目录
- 引言
- [一、OpenClaw 记忆系统工作原理](#一、OpenClaw 记忆系统工作原理)
-
- [1、 记忆存储:文件即记忆](#1、 记忆存储:文件即记忆)
- [2、 记忆检索:混合搜索](#2、 记忆检索:混合搜索)
- [3、 上下文管理:自动压缩与防丢失](#3、 上下文管理:自动压缩与防丢失)
引言
前篇文章《初探来会会OpenClaw这只龙虾》我们介绍了OpenClaw 的整体原理和基本运行。作为一个合格的AI助理Agent,必然具备对用户的习惯了解技能。今天我们就对其用户行为记忆的机制进行简单的探究,也是可以作为我们实现各种服务类型的Agent智能体的长期记忆机制的方案借鉴,比如客服系统、问答系统对用户特征、用户习惯的记录以及一对一风格服务等等。

一、OpenClaw 记忆系统工作原理
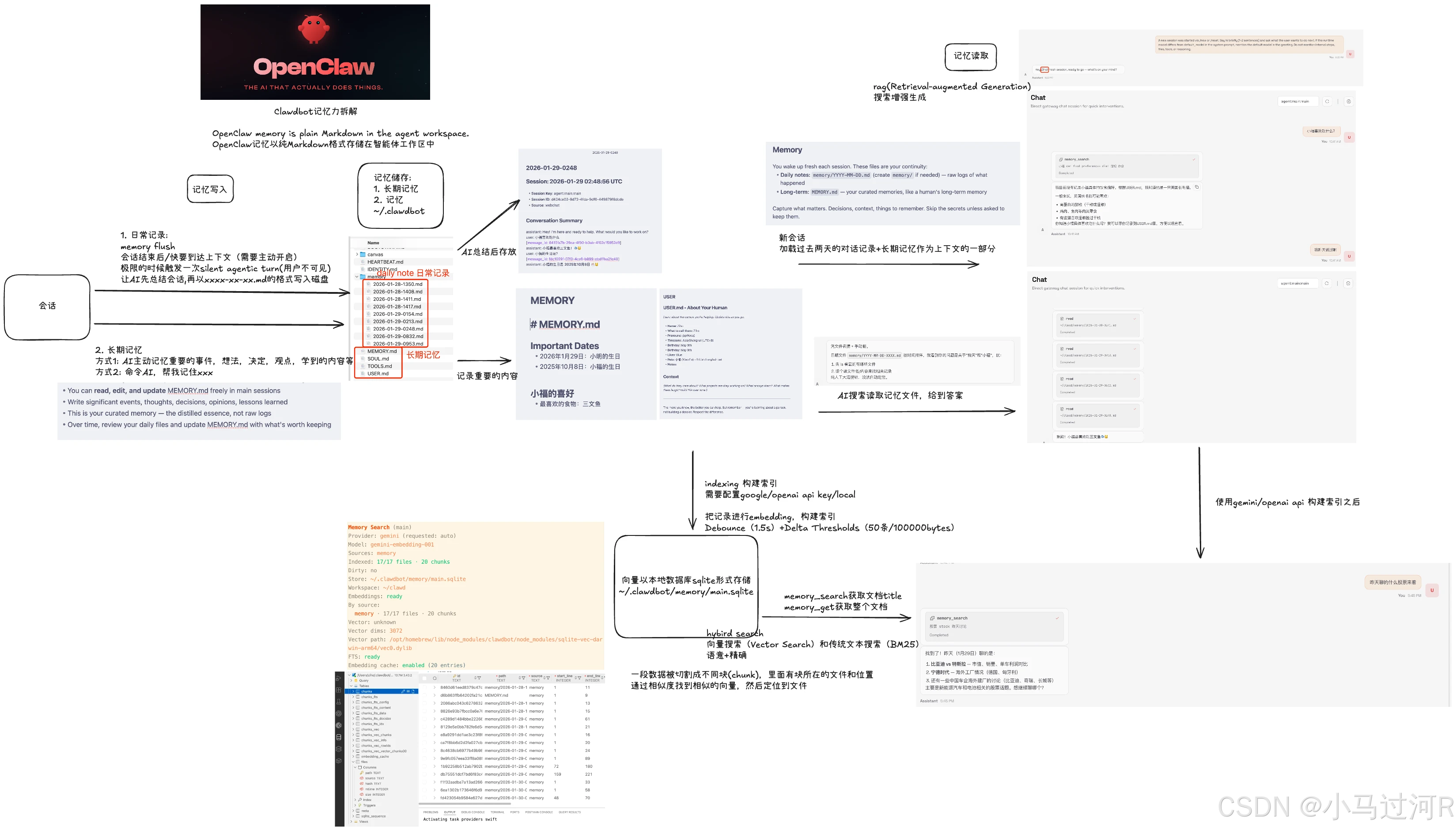
OpenClaw 记忆系统其核心创新在于采用了一种透明、可控制的记忆系统,与大多数将上下文存储在专有数据库中的 AI 记忆系统不同。
1、 记忆存储:文件即记忆
OpenClaw 将所有记忆内容写入磁盘上的普通 Markdown 文件,用户可以使用 Git 打开、编辑和版本控制这些文件。记忆文件默认存储在 ~/.openclaw/workspace 目录下,分为两层:
- 长期记忆 (MEMORY.md):保存持久的事实、决策、偏好和重复模式。在私有会话开始时,其内容会自动加载到系统提示词中(出于隐私考虑,不用于群组聊天)。
- 每日日志 (memory/YYYY-MM-DD.md):用于记录当天的运行上下文、进行中的任务和对话笔记。与 MEMORY.md 不同,每日日志不会自动注入提示词,AI 在需要时通过内置工具按需检索。
2、 记忆检索:混合搜索
将记忆存储在文件中很简单,困难的是在需要时找到正确的记忆。OpenClaw 使用混合搜索来结合两种方法的优势:
- 向量搜索 (语义搜索,权重70%):将记忆文本分块并转换为数字嵌入,通过计算余弦距离来查找语义上最接近查询的文本块。这能捕获"意义"上的匹配。
- 关键词搜索 (BM25,权重30%) :使用 SQLite 的 FTS5 模块进行全文搜索,擅长处理精确术语、特定名称和技术术语的匹配。
系统并行运行两次搜索,将结果池合并,并使用加权评分(向量分数×0.7 + 关键词分数×0.3)进行排序,最终返回最相关的几个结果给 AI。
3、 上下文管理:自动压缩与防丢失
AI 模型有上下文窗口限制。当会话接近此限制时,OpenClaw 会触发自动压缩流程:
- 检测:监控令牌使用量,达到阈值时触发压缩。
- 压缩前记忆刷新:在压缩前,系统会静默要求 AI 将任何重要内容写入记忆文件(MEMORY.md 或每日日志),以防止数据丢失。
- 压缩:压缩对话历史,在减少冗余的同时保留关键信息和决策。
- 重试 :使用压缩后的历史记录重新处理用户的原始请求。
如果压缩本身失败,系统会回退到会话重置(最后手段),但之前已刷新保存的记忆会在 Markdown 文件中得以保留。
总结:OpenClaw 的记忆系统通过将记忆存储在可读、可编辑的 Markdown 文件中,并利用混合搜索技术进行高效检索,实现了对 AI 记忆的完全透明和用户控制。它通过自动压缩机制智能管理上下文限制,并在设计上优先考虑隐私和离线可用性,为希望深度掌控其 AI 助手行为的用户提供了一个强大而实用的解决方案。
以上整体的原理可以借用一张视频博主的流程图来总结。
相关文章:
openclaw官方文档(openclaw 的长期记忆实现):https://docs.openclaw.ai/zh-CN/concepts/memory
OpenClaw 的记忆机制:https://www.hubwiz.com/blog/how-openclaw-memory-works/