在运行的软件":
- 镜像名称(IMAGE) :是一个静态的"模板/安装包" ,里面包含了服务运行需要的代码、依赖、配置等所有内容(比如上面的
spark-knowledge:V1.0_1111就是带版本的镜像)。它是"死的",不能直接运行,只能用来创建容器。 - 容器名称(NAMES) :是基于镜像启动的"动态运行实例" (比如
spark-knowledge)。它是"活的",可以启动、停止、修改里面的内容,每个容器都是独立的(哪怕用同一个镜像,也能启动多个不同的容器)。
一、命令是打包「镜像」,不是容器
docker save 是专门用于将Docker镜像 打包成tar文件的命令,而容器是镜像的运行实例,打包容器需要用 docker export(但业务场景中一般优先打包镜像,因为镜像包含完整运行环境)。
你原命令里 spark-knowledge:backup_$(date +%Y%m%d) 是「镜像名称:标签」的格式,但这里有个小问题:你的镜像实际名称不是 spark-knowledge(spark-knowledge 是容器名),直接用这个会提示找不到镜像,需要先修正镜像名称。
二、先理清:各服务的「镜像完整名称」(打包的核心前提)
先从你之前的 docker ps 输出里提取每个服务的完整镜像名(镜像名带仓库地址+版本标签),整理如下:
| 容器名称(NAMES) | 完整镜像名称(IMAGE,打包时必须用这个) |
|---|---|
| spark-knowledge | artifacts.iflytek.com/znfw-docker-repo/znzt2024qyzskv10cpg hxm/ckb/spark-knowledge:V1.0_1111 |
| spark-ai-search | artifacts.iflytek.com/znfw-docker-repo/znzt2024qyzskv10cpg hxm/ckb/spark-ai-search:V1.0_1014 |
| spark-user | artifacts.iflytek.com/znfw-docker-repo/znzt2024qyzskv10cpg hxm/ckb/spark-user:V1.0_1013 |
| spark-ai-collect | artifacts.iflytek.com/znfw-docker-repo/znzt2024qyzskv10cpg hxm/ckb/spark-ai-collect:V1.0_1036 |
| spark-elasticsearch | artifacts.iflytek.com/znfw-docker-repo/znzt2024qyzskv10cpg hxm/ckb/spark-elasticsearch:V1.0_2 |
| spark-gateway | artifacts.iflytek.com/znfw-docker-repo/znzt2024qyzskv10cpg hxm/ckb/spark-gateway:V1.0_7 |
三、各服务镜像打包成tar包的正确命令(逐个说明)
通用规则:
docker save -o 【输出的tar包路径/名称】 【完整镜像名称】
-o:指定打包后的tar包保存路径和名称(建议包含服务名+日期,方便区分);- 镜像名称必须和上面表格里的「完整镜像名称」完全一致(包括仓库地址、版本标签)。
逐个服务的打包命令:
1. spark-knowledge 镜像打包
bash
# 打包后tar包名:spark-knowledge_20251203.tar(日期自动取当天)
docker save -o ./spark-knowledge_$(date +%Y%m%d).tar artifacts.iflytek.com/znfw-docker-repo/znzt2024qyzskv10cpg hxm/ckb/spark-knowledge:V1.0_11112. spark-ai-search 镜像打包
bash
docker save -o ./spark-ai-search_$(date +%Y%m%d).tar artifacts.iflytek.com/znfw-docker-repo/znzt2024qyzskv10cpg hxm/ckb/spark-ai-search:V1.0_10143. spark-user 镜像打包
bash
docker save -o ./spark-user_$(date +%Y%m%d).tar artifacts.iflytek.com/znfw-docker-repo/znzt2024qyzskv10cpg hxm/ckb/spark-user:V1.0_10134. spark-ai-collect 镜像打包
bash
docker save -o ./spark-ai-collect_$(date +%Y%m%d).tar artifacts.iflytek.com/znfw-docker-repo/znzt2024qyzskv10cpg hxm/ckb/spark-ai-collect:V1.0_10365. spark-elasticsearch 镜像打包
bash
docker save -o ./spark-elasticsearch_$(date +%Y%m%d).tar artifacts.iflytek.com/znfw-docker-repo/znzt2024qyzskv10cpg hxm/ckb/spark-elasticsearch:V1.0_26. spark-gateway 镜像打包
bash
docker save -o ./spark-gateway_$(date +%Y%m%d).tar artifacts.iflytek.com/znfw-docker-repo/znzt2024qyzskv10cpg hxm/ckb/spark-gateway:V1.0_7四、补充说明
-
为什么不能用容器名打包?
docker save只认「镜像名」,不认「容器名」。比如你原命令里写spark-knowledge:backup_xxx,但spark-knowledge是容器名,不是镜像名,执行会报错no such image,必须替换成表格里的完整镜像名。 -
打包后验证:
执行完打包命令后,用
ls -lh查看当前目录,能看到对应tar包(比如spark-knowledge_20251203.tar),说明打包成功。 -
如果想打包容器(极少用,仅作补充):
若非要打包容器(容器是运行实例,打包后丢失镜像的分层、历史等信息),命令是:
bash# 以spark-knowledge容器为例 docker export -o ./spark-knowledge_container_$(date +%Y%m%d).tar spark-knowledge业务场景中优先用
docker save打包镜像,因为镜像可直接重新创建容器,而容器打包的文件仅能导入为镜像(且不完整)。 -
批量打包(可选,简化操作):
若想一次性打包所有服务,可写个简单脚本:
bash#!/bin/bash # 定义所有服务的镜像名和对应输出文件名 declare -A images=( ["spark-knowledge"]="artifacts.iflytek.com/znfw-docker-repo/znzt2024qyzskv10cpg hxm/ckb/spark-knowledge:V1.0_1111" ["spark-ai-search"]="artifacts.iflytek.com/znfw-docker-repo/znzt2024qyzskv10cpg hxm/ckb/spark-ai-search:V1.0_1014" ["spark-user"]="artifacts.iflytek.com/znfw-docker-repo/znzt2024qyzskv10cpg hxm/ckb/spark-user:V1.0_1013" ["spark-ai-collect"]="artifacts.iflytek.com/znfw-docker-repo/znzt2024qyzskv10cpg hxm/ckb/spark-ai-collect:V1.0_1036" ["spark-elasticsearch"]="artifacts.iflytek.com/znfw-docker-repo/znzt2024qyzskv10cpg hxm/ckb/spark-elasticsearch:V1.0_2" ["spark-gateway"]="artifacts.iflytek.com/znfw-docker-repo/znzt2024qyzskv10cpg hxm/ckb/spark-gateway:V1.0_7" ) # 循环打包 for name in "${!images[@]}"; do docker save -o ./${name}_$(date +%Y%m%d).tar ${images[$name]} echo "✅ 已打包 ${name} 镜像:./${name}_$(date +%Y%m%d).tar" done保存为
backup_spark_images.sh,执行chmod +x backup_spark_images.sh && ./backup_spark_images.sh即可批量打包。
一、打包耗时:没有固定值,核心看2个因素
Docker镜像打包(docker save)的耗时主要取决于镜像大小 + 服务器磁盘IO/网络(如果镜像有远程层):
- 小镜像(几十MB):几秒到十几秒;
- 中大型镜像(几百MB几GB):几分钟甚至更久(比如你的spark相关镜像,大概率是几百MB级别,通常15分钟居多)。
你可以先执行 docker images --format "{``{.Repository}}:{``{.Tag}} {``{.Size}}" | grep spark 查看每个镜像的大小,能大致判断耗时:
bash
# 执行这个命令看镜像大小
docker images --format "{{.Repository}}:{{.Tag}} {{.Size}}" | grep spark二、怎么看是否在打包?3种方法确认状态
docker save 命令执行时默认没有实时输出(属于"静默执行"),但可以通过以下方式判断是否在运行:
方法1:新开终端,查进程(最直接)
登录服务器新开一个终端,执行以下命令,能看到 docker save 进程就说明还在打包:
bash
# 查找docker save相关进程
ps -ef | grep "docker save"
# 或更精准:只看正在运行的docker save进程(排除grep自身)
ps -ef | grep "docker save" | grep -v grep-
输出类似这样,说明进程还在(打包中):
root 12345 12000 2 10:00 pts/0 00:00:10 docker save -o ./spark-knowledge_20251203.tar artifacts.iflytek.com/znfw-docker-repo/znzt2024qyzskv10cpg hxm/ckb/spark-knowledge:V1.0_1111 -
若没有输出,说明进程已结束(要么打包完成,要么报错退出)。
方法2:看磁盘写入(判断是否在干活)
docker save 会往本地写tar文件,可通过 du 或 ls -lh 实时看文件大小变化:
- 先执行
ls -lh | grep .tar看目标tar文件的大小(刚执行命令时,文件可能是0字节或很小); - 隔几秒再执行一次,如果文件大小在持续增长,说明还在打包;
- 若大小长时间不变,且进程也消失了,说明打包完成/失败。
示例:
bash
# 实时监控tar包大小(替换成你的包名)
watch -n 1 "ls -lh spark-knowledge_$(date +%Y%m%d).tar"watch -n 1表示每秒刷新一次,能直观看到文件从0→逐渐增大→停止增长(完成)。
方法3:查Docker守护进程日志(可选)
如果怀疑命令卡住,可查看Docker日志(不同系统路径略有差异):
bash
# CentOS/RHEL系统
journalctl -fu docker.service | grep save
# Ubuntu系统
tail -f /var/log/docker.log | grep save- 若有
save相关的日志输出,能看到打包的进度/错误;若无异常日志,说明命令在正常执行。
三、关于"命令执行完没输出":必须等打包完成!
docker save 是阻塞式命令 ------执行后会一直运行,直到打包完成(或报错)才会返回终端提示符(比如 [root@server ~]#):
- 终端没有回到提示符 → 还在打包中,千万别中断(Ctrl+C会导致打包失败,tar包损坏);
- 终端回到提示符 → 打包完成(无论成功/失败,都会退出)。
四、打包完成/失败的判断
1. 打包成功
- 终端回到提示符;
ls -lh能看到tar包,且大小和镜像大小匹配(比如镜像500MB,tar包大概450~500MB,因为tar会轻微压缩);- 执行
docker load -i 你的tar包名.tar能正常加载(可选验证,确保包没问题)。
2. 打包失败
- 终端回到提示符,但tar包大小为0字节/远小于镜像大小;
- 终端会输出错误提示(比如
no such image、权限不足、磁盘满等); - 常见失败原因:镜像名写错、磁盘空间不足(执行
df -h看磁盘使用率)、权限不够(加sudo)。
五、补充:避免打包卡住的小技巧
- 先检查磁盘空间:
df -h确保当前目录所在磁盘有足够空间(至少是镜像大小的1.5倍); - 打包时别做高IO操作(比如拷贝大文件、跑其他任务),避免拖慢速度;
- 若单个镜像打包太久,可分批打包(比如先打1个,确认耗时后再批量)。
如果等了很久(比如超过10分钟)还没完成,先通过方法1查进程是否还在,再查磁盘IO(iostat -x 1)和Docker日志,大概率是磁盘慢或镜像太大导致的,耐心等即可。