目录
[1. 基础环境准备(权限与目录)](#1. 基础环境准备(权限与目录))
[2. 封装启动脚本](#2. 封装启动脚本)
[3. 服务启动与验证](#3. 服务启动与验证)
[3.1 启动服务](#3.1 启动服务)
[3.2 状态验证](#3.2 状态验证)
[3.3 终端验证](#3.3 终端验证)
[4. Hue 集成配置](#4. Hue 集成配置)
[4.1 修改 Hue 配置](#4.1 修改 Hue 配置)
[4.2 重启 Hue](#4.2 重启 Hue)
[4.3 界面验证](#4.3 界面验证)
[5. 脚本迁移与使用总结](#5. 脚本迁移与使用总结)
[场景 A:定时调度 / 生产脚本 (替代 hive -f)](#场景 A:定时调度 / 生产脚本 (替代 hive -f))
[场景 B:Hue 交互式查询](#场景 B:Hue 交互式查询)
[6. 故障排查汇总 (FAQ)](#6. 故障排查汇总 (FAQ))
适用环境 :CDH 6.3.2 / Spark 3.5.7 / Paimon 1.1.1 核心目标:在不破坏 CDH 原有 Hive/Spark 稳定性的前提下,通过旁路服务(Sidecar)模式部署 Spark 3.5,并对接 Hue 和 Beeline,实现对 Paimon 数据湖的读写支持。
1. 基础环境准备(权限与目录)
在启动服务前,必须先创建日志目录并配置正确的权限,否则会导致服务因无法写入日志而秒退。
执行节点 :部署 Spark Thrift Server 的节点(通常是 HiveServer2 所在节点,这里为 nd2)。 执行用户 :拥有 sudo 权限的用户(如 bigdata)。
bash
# 1. 创建 Spark Thrift Server 专用日志目录
sudo mkdir -p /var/log/spark3-thrift
# 2. 创建 Hive 操作日志目录 (修复 Beeline 无进度条警告)
sudo mkdir -p /var/log/hive/operation_logs
# 3. 将目录所有权移交给 hive 用户 (服务将以 hive 身份启动)
sudo chown -R hive:hive /var/log/spark3-thrift
sudo chown -R hive:hive /var/log/hive/operation_logs
# 4. 赋予读写权限
sudo chmod -R 755 /var/log/spark3-thrift
sudo chmod -R 755 /var/log/hive/operation_logs2. 封装启动脚本
我们需要创建一个封装好的脚本,解决环境变量隔离、日志路径重定向以及 YARN 资源限制问题。
创建脚本:
bash
sudo vi /opt/cloudera/parcels/CDH/bin/start-spark3-thrift.sh脚本内容(已包含内存优化与日志修正):
bash
#!/bin/bash
# ==================== 环境变量配置 ====================
# 指向外挂的 Spark 3.5.7 路径
export SPARK_HOME=/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/spark3
export SPARK_CONF_DIR=$SPARK_HOME/conf
# 指向 CDH 的 Hadoop/YARN 配置
export HADOOP_CONF_DIR=/etc/hadoop/conf
export YARN_CONF_DIR=/etc/hadoop/conf
# 【关键修正】强制将 Spark 内部日志和 PID 文件指向我们创建的有权限目录
# 否则会尝试写入 /opt/.../spark3/logs 导致权限不足报错
export SPARK_LOG_DIR=/var/log/spark3-thrift
export SPARK_PID_DIR=/var/log/spark3-thrift
# 脚本自身日志路径
LOG_DIR=/var/log/spark3-thrift
mkdir -p $LOG_DIR
echo "Starting Spark 3.5.7 Thrift Server..."
# ==================== 启动命令 ====================
# 参数说明:
# 1. hive.server2.thrift.port=10001 : 避开 CDH Hive 默认的 10000 端口
# 2. --driver/executor-memory 2g : 【关键修正】避免超过 CDH YARN 单容器最大内存限制 (通常为 4G 左右)
# 3. spark.sql.extensions... : 加载 Paimon 插件
exec $SPARK_HOME/sbin/start-thriftserver.sh \
--master yarn \
--deploy-mode client \
--hiveconf hive.server2.thrift.port=10001 \
--hiveconf hive.server2.thrift.bind.host=0.0.0.0 \
--driver-memory 2g \
--executor-memory 2g \
--executor-cores 2 \
--conf spark.sql.extensions=org.apache.paimon.spark.extensions.PaimonSparkSessionExtensions \
--conf spark.sql.catalog.paimon=org.apache.paimon.spark.SparkCatalog \
--conf spark.sql.catalog.paimon.metastore=hive \
--conf spark.sql.catalog.paimon.hadoop.conf.dir=/etc/hadoop/conf \
>> $LOG_DIR/start.log 2>&1赋权:
bash
sudo chmod +x /opt/cloudera/parcels/CDH/bin/start-spark3-thrift.sh3. 服务启动与验证
3.1 启动服务
必须使用 hive 用户启动,以确保有权限访问 HDFS 上的 Hive Warehouse 和本地日志目录。
bash
sudo -u hive /opt/cloudera/parcels/CDH/bin/start-spark3-thrift.sh
3.2 状态验证
启动通常需要 15-30 秒。
方式一:检查端口
bash
# 确认 10001 端口处于监听状态
sudo netstat -tulpn | grep 10001
方式二:查看日志 如果端口未启动,查看日志排查:
bash
tail -f /var/log/spark3-thrift/spark-hive-org.apache.spark.sql.hive.thriftserver.HiveThriftServer2*.out成功标志 :看到日志输出 Starting ThriftBinaryCLIService on port 10001。

方式三:YARN 界面
访问 http://<ResourceManager_IP>:8088,应看到名为 Thrift JDBC/ODBC Server 的任务状态为 RUNNING。

3.3 终端验证
执行命令如下:
bash
/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/spark3/bin/beeline -u "jdbc:hive2://nd2:10001/default" -n hive
sql
SHOW DATABASES;
use paimon;
# 默认表
show tables;
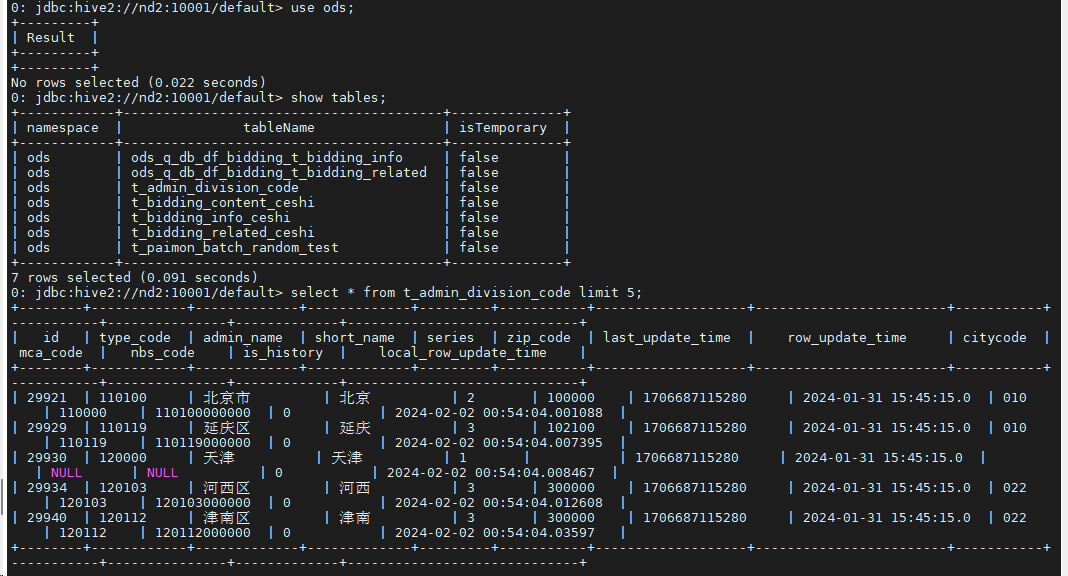
use ods;
show tables;
select * from t_admin_division_code limit 5;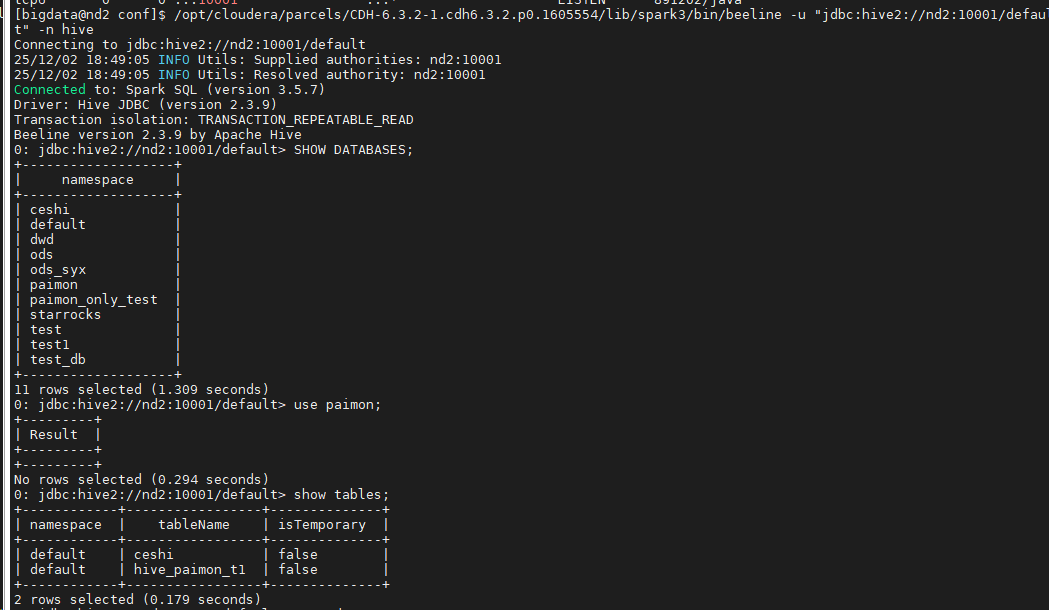
4. Hue 集成配置
为了让用户在 Hue 界面上无感使用 Spark 3.5,需要配置 Hue 通过 JDBC 连接到我们启动的 10001 端口。
4.1 修改 Hue 配置
-
登录 Cloudera Manager。
-
进入 Hue 服务 -> 配置 (Configuration)。
-
搜索
safety valve(安全阀)。 -
找到 Hue Service Advanced Configuration Snippet (Safety Valve) for hue_safety_valve.ini。
-
添加以下配置:
bash
[spark]
# 显示在 Hue 编辑器列表中的名称
display_name=Spark 3.5 SQL
# Spark Thrift Server 的地址
server_host=10.8.16.202
# Spark Thrift Server 的端口
server_port=10001
# 语言类型
interface=hiveserver2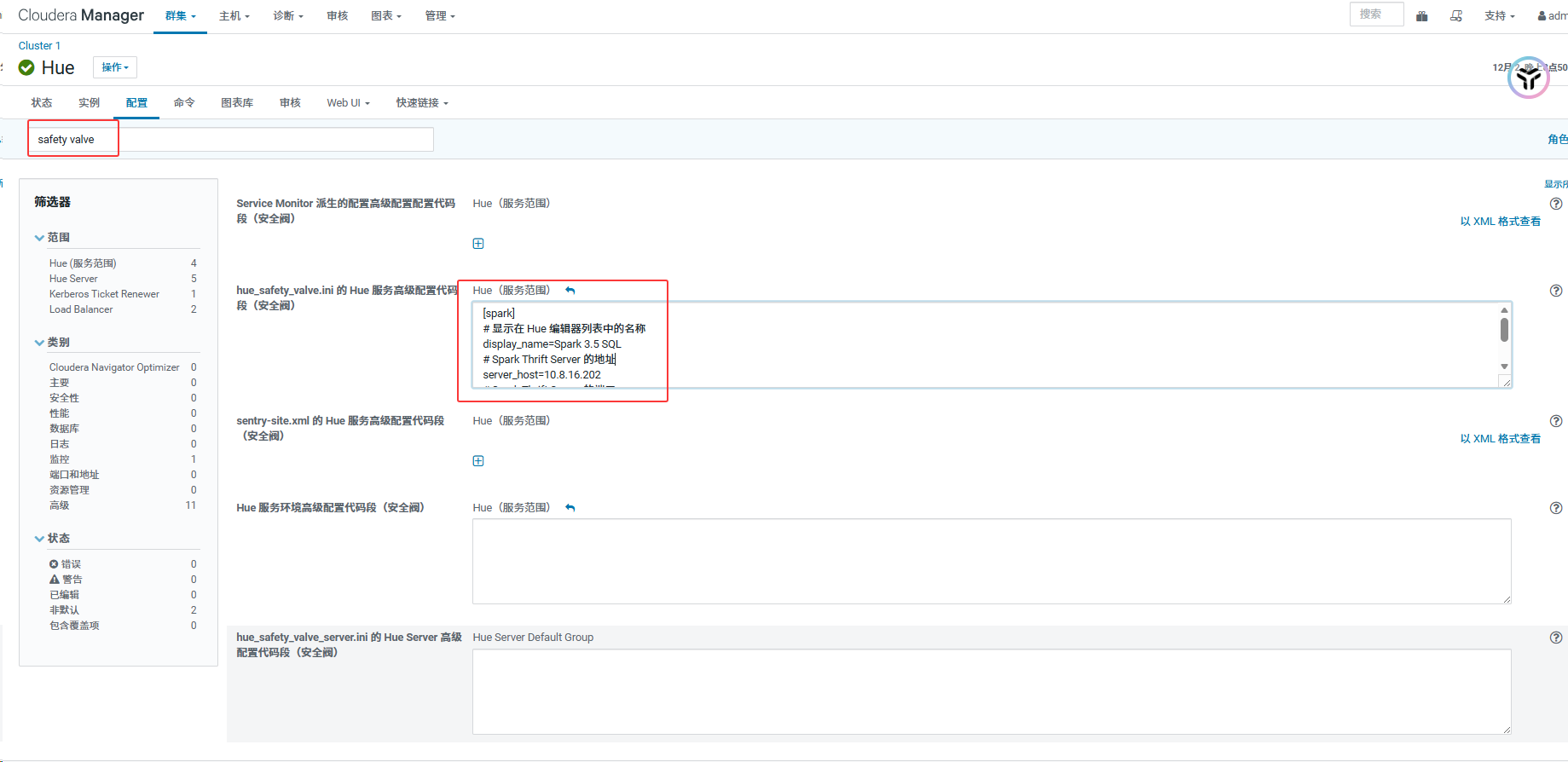
还有一种配置方式如下:
bash
[notebook]
[[interpreters]]
# 定义一个新的解释器组
[[[spark3sql]]]
# 在 Hue 编辑器菜单中显示的名称
name=Spark 3.5 SQL
# 接口类型 (必须是 hiveserver2,因为 STS 兼容 Hive 协议)
interface=hiveserver2
# 连接参数配置
# 请替换 10.x.xx.202 为部署 STS 的节点 IP
# 请替换 10001 为启动脚本中设置的端口
options='{"url": "jdbc:hive2://10.x.xx.202:10001/default", "driver": "org.apache.hive.jdbc.HiveDriver"}'但是上述命令在配置之后会出现hue重启失败,或者重启成功连接不上数据库的问题。在 Hue 4.3.0 (CDH 6.3.2) 的架构中,Spark 2.x(CDH自带)和 Spark 3.x(你外挂的)是完全物理隔离的进程。Hue 只是作为一个"客户端"去连接它们,它并不关心后端到底跑的是哪个版本的代码。
notebook 配置方式失败的真正原因 ,更多是归咎于 Hue 4.3.0 在 CDH 环境下的配置解析缺陷。
在 CDH 6.3.2 的 Hue 4.3.0 中,使用 notebook \[interpreters] 配合 options='{...}' JSON 字符串存在两个致命的兼容性陷阱:
-
CM 安全阀的转义灾难:
-
Cloudera Manager (CM) 会将你在网页上输入的"安全阀"内容注入到 hue_safety_valve.ini 文件中。
-
CM 对特殊字符(尤其是双引号 " 和单引号 ')的处理非常敏感。
-
当你输入 options='{"url": "..."}' 时,CM 可能会错误地转义引号,导致 Hue 的 Python 后端在读取配置文件时,解析出的 JSON 格式已损坏。Hue 读不懂这个连接字符串,自然就无法启动解释器,从而报错。
-
-
Hue 4.3.0 的 JDBC 驱动加载机制:
-
在 Hue 4.3.0 这个古老的版本中,notebook 动态解释器对 JDBC 驱动的加载路径有严格要求。
-
虽然我们指定了 driver="org.apache.hive.jdbc.HiveDriver",但通过动态配置方式加载时,Hue 有时无法在正确的 Classpath 下找到 CDH 预置的 Hive 驱动,或者无法初始化连接池。
-
结论 :报错不是因为 Spark 版本冲突,而是因为 配置文件的语法解析 和 驱动动态加载 在老版本 Hue 中极其不稳定。因此推荐使用**spark**的这种配置进行连接。
4.2 重启 Hue
保存更改后,在 CM 界面点击重启 Hue 服务。
4.3 界面验证
-
登录 Hue。
-
点击 Editor ,下拉菜单中应出现 "Spark 3.5 SQL"。
-
输入
SELECT version();执行,应返回 Spark 3.5.7 版本号。 -
输入
USE paimon; SHOW TABLES;验证 Paimon 连通性。
sql
SELECT 1;
-- 查看 Spark 版本 (仅 Spark 支持,Hive 会报错或返回不同内容)
SELECT version();
-- 这通常会返回当前 Spark Session 的各种配置
SET spark.app.id;
USE paimon;
use ods;
SELECT * FROM ods.t_admin_division_code LIMIT 5;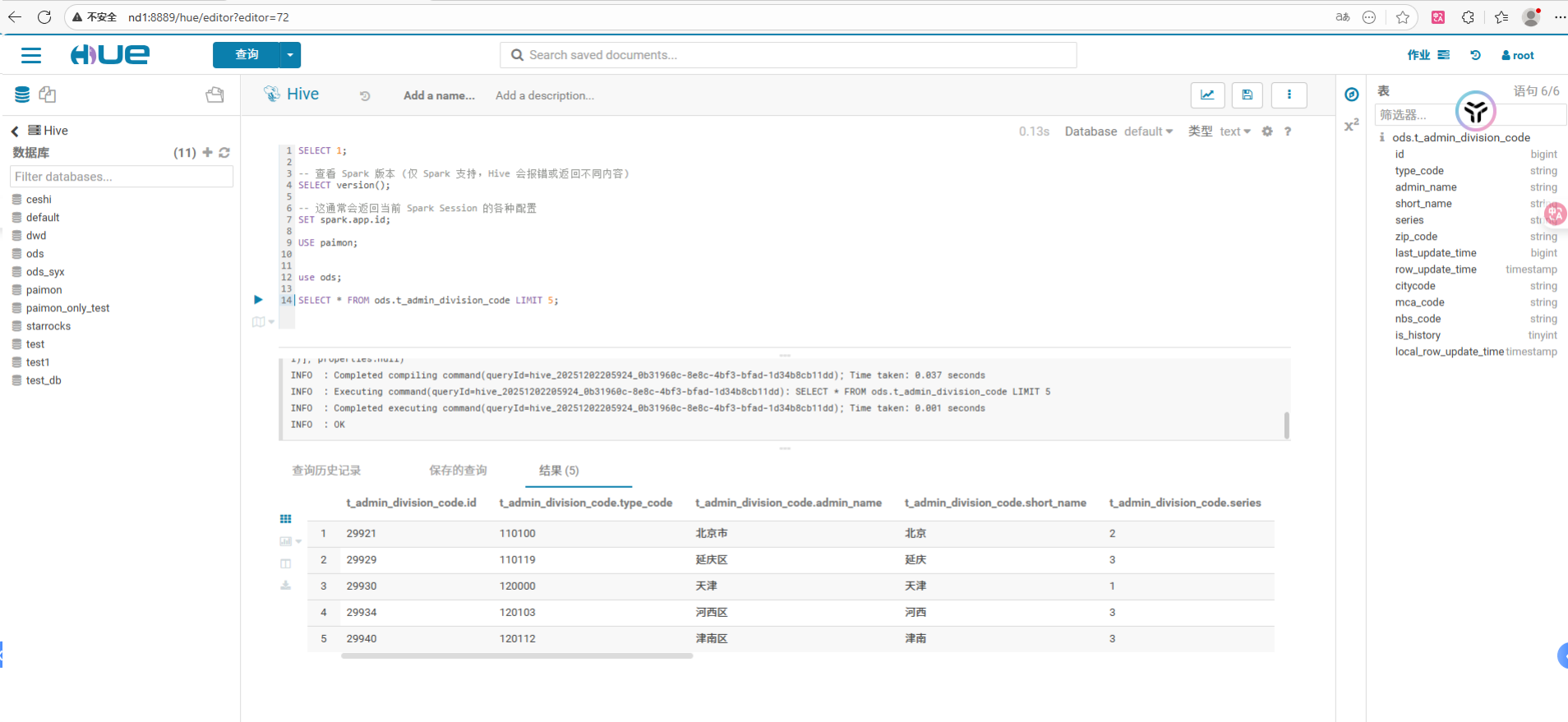
5. 脚本迁移与使用总结
由于 CDH 默认环境未变更,原有的 hive 命令依然指向旧版本。针对 .sql 脚本的调度,需采用以下替代方案。
场景 A:定时调度 / 生产脚本 (替代 hive -f)
强烈推荐使用 Spark 3 自带的 Beeline 连接 10001 端口,这比每次启动一个新的 Spark App 更快且资源利用率更高。下面是示例代码
bash
# 定义变量
SPARK3_BIN=/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/spark3/bin
STS_HOST=10.8.16.202
STS_PORT=10001
# 执行命令
$SPARK3_BIN/beeline \
-u "jdbc:hive2://${STS_HOST}:${STS_PORT}/default" \
-n hive \
-f /path/to/your_script.sql场景 B:Hue 交互式查询
直接在 Hue 界面选择 "Spark 3.5 SQL" 编辑器进行查询。
6. 故障排查汇总 (FAQ)
在部署过程中可能遇到的核心问题及解决方案:
| 现象 | 原因 | 解决方案 |
|---|---|---|
| 日志报错:mkdir: 无法创建目录 .../lib/spark3/logs | 权限不足 | 在启动脚本中添加 export SPARK_LOG_DIR=/var/log/spark3-thrift 强制重定向日志路径。 |
| 日志报错:Required executor memory ... above max threshold | YARN 资源超限 | 将启动脚本中的 --driver-memory 和 --executor-memory 从 4g 降为 2g 或 3g。 |
| Hue 编辑器不显示 Spark 3.5 | 配置格式错误 | 确保 hue_safety_valve.ini 使用 [notebook] -> [[interpreters]] 层级,而非 [spark]。 |
| Beeline 无执行进度条 | 缺少操作日志目录 | 确保已创建 /var/log/hive/operation_logs 并将所有权赋予 hive 用户。 |