为了解决CDH 6.3.2 默认的 Hive sql on Spark 和 Spark sql (Spark版本为2.4.0)无法写入修改Paimon 1.1.1 版本的表格数据的问题。
这里我先使用Flink SQL创建测试表:
sql
-- 创建paimon的catalog
CREATE CATALOG paimon_catalog WITH (
'type' = 'paimon',
'warehouse' = 'hdfs:///user/hive/warehouse',
'metastore' = 'hive',
'hive-conf-dir' = '/etc/hive/conf.cloudera.hive'
);
use catalog paimon_catalog;
use ods;
-- 创建测试表
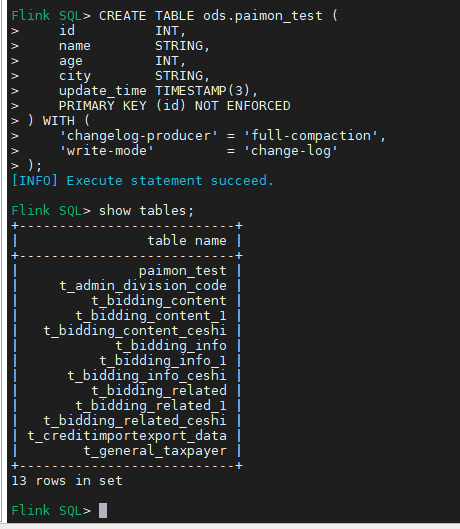
CREATE TABLE paimon_test (
id INT,
name STRING,
age INT,
city STRING,
update_time TIMESTAMP(3),
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'changelog-producer' = 'full-compaction',
'write-mode' = 'change-log'
);
之后在hue上执行如下操作:
sql
show tables;
发现插入数据出现报错,因此hue上不能进行数据的插入,因此我在Flink SQL进行数据的插入。
sql
INSERT INTO ods.paimon_test
VALUES
(1,'Alice',23,'Shanghai',TIMESTAMP '2025-12-03 10:00:00'),
(2,'Bob',30,'Beijing',TIMESTAMP '2025-12-03 10:01:00'),
(3,'Carol',25,'Guangzhou',TIMESTAMP '2025-12-03 10:02:00'),
(4,'David',28,'Shenzhen',TIMESTAMP '2025-12-03 10:03:00'),
(5,'Eve',22,'Hangzhou',TIMESTAMP '2025-12-03 10:04:00'),
(6,'Frank',35,'Chengdu',TIMESTAMP '2025-12-03 10:05:00'),
(7,'Grace',27,'Wuhan',TIMESTAMP '2025-12-03 10:06:00'),
(8,'Henry',29,'Xian',TIMESTAMP '2025-12-03 10:07:00'),
(9,'Ivy',24,'Nanjing',TIMESTAMP '2025-12-03 10:08:00'),
(10,'Jack',31,'Tianjin',TIMESTAMP '2025-12-03 10:09:00');在hue上进行查看数据
sql
select * from paimon_test limit 5;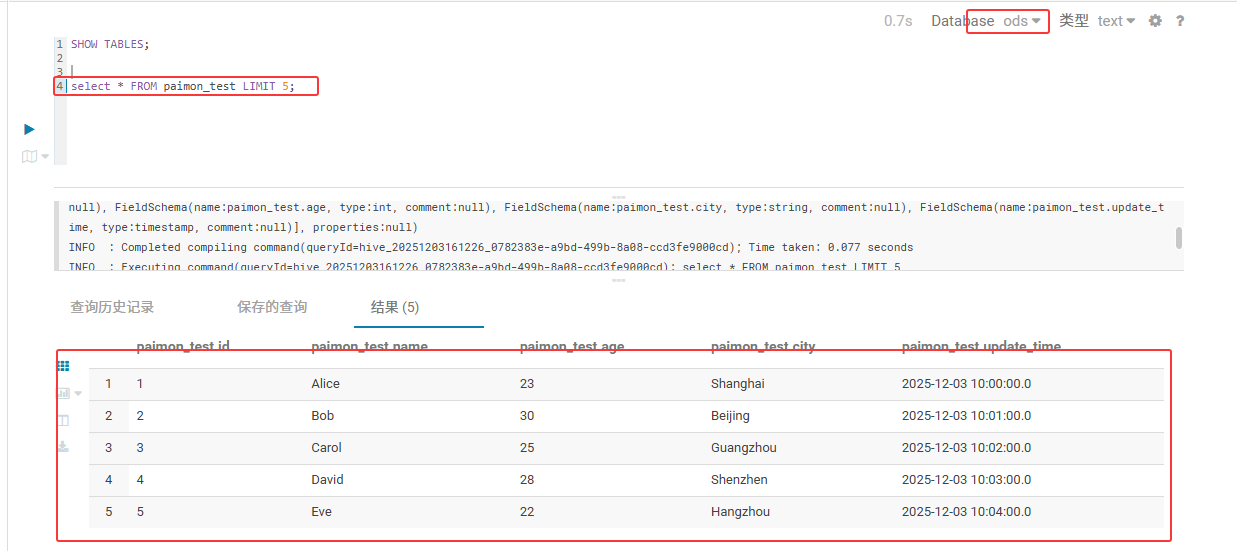
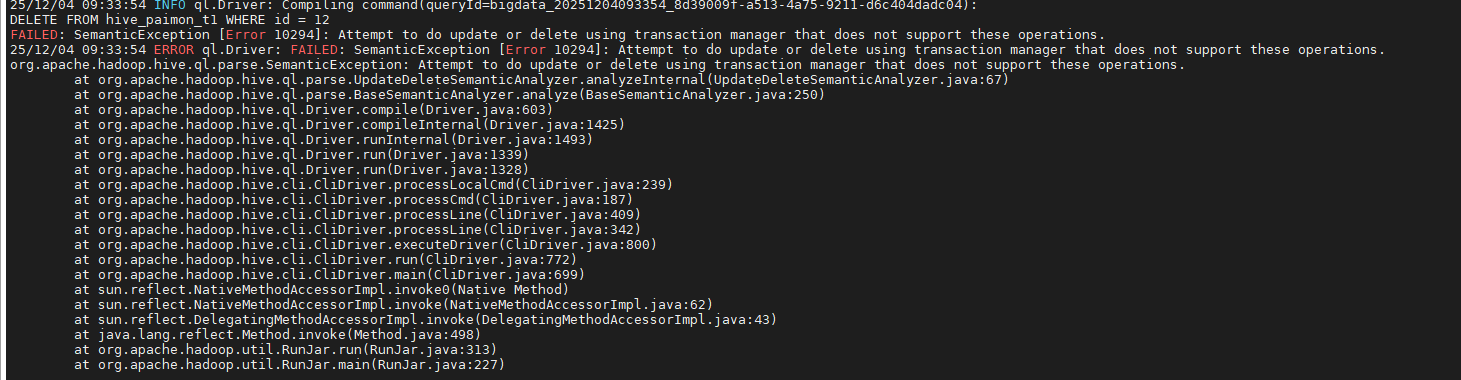
在终端执行下述语句,用于验证hive sql on spark对paimon表数据的更新操作。这是在CDH6.3.2的客户端机器上执行
bash
hive -e "SET hive.execution.engine=spark;
SET hive.spark.client.extra.jar.path=/home/bigdata/CDH/lib/hive/auxlib/paimon-hive-connector-2.1-cdh-6.3-1.1.1.jar;
SET spark.master=yarn;
SET spark.submit.deployMode=client;
SET spark.driver.memory=1g;
SET spark.executor.memory=2g;
SET spark.executor.cores=2;
SET spark.executor.instances=2;
SET spark.yarn.executor.memoryOverhead=512m;
USE paimon;
DELETE FROM hive_paimon_t1 WHERE id = 12;"出现如下报错:
在CDH6.3.2集群节点(这里我选择的第一个节点10.x.xx.201),执行下述语句:
bash
hive -e "SET hive.execution.engine=spark;
SET hive.spark.client.extra.jar.path=/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hive/auxlib/paimon-hive-connector-2.1-cdh-6.3-1.1.1.jar;
SET spark.master=yarn;
SET spark.submit.deployMode=client;
SET spark.driver.memory=1g;
SET spark.executor.memory=2g;
SET spark.executor.cores=2;
SET spark.executor.instances=2;
SET spark.yarn.executor.memoryOverhead=512m;
USE paimon;
DELETE FROM hive_paimon_t1 WHERE id = 12;"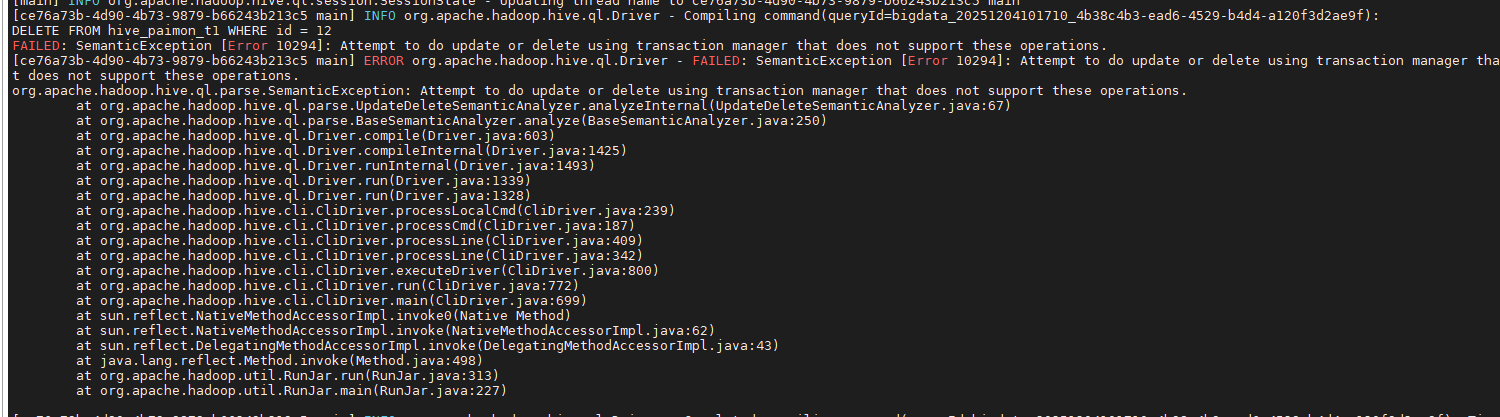
不论是客户端节点还是集群节点都出现了同样的报错。根本原因是Hive 在 CDH6.3.2 里默认使用「非事务」表(或虽然表属性里写了 transactional=true,但底层事务管理器仍然是org.apache.hadoop.hive.ql.lockmgr.DummyTxnManager)。
而 DELETE/UPDATE 语法只能在工作在「ACID 事务表」上,且必须满足下面 3 个条件:
-
表本身以 ORC 格式、分桶、transactional=true 的方式创建;
-
HiveServer/Metastore 端启用了事务功能(
hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager); -
当前会话把事务开关打开(
set hive.txn.manager=...; set hive.support.concurrency=true; set hive.enforce.bucketing=true; set hive.exec.dynamic.partition.mode=nonstrict;)。
只要其中任何一步没配好,Hive 就会抛出 「Attempt to do update or delete using transaction manager that does not support these operations」。 Paimon 表(paimon-hive-connector)目前只支持INSERT / SELECT / MERGE-INTO,并不支持 Hive 原生语法的 DELETE WHERE / UPDATE,所以即使 Hive 端 ACID 已配好,这条 DELETE 也依旧会报同样的错。为了解决如上出现的问题,需要在CDH 6.3.2 版本上编译支持java8,能对paimon 1.1.1 的表进行增删改查等操作。因此这里选择的编译spark版本为3.5.7。
后续编译步骤参考CDH 6.3.2 集群外挂部署 Spark 3.5.7 连接 Paimon 1.1.1 (二):CDH 6.3.2 集群外挂部署 Spark 3.5.7 连接 Paimon 1.1.1 (二)-CSDN博客