1 问题
-
正则化与偏差-方差分解之间的联系。
-
Weight decay全值衰减。
2 方法
-
regularization:减小方差的策略
误差可分解为:偏差,方差与噪声之和。即误差=偏差+方差+噪声之和偏差度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力
方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响
噪声则表达了在当前任务上任何学习算法所能达到的期望泛化误差
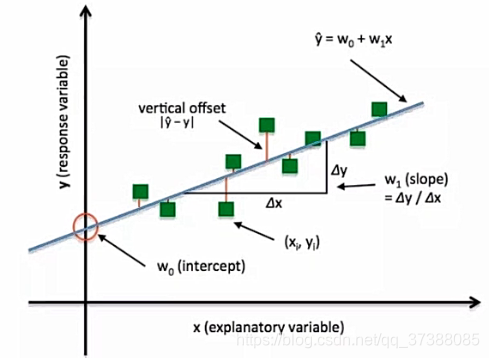
方差(Variance)是刻画数据扰动所造成的影响
偏差是指刻画学习算法的本身拟合能力
目标函数处理公式:( Objective Function ): Obj = Cost + Regularization Term
-
权值衰减代码复现模型搭建
-
classMLP(nn.Module):
-
def__init__(self, neural_num):
-
super(MLP, self).init()
-
self.linears=nn.Sequential(
-
nn.Linear(1, neural_num),
-
nn.ReLU(inplace=True),
-
nn.Linear(neural_num, neural_num),
-
nn.ReLU(inplace=True),
-
nn.Linear(neural_num, neural_num),
-
nn.ReLU(inplace=True),
-
nn.Linear(neural_num, 1),
-
)
-
defforward(self, x):
-
returnself.linears(x)
3 总结
针对问题一:对于pytorch模型中存在的过拟合与欠拟合做出明确原因与产生的数据来源的算法做出明确标注,解释清楚了误差的组成成分。
针对问题二:正则化策略的目的就是降低方差,减小过拟合的发生。weight_decay是在优化器中实现的,在代码中构建了两个优化器,一个优化器不带有正则化,一个优化器带有正则化。对与模型的优化有进一步提升。