目录
[1.从纸币鉴别类比到 GAN 的初始目标](#1.从纸币鉴别类比到 GAN 的初始目标)
[步骤 1:真币的鉴别流程](#步骤 1:真币的鉴别流程)
[步骤 2:假币的生成与鉴别流程](#步骤 2:假币的生成与鉴别流程)
[tqdm 进度条的默认显示内容](#tqdm 进度条的默认显示内容)
用torch.no_grad()包裹判别器前向传播(更直观)
一.GAN的介绍
1.概念
GAN(生成对抗网络)是一种通过 "博弈" 来学习数据分布的深度学习模型,核心是让两个神经网络(生成器 + 判别器)互相竞争、共同进步,最终让生成器学会 "模仿真实数据生成新内容"。
GAN模型主要由两部分组成:生成器(Generator)和判别器(Discriminator)。
① 生成器:生成器模型可以是 任意结构的神经网络,其 输入是 随机噪声(torch.randn),输出则是 生成的样本。生成器的 目标是使生成的样本尽可能接近真实样本的分布,以欺骗判别器。
② 判别器:判别器模型同样可以是任意结构的神经网络,其 输入是真实样本或生成器生成的样本,输出是一个 概率值,表示 输入样本是真实样本的概率。判别器的 目标是尽可能准确地判断输入样本是真实样本还是生成样本。
2.作用
通俗来说,最普通的GAN 的作用就是"输入一团随机噪声,然后通过人脸训练的模型,把这一团噪声变成一张近似的人脸"
以下公式推导根据此视频进行讲解:
二.核心公式推导
1.从纸币鉴别类比到 GAN 的初始目标
以"纸币鉴别" 的类比,解释了 GAN(生成对抗网络)中判别器和生成器的目标函数:
记有某一张纸币为,D(
)表示把纸币给帽子叔叔鉴别真伪,输出这张纸币为真币的概率。比如D(
)=0.3,表示帽子叔叔判断这张纸币有 30% 的概率为真币。
记有一张白纸为,G(
)表示把这张白纸送给不法之徒,不法之徒将他制作成纸币 (伪造的)。比如G(
)=
,表示不法之徒把白纸伪造为纸币,我们可以用
表示。
对于帽子叔叔而言:
当纸币为真,即:D()是真币的概率,我们让这个概率越大越好
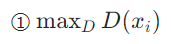
当纸币为假,即:G()是假币的概率,我们让这个概率越小越好
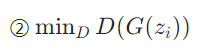
对于法外狂徒而言:
它希望自己伪造的假币可以骗过帽子叔叔,即:法外狂徒希望G()是假币的概率越大越好
③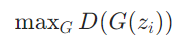
公式部分:
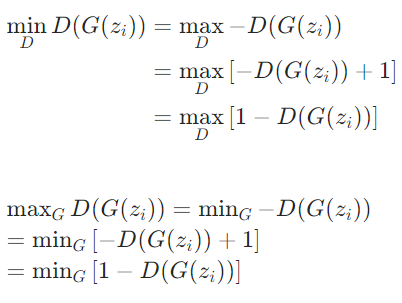 我们让②最小值公式变一下,想让取最小值min变为取最大值max,那么就让里面的D(G(
我们让②最小值公式变一下,想让取最小值min变为取最大值max,那么就让里面的D(G())先取负号,第二步:取最值时,加上一个常数不会影响最终变量取值(看下面"补充解释"的例子),因此给-D(G(
))加上个1,最终变成了第三步的最终式子。下面的③公式转换同理。
(补充解释:取最值时,加上一个常数不会影响最终变量取值)
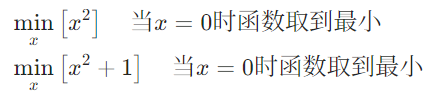
2.转成对数形式
上面我们转换了②③公式,现在再给所有公式套上一个自然对数log,取最值时,加上一个自然对数也不会影响最终变量取值,就变成了下面的公式
对于帽子叔叔而言:
当纸币为真,即:D()是真币的概率,我们让这个概率越大越好,即:
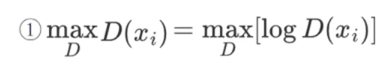
当纸币为假,即:G()是假币的概率,我们让这个概率越小越好,即:
②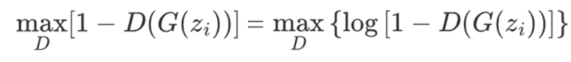
对于法外狂徒而言:
它希望自己伪造的假币可以骗过帽子叔叔,即:法外狂徒希望G()是假币的概率越大越好
③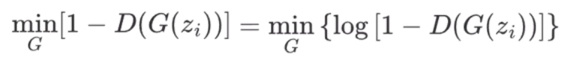
3.批量数据下的目标函数扩展
因此对于帽子叔叔而言,优化目标为①+②
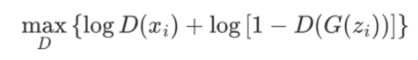
但是上面说的公式只是针对某一张纸币的真假概率,假设存在N张纸币,则优化目标为:
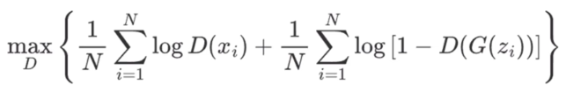
对于法外狂徒而言,则
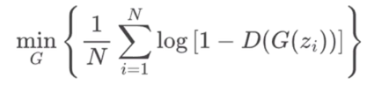
4.目标函数转为期望形式
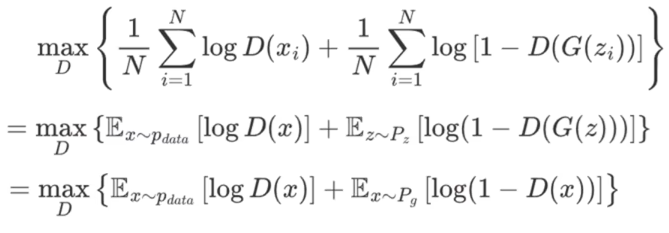
进一步推导,把帽子叔叔 的优化目标可以写成期望E(x)形式,期望就是求和取平均,根据下面的"4.GAN流程图",是 "输入的真币的特征规律",Pz是给法外狂徒的白纸,所以直接写成第二步形式;根据下面的"4.GAN流程图",我们可以把白纸z~Pz写成假币x~
,用x替换G(z),省去了x=G(z)"白纸→假币"的过程,进而得到第三步式子。
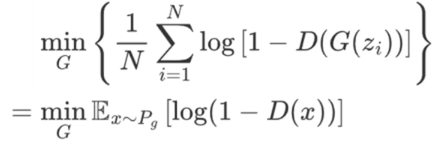
该图则是法外狂徒的优化目标的同理变换,也是先写成期望形式,再用x替换G(z)
二者合并起来就是极大极小目标函数:
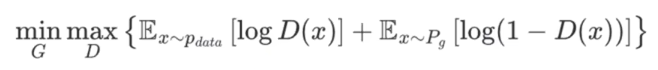
- minG:对生成器 G求 "最小值"(生成器的优化方向);
- maxD:对判别器 D求 "最大值"(判别器的优化方向);
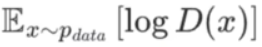 :对 "真实数据x" 的期望 ------ 真实数据服从分布
:对 "真实数据x" 的期望 ------ 真实数据服从分布,D(x)是判别器判断 "x是真数据" 的概率,log D(x)是其对数形式;
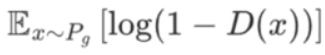 :对 "生成器造的假数据x" 的期望 ------ 假数据服从生成器的分布
:对 "生成器造的假数据x" 的期望 ------ 假数据服从生成器的分布
判别器要最大化整个大括号里的内容,对应 "区分真假数据" 的目标:
- 对于真实数据:希望D(x)越大越好(即log D(x)越大);
- 对于假数据:希望1-D(x)越大越好(即log(1-D(x))越大);两者结合,判别器的目标是 "让真数据的判定概率尽可能高,假数据的判定概率尽可能高"。
生成器要最小化整个大括号里的内容,对应 "让假数据骗过判别器" 的目标:
- ++生成器只影响假数据的分布这一项++ ,
- 生成器希望假数据被判定为 "真"(即D(x)越大),等价于让log(1-D(x))越小 ------ 因此生成器要最小化这一项,最终实现 "假数据以假乱真"。
5.总结核心公式
对于"帽子叔叔"(判别器)的目标函数:让真数据的判别概率尽可能大,假数据的判别概率尽可能小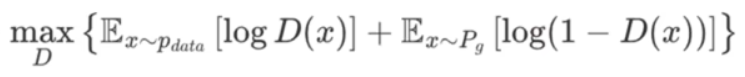
对于"法外狂徒"(生成器)的目标函数:让假数据的判别概率尽可能大,(等价于让log(1-D(x)) 尽可能小)。
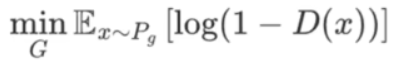
所以最终的目标函数可以写成:
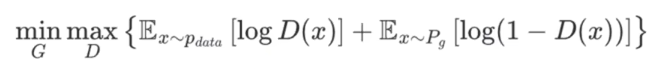
6.GAN流程图
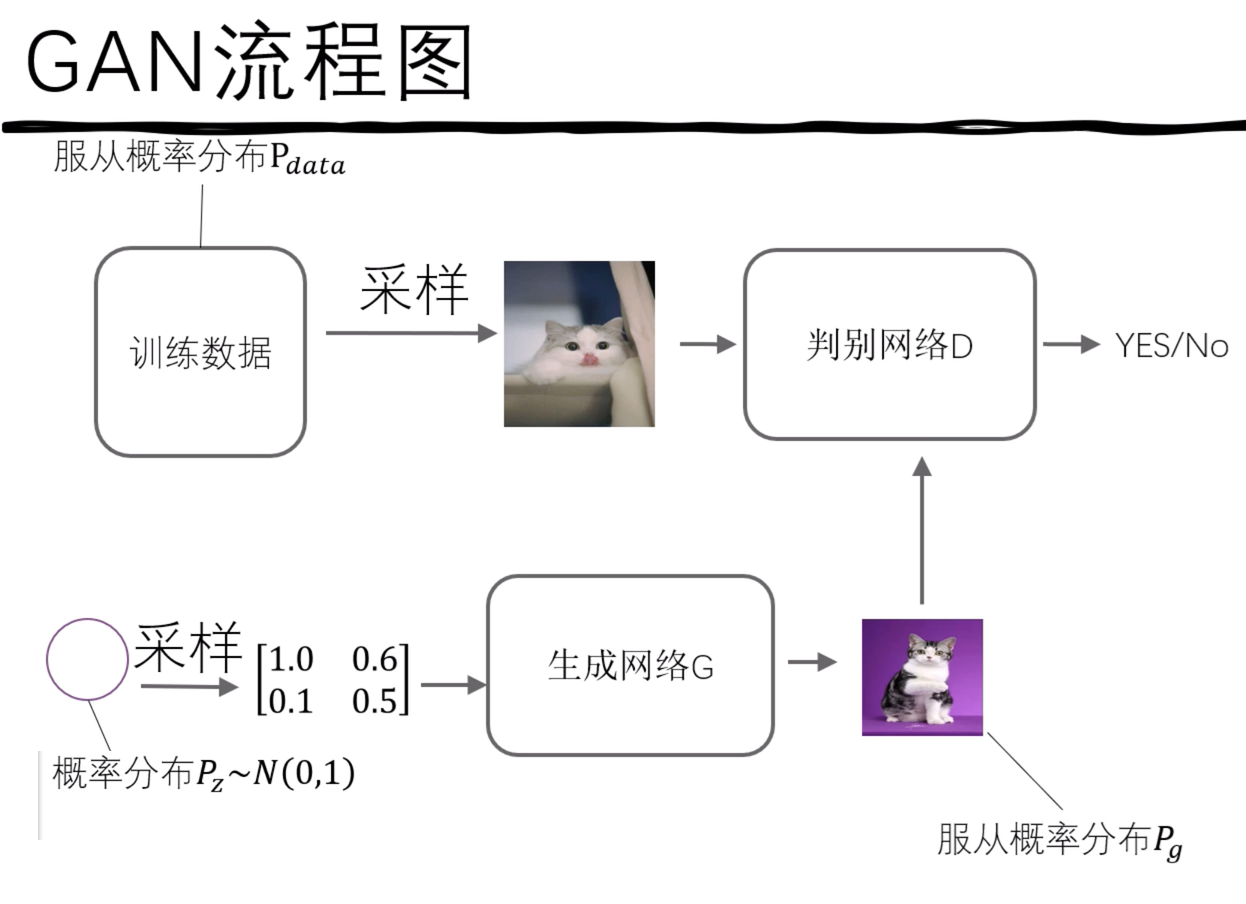
我们用 "纸币鉴别(真币 / 假币)" 的例子,对应这个 GAN 流程图的每一步:
(1)流程中的角色对应
- Pz 是生成器输入的 "随机噪声" 的概率分布,即那个"白纸"
- 训练数据 :对应 "真实纸币",服从的概率分布
- 生成网络 G :对应 "法外狂徒",输入的是随机噪声(对应 "白纸"),输出的是 "伪造的假币",服从的概率分布
- 判别网络 D:对应 "鉴别纸币的帽子叔叔",输入是 "真币 / 假币",输出是 "这张纸币是真币的判断(YES/NO)"。
(2)流程步骤(对应纸币场景)
步骤 1:真币的鉴别流程
- 从 "训练数据(真币)" 中采样:拿出一张真实纸币;
- 输入 "判别网络 D(帽子叔叔)":让帽子叔叔鉴别这张纸币;
- 输出 "YES/No":帽子叔叔判断这张纸币是 "真币(YES)" 还是 "假币(No)"------ 目标是让真币都被判定为 YES。
步骤 2:假币的生成与鉴别流程
- 从 "概率分布Pz∼N(0,1)(随机噪声)" 中采样 :对应 "法外狂徒拿到一张白纸",采样得到的数值(比如
[1.0 0.6; 0.1 0.5])是 "白纸的随机特征"; - 输入 "生成网络 G(法外狂徒)":法外狂徒把白纸加工成 "伪造的假币";
- 生成的假币服从概率分布
- 把假币输入 "判别网络 D(帽子叔叔)":让帽子叔叔鉴别这张假币;
- 输出 "YES/No":帽子叔叔判断这张假币是 "真币(YES)" 还是 "假币(No)"------ 法外狂徒希望假币被判定为 YES,帽子叔叔希望假币被判定为 No。
(3)核心对抗逻辑(对应纸币场景)
- 判别网络 D(帽子叔叔)的目标:区分真币和假币------ 看到真币输出 YES,看到假币输出 No;
- 生成网络 G(法外狂徒)的目标:让假币骗过鉴别者------ 造出的假币让帽子叔叔误以为是真币(输出 YES)。
最终,法外狂徒(G)和鉴别者(D)不断博弈:法外狂徒的假币越来越逼真,鉴别者的鉴别能力越来越强,直到鉴别者无法区分真假(假币和真币特征一致),对应 GAN 训练完成。
三.最优值求解
公式图不全随便放一张,因为用不到,我不想看公式,只想看看结论
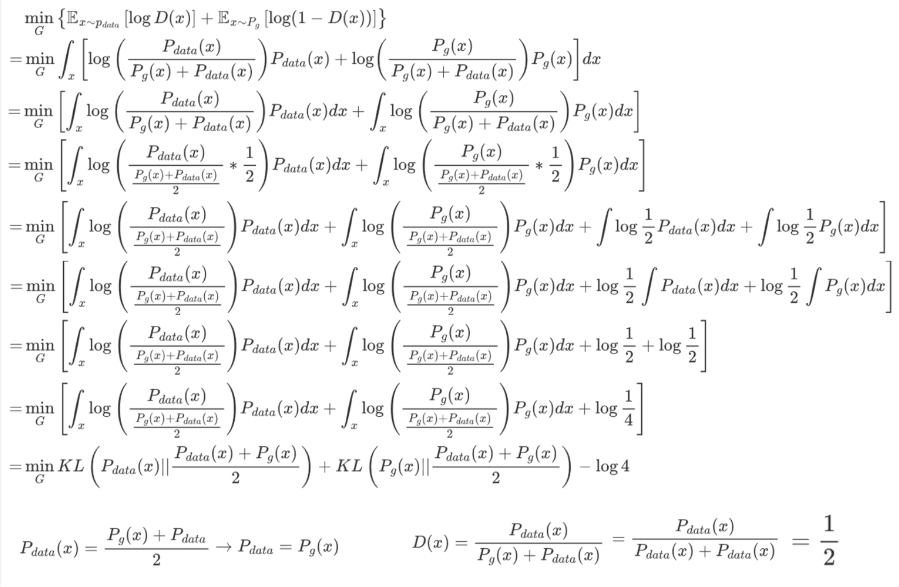
经过一系列公式推导,我们可以得到下面结论:
D(x)= 是 GAN 达到理想平衡状态的标志 ------ 生成器完美模仿真实数据,判别器无法区分真假。
这个公式推导我不想看也不想提,我就只想看看结论好吧。
四.代码讲解
只讲解部分新增技巧,其他的全注释在代码里
1.进度条包装
python
# 遍历数据(用 tqdm 包装成可视化进度条)
for step, data in tqdm(enumerate(dataloader), desc=f"第{epoch}轮", total=loader_len):tqdm(..., desc=f"第{epoch}轮", total=loader_len)
在train函数里面的tqdm 是一个 Python 进度条库,作用是把普通循环变成 "带进度条 + 剩余时间" 的可视化循环,参数含义:
| 参数 | 作用 |
|---|---|
enumerate(dataloader) |
要包装的循环对象(即 "遍历每一批数据" 的循环),是进度条的 "迭代来源"; |
desc=f"第{epoch}轮" |
进度条的 "描述文字",显示当前是第几轮训练(比如第 3 轮训练时,desc 就是 "第 3 轮"); |
total=loader_len |
进度条的 "总步数",即本轮训练要遍历的总批次数(loader_len = len(dataloader),由数据总量 / 批次大小计算而来,比如 MNIST 有 60000 张图,批次大小 64,总批次数≈938); |
tqdm 进度条的默认显示内容
运行时会看到类似这样的进度条:
plaintext
第3轮: 50%|█████ | 469/938 [00:12<00:12, 38.2it/s]第3轮:desc 参数指定的描述;50%:当前进度(已完成 469 批,总 938 批);469/938:已完成批次数 / 总批次数;00:12<00:12:已用时间 / 剩余时间;38.2it/s:每秒处理的批次数(迭代速度)。
2.reshape和view基本一样
(1)核心功能一样
python
# 重塑图像:[64, 1, 28, 28] → [64, 784],并移动到设备
#与全连接层的view函数view(-1, 784)功能基本一致,详见第2.
sample = sample.reshape(-1, 784).to(device)
python
sample = sample.reshape(-1, 784) # [64,1,28,28] → [64,784]
# 等价于
sample = sample.view(-1, 784) # 效果完全一样两者最终都会把 "64 张 1 通道 28×28 的图像",平铺成 "64 个 784 维的向量",数据的数值、顺序都不变,只是形状变了------ 这是它们的核心共性。
(2)区别在于view要求张量内存连续
更推荐用reshape,虽然核心作用一致,但底层逻辑和适用场景有小差异
| 对比维度 | reshape(-1, 784) |
view(-1, 784) |
|---|---|---|
| 本质逻辑 | ++先尝试 "直接调整形状",若张量内存不连续++ (比如经过 transpose、permute 等操作后),++会先复制一份连续内存,再调整形状++ | ++仅 "直接调整形状",不复制内存++ ------ 要求++张量的内存必须是 "连续的"++(contiguous),否则会报错 |
| 内存占用 | 大多数情况(如代码中)不复制内存,特殊情况会额外占用一点内存 | 绝对不复制内存,只改 "视图",内存更高效 |
| 适用场景 | 通用场景,不用关心张量是否连续,兼容性强(推荐新手用) | 已知张量内存连续时(如代码中,sample 是刚加载的原始数据,内存连续),效率更高 |
| 报错风险 | 极低(几乎不会因内存不连续报错) | 若张量内存不连续,会抛出 RuntimeError: invalid argument 2: view size is not compatible with input tensor's size and stride 错误 |
本历程代码中,sample 是刚从 dataloader 加载的原始数据,形状是 [64,1,28,28]:
- 原始数据的内存是 "连续的"(contiguous=True)------ 因为没有经过任何打乱内存顺序的操作(如 transpose、permute);
- 此时
view(-1,784)和reshape(-1,784)完全等价:都是直接调整形状,不复制内存,最终结果一样。
3.sigmoid函数
(1)作用
把任意实数 -∞~+∞ 的输入,压缩到0,1区间 ------ 这个特性是它最关键的价值,能把网络的无界输出转成 "有界的概率 / 置信度"。同时增加非线性。
**概率映射(人为约定)**配合任务规则,把压缩后的结果映射成 "二分类概率":
- 输出接近 1 → 属于某类(如 "真实数据""正样本")的概率高;
- 输出接近 0 → 属于另一类(如 "伪造数据""负样本")的概率高。
- 网络最后一层输出一个实数x,经过 Sigmoid 压缩成0,1的概率值;
- 通常以 0.5 为阈值:σ(x) ≥ 0.5 判定为正类,否则为负类。
sigmoid通过输入真图不断训练,我们希望判别器对真图输出的概率 接近 1,所以sigmoid让输出的真图的概率不断靠近1,<3>例子有说明
(2)公式
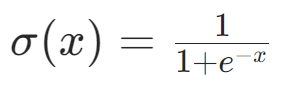
(3)举例
假设我们有一张真实猫咪图片 ,输入判别器后,经过多层卷积、全连接层的计算,判别器最后一层(未经过 Sigmoid)的输出是 x = 5(这个值是无界的,可能是正数、负数,比如 5、-3 等)。
把这个无界的x=5代入 Sigmoid 公式: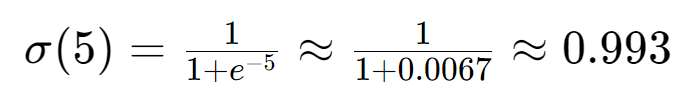
此时 Sigmoid 输出约为0.993,已经非常接近 1。
再通过损失函数让输出更接近 1:如果这张真实图片的标签是1(我们定义 "真实数据标签 = 1"),此时用 BCE 损失计算 "输出 0.993" 和 "标签 1" 的差距:
BCE=−1×ln(0.993)+(1−1)×ln(1−0.993)≈−(−0.007)=0.007
++损失会驱动网络反向调整参数 ,让下一次输入这张图时,判别器的原始输出x更大++ (比如变成x=10)。再代入 Sigmoid: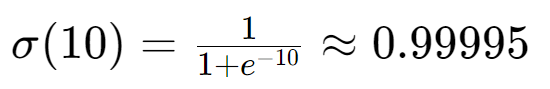
++输出就更接近 1++了 ------ 这就是 "真实数据对应输出接近 1" 的过程。
过程:真实图片→判别器原始输出(大正数)→Sigmoid 压缩成接近 1 的数→损失函数优化让原始输出更大→Sigmoid 输出更接近 1。
4.detach切断生成器梯度(我讲的非常详细!)
detach是非必要的,主要是不 detach 会浪费大量算力和内存
python
# --------------------- 训练判别器 ---------------------
# 判别器处理真实图像:输出真实概率(希望接近1)
Dis_true = D(sample)
#计算真实图像的损失:Dis_true(预测概率)与全1标签(真实图像标签)的差距
true_loss = loss_fn(Dis_true, torch.ones_like(Dis_true))
# 判别伪造样本:希望输出接近0
fake_sample = G(sample_z) # 生成器生成假图像
Dis_fake = D(fake_sample.detach()) # detach切断生成器梯度
#解释detach:在大标题四->2.->(4)
fake_loss = loss_fn(Dis_fake, torch.zeros_like(Dis_fake))
# 判别器总损失
Dis_loss = true_loss + fake_loss
# 反向传播+更新判别器参数
D_optim.zero_grad() # 清空梯度
Dis_loss.backward() # 计算梯度
D_optim.step() # 更新参数
fake_loss损失的生成路径:生成器G先生成fake_sample样本,fake_sample样本再通过判别器D输出概率Dis_fake,概率Dis_fake再被转换成损失fake_loss。则损失的生成路径是:G → fake_sample → D → Dis_fake → fake_loss。(梯度等会沿着这个路径找回来)
true_loss损失的生成路径:直接输入的样本sample通过判别器D输出概率Dis_true,Dis_true再被转换成损失true_loss。则损失的生成路径是:sample → D → Dis_true → true_loss。
若不切断(直接写 D(fake_sample)):当计算 fake_loss 并执行 D_optim.step() 时,梯度会沿着 "fake_loss → Dis_fake → D → fake_sample → G" 的路径反向传播,此时G的梯度被计算出来了了,这就浪费了算力。(D_optim在这里不会更新生成器 G参数,在下面"训练生成器 G"的代码中由于会清空梯度也不会产生影响生成器 G参数)
导致生成器 G 的神经网络网络层参数也被更新/训练(这是错误的!因为当前正在训练判别器,G 不该参与更新);损失是有两个损失相加的结果,即Dis_loss = true_loss + fake_loss,则总的来说,从Dis_loss损失开始反向传播时梯度会分别沿着这两个损失生成的路径来反向传播更新参数,这两条路径分别是:①"true_loss → Dis_true → D → sample "(最终梯度找到判别器D) 和 ②"fake_loss → Dis_fake → D → fake_sample → G"(最终梯度找到生成器G),现在我们正在训练的是判别器D,所以我们不需要找到生成器G,因此切断第二条路,但还没说完。
如果detach要切断生成器梯度,从哪开始切?我们还要保留"fake_loss → Dis_fake → D"让fake_loss能找到判别器D,这样fake_loss才能起作用,因此我们要切断它后面的 "fake_sample→G" 的路径防止计算梯度,而不切断 "fake_loss → Dis_fake → D" 的路径 ------省去额外计算用不到的生成器G的梯度。因此当 fake_sample = G(sample_z)生成器生成fake_sample后,就立马detach切断前面的路径防止计算梯度,不让反向传播往上找到生成器并生成梯度,即"G →❌️ fake_sample → D → Dis_fake → fake_loss";接着。则此时梯度会只沿着 ①"true_loss → Dis_true → D → sample " 和 ②"fake_loss → Dis_fake → D "反向传播了,他们都是只更新判别器而省去了计算生成器G的梯度。
这样只训练判别器D的神经网络层参数。
5.detach切断判别器梯度(同理)
切断 G_loss 到 D 的梯度,但保留 G_loss 到 G 的梯度。**不对 D(fake_sample) 做 detach(),**这种情况下不会影响生成器的梯度计算(因为G_optim不关心判别器D的参数),但会有 "无用的额外开销"------多计算了判别器的梯度。
对判别器的输出用detach()(最简洁)
python
# --------------------- 训练生成器 ---------------------
# 让判别器判别假图像:希望输出接近1
Dis_G = D(fake_sample).detach() # 切断D的梯度传播
G_loss = loss_fn(Dis_G, torch.ones_like(Dis_G))
# 反向传播+更新生成器参数
G_optim.zero_grad() # 清空梯度
G_loss.backward() # 计算梯度
G_optim.step() # 更新参数用torch.no_grad()包裹判别器前向传播(更直观)
python
# --------------------- 训练生成器 ---------------------
# 让判别器判别假图像:希望输出接近1
with torch.no_grad(): # 禁止计算D的梯度
Dis_G = D(fake_sample) # D的前向传播不记录梯度
G_loss = loss_fn(Dis_G, torch.ones_like(Dis_G))
# 反向传播+更新生成器参数
G_optim.zero_grad() # 清空梯度
G_loss.backward() # 梯度只流向G
G_optim.step() # 更新参数历程代码:
python
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision.datasets import MNIST
from torchvision import transforms
from torch.utils.data import DataLoader
from tqdm import tqdm
import matplotlib.pyplot as plt
import numpy as np
import os
# 1. 定义判别器网络
class Distinguish_Model(torch.nn.Module):
"""判别器:输入784维图像向量,输出0-1的真假概率"""
def __init__(self):
super().__init__()
#定义全连接层序列(Sequential:按顺序执行层操作,简化代码)
self.fc = torch.nn.Sequential(
#第1个全连接层:输入784维(28×28图像展平后),输出512维
torch.nn.Linear(in_features=784, out_features=512),
#激活函数Tanh:输出范围[-1,1],增加非线性表达能力
torch.nn.Tanh(),
torch.nn.Linear(in_features=512, out_features=256),
torch.nn.Tanh(),
torch.nn.Linear(in_features=256, out_features=128),
torch.nn.Tanh(),
torch.nn.Linear(in_features=128, out_features=1),
torch.nn.Sigmoid() #激活函数Sigmoid:将输出映射到[0,1],表示"真实概率"(1=真实,0=伪造)
)
#前向传播方法
def forward(self, x):
x = self.fc(x)
return x
# 2. 定义生成器网络
class Generate_Model(torch.nn.Module):
"""生成器:输入128维随机噪声,输出784维图像向量"""
def __init__(self):
super().__init__()
self.fc = torch.nn.Sequential(
torch.nn.Linear(in_features=128, out_features=256),
torch.nn.Tanh(),
torch.nn.Linear(in_features=256, out_features=512),
torch.nn.ReLU(),
torch.nn.Linear(in_features=512, out_features=784),
torch.nn.Tanh()
)
def forward(self, x):
x = self.fc(x)
return x
# 3. 训练函数
def train():
# 设备配置:优先GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 数据预处理:转张量 + 归一化到[-1, 1]
transformer = transforms.Compose([
#把PIL图像转为PyTorch张量(Tensor),像素值从[0,255]缩放到[0,1]
transforms.ToTensor(),
# 归一化:(输入 - mean) / std,将像素值缩放到[-1,1]
# mean=0.5、std=0.5:(0-0.5)/0.5=-1,(1-0.5)/0.5=1,匹配生成器Tanh输出
transforms.Normalize(mean=0.5, std=0.5)
])
# 加载MNIST训练集
train_data = MNIST(root="./data", transform=transformer, download=True)
# 数据加载器:批次64,打乱数据
#num_workers=4:用4个线程加载数据(并行加速,避免CPU瓶颈)
dataloader = DataLoader(train_data, batch_size=64, num_workers=4, shuffle=True)
# 实例化模型并移动到设备(CPU)
D = Distinguish_Model().to(device) # 判别器,一张图形状是 [1, 784],他们都可以输入一批图像(64 张):形状是 [64, 784]
G = Generate_Model().to(device) # 生成器
# 优化器:Adam,学习率1e-4,即0.0001
#D.parameters() 会找到判别器(D)这个神经网络中所有需要被优化的可训练参数
D_optim = torch.optim.Adam(D.parameters(), lr=1e-4)
G_optim = torch.optim.Adam(G.parameters(), lr=1e-4)
# 损失函数:二分类交叉熵(BCELoss)
loss_fn = torch.nn.BCELoss()
# 训练轮数
epochs = 100
# 创建模型保存目录:./model(如果目录已存在,把模型保存在该文件中,exist_ok=True避免报错)
#当 ./model 目录不存在时,自动创建该目录
os.makedirs("./model", exist_ok=True)
# 开始训练
for epoch in range(epochs):
dis_loss_all = 0.0 # 记录判别器总损失
gen_loss_all = 0.0 # 记录生成器总损失
loader_len = len(dataloader) # 数据加载器长度(即本轮训练的总批次数)
# 遍历数据(用 tqdm 包装成可视化进度条)
for step, data in tqdm(enumerate(dataloader), desc=f"第{epoch}轮", total=loader_len):
# 从data中分离出图像样本(sample)和标签(label),标签后续用不到
sample, label = data
#重塑图像:sample形状[64, 1, 28, 28] → [64, 784],并移动到设备
#reshape与全连接层的view函数view(-1, 784)功能基本一致,详见大标题四--->2.
#把sample展成784维是为了输入判别器,因为判别器全是全连接层
sample = sample.reshape(-1, 784).to(device)
#获取当前sample批次的实际大小(一般是64,最后一批可能不足64)
sample_shape = sample.shape[0]
# normal函数:生成随机噪声:服从正态分布N(0,1)
# 0 和 1 分别是正态分布的均值和标准差)
# size=(sample_shape, 128):形状为(批次大小,128维),与生成器输入匹配
# device=device:噪声数据与模型设备一致
# 为128维每个位置随机生成一个数值,这128维随机数字就是噪声图像
sample_z = torch.normal(0, 1, size=(sample_shape, 128), device=device)
# --------------------- 训练判别器 ---------------------
# 判别器处理真实图像:输出真实概率(希望接近1)
Dis_true = D(sample)
#计算真实图像的损失:Dis_true(预测概率)与全1标签(真实图像标签)的差距
true_loss = loss_fn(Dis_true, torch.ones_like(Dis_true))
# 判别伪造样本:希望输出接近0
fake_sample = G(sample_z) # 生成器生成假图像
#解释detach:由于讲解十分详细、字多,放在大标题四->4.
Dis_fake = D(fake_sample.detach()) # detach切断生成器梯度
#torch.zeros_like(Dis_fake)的参数Dis_fake解释:
#ones_like 需要以 Dis_true 为 "模板",生成一个和它形状、数据类型、设备完全一致,且所有元素都是 1 的张量
fake_loss = loss_fn(Dis_fake, torch.zeros_like(Dis_fake))
# 判别器总损失
Dis_loss = true_loss + fake_loss
# 反向传播+更新判别器参数
D_optim.zero_grad() # 清空上一轮的梯度,而不是当前轮要计算的新梯度
Dis_loss.backward() # 计算梯度
D_optim.step() # 更新参数
# --------------------- 训练生成器 ---------------------
# 让判别器判别假图像:希望输出接近1
Dis_G = D(fake_sample).detach() # 切断D的梯度传播
G_loss = loss_fn(Dis_G, torch.ones_like(Dis_G))
# 反向传播+更新生成器参数
G_optim.zero_grad() # 清空前面的梯度
G_loss.backward() # 计算梯度
G_optim.step() # 更新参数
# 累加损失(避免计算图占用内存)
with torch.no_grad():
dis_loss_all += Dis_loss
gen_loss_all += G_loss
# 计算本轮平均损失
with torch.no_grad():
dis_loss_all /= loader_len
gen_loss_all /= loader_len
print(f"判别器损失为:{dis_loss_all.item():.4f}")
print(f"生成器损失为:{gen_loss_all.item():.4f}")
#(item()把包含单个数值的张量转换成 Python 原生的数值类型(如 float/int),方便打印、计算或存储)
# 保存模型
torch.save(G, "./model/G.pth")
torch.save(D, "./model/D.pth")
# 4. 主函数:训练+生成图像
if __name__ == '__main__': #当脚本直接运行时,执行以下代码;把这个脚本当作模块导入其他文件,即被导入时不执行
# 训练模型
train()
# 加载生成器模型(CPU)
model_G = torch.load("./model/G.pth", map_location=torch.device("cpu"))
# 生成10个128维随机噪声
fake_z = torch.normal(0, 1, size=(10, 128))
# 生成图像:[10, 784] → [10, 28, 28]
result = model_G(fake_z).reshape(-1, 28, 28)
# 转为numpy数组
# detach:张量关联着计算图(默认 requires_grad=True)不能直接转成 numpy 数组
# detach() 会把张量从计算图中 "摘下来",让它变成一个 "纯数值张量"(不再参与梯度计算),此时才能正常调用 .numpy() 转换格式。
result = result.detach().numpy()
# 绘制生成的图像,
plt.figure(figsize=(10, 4)) #创建一个新的绘图画布,尺寸是宽 10 英寸、高 4 英寸
for i in range(10):
plt.subplot(2, 5, i+1)
plt.imshow(result[i], cmap="gray") # 灰度显示
plt.axis("off") # 隐藏坐标轴
plt.show()简洁代码输出
python
import torch
from torchvision import transforms
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
import os
from tqdm import tqdm
import numpy as np
import matplotlib.pyplot as plt
#判别器
class Distinguish_Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.fc = torch.nn.Sequential(
torch.nn.Linear(in_features=784, out_features=512),
torch.nn.Tanh(),
torch.nn.Linear(in_features=512, out_features=256),
torch.nn.Tanh(),
torch.nn.Linear(in_features=256, out_features=128),
torch.nn.Tanh(),
torch.nn.Linear(in_features=128, out_features=1),
torch.nn.Sigmoid()
)
def forward(self, x):
x = self.fc(x)
return x
#生成器
class Generate_Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.fc = torch.nn.Sequential(
torch.nn.Linear(in_features=128, out_features=256),
torch.nn.Tanh(),
torch.nn.Linear(in_features=256, out_features=512),
torch.nn.Tanh(),
torch.nn.Linear(in_features=512, out_features=784),
torch.nn.Tanh(),
)
def forward(self, x):
x = self.fc(x)
return x
def train():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"当前使用设备:{device}")
transformer = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=0.5, std=0.5)
])
train_data = MNIST(root="Y:/pycharm/mnist", transform=transformer, download=False)
dataloader = DataLoader(train_data, batch_size=64,num_workers=4, shuffle=True)
D = Distinguish_Model().to(device)
G = Generate_Model().to(device)
D_optim = torch.optim.Adam(D.parameters(), lr=1e-4)
G_optim = torch.optim.Adam(G.parameters(), lr=1e-4)
loss_fn = torch.nn.BCELoss()
epochs = 5
os.makedirs("./model", exist_ok=True)
for epoch in range(epochs):
dis_loss_all = 0.0
gen_loss_all = 0.0
loader_len = len(dataloader)
for step, data in tqdm(enumerate(dataloader), desc=f'第{epoch}轮', total=loader_len):
sample, label = data
sample = sample.reshape(-1,784).to(device)
sample_shape = sample.shape[0]
sample_z = torch.normal(0, 1, size=(sample_shape, 128), device=device) # ?参数有点问题
# 训练判别器
Dis_true = D(sample)
true_loss = loss_fn(Dis_true, torch.ones_like(Dis_true))
fake_sample = G(sample_z)
Dis_fake = D(fake_sample.detach())#里面detach
fake_loss = loss_fn(Dis_fake, torch.zeros_like(Dis_fake))
Dis_loss = true_loss + fake_loss
D_optim.zero_grad()
Dis_loss.backward(retain_graph=True)# 保留计算图,供生成器后续使用
D_optim.step()
# 训练生成器
Dis_G = D(fake_sample)#外面detach()
G_loss = loss_fn(Dis_G, torch.ones_like(Dis_G))
G_optim.zero_grad()
G_loss.backward()
G_optim.step()
# 累加损失
with torch.no_grad():
dis_loss_all += Dis_loss
gen_loss_all += G_loss
# 计算本轮损失
with torch.no_grad():
dis_loss_all /= loader_len
gen_loss_all /= loader_len
print(f"判别器损失:{dis_loss_all.item():.4f}")
print(f"生成器损失:{gen_loss_all.item():.4f}")
# 保存模型
torch.save(G, "./model/G.pth")
torch.save(D, "./model/D.pth")
if __name__ == '__main__':
train() #下面load里面weights_only=False,允许加载完整模型
model_G = torch.load("./model/G.pth", map_location=torch.device("cpu"),weights_only=False)
model_G.eval()
fake_z = torch.normal(0, 1, size=(10, 128))
with torch.no_grad():
result = model_G(fake_z).reshape(-1, 28, 28)
result = result.detach().numpy()
# 绘制图形
plt.figure(figsize=(10, 4))
for i in range(10):
plt.subplot(2, 5, i + 1)
plt.imshow(result[i], cmap="gray")
plt.axis('off')
plt.show()训练五轮的结果:
