概述
本文档分析了 Dify 平台中在线文档导入的完整流程,包括 Notion 导入和网站爬取两种主要方式。
时序图
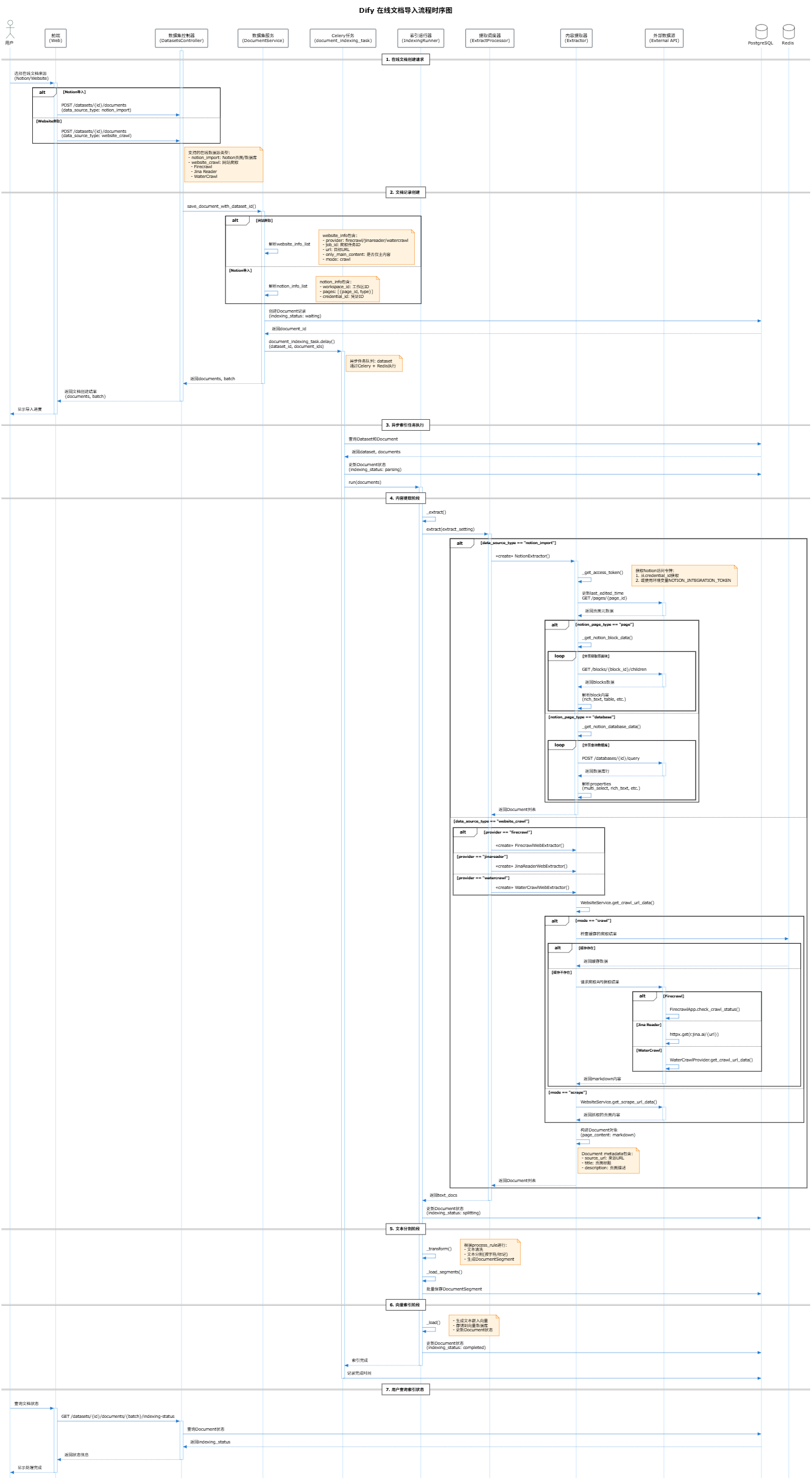
支持的在线数据源类型
1. Notion 导入 (notion_import)
支持导入 Notion 的两种类型内容:
- 页面 (page):单个 Notion 页面,解析页面中的所有块内容
- 数据库 (database):Notion 数据库,解析数据库中所有行的属性
2. 网站爬取 (website_crawl)
支持三种网站爬取服务提供商:
| 提供商 | 插件ID | 特点 |
|---|---|---|
| Firecrawl | langgenius/firecrawl_datasource |
支持 crawl 和 scrape 两种模式 |
| Jina Reader | langgenius/jina_datasource |
使用 r.jina.ai 服务抓取网页 |
| WaterCrawl | langgenius/watercrawl_datasource |
类似 Firecrawl 的开源替代 |
核心组件
控制器层
api/controllers/console/datasets/datasets.py- 数据集创建和索引估算api/controllers/console/datasets/datasets_document.py- 文档管理API
服务层
api/services/dataset_service.py-DocumentService文档服务api/services/website_service.py-WebsiteService网站爬取服务
核心处理层
api/core/indexing_runner.py-IndexingRunner索引执行器api/core/rag/extractor/extract_processor.py-ExtractProcessor提取调度器
内容提取器
api/core/rag/extractor/notion_extractor.py-NotionExtractorapi/core/rag/extractor/firecrawl/firecrawl_web_extractor.py-FirecrawlWebExtractorapi/core/rag/extractor/jina_reader_extractor.py-JinaReaderWebExtractorapi/core/rag/extractor/watercrawl/extractor.py-WaterCrawlWebExtractor
异步任务
api/tasks/document_indexing_task.py- 文档索引任务api/tasks/sync_website_document_indexing_task.py- 网站文档同步任务
数据模型
ExtractSetting
python
class ExtractSetting(BaseModel):
datasource_type: str # "upload_file" | "notion_import" | "website_crawl"
upload_file: UploadFile | None = None
notion_info: NotionInfo | None = None
website_info: WebsiteInfo | None = None
document_model: str | None = NoneNotionInfo
python
class NotionInfo(BaseModel):
credential_id: str | None = None
notion_workspace_id: str
notion_obj_id: str
notion_page_type: str # "page" | "database"
document: Document | None = None
tenant_id: strWebsiteInfo
python
class WebsiteInfo(BaseModel):
provider: str # "firecrawl" | "jinareader" | "watercrawl"
job_id: str
url: str
mode: str # "crawl" | "scrape"
tenant_id: str
only_main_content: bool = False处理流程
阶段1:文档创建
- 用户通过 API 提交在线文档导入请求
DocumentService.save_document_with_dataset_id()创建文档记录- 触发
document_indexing_taskCelery 异步任务
阶段2:内容提取
IndexingRunner._extract()调用ExtractProcessor.extract()- 根据数据源类型选择对应的提取器:
- Notion →
NotionExtractor - Website →
FirecrawlWebExtractor/JinaReaderWebExtractor/WaterCrawlWebExtractor
- Notion →
- 提取器调用外部 API 获取内容并转换为
Document对象
阶段3:文本分割
IndexingRunner._transform()根据处理规则分割文本- 生成
DocumentSegment记录
阶段4:向量索引
IndexingRunner._load()生成文本嵌入向量- 存储到向量数据库
- 更新文档状态为
completed
Notion API 调用
NotionExtractor 使用以下 Notion API 端点:
| 端点 | 用途 |
|---|---|
GET /blocks/{block_id}/children |
获取页面块内容 |
POST /databases/{database_id}/query |
查询数据库行 |
GET /pages/{page_id} |
获取页面元数据 |
API 版本:Notion-Version: 2022-06-28
网站爬取流程
Firecrawl
- 调用
FirecrawlApp.crawl_url()启动爬取任务 - 通过
FirecrawlApp.check_crawl_status()轮询状态 - 获取爬取结果的 markdown 内容
Jina Reader
- 单页抓取:
GET https://r.jina.ai/{url} - 多页爬取:使用
adaptivecrawl服务
WaterCrawl
- 类似 Firecrawl 的 API 结构
- 通过
WaterCrawlProvider封装调用
文档状态流转
waiting → parsing → splitting → indexing → completed
↘ error相关配置
| 配置项 | 说明 |
|---|---|
NOTION_INTEGRATION_TOKEN |
默认 Notion 集成令牌 |
BATCH_UPLOAD_LIMIT |
批量上传文档数量限制 |
ETL_TYPE |
ETL 处理类型 (Unstructured 等) |