一、为什么需要ETL与Hudi集成
随着企业数据规模的爆发式增长,传统的数据仓库架构已难以满足业务对实时性和灵活性的需求。Apache Hudi作为新一代流式数据湖框架,将流处理的能力引入数据湖,实现了批流一体的数据管理范式。
然而,将业务数据高效写入Hudi数据湖并与现有ETL流程无缝衔接,是许多企业面临的技术挑战。传统的做法是通过多级数据搬运:先写入Kafka,再由Spark/Flink消费后写入Hudi。这种方案虽然可行,但架构复杂、延迟较高、维护成本居高不下。
1.传统方案痛点
架构复杂、延迟高、组件多、运维难
2.集成后优势
一站式写入、分钟级延迟、统一管理
3.业务价值
降本增效、数据实时可用、分析更灵活

二、Apache Hudi核心概念解析
Apache Hudi(Hive Update, Deletion, and Insertion)是Uber开源的流式数据湖框架,于2020年晋升为Apache顶级项目。它在HDFS/云存储之上提供了类似于数据库的ACID事务能力,支持增量处理和模式演化。
Hudi三大表类型
Copy On Write (COW)
写入时直接重写数据文件,无压缩合并。适合写少读多的场景,读取性能最优。
Merge On Read (MOR)
数据先写入日志文件,读取时合并。适合写多读少的场景,写入性能最优。
Log (仅MOR)
增量日志方式存储最新写入,兼顾实时性与压缩优化。

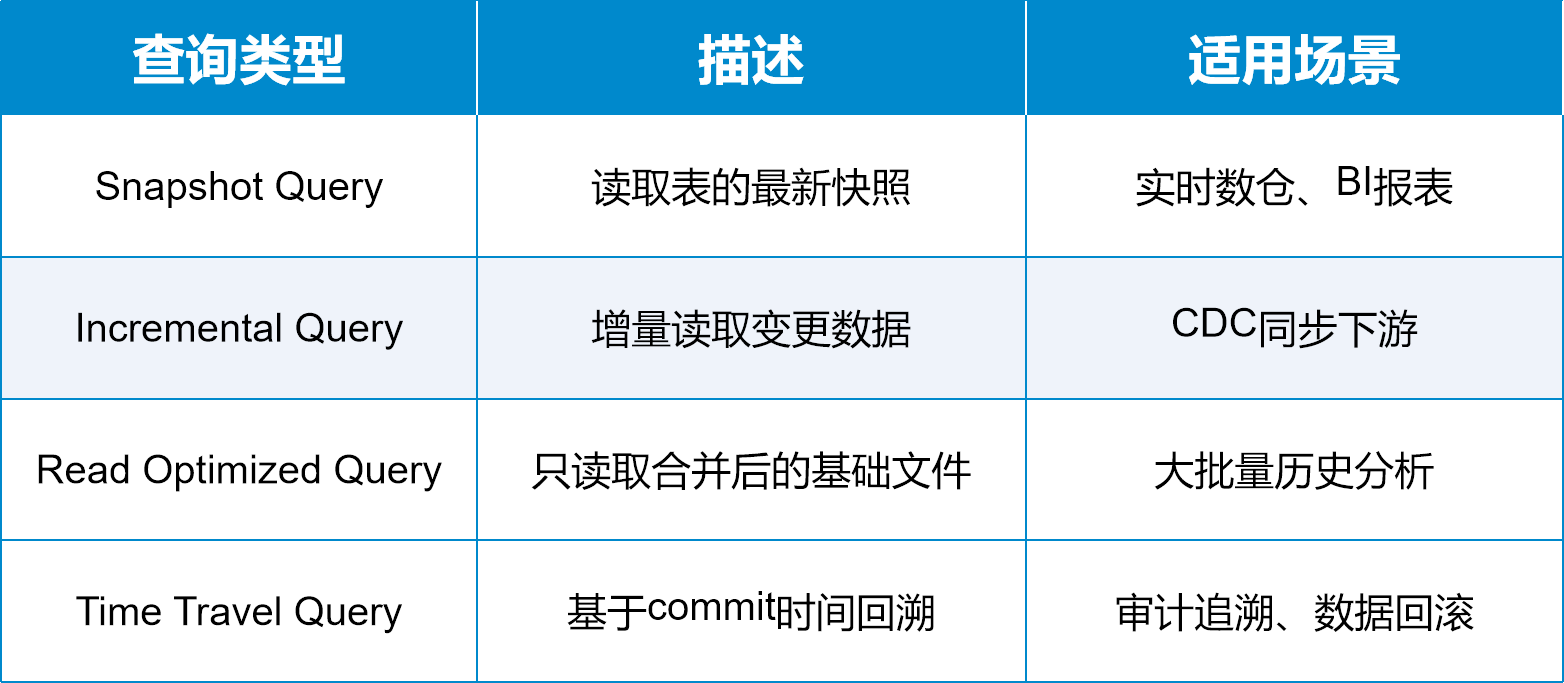
Hudi四种查询类型
三、ETLCloud集成Hudi实战
ETLCloud提供了开箱即用的Hudi集成能力,支持将任意数据源的数据直接写入Hudi数据湖。整个过程可视化配置,无需编写代码。
操作步骤一:创建Hudi数据目标
- 在ETLCloud「数据目标」页面,选择「Hudi」类型;
- 配置Hudi表参数:表名、存储路径(HDFS/S3)、表类型(COW/MOR);
- 设置分区策略:按日期/业务ID/动态分区;
- 配置写入参数:压缩策略、并发度、记录键字段;
操作步骤二:配置ETL转换流程
- 拖拽创建「数据源」节点 → 「数据转换」节点 → 「Hudi输出」节点;
- 在数据转换节点中配置字段映射、类型转换、数据清洗规则;
- 设置Hudi输出节点的Upsert策略:Insert if Not Exists / Update if Exists;
操作步骤三:执行与监控
- 点击「运行」按钮,任务将以Spark引擎执行;
- 在「运行监控」页面查看写入进度、延迟、数据量;
- 支持异常告警配置,数据写入失败自动通知;
四、最佳实践与性能优化
1.表类型选择建议
Copy On Write (COW)
适合读多写少场景,如数据仓库、历史数据分析。读取时无需合并,延迟更低。
Merge On Read (MOR)
适合写多读少场景,如实时数仓CDC写入。写入性能更高,存储更紧凑。
2.分区策略优化
-
按日期分区:最常用策略,便于数据生命周期管理和历史数据清理
-
按业务ID分区:避免小文件问题,提升查询性能
-
动态分区:根据数据内容自动创建分区,减少元数据管理开销
3.写入性能调优
-
调整并发度:根据集群资源合理配置写入并发,通常建议4-8个并发任务
-
小文件合并:配置自动合并策略,避免小文件影响读取性能
-
批量提交:合理设置commit间隔,在延迟与吞吐量间取得平衡
五、总结
ETL与数据湖Hudi的集成是构建现代流式数据架构的关键一环。通过ETLCloud的可视化配置,企业可以快速实现数据源到Hudi的高效写入,无需深入了解底层技术细节。掌握Hudi的表类型选择、分区策略和性能调优,将帮助企业更好地发挥数据湖的价值,支撑实时分析与AI数据需求。