第一部分:线程概念与控制
1.线程和进程概念
进程 = 内核数据结构(PCB、文件描述符表、信号相关结构等) + 进程自身的代码和数据(执行流)
线程:是进程内部的一个执行分支,也是一个执行流。
注:
进程:承担分配系统资源的基本实体
线程:CPU 调度的基本单位
2.进程在 Linux 中 "创建完成后" 的核心静态结构(管理结构 + 资源映射状态)

当 Linux 创建一个进程时,首先会生成task_struct(也 PCB) ------ 它是这个进程的 "总控档案",记录着进程的身份、状态等核心信息;接着为进程分配mm_struct(也就是地址空间),它会划定进程可用的虚拟内存范围,同时关联页表;然后通过页表建立虚拟地址到物理内存的映射关系,把进程的代码、数据等资源加载到右侧物理内存的对应区域。
3. Linux 中线程的实现:用进程模拟线程
(1)核心设计思路:共享地址空间
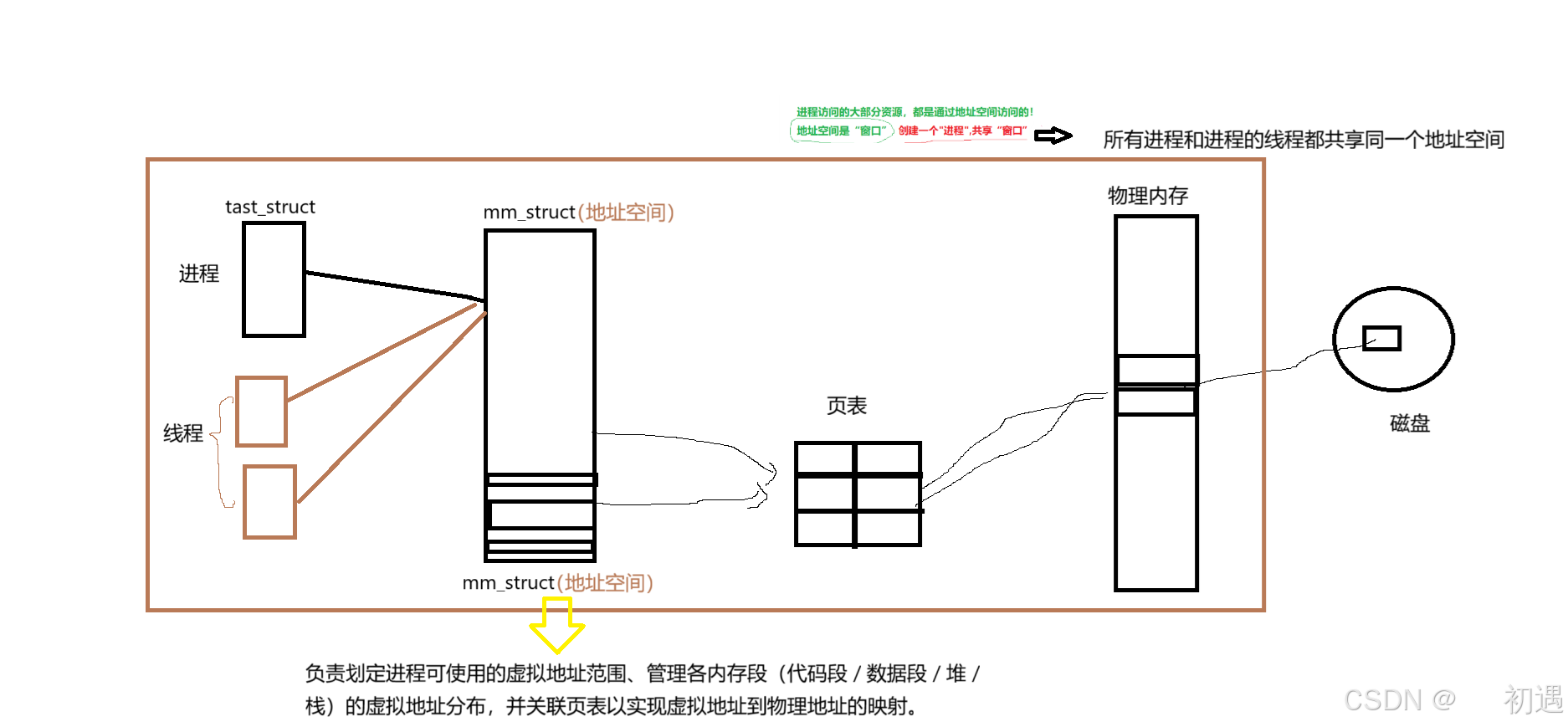
-
基础:进程的资源容器 进程拥有独立的
mm_struct(地址空间)、页表,以及通过页表映射到物理内存的资源(代码、数据等),同时进程对应一个task_struct(PCB)。 -
线程的 "特殊" 创建 当创建线程时,不新建独立的
mm_struct和页表 ,而是让线程的task_struct(图中左侧棕色方块)直接指向进程已有的mm_struct------ 相当于所有线程共享进程的地址空间这个 "资源窗口"。 -
线程的执行逻辑 每个线程有自己的
task_struct(独立管理自身的执行状态),但通过共享的地址空间访问同一份物理内存资源;同时给不同线程的task_struct设置不同入口函数,让它们执行进程代码的不同分支
总结:
线程:
- 每个线程对应一个 task_struct(PCB)结构体
- 所有线程的 task_struct 都指向同一个地址空间(mm_struct)和页表
- 线程的执行:通过给不同的 task_struct 设置不同的入口函数,让它们执行进程代码中的不同分支
(2)四个关键结论
结论一:Linux 中没有真正的线程,而是用进程模拟线程
- 这里的 "模拟" 不是 "虚假",而是复用进程的调度机制和数据结构,减少代码冗余
结论二:资源划分的本质是地址空间(虚拟地址)的划分
- 虚拟地址是资源的代表:只要申请到虚拟地址,就对应着相应的内存资源、代码资源和数据资源
- 地址空间是进程看到资源的 "窗口":进程能访问的资源数量,取决于这个窗口能覆盖的虚拟地址范围
结论三:代码和数据的划分天然通过 "函数入口" 实现
- 不管是 C 还是 C++ 代码,最终都是由一个个函数构成,每个函数都有独立的入口地址
- 函数的本质:虚拟地址空间的集合(编译后的代码块对应连续的虚拟地址)
- 线程执行不同函数,就天然访问了地址空间的不同区域,实现了资源划分
结论四:单进程是 "单线程进程" 的特殊情况
- 以前学的单进程,本质是进程内部只有一个线程(一个 task_struct 对应一个地址空间)
- 多线程进程是更普适的情况:一个地址空间对应多个 task_struct(多个执行流)
- 历史进程概念与新定义的兼容:进程 = 内核数据结构(含多个 task_struct) + 地址空间 + 代码和数据,线程是进程内部的执行分支
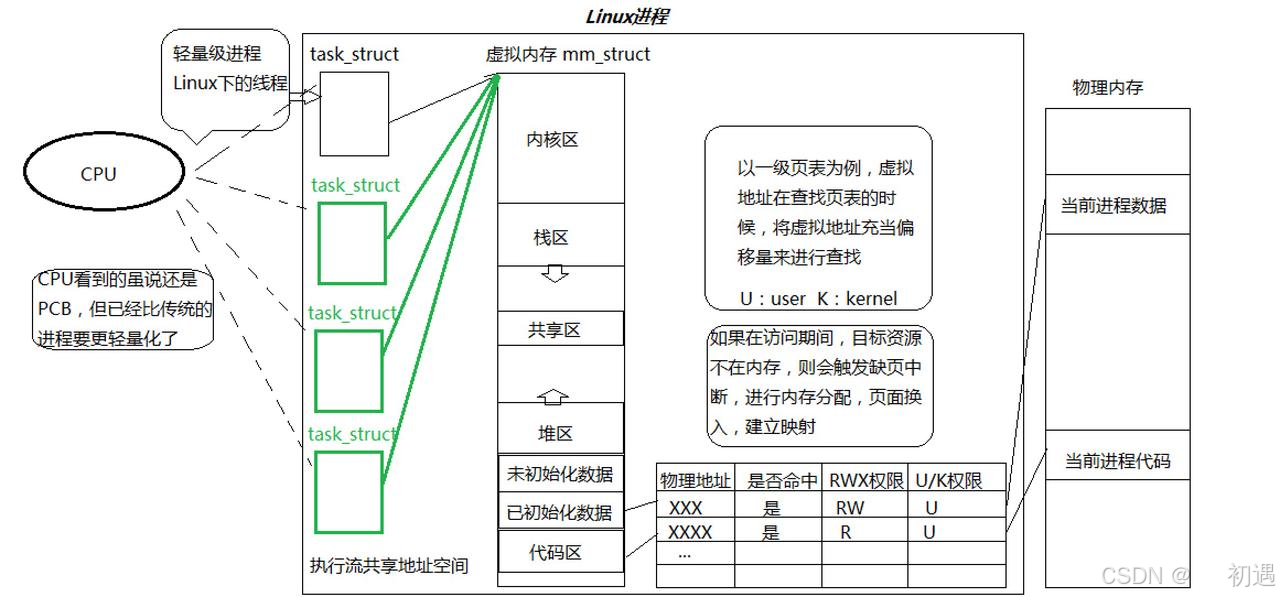
第二部分:内存管理与页表(线程的底层支撑)
1. 页表的由来
每个程序得占连续的物理空间。但程序大小不一样,用着用着物理内存会被拆成很多 "小碎块"(内存碎片),新程序可能因为找不到连续的空间,明明内存够也没法运行。
经过⼀段运⾏时间之后,有些程序会退出,那么它们占据的物理内存空间可
比特就业课以被回收,导致这些物理内存都是以很多碎⽚的形式存在。
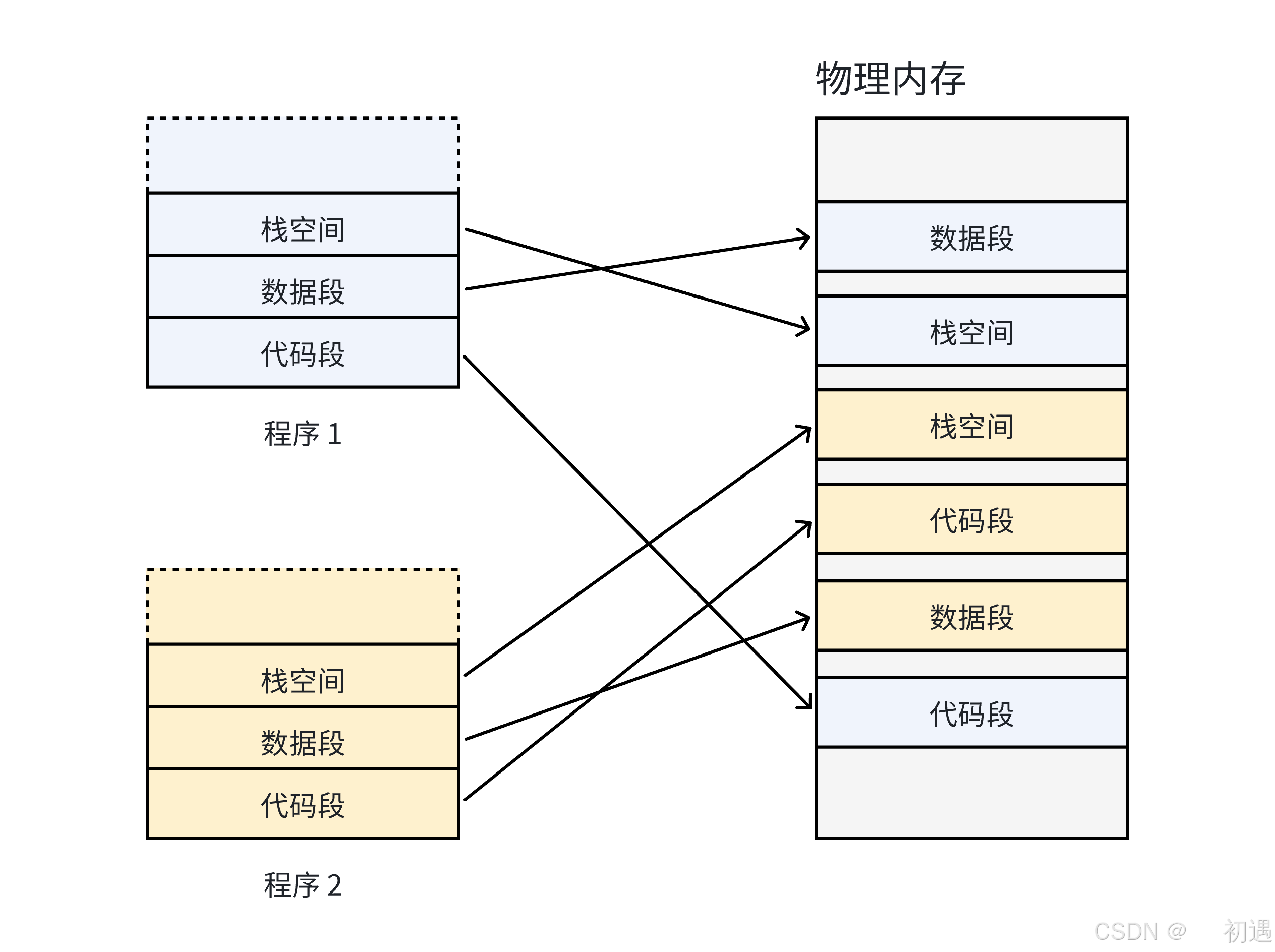
看图图:
经过⼀段运⾏时间之后,有些程序会退出,那么它们占据的物理内存空间可以被回收,导致这些物理内存都是以很多碎⽚的形式存在。
如何解决??**我们希望操作系统提供给⽤⼾的空间必须是连续的,但是物理内存最好不要连续。**此时虚 拟内存和分⻚便出现了,如下图所⽰:
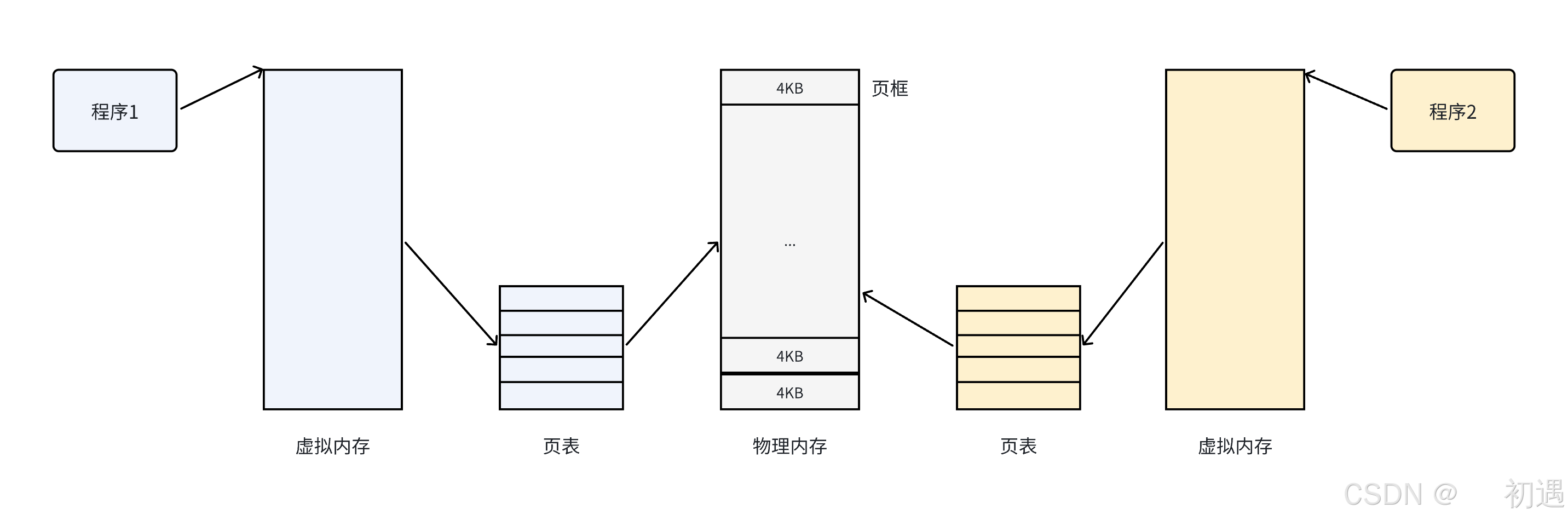
把物理内存按照⼀个固定的⻓度的**⻚框** 进⾏分割,有时叫做物理⻚ 。每个⻚框包含⼀个物理⻚
(page)。⼀个⻚的⼤⼩等于⻚框的⼤⼩ 。⼤多数32位 体系结构⽀持 4KB 的⻚,⽽ 64位 体系结 构⼀般会⽀持 8KB 的⻚。
区分一页 和一**个页框(4KB)**是很重要的:
•页框是⼀个存储区域;
• ⽽⻚是⼀个数据块,可以存放在任何⻚框或磁盘中。
2. 物理内存与磁盘的共性:4KB 页框
首先明确两个基础事实:
- 磁盘存储:文件系统以 4KB 为单位划分数据块(不管是文本文件还是可执行程序,都按 4KB 存储)
- 物理内存管理:操作系统将物理内存划分为 4KB 的内存块,称为 "页框"(或 "页帧")
为什么是 4KB?
- 兼容性:磁盘和内存的 IO 交换以 4KB 为单位,统一大小减少数据转换成本
- 效率平衡:4KB 是资源浪费和访问效率的平衡点(太小会导致碎片过多,太大则浪费空间)
3. 物理内存的管理:struct page 结构体
(1)struct page 的核心作用
每个 4KB 页框对应一个 struct page 结构体
核心字段:
flag:标志位 (表示页框是否被占用、可读可写可执行、是否被锁定等)
map_count:映射计数器 (记录有多少个页表项指向该页框)
_mapcount:引用计数器 (记录该页框被多少进程 / 线程引用)
其他字段:缓存相关、IO 相关属性(因内核版本不同略有差异)
(2) 数组:物理内存管理的底层载体
操作系统会定义一个全局数组(比如struct page mem_map[1048576]),数组的每个下标对应一个 4KB 页框:
- 数组下标范围是 0 到 100 万左右(以 4GB 内存为例:4GB = 410241024 KB,除以 4KB / 页框,得到 1048576 个页框)。
- 每个 page 结构体的起始物理地址 = 数组下标 × 4KB(比如下标 0 对应 0×0000~0×1000,下标 1 对应 0×1000~0×2000,以此类推)。
- 物理内存中任意一个字节的地址 = 页框起始物理地址 + 页内偏移量。
4.页表的定义
页表是 操作系统内核维护的一张 "地址映射表",核心使命是建立 "虚拟地址" 与 "物理页框地址" 的对应关系,充当两者之间的 "翻译官"------ 把进程访问的虚拟地址,翻译成物理内存中实际的页框地址,最终找到对应的 4KB 数据块(页)。
5.页表的核心:虚拟地址到物理地址的转化
(1)单级页表的问题:空间浪费
首先思考一个问题:如果用单级页表(一张表存储所有虚拟地址到物理地址的映射),会有什么问题?
- 32 位 4GB 地址空间,每个页表项 8 字节(存储物理地址)
- 单级页表需要的空间:4GB / 4KB × 8 字节 = 8MB × 4 = 32GB(这显然超出内存容量,完全不现实)
所以结论:页表必须是 "多级" 的,才能解决空间浪费问题。
(2)32 位系统的两级页表结构
- 虚拟地址拆分 :32 位虚拟地址分为 3 部分
- 前 10 位:页目录索引
- 中间 10 位:页表索引
- 后 12 位:页内偏移(因 4KB 页框对应 2^12=4096 的偏移范围
2.地址转化流程:
- 查页目录:用前 10 位索引页目录,找到下一级页表的基地址(CR3 寄存器存当前进程的页目录基地址)
2.查页表:用中间 10 位索引页表,找到页框基地址
3.算物理地址:页框基地址 + 后 12 位页内偏移
关键硬件支持:
CR3 寄存器:存储当前进程的页目录基地址(进程切换时,CR3 寄存器的值也会切换,实现页表切换)
MMU(内存管理单元):CPU 内部集成的硬件组件,负责自动完成虚拟地址到物理地址的转化(硬件加速,效率极高)
6. 页表的动态构建:缺页中断与写时拷贝
进程的页表不是一开始就完整构建的,而是动态生成的。
(1)缺页中断
触发条件:进程访问的虚拟地址是合法的(在地址空间范围内),但对应的页表项不存在(代码 / 数据还在磁盘未加载到内存)
处理流程:
1.操作系统触发缺页中断
2.执行页面置换算法,申请物理内存页框(找到空闲的 struct page)
3.从磁盘加载对应的代码 / 数据到页框
4.构建页表项(填写虚拟地址到页框的映射)
5.恢复进程执行
(2)写时拷贝(Copy-On-Write)
触发条件:多个线程 / 进程共享一个页框(如父子进程共享代码段),其中一个尝试修改该页框的数据
处理流程:
1.检测到页框的映射计数器(map_count)大于 1(被多个执行流引用)
2.操作系统为修改方创建一个新的页框,拷贝原页框的数据
3.修改该执行流的页表项,指向新的页框允许修改操作继续
Linux的线程和进程的区别
1.线程的优点
1.创建代价低: 线程基于已有进程创建,无需重新分配虚拟地址空间、构建页表等,只需创建 PCB(进程控制块)和独立资源(如栈)。
**2.占用资源少:**线程共享进程的大部分资源(代码段、数据段、文件描述符、信号处理方式等),仅占用少量私有资源。
**3.充分利用多核 CPU:**线程是调度的基本单位,多线程可在多核 CPU 上并行执行,提升计算密集型任务的效率。
**4.提高程序响应性:**等待慢速 IO 操作时,程序可通过多线程执行其他任务(多进程也能实现,但线程切换成本更低)。
补充知识点:IO 密集型与计算密集型应用
计算密集型(如加密解密、数据排序、游戏画面渲染): 适合多线程拆分任务,线程数建议与 CPU 核心数一致(避免切换开销)。
**IO 密集型(如文件读写、网络下载):**适合多线程重叠 IO 操作(如多线程下载同一文件的不同片段),线程数可多于 CPU 核心数(因为大部分时间在等待 IO)
2.线程的缺点
1.性能损失(创建过多时) :计算密集型应用中,线程数超过 CPU 核心数会导致频繁切换,反而降低效率。
2.健壮性低 :线程共享进程资源,一个线程的异常(如除零、野指针)会触发进程终止,所有线程随之崩溃。
3.缺乏访问控制 :线程共享地址空间,无天然的隔离机制,容易出现数据竞争(如多个线程同时修改全局变量)。
**4.编程难度高:**需要处理线程同步(如锁、信号量)、数据一致性等问题,容易引入 bug。
线程切换成本低的核心是:
同进程内的线程共享地址空间和页表,切换时仅需替换线程私有 PCB 上下文(寄存器、栈指针等),不用切换页表,TLB 和 CPU 缓存不会大规模失效;而进程切换要换页表和整个资源容器,缓存全失效,开销远大于线程切换。
Linux的线程控制
1.POSIX 线程库
POSIX 线程库是一套以 "pthread_" 为前缀的线程操作函数集合 ,使用时需包含头文件<pthread.h>,编译链接时要加-lpthread选项(不过新版本系统中线程库可能已整合到标准库,无需显式加此选项)。
2.创建线程的函数
函数phread_create
头文件:
#include <pthread.h>
功能:
在当前进程内创建一个新的线程,新线程与原线程共享进程地址空间(mm_struct、页表、物理内存资源),仅独立维护执行上下文(寄存器、栈指针等),实现进程内多执行流并行
原型:
int pthread_create (pthread_t *thread, const pthread_attr_t *attr,void *(*start_routine) (void *), void *arg);
参数:
thread:返回线程ID
attr:设置线程的属性,attr为NULL表⽰使⽤默认属性
start_routine:是个函数地址,线程启动后要执⾏的函数
arg:传给线程启动函数的参数
返回值:
成功返回 0;
失败返回非 0 错误码(errno 不生效,需通过返回值判断错误类型),
常见错误码:EAGAIN:系统资源不足(如超出线程数上限、无空闲 task_struct / 页框)
EINVAL:attr 参数配置的属性非法(如栈大小小于 PTHREAD_STACK_MIN)
EPERM:无权限设置指定的线程属性(如调度策略 / 优先级)3.创建线程代码
#include<string>
#include<unistd.h>
#include <pthread.h>
void* rountine(void *arg)
{
std::string name=(char*)arg;
while(true)
{
std::cout<<"我新线程,name:"<<name<<"pid:"<<getpid()<<std::endl;
sleep(1);
}
return nullptr;
}
int main()
{
pthread_t tid=0;
pthread_create(&tid,nullptr,rountine,(void*)"thread-1");
while(true)
{
std::cout<<"我是主进程..."<<"pid:"<<getpid()<<std::endl;
sleep(1);
}
return 0;
}makefile代码
ss:1.cc
g++ -o $@ $^ -lpthread//要加线程库
//新版本系统中线程库可能已整合到标准库,建议加
.PHONY:clean
clean:
rm -f ss运行结果:
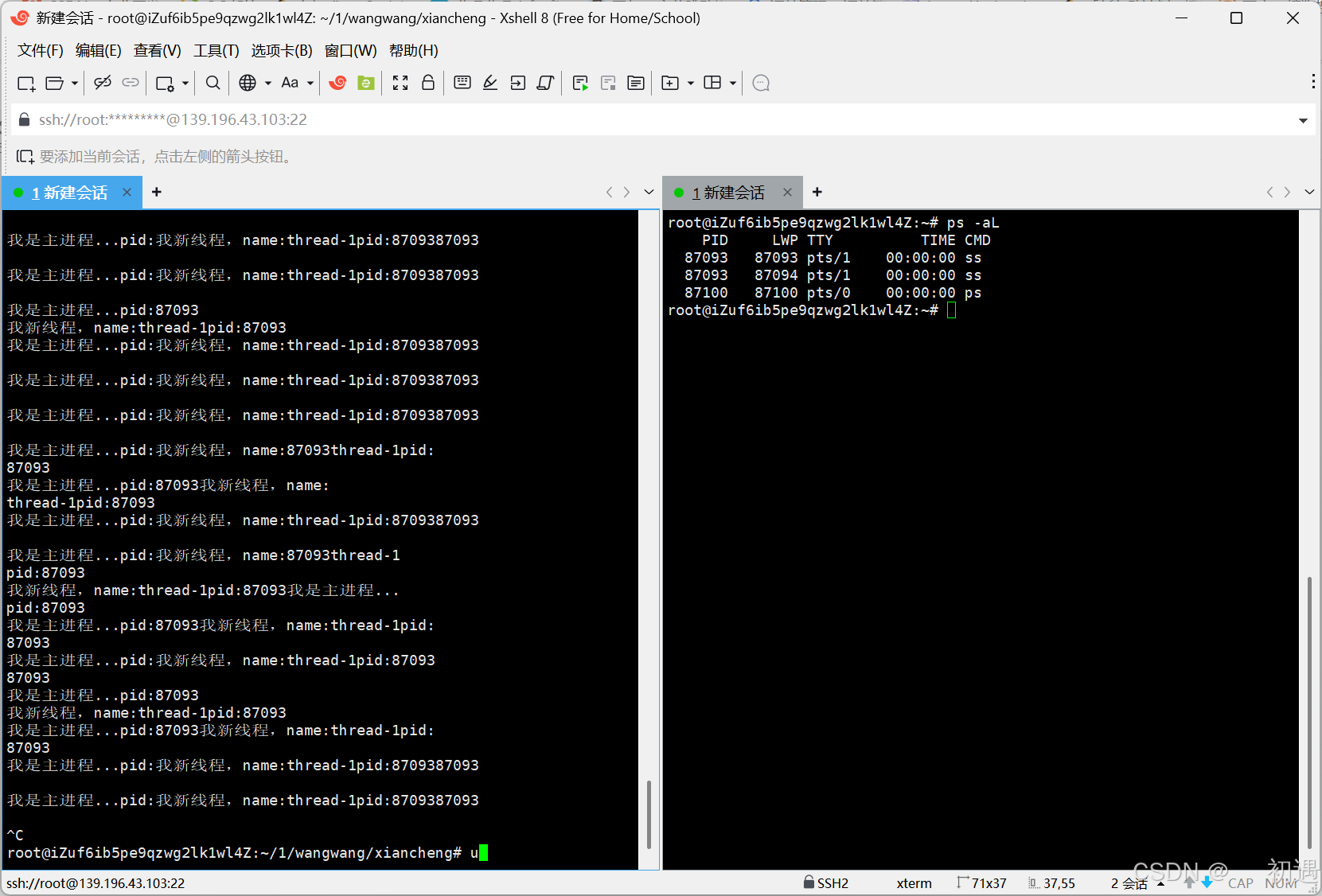
4.Linux线程是轻量级进程

两个线程的 PID 相同(属于同一个进程)
LWP(轻量级进程号)不同,证明内核中是两个独立的轻量级进程。
结论:
- Linux 内核中只有 "轻量级进程",线程是用户级概念,由 pthread 库封装实现。
- CPU 调度的是轻量级进程(LWP),单进程的 LWP 与 PID 相等
5.线程异常导致进程崩溃
上面代码加了一些代码

新线程中执行除零操作(触发浮点错误)
总结:
- 线程的异常会触发内核发送信号给进程,进程默认处理方式是终止,因此所有线程都会随之崩溃。
- 结论:多线程程序的健壮性依赖于每个线程的稳定性,单个线程的错误会导致 "全盘崩溃"。、
6..线程打印信息混乱的原因
多个线程同时向显示器打印时,信息会混杂在一起,原因是:显示器是共享资源(本质是文件),多个线程同时写入时,没有同步机制,会出现 "我写一半你写一半" 的情况(竞态条件)。
7.关于处理线程的函数
7.1线程的等待
- 如果不等待,会造成 "类似僵尸进程的问题"------ 内存泄漏(没有僵尸线程的说法,但本质是资源没回收)。
- 进程中父子进程需要
wait,线程中主线程需要pthread_join,逻辑一致。
函数pthread_join(tid, ...)
功能:
等待线程结束
原型
int pthread_join(pthread_t thread, void **value_ptr);
参数:
thread:线程ID
value_ptr:它指向⼀个指针,后者指向线程的返回值
返回值:成功返回0;失败返回错误码
#include<iostream>
#include<string>
#include<unistd.h>
#include<pthread.h>
#include<stdio.h>
void show(pthread_t tid)
{
printf("tid:0x%lx\n",tid);
}
std::string F(const pthread_t &tid)
{
char id[66];
snprintf(id,sizeof(id),"0x%lx",tid);
return id;
}
void* routine(void*args)
{
std::string name=(char*)args;
int cout=5;
pthread_t tid=pthread_self();
while(true)
{
std::cout<<"我是新线程,name:"<<name<<",tid:"<<F(tid)<<std::endl;
sleep(1);
}
return nullptr;
}
int main()
{
pthread_t tid;
int n=pthread_create(&tid,nullptr,routine,(void*)"thread-1");
(void)n;
show(tid);
pthread_join(tid,nullptr);
while(true)
{
std::cout<<"我是Main线程,tid:"<<",tid:"<<F(pthread_self())<<std::endl;
sleep(1);
}
return 0;
}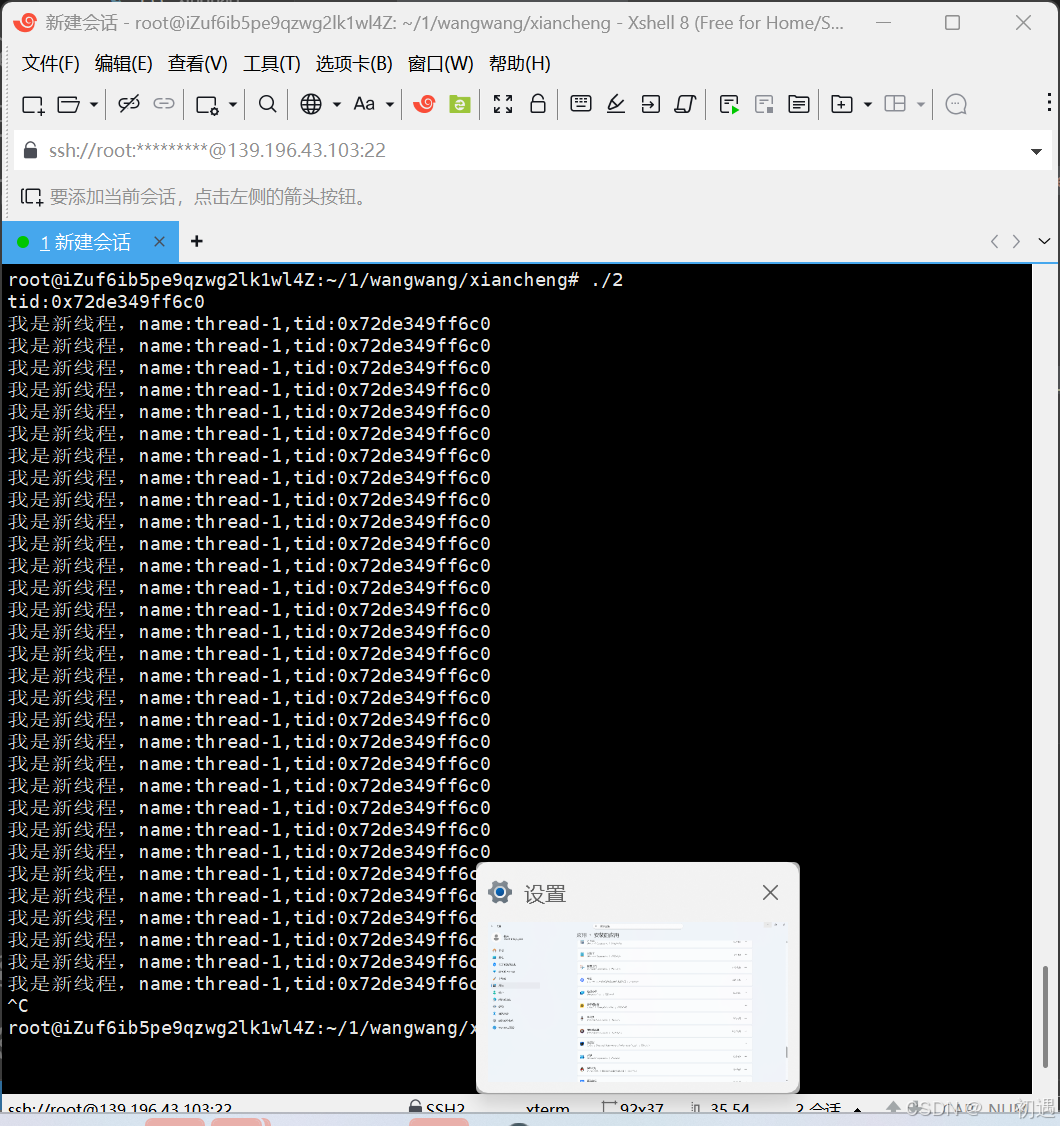
运行结果:
根据代码 **int n=pthread_create(&tid,nullptr,routine,(void*)"thread-1");**可以看出这个tid就是新线程的ID。
在代码里**,pthread_join(tid, nullptr) 的 tid 是新线程 ID,主线程调用该函数后,会一直阻塞等待这个新线程退出**;但新线程是死循环不会停,所以主线程卡着不动,只有新线程持续打印,主线程的循环永远执行不到。
8.线程的禁止
1.return(最常用)
线程从入口函数 return,代表线程正常终止。
返回值会被存入 TCB,供 pthread_join 获取。
适用场景:线程完成任务后正常退出,是最佳实践。
线程内部主动终止:pthread_exit
头文件:
#include <pthread.h>
功能:
主动终止当前调用线程的执行,释放线程自身的执行上下文(寄存器、栈指针等),但不会释放进程级资源(如共享内存、文件描述符);
线程退出状态会存入线程控制块(TCB),供 pthread_join 函数获取;若主线程调用该函数,仅终止主线程,其他子线程仍可继续执行(区别于 exit 终止整个进程)。
原型:
void pthread_exit(void *retval);
参数: retval: 线程退出时的返回值,类型为 void*,可传递任意数据的地址(如整型、结构体、字符串等);
该值会被存入 TCB,供 pthread_join 的第二个参数接收;注意:禁止传递线程局部变量的地址(线程退出后局部变量内存被释放,主线程读取会导致野指针),推荐使用动态内存(malloc)、全局变量或静态变量传递。
返回值:无返回值(void);因为调用该函数后线程立即终止,不会回到调用点继续执行,因此不存在 "返回" 的场景;若线程无需返回数据,可传递 NULL 作为 retval(即 pthread_exit (NULL))。
补充关键注意事项
线程入口函数中 return 等价于调用 pthread_exit:如线程函数 return (void*) 100; 与 pthread_exit ((void*) 100); 效果完全一致;
若主线程未调用 pthread_join 回收子线程,子线程退出后会成为 "僵尸线程",占用 TCB 资源;
若子线程未调用 pthread_exit/return 且无其他终止方式,线程会一直运行至入口函数结束;
与 exit 区别:pthread_exit 仅终止当前线程,exit 会终止整个进程(所有线程均退出)。线程主动取消:pthread_cancel
头文件:
#include <pthread.h>
功能:
由一个线程(发起者)向另一个线程(目标线程)发送 "取消请求",请求目标线程终止执行;目标线程收到请求后,会在 "取消点"(如系统调用、阻塞操作)处响应并终止;若目标线程未处于取消点,需主动调用 pthread_testcancel () 触发检查;被取消的线程退出状态为 PTHREAD_CANCELED(系统定义的特殊值)。
原型:int pthread_cancel(pthread_t thread);
参数:thread: 目标线程的线程 ID(由 pthread_create 返回);注意:必须确保目标线程已启动(pthread_create 成功后),否则取消请求无意义;若目标线程已退出,调用该函数不会产生任何效果。
返回值:成功返回 0;失败返回非 0 错误码(errno 不生效,需通过返回值判断),常见错误码:ESRCH:目标线程 ID 不存在(如线程未创建、已退出);EINVAL:目标线程处于不可取消状态(通过 pthread_setcancelstate 设置);EPERM:无权限取消目标线程(如目标线程是内核线程或具有更高权限)。注意事项:
必须确保目标线程已经启动,否则取消无意义。
被取消的线程,退出码是PTHREAD_CANCELED(值为 1)。
主线程取消新线程后,仍需通过 pthread_join 回收资源。
绝对禁忌:调用 exit
exit 的本质是终止整个进程,而非单个线程。
任何线程调用 exit,都会导致当前进程的所有线程全部退出,无论其他线程是否执行完毕。
除非故意终止整个进程,否则线程中绝对不能调用 exit。
线程分离
1