🍊作者:计算机毕设匠心工作室
🍊简介:毕业后就一直专业从事计算机软件程序开发,至今也有8年工作经验。擅长Java、Python、微信小程序、安卓、大数据、PHP、.NET|C#、Golang等。
擅长:按照需求定制化开发项目、 源码、对代码进行完整讲解、文档撰写、ppt制作。
🍊心愿:点赞 👍 收藏 ⭐评论 📝
👇🏻 精彩专栏推荐订阅 👇🏻 不然下次找不到哟~
🍅 ↓↓文末获取源码联系↓↓🍅
基于大数据的全面皮肤病症状数据可视化分析系统-功能介绍
本项目"【python大数据毕设实战】全面皮肤病症状数据可视化分析系统"是一个旨在运用前沿大数据技术对海量皮肤病医疗数据进行深度挖掘与直观展示的综合分析平台。系统以后端Python语言为核心,采用轻量高效的Django框架搭建Web服务,并深度融合了Hadoop与Spark分布式计算框架来应对海量数据的处理挑战。原始数据存储于MySQL数据库中,系统通过Spark SQL和强大的DataFrame API对包含患者年龄、性别、肤色、疾病类型、严重程度、病程、治疗历史等十多个维度的askin_disease_dataset.csv数据集进行高效清洗、转换与聚合分析。在数据处理层面,系统特别针对连续数值(如年龄、病程)进行智能分箱,并对有序分类变量(如严重程度)进行逻辑排序,确保了分析结果的科学性。最终,系统将16个核心分析维度的结果数据,通过API接口精准推送至前端。前端界面则基于Vue框架,结合ElementUI组件库与功能强大的Echarts可视化图表库,将复杂的数据关系以动态、交互式的图表形式呈现,为研究者提供了一站式的数据洞察与决策支持工具。
基于大数据的全面皮肤病症状数据可视化分析系统-选题背景意义
选题背景 如今,皮肤病已经成为困扰相当一部分人群的常见健康问题,其种类繁多、成因复杂,传统的诊断与研究方式在很大程度上依赖于医生的个人经验,这其中难免会带有一些主观性。随着信息化技术的发展,大量的临床诊疗数据被记录下来,这些数据其实就像一个尚未被充分挖掘的宝库,里面隐藏着关于皮肤病发生、发展及治疗反应的深层规律。大家也知道,单纯依靠人力去梳理成千上万条病历记录,既耗时又费力,还容易出错。大数据技术的出现,正好为解决这个难题提供了全新的思路。本项目就是想在这方面做个小小的尝试,利用Hadoop和Spark这样成熟的分布式计算框架,去高效处理和分析皮肤病症状数据,希望能够从看似杂乱的数据中,发现一些以往难以察觉的关联性,为更科学的认知和研究皮肤病提供一种数据驱动的新视角。 选题意义 这个系统的实际意义,可以从几个层面来看。对于临床医生来说,系统通过多维度的可视化图表,比如不同年龄段高发的皮肤病类型、不同疾病在各身体部位的分布规律等,能够帮助他们快速建立起宏观的认知,辅助他们进行更精准的诊断。对于医学研究者,系统对治疗效果与病程、严重程度之间关系的深入分析,可能会为评估现有疗法或探索新治疗方案提供有价值的线索。虽然它只是个毕业设计,但至少提供了一个完整的技术验证,展示了如何将大数据技术真正应用于一个具体的医疗场景中。对于公共卫生领域,了解特定人群(如不同肤色)的疾病分布情况,有助于制定更具针对性的健康科普和预防策略。总的来说,本项目不仅是一次技术上的综合实践,更重要的是它搭建了一个连接数据与医学洞察的桥梁,其分析结果具备一定的参考价值。
基于大数据的全面皮肤病症状数据可视化分析系统-技术选型
大数据框架:Hadoop+Spark(本次没用Hive,支持定制) 开发语言:Python+Java(两个版本都支持) 后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持) 前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery 详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy 数据库:MySQL
基于大数据的全面皮肤病症状数据可视化分析系统-图片展示
基于大数据的全面皮肤病症状数据可视化分析系统-图片展示
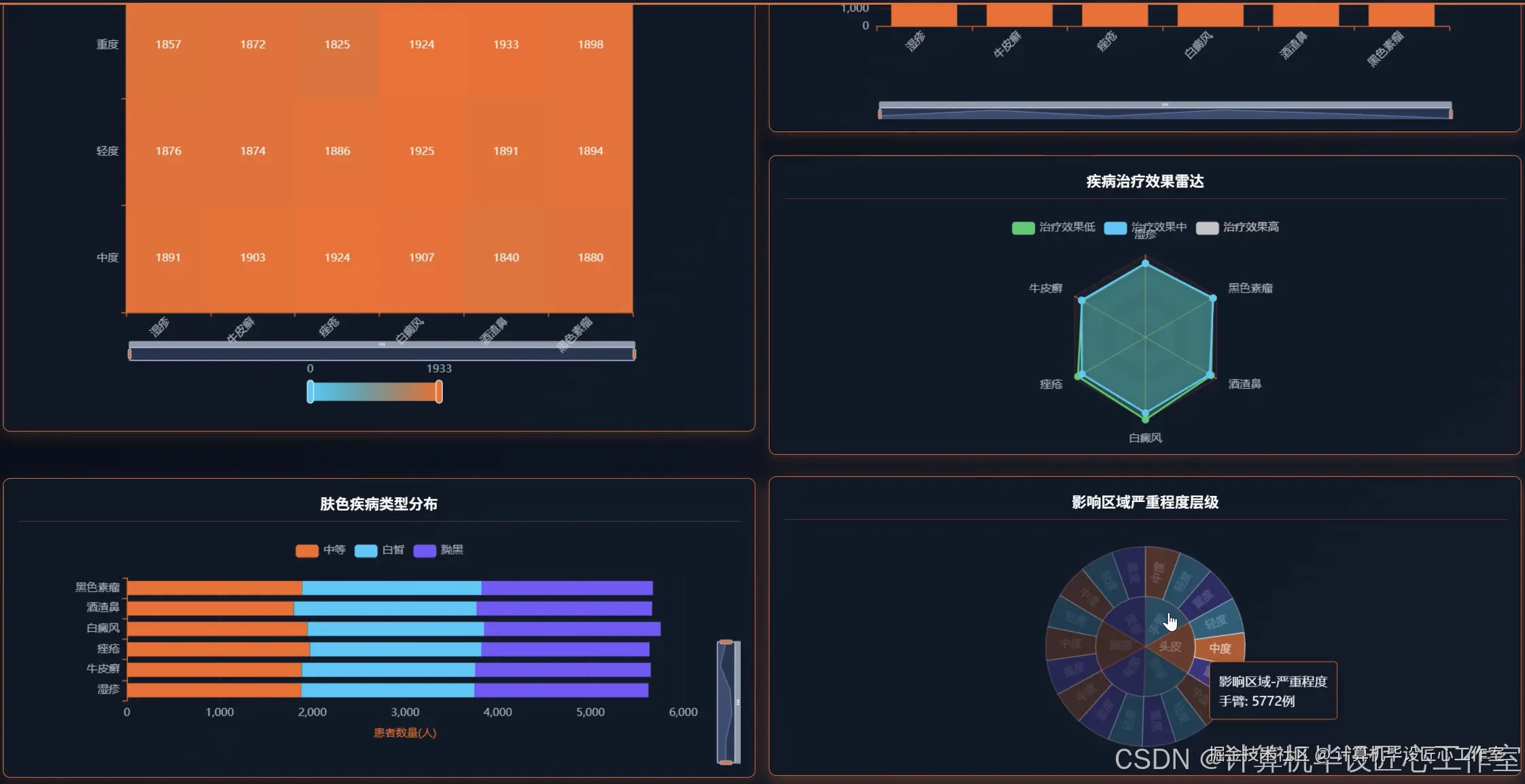
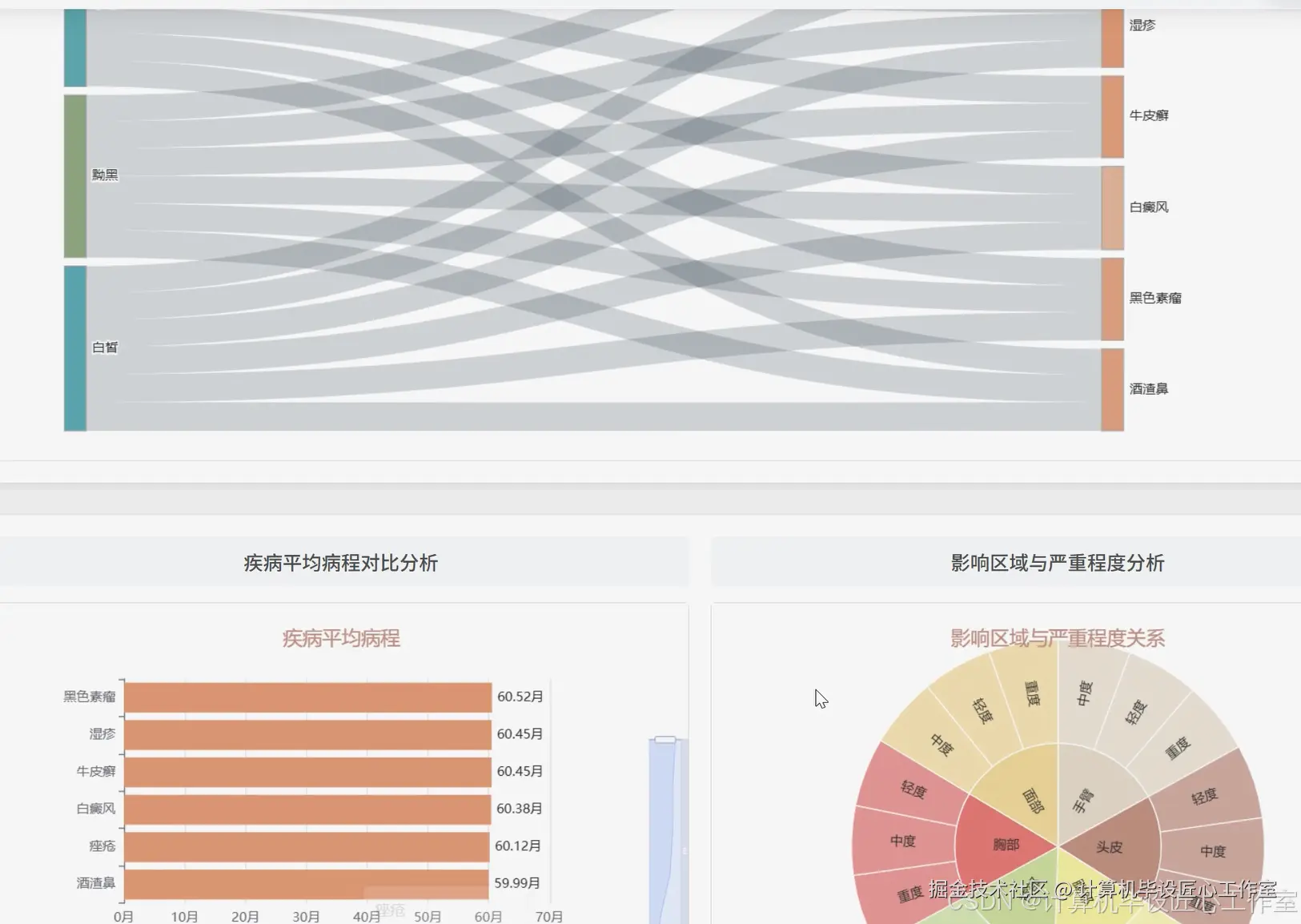
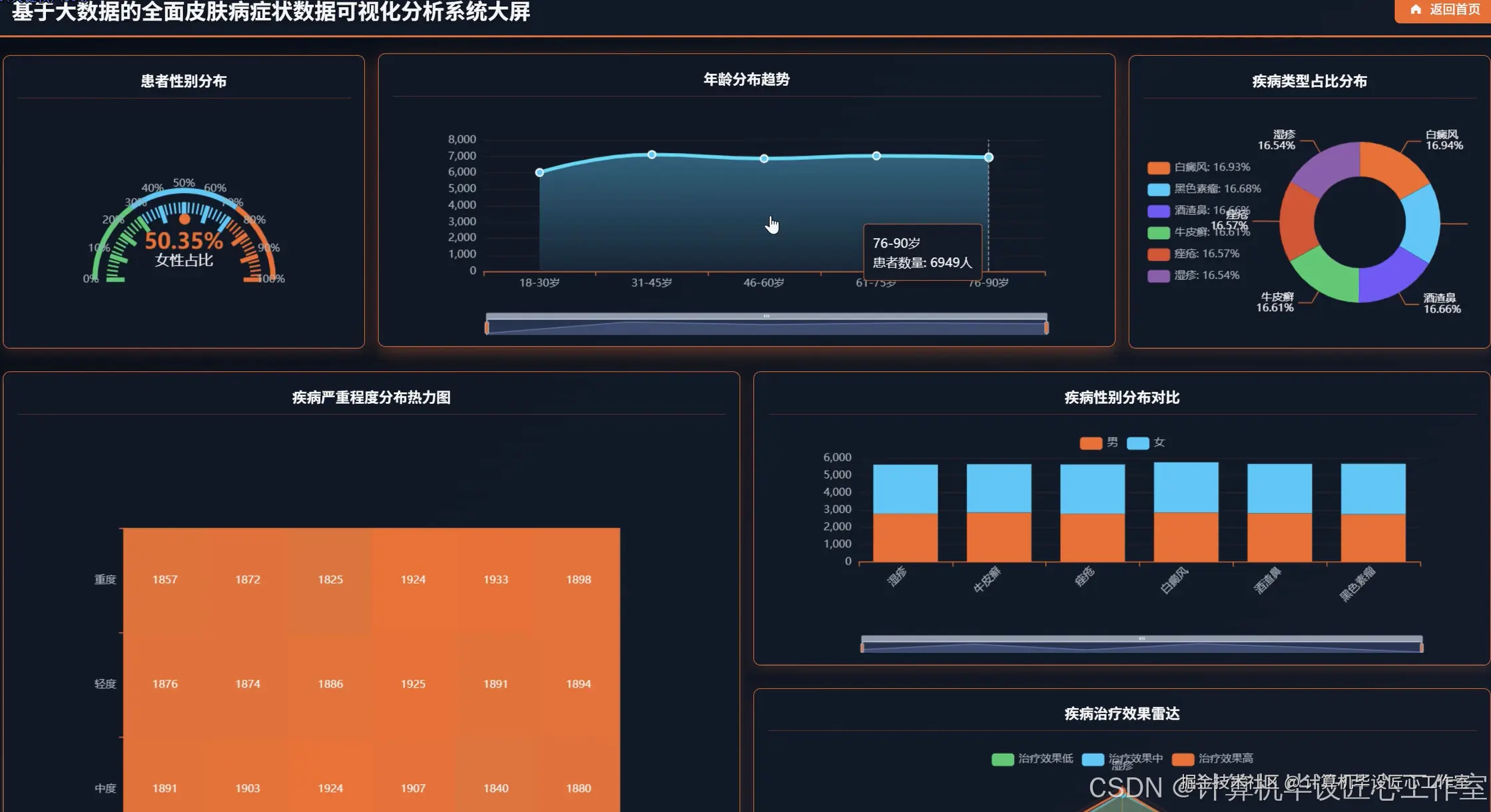
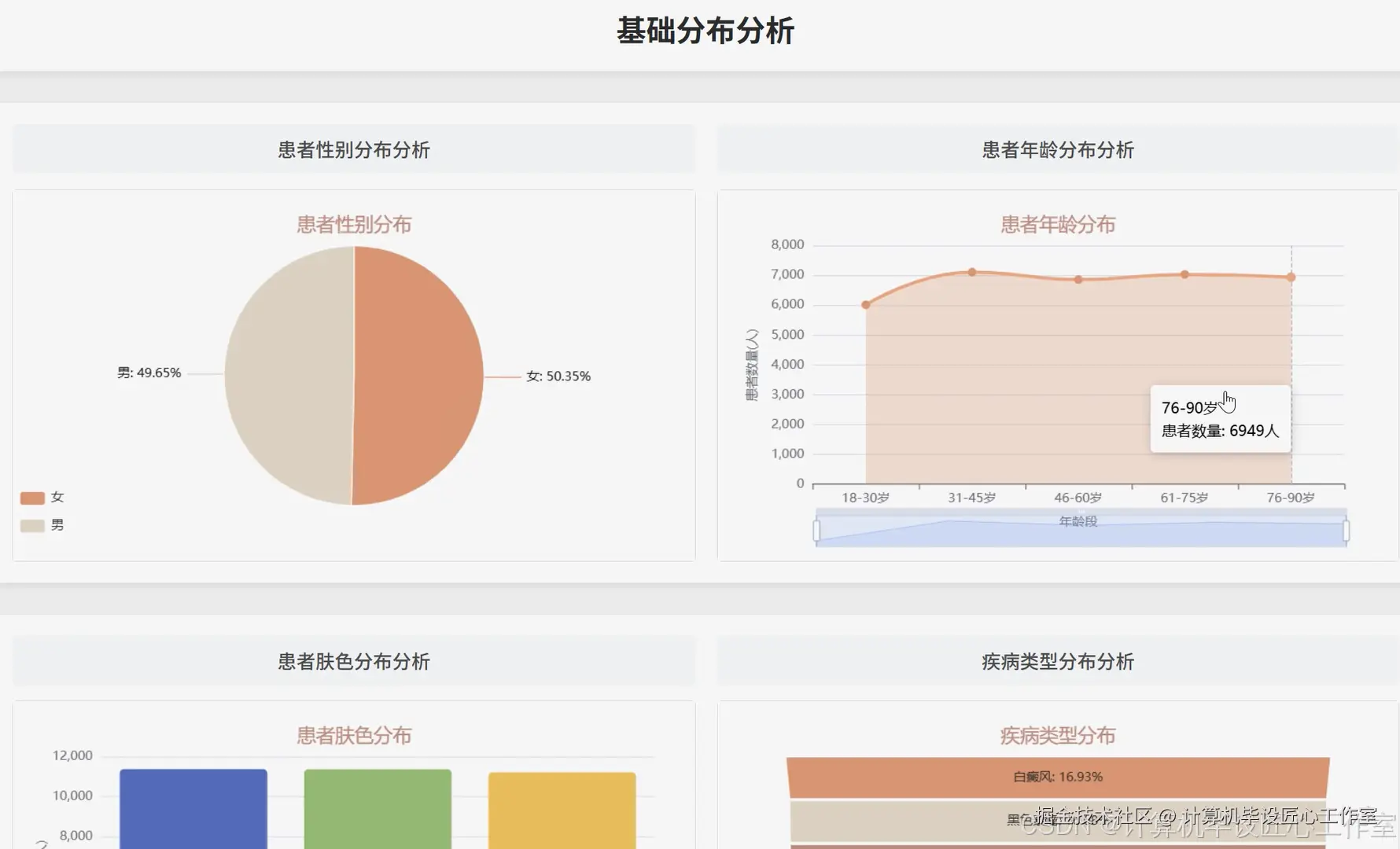
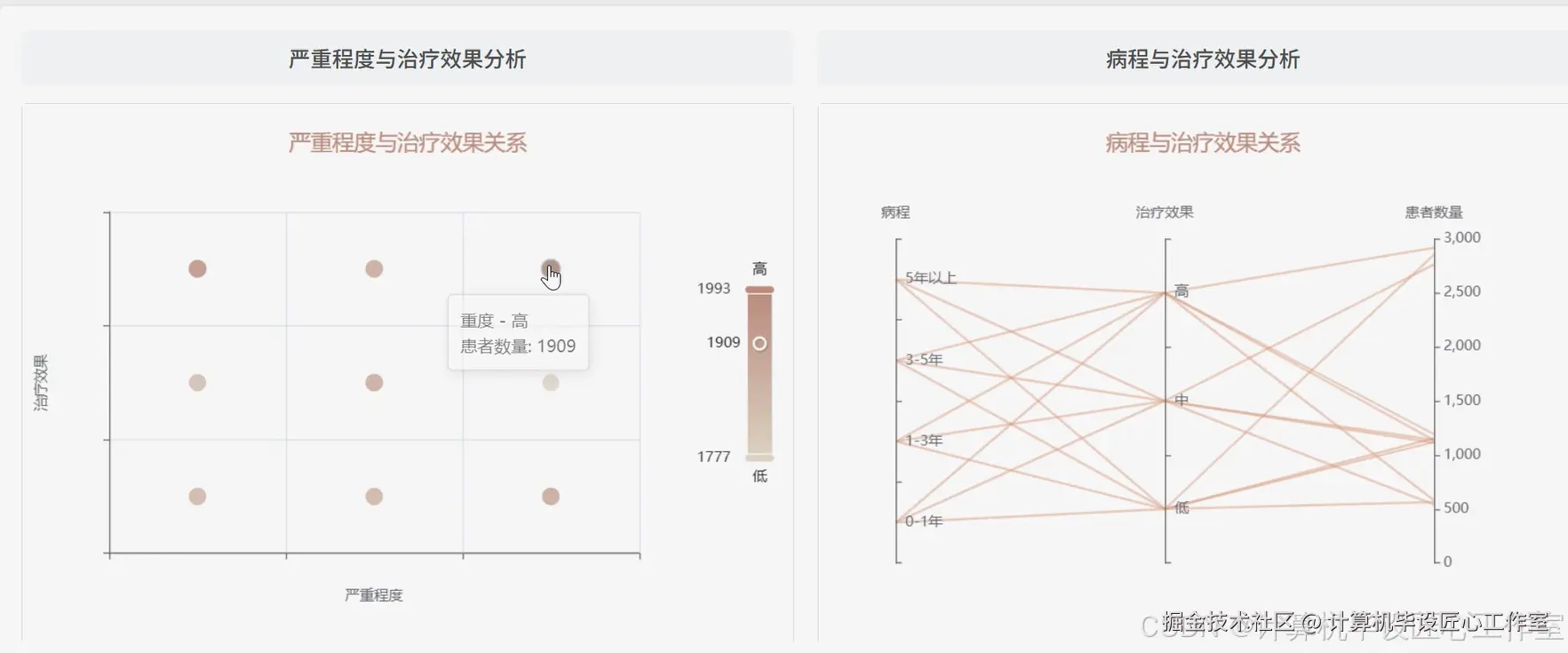
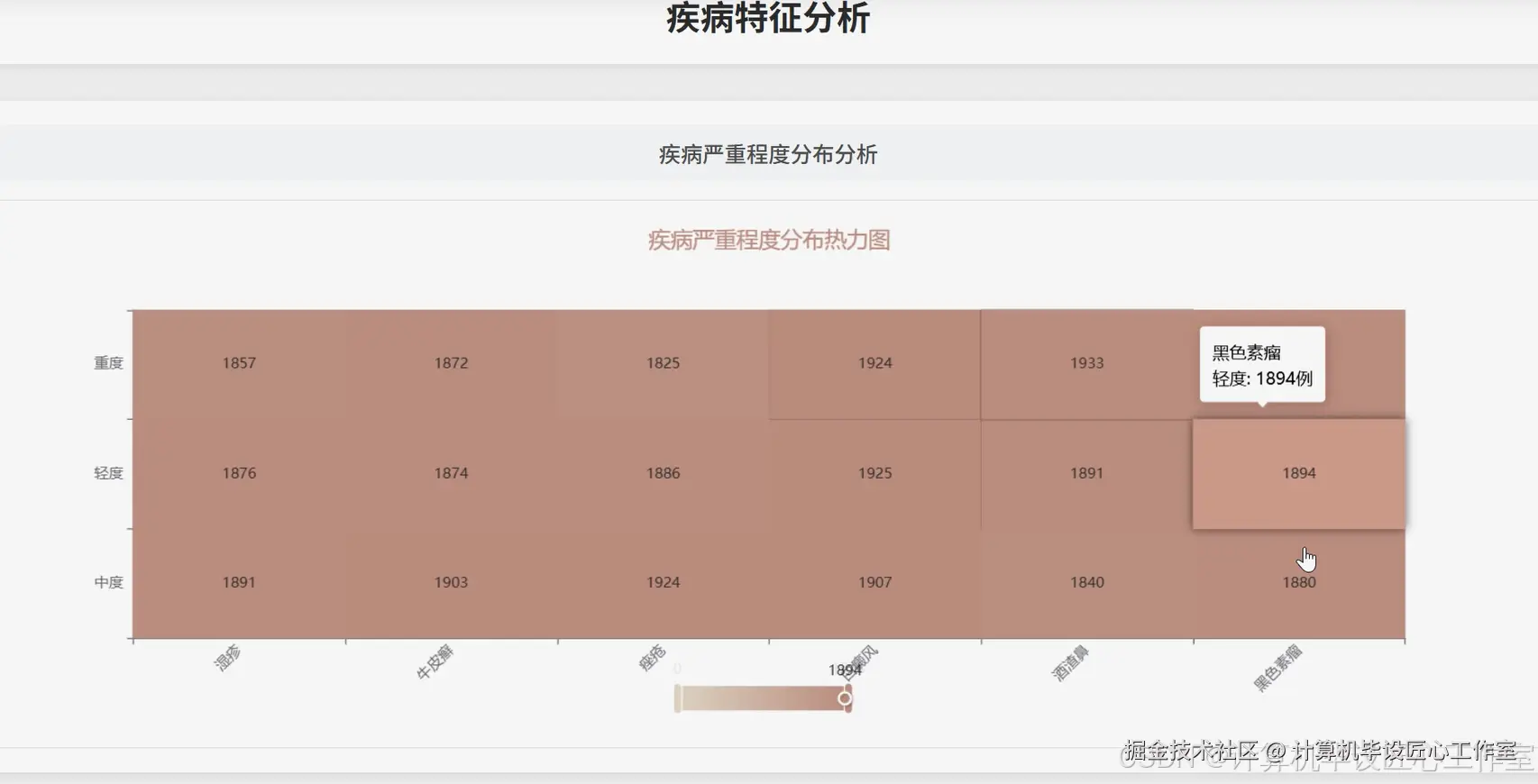
基于大数据的全面皮肤病症状数据可视化分析系统-代码展示
python
from pyspark.sql import SparkSession, functions as F, Window
spark = SparkSession.builder.appName("SkinDiseaseAnalysis").getOrCreate()
df = spark.read.csv("askin_disease_dataset.csv", header=True, inferSchema=True)
def analyze_age_distribution(df):
age_grouped_df = df.withColumn("age_group", F.when((F.col("Age") >= 18) & (F.col("Age") <= 40), "青年(18-40岁)")
.when((F.col("Age") >= 41) & (F.col("Age") <= 65), "中年(41-65岁)")
.when((F.col("Age") >= 66) & (F.col("Age") <= 90), "老年(66-90岁)")
.otherwise("未知"))
result_df = age_grouped_df.filter(F.col("age_group") != "未知").groupBy("age_group").agg(F.count("Patient_ID").alias("患病人数"))
result_df = result_df.orderBy(F.col("age_group").asc())
result_df.show()
return result_df
def analyze_severity_by_disease(df):
disease_severity_count = df.groupBy("Disease_Type", "Severity").agg(F.count("Patient_ID").alias("count"))
window_spec = Window.partitionBy("Disease_Type")
disease_total = disease_severity_count.withColumn("total_count", F.sum("count").over(window_spec))
result_df = disease_total.withColumn("percentage", F.format_number(F.col("count") / F.col("total_count") * 100, 2))
result_df = result_df.select("Disease_Type", "Severity", "count", "percentage")
result_df = result_df.orderBy(F.col("Disease_Type").asc(), F.col("Severity").asc())
result_df.show()
return result_df
def analyze_duration_vs_effectiveness(df):
treated_df = df.filter(F.col("Previous_Treatment") == "Yes")
duration_grouped_df = treated_df.withColumn("duration_group", F.when((F.col("Duration") >= 1) & (F.col("Duration") <= 6), "短期(1-6月)")
.when((F.col("Duration") >= 7) & (F.col("Duration") <= 24), "中期(7-24月)")
.when((F.col("Duration") > 24), "长期(>24月)")
.otherwise("未知"))
valid_df = duration_grouped_df.filter(F.col("duration_group") != "未知")
pivot_df = valid_df.groupBy("duration_group").pivot("Treatment_Effectiveness", ["Low", "Moderate", "High"]).count().na.fill(0)
result_df = pivot_df.withColumn("总计", F.col("Low") + F.col("Moderate") + F.col("High"))
result_df = result_df.orderBy(F.col("duration_group").asc())
result_df.show()
return result_df基于大数据的全面皮肤病症状数据可视化分析系统-结语
👇🏻 精彩专栏推荐订阅 👇🏻 不然下次找不到哟~
🍅 主页获取源码联系🍅