【论文阅读】SegEarth-OV:面向遥感图像的免训练开放词汇分割
SegEarth-OV: Towards Training-Free Open-Vocabulary Segmentation for Remote Sensing Images
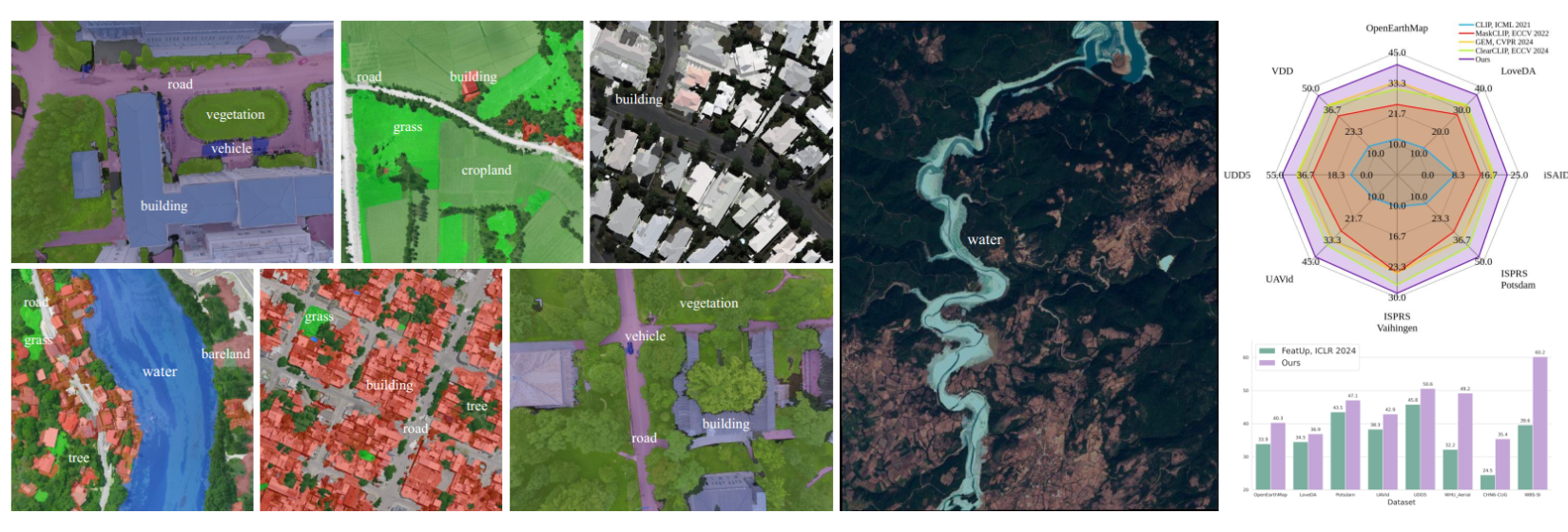
SegEarth-OV在遥感图像开放词汇语义分割上的可视化和性能。我们对17个遥感数据集(包括语义分割,建筑物提取,道路提取和洪水检测任务)进行了评估
SegEarth-OV始终生成高质量的分割掩模
像素级解译是遥感图像应用的重要方面,但目前普遍存在的局限性是需要大量的人工标注
本文尝试将开放词汇语义分割(OVSS)引入到遥感图像中
遥感图像对低分辨率特征的敏感性,在预测模板中会出现目标形状失真和边界拟合不佳的情况
我们提出了一种简单通用的上采样器Simplified Up,以无需训练的方式恢复深层特征中丢失的空间信息
CLIP中局部块标记对CLS标记的异常响应的观察,我们提出了一种简单的减法运算来减少斑块标记的全局偏差
在17个遥感数据集上进行了广泛的实验,包括语义分割 ,建筑物提取 ,道路检测 和洪水检测任务
一、介绍
遥感影像改变了人类观察和认识地球的方式,使我们能够监测土地覆盖/利用类型,有效应对自然灾害
在联合国发布的17个可持续发展目标(SDG)1中,遥感图像可以为多个目标提供重要的数据支持,包括"零饥饿"、"清洁水和卫生"、"工业、创新和基础设施"、"气候行动"、"陆地生命"等
与自然图像相比,它涉及更多样化的空间分辨率(从厘米到公里)、时间维度(从小时到几十年)和对象视角(头顶和定向)。
原始遥感图像可从各种来源获得(例如,QuickBird,WorldView,Landsat,Sentinel),但由于昂贵的人工成本,获得大规模标签仍然是一个挑战
OpenStreetMap 19是一种流行的解决方案,旨在创建一个可自由使用、可编辑和可共享的世界地图
视觉语言模型(VLM)的兴起,以其开放词汇语义分割(OVSS)的能力给我们带来了新的启示
针对自然图像设计的解在遥感图像上是次优的,一个值得注意的现象是在预测掩模中存在失真的目标形状和不拟合的边界,如图2所示。

根据经验,我们认为这些问题主要是由于特征分辨率过低
CLIP 51的特征图被下采样到原始图像的1/16(ViT-B/16)提出了一种简单通用的特征上采样器SimFeatUp
该算法的训练目标是在少量的未标记图像上重建内容不变的高分辨率特征,训练后可以对任意的遥感图像特征进行上采样,
CLIP是在图像级训练的
我们发现,一个简单的局部块特征和全局特征的减法运算可以有效地减少全局偏差
贡献:
- 我们提出了Simplified Up,一个用于无训练OVSS的通用特征上采样器,它可以对低分辨率(LR)特征进行鲁棒上采样,并保持与图像内容的语义一致性
- 提出了一种非常简单和直接的方法来减轻CLIP的全局偏差问题,即执行本地和全局令牌的减法运算
- 我们最终提出的模型名为SegEarth-OV,在17个遥感数据集上实现了最先进的性能,包括语义分割,建筑物提取,道路提取和洪水检测任务
## 二、联系工作
Vision-Language Model
最近,基础模型,特别是视觉语言模型,为计算机视觉领域注入了活力
一个显著的进步是对比语言视觉预训练,即CLIP 51,它巧妙地弥合了图像和自然语言之间的差距
通过在多模态嵌入空间中使用大量数据进行训练,CLIP获得了强大的迁移能力,实现零射击学习的飞跃
相关研究逐渐涌现,从数据10,58,72,75,训练14,33,75或模型31,32方面
CLIP只关注全局CLS令牌,即使可以生成patch token,它们也不可避免地受到全局偏差的污染
出现了几种遥感VLM,它们使一般VLM适应遥感上下文36,49,66,77]或挖掘遥感数据的特征21,50。
Supervised semantic segmentation
语义分割的目的是在像素级上区分图像。解码器作为分割模型的重要组成部分,能够将LR特征图上采样为HR预测
例如,UNet 55,UperNet 71,Semantic FPN 25,MaskFormer 9等。一些作品37,40,80专注于动态,可学习的上采样运算符
然而,本文所提出的Simplified Up算法是基于Simplified Up算法的,它能够在不使用任何标签的情况下显著地改善OVSS
Open-Vocabulary Semantic Segmentation
由于VLM在图像分类中表现出显著的零触发推理,这自然扩展到语义分割
它们使分割管道能够识别可见和不可见的类别
用户可以使用提示词汇分割图像中的几乎任何类别
我们将当前基于CLIP的OVSS方法分为两组:需要训练和无需训练
一些作品16,42,48,52试图训练一个本地化感知的CLIP,它可以自然地进行密集预测
其他作品[11,13,30,38,73,选择CLIP的预训练参数的子集和/或将有限数量的可训练参数引入到冻结的CLIP中,即,微调CLIP以适应对基类的密集预测。
无需训练的OVSS方法强调利用CLIP的固有定位能力,对特征或结构进行有限的调整
MaskCLIP 79率先在CLIP的图像编码器的注意力池层删除查询和关键投影
- 后续研究3,28,34,63充分探索了自我注意力(即qq,k-k或v-v自我注意力),这些修改在一定程度上减轻了CLIP的噪声激活和空间不变感知
- 另一个流2,23,56,60是两阶段方法,该方法首先生成类别不可知的掩码建议,然后对掩码进行分类
关注的是遥感图像的内在特征,而不是自然图像的一般属性
与以往的方法不同,我们关注的是遥感图像的内在特征,而不是自然图像的一般属性。唯一的同期工作是6,但它需要训练,如11,74。
我们的SimplyUp组件,虽然它需要预先在一些仅图像的数据上进行训练,但这个过程独立于语义分割过程
训练的权重可以用于几乎任何遥感数据(就像其他作品中的基础模型2,29),因此我们的方法仍然可以被视为一种无训练方法
三、Method
CLIP
在基于ViT的CLIP中,图像编码器由一系列的Transformer块组成
前向过程可以公式化为
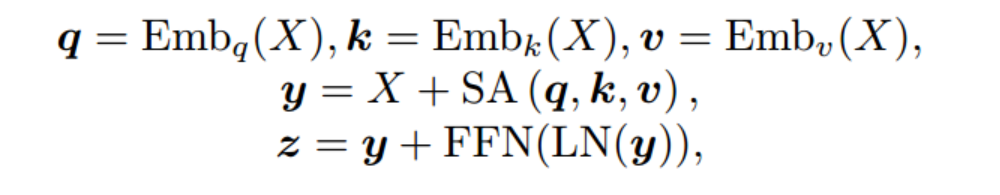
在CLIP训练期间,CLIP的output_cls用于图像级学习
而在OVSS推理期间,O1:hw + 1用于块级预测(也就是后续的Patch token用于分割任务)
FeatUp
FeatUp旨在训练一个模型无关的上采样器。它通过一个可学习的上采样器σ↑对来自冻结骨干网络的LR特征O1:hw + 1执行上采样操作
JBU将σ↑实例化为堆叠的参数化JBU算子
对于权重生成,JBU考虑了两个因素,即相邻元素与指导特征中的中心元素之间的相似性和距离,对应于内核krange和kspatial
SimFeatUp
OVSS为一般上采样器提供了一个很好的训练范例,但它缺乏对免训练设置的考虑,导致它对于OVSS任务不是最佳的
重新采样的目标是最小化原始LR特征和上下采样后的LR特征
因此在这种弱约束的情况下,上下采样过程变成了黑盒,并且不能保证中间HR特征是完整的并且与原始图像在内容上一致
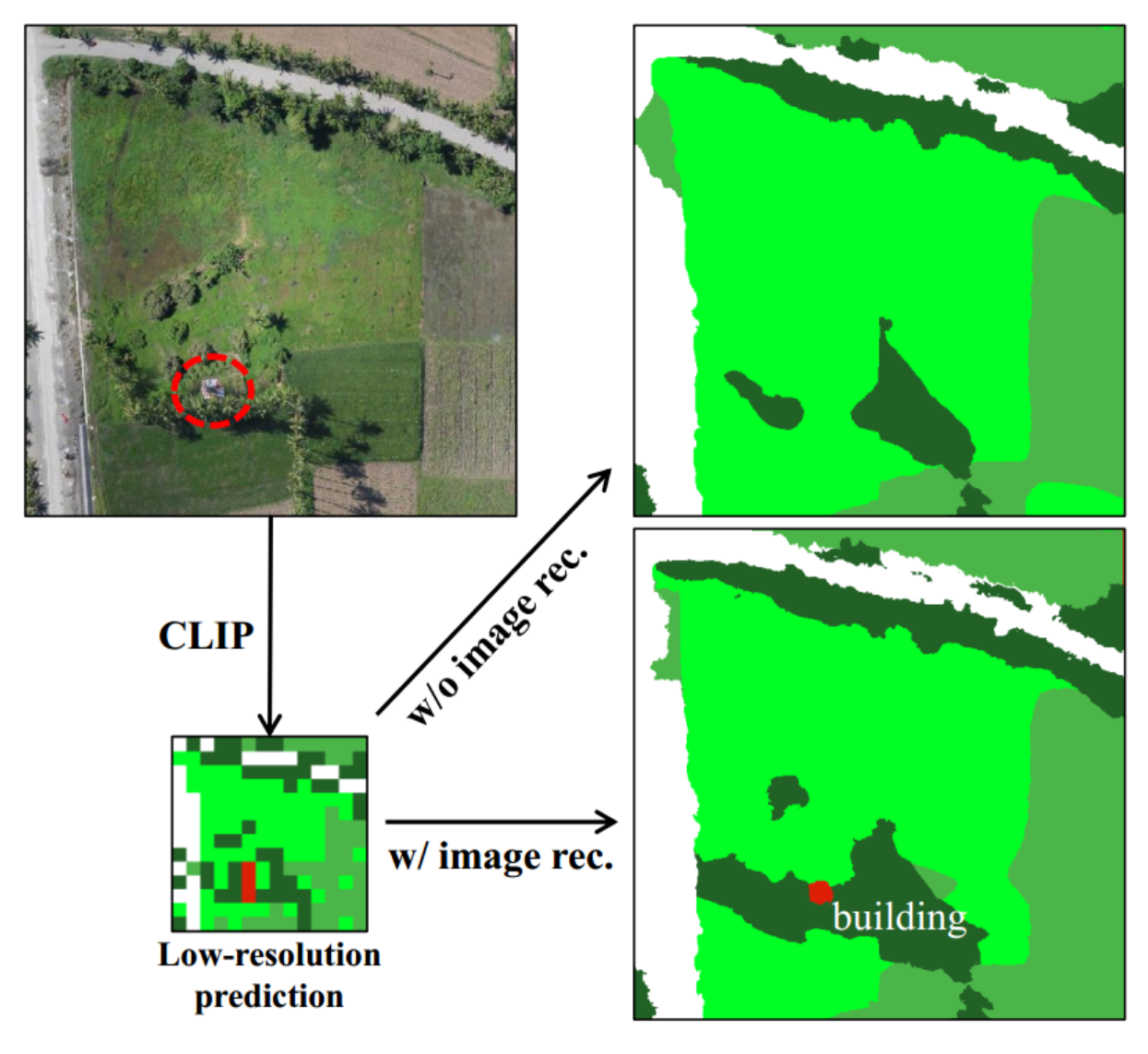
有和没有图像重建损失的比较(等式(4))。LR预测直接使用CLIP的输出获得(没有双线性插值)。颜色:建筑物、树木、农田、草地
其中原始图像中的一个小建筑物在LR预测中存在,但在HR预测中消失
引入了一个额外的图像重建损失来约束HR特征:
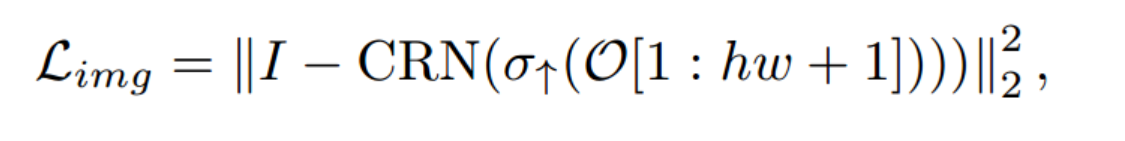
CRN是一个非常轻量级的网络,它接收HR特征作为输入并重建原始图像
CRN由两个带有激活的2D卷积层和一个Tanh激活层组成,其中Tanh层被设计为将输出限制为-1,1
然而,在无训练的OVSS中,如第2节所述,自我注意力导致较差的性能
中的SA替换为其他模块,并直接对O1:hw+ 1会导致训练和推理之间的不匹配。受此启发,我们建议在更早的层上采样CLIP特征
我们保留投影层。最终,需要上采样的特征O′可以公式化为
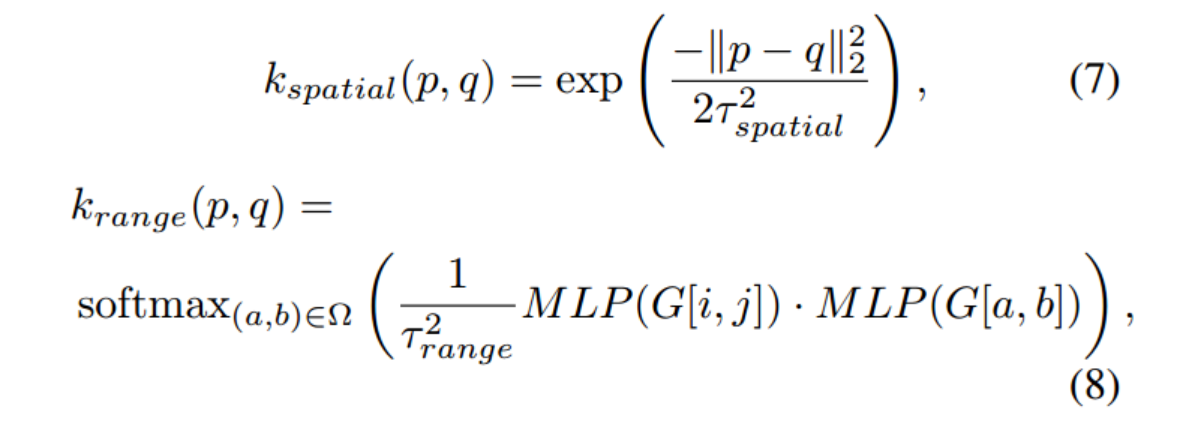
JBU的上采样内核krange和kspatial是根据制导特征中窗口内的元素计算的
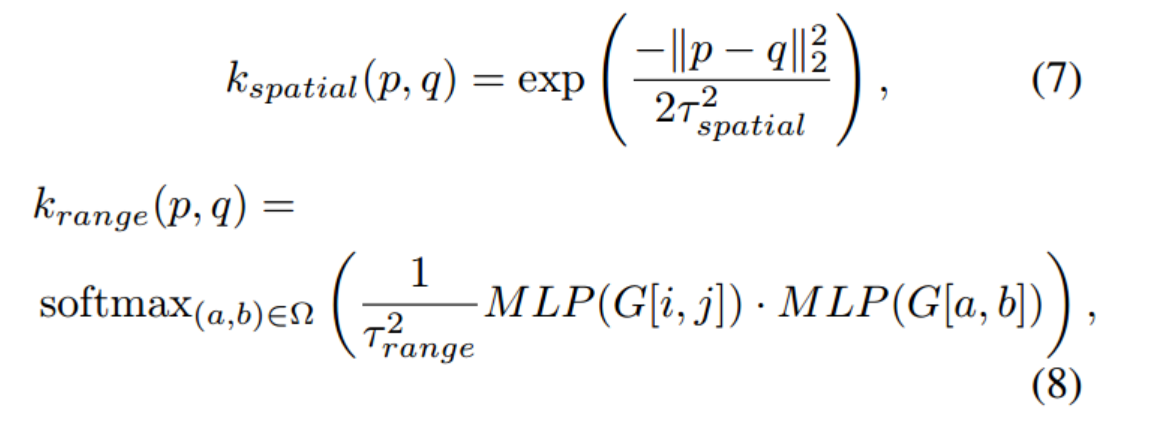
因此,我们设置更大的上采样内核以获得更宽的感受野。在这里,我们将窗口大小扩展到11 × 11,一个可能的问题是,更大的感受野可能会引入更多的无关内容
在Simplified Up中,参数化的JBU模块堆叠4次,进行16倍上采样,每个JBU模块的参数都是独立的
"JBU One"显著减少了上采样器中可训练参数的数量,并提供了上采样任意倍数的可能性
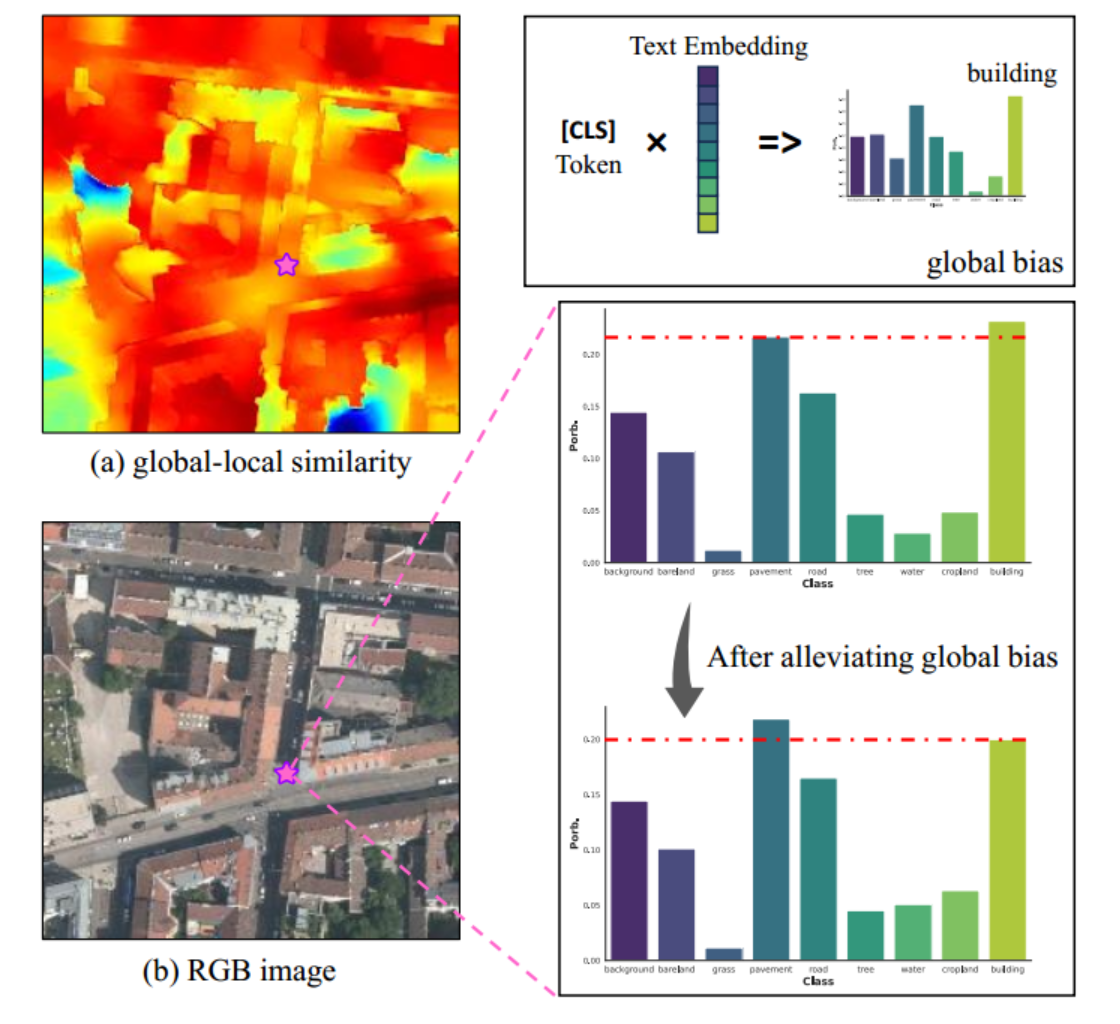
在CLIP的训练阶段,包含整个图像的全局信息的CLS令牌通过对比学习与多模态空间中的文本嵌入一起优化
在OVSS的推理阶段,CLS标记通常被丢弃,并且仅使用补丁标记来与提示词汇表进行相似度计算
我们使用CLIP为图(B)中的RGB图像提取CLS标记,并计算其与候选文本嵌入的相似度
我们建议从patch token中"减去"一些全局偏差
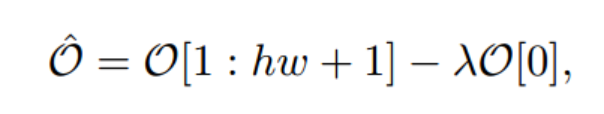
四、实验
不仅需要进行多类语义分割,还需要提取特定的土地覆盖类型(如建筑物、道路、水体),例如Google的Open Buildings
语义分割
在8个遥感语义分割数据集上评估了SegEarth-OV,包括
OpenEarthMap 70,LoveDA 64,iSAID 67,波茨坦,Vaihingen 3,UAVid 43,UDD 5 8和VDD 5
其中,前5个数据集主要由卫星图像组成,后3个数据集由无人机图像组成
4个建筑物提取数据集
WHUAerial 22,WHUSat.II 22,Inria 44和xBD 18
4个道路提取数据集
CHN 6-CUG 82、DeepGlobe 4、马萨诸塞州46和SpaceNet 62
1个洪水检测数据集
即WBS-SI 5用于评价单类提取
Simplified Up只需要图像数据进行训练
使用了一个公共的遥感图像分类数据集Million-AID 39,它主要收集来自Google Earth的图像
实现基于MMSegmentation 6工具包。如果没有指定,我们使用CLIP的原始预训练权重(ViT-B/16)。
OpenAI ImageNet模板作为文本编码器的输入,例如"a photo of a {class name}"
输入图像的长边调整为448,并使用224 × 224窗口和112步幅进行滑动推理。
对于Simplified Up训练,我们在原始图像上随机裁剪224 × 224图像块