Hive概述
Hive核心是将HQL转换为MapReduce程序,然后将程序提交到Hadoop群集执行。Hive的最大的魅力在于用户专注于编写HQL,Hive帮您转换成为MapReduce程序完成对数据的分析。
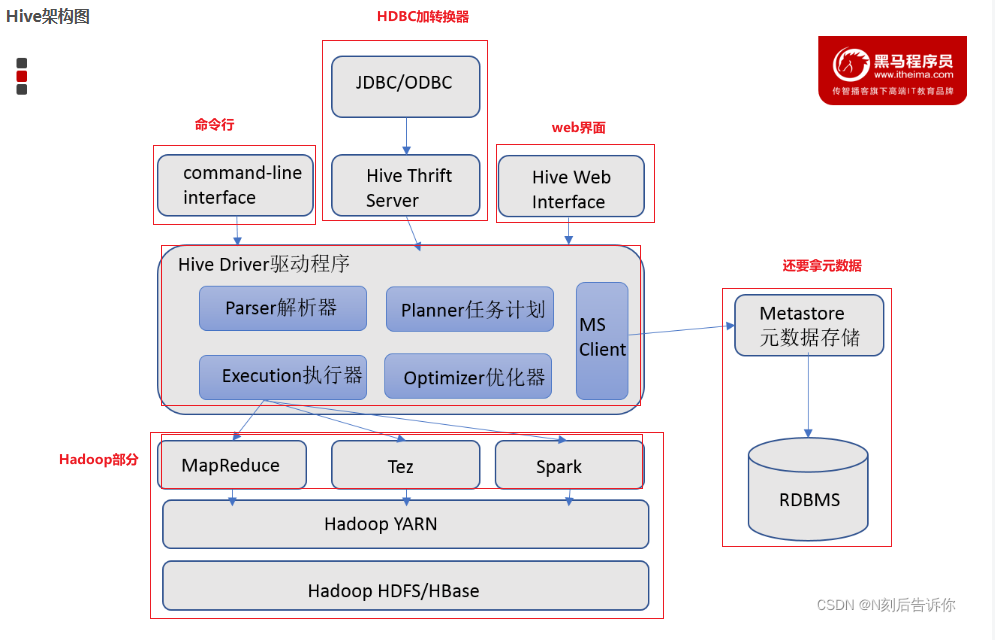
Hive基础架构
执行流程
- Metastore (元数据服务) ------ 图书馆的目录卡片
- MySQL 原理: 数据文件(.ibd)里既有数据又有表结构定义。
- Hive 原理: 数据只是 HDFS 上的一堆文本文件(CSV, JSON, Parquet)。Hive 怎么知道哪一列是
user_id?- 全靠 Metastore 。它通常是一个独立的 MySQL 数据库,记录了:
表A -> 对应 HDFS 路径 /data/table_a,以及第一列是 int, 第二列是 string。
- 全靠 Metastore 。它通常是一个独立的 MySQL 数据库,记录了:
- 实战影响: 如果你删了 HDFS 文件,表还在(读的时候报错);如果你删了 Metastore 里的元数据,文件还在(变成了无主孤魂的垃圾文件)。
- Drver (驱动器) ------ SQL 编译器
- 这是 Hive 的核心。它负责把你写的 HQL 解析成抽象语法树 (AST),然后优化,最后生成 执行计划 (Execution Plan)。
- 实战影响: 你需要学会看
EXPLAIN命令,看看 Driver 把你的 SQL 翻译成了几个 MapReduce 任务。
3. 执行引擎 (MapReduce / Tez / Spark) ------ 真正的苦力
- MySQL 自己有执行线程。
- Hive 没有自己的计算能力,它要把任务外包给计算引擎(默认是 MapReduce,现在主流是 Spark 或 Tez)。
- 实战影响: 一个简单的
GROUP BY操作,在底层会引发巨大的网络传输(Shuffle)。理解了这个,你就知道为什么要避免数据倾斜了。
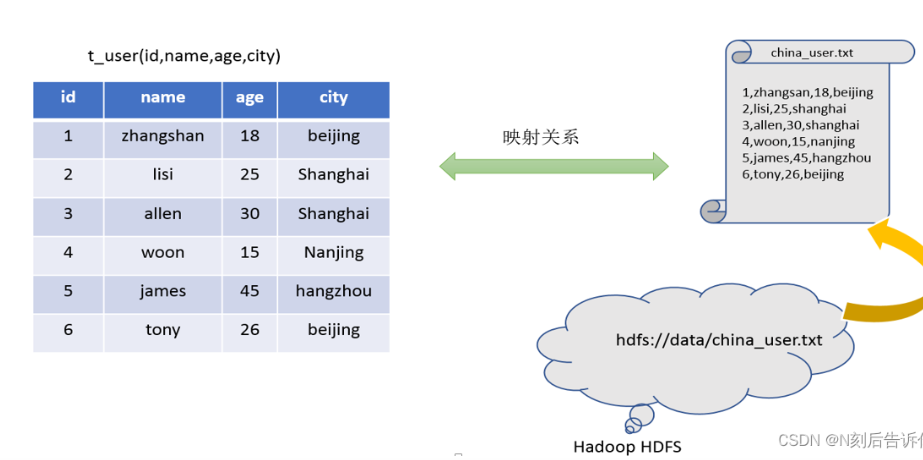
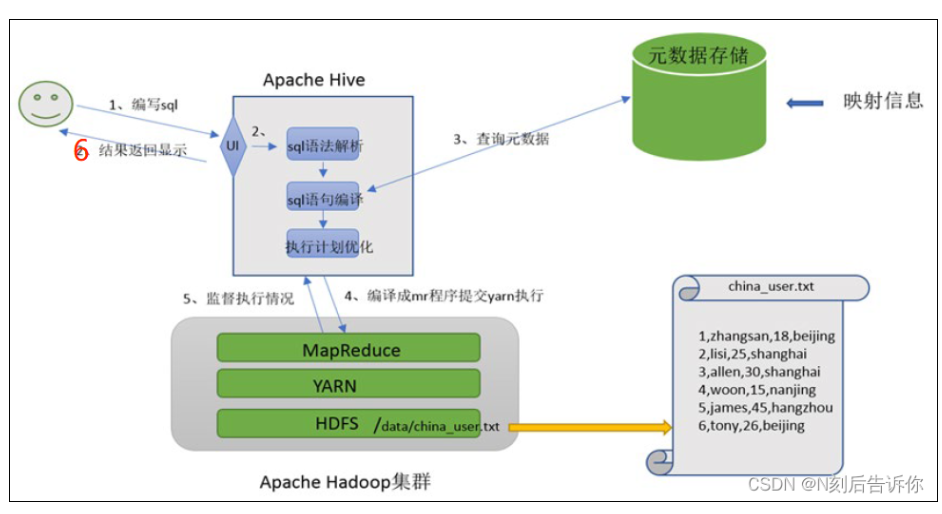
Hive metadata
因为HDFS里存储的一般是JSON或者CSV格式的,不想MySQL数据库那样有结构,那么Hive SQL该怎么找到对应的列呢?通过metaddata
Metastore 后端通常也是一个 MySQL 数据库 。 如果你连上这个 MySQL,你会看到这几张核心表(不要在生产环境手动改它们!):
TBLS: 存储表的名称、Owner、类型(Managed/External)、对应SDS表的 ID。DBS: 存储数据库的信息(对应 Hive 的 Database)。SDS(Storage Descriptors) : 最核心的表 。存储了 HDFS 路径 (LOCATION)、输入输出格式类名、是否压缩等。COLUMNS_V2: 存储具体的列名、类型、顺序。SERDES&SERDE_PARAMS: 存储具体的分隔符(比如field.delim是,)。
当你执行 SELECT name FROM users 时,Driver 访问 Metastore 的对话其实是这样的:
- Driver: "我要查
users表。" - Metastore (查询
TBLS): "有这张表,属于default库。" - Driver: "它的
name字段在哪?" - Metastore (查询
COLUMNS_V2): "是第 2 列,类型是 String。" - Driver: "文件在哪?怎么解析?"
- Metastore (查询
SDS和SERDE_PARAMS):- "文件在
hdfs://.../users。" - "格式是
TextFile。" - "分隔符是逗号
,(ASCII 44)。"
- "文件在
- Driver: "收到。我生成一个任务:去那个路径读文件,按逗号切分,取第 2 块数据作为
name返回。"
Hive SQL
SQL 是 Structured Query Language 的缩写,中文叫 结构化查询语言。
DML 是 Data Manipulation Language 的缩写,中文叫 数据操作语言 。
它主要用于对数据库中已有的表进行数据增删改查,也就是对**表里的记录(行)**进行操作,而不是改表结构。
DDL 是 Data Definition Language 的缩写,中文一般叫 数据定义语言 。
它是一类 用来定义和管理数据库结构 的 SQL 语句,主要负责"建库建表"这类操作,而不是操作表里的具体数据。
太棒了!既然你已经打通了任督二脉(架构原理),那我们现在正式开始练招(Hive SQL)。
作为后端开发,学习 Hive SQL 最痛苦的不是"学不会",而是**"习惯性动作导致的坑"**。
我们将按照 DDL (建表) -> DML (数据导入) -> DQL (查询) 的顺序,每一个环节都把你熟悉的 MySQL 和 Hive 拉出来"单挑",让你一眼看穿区别。
1. DDL 篇
这是差异最大的地方。MySQL 建表关注索引和引擎,Hive 建表关注数据的物理格式。
场景:建立 users 表
假设数据还是那个 CSV:id, name, age, city,逗号分隔。
| 维度 | MySQL (InnoDB) | Hive (数仓标准) | 根本区别 |
|---|---|---|---|
| 语法关键字 | PRIMARY KEY, AUTO_INCREMENT, ENGINE=InnoDB |
ROW FORMAT, STORED AS, PARTITIONED BY |
Hive 无主键约束,无自增 ID。 |
| 数据与表 | 强绑定。建表即分配空间。 | 松耦合。可以先建表,再把文件指过去;或者删表留文件。 | Hive 必须告诉 Driver 怎么切分这行文本。 |
| 类型 | VARCHAR(255) |
STRING |
Hive 尽量用 STRING,不用指定长度。 |
代码对比
MySQL 写法:
CREATE TABLE users (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50),
age INT,
city VARCHAR(50)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;Hive 写法 (标准生产环境版):
CREATE EXTERNAL TABLE users ( -- 1. 推荐使用 EXTERNAL (外部表)
id INT COMMENT '用户ID',
name STRING COMMENT '姓名', -- 2. 类型直接用 STRING
age INT COMMENT '年龄',
city STRING COMMENT '城市'
)
COMMENT '用户基础信息表'
PARTITIONED BY (dt STRING) -- 3. 核心:按日期分区 (MySQL很少这么写)
ROW FORMAT DELIMITED -- 4. 告诉 SerDe 怎么解析
FIELDS TERMINATED BY ',' -- 列分隔符是逗号
STORED AS TEXTFILE -- 5. 存储格式 (生产环境常用 ORC/Parquet)
LOCATION '/data/warehouse/users'; -- 6. 指定 HDFS 路径 (可选)🛑 避坑指南:
EXTERNAL: 后端习惯DROP TABLE删库跑路。在 Hive 里,如果是EXTERNAL表,DROP只删元数据,HDFS 数据还在。这在生产环境是保命符。PARTITIONED BY: 看到dt了吗?它不在(id, name...)的定义里,但在 HDFS 上会变成/dt=2023-11-22/这样的文件夹。这是 Hive 唯一的"粗粒度索引"。
2. DML 篇
后端开发习惯用 INSERT 一条条插数据,这在 Hive 里是绝对禁止的。
| 维度 | MySQL | Hive | 根本区别 |
|---|---|---|---|
| 模式 | 交互式写入 (OLTP) | 批量导入 (Bulk Load) | Hive 为了吞吐量设计,不是为了低延迟。 |
| 底层动作 | 写 WAL 日志,更新 B+ 树 | 移动文件 或 MapReduce 写入 | LOAD 仅仅是把 HDFS 上的文件 mv 到表目录下。 |
| 速度 | 几千条/秒 | 几百 MB/秒 (直接搬文件) | Hive 极其擅长处理海量数据。 |
代码对比
MySQL 写法:
INSERT INTO users (name, age, city) VALUES ('zhangsan', 18, 'beijing');
-- 只有少量数据这样做Hive 写法 1:搬运文件 (最快)
-- 假设你已经把 100GB 的 log.csv 上传到了 HDFS 的 /tmp 目录
-- 这句话瞬间完成,因为只是改了 HDFS 的文件路径元数据
LOAD DATA INPATH '/tmp/log.csv'
INTO TABLE users
PARTITION (dt='2023-11-22');Hive 写法 2:清洗数据 (常用)
-- 从临时表 A 选出数据,经过处理,覆盖写入正式表 B
INSERT OVERWRITE TABLE users PARTITION (dt='2023-11-22')
SELECT id, name, age, city
FROM tmp_users
WHERE dt = '2023-11-22' AND age > 0;🛑 避坑指南:
- 不要用
INSERT INTO ... VALUES ...:虽然 Hive 支持,但每插入一条都会生成一个小文件。几万个小文件会把 NameNode (HDFS 的主节点) 搞挂。 OVERWRITE: Hive 数仓为了保证幂等性,通常用INSERT OVERWRITE。如果任务重跑,它会先清空该分区,再写入,防止数据重复。
3. DQL 篇
语法 90% 相似,但执行代价天差地别。
| 维度 | MySQL | Hive | 根本区别 |
|---|---|---|---|
| 全表扫描 | SELECT * 慢,但能接受 |
灾难级后果 | Hive 表可能有 PB 级数据。必须加分区过滤。 |
| 去重 | COUNT(DISTINCT col) 很快 |
极慢 (容易 OOM) | 所有数据挤到一个 Reducer 去重,容易内存溢出。 |
| LIMIT | LIMIT 10 瞬间返回 |
可能需要启动 MapReduce | 虽然新版本有 fetch task 优化,但本质仍不同。 |
代码对比:去重统计
场景: 统计有多少个不同的用户。
MySQL 写法:
SELECT COUNT(DISTINCT user_id) FROM users;Hive 写法 (优化版):
如果数据量过亿,上面的写法在 Hive 里可能会跑几个小时甚至报错。
后端思维转换: 用"多线程分组"代替"单点去重"。
-- 1. 错误/低效写法 (数据倾斜风险)
SELECT COUNT(DISTINCT user_id) FROM users WHERE dt='2023-11-22';
-- 2. 高效写法 (MapReduce 思维)
-- 先 Group By 把数据打散到不同的 Reducer,再 Count
SELECT COUNT(1)
FROM (
SELECT user_id
FROM users
WHERE dt='2023-11-22'
GROUP BY user_id -- 这里利用了多节点并行去重
) t;避坑指南
- 分区过滤是强制的 :在很多公司,如果你的 SQL
WHERE里没有dt=...,SQL 审核平台直接会拦截你的查询,不允许提交。 - 别指望秒级响应 :在 MySQL 里你可能习惯不断试错修改 SQL;在 Hive 里,跑一次 SQL 可能要 10 分钟,所以写之前要在脑子里(或者用
EXPLAIN)先预演一遍。
总结
- 建表 (Create): 记得加
EXTERNAL,记得定义分隔符ROW FORMAT,最重要的是一定要加PARTITIONED BY。 - 写入 (Insert): 忘掉
INSERT VALUES,使用LOAD DATA(搬文件) 或INSERT OVERWRITE SELECT(洗数据)。 - 查询 (Select): 永远带着
WHERE dt='...'。遇到COUNT(DISTINCT)要警惕,尝试用GROUP BY替代。
ORMAT,最重要的是**一定要加 PARTITIONED BY**。 2. **写入 (Insert):** 忘掉 INSERT VALUES,使用 LOAD DATA(搬文件) 或INSERT OVERWRITE SELECT(洗数据)。 3. **查询 (Select):** 永远带着WHERE dt='...'。遇到 COUNT(DISTINCT)要警惕,尝试用GROUP BY` 替代。