IO是编程语言中一个很重要的应用,在之前的内容中我们已经学习过C++的IO流。而本期我们将就Linux系统对底层角度的IO进行学习理解
相关代码已经上传至作者的个人gitee:楼田莉子/Linux学习喜欢请点个赞谢谢
目录
[1. 绝对定位](#1. 绝对定位)
[2. 相对定位](#2. 相对定位)
[3. 文件末尾操作](#3. 文件末尾操作)
[4. 数据库式记录访问](#4. 数据库式记录访问)
文件概念的理解和总结
狭义理解
• 文件在磁盘里
• 磁盘是永久性存储介质,因此文件在磁盘上的存储是永久性的
• 磁盘是外设(既是输出设备也是输入设备)
• 磁盘上的文件 本质是对文件的所有操作,都是对外设的输入和输出 简称 IO
广义理解
• Linux 下一切皆文件(键盘、显示器、网卡、磁盘...... 这些都是抽象化的过程)(后面会讲如何去理解)
文件操作的归类认知
• 对于 0KB 的空文件是占用磁盘空间的
• 文件是文件属性(元数据)和文件内容的集合(文件 = 属性(元数据)+ 内容)
• 所有的文件操作本质是文件内容操作和文件属性操作
系统角度
• 对文件的操作本质是进程对文件的操作
• 磁盘的管理者是操作系统
• 文件的读写本质不是通过 C 语言 / C++ 的库函数来操作的(这些库函数只是为用户提供方便),而是通过文件相关的系统调用接口来实现的
文件理解的总结
文件=文件的内容+文件的属性(元数据)
未来对文件的操作,主要是针对文件的内容和属性进行操作
对文件进行操作首先要找到其文件然后才能打开其文件。找到对应的文件需要对应的文件路径和文件名,这个文件路径是必须要有的,要么依赖于用户自己提供,要么使用进程自己的cwd
打开文件依赖于fopen函数来实现,在程序运行后动态打开文件。也就是说文件的打开依赖于进程,也是由进程来打开文件。通过这种方式动态维持自己的当前工作路径。
打开文件就是把文件加载到内存中,对文件的操作本质上是进程通过CPU对加载到内存中的文件进行操作
文件分为被打开的文件和没有被打开的文件。从位置上分为内存级打开文件和磁盘上的文件。
Linux系统中可以存在多个被打开的文件。那么操作系统内如何管理这么多的文件?先描述再管理。
C/C++文件IO接口
C语言打开文件
我们可以以以下方式打开文件(打开的文件最后必须关闭,否则会内存泄漏)
cpp
#include <stdio.h>
#include <sys/types.h>
#include <string.h>
#include <stdlib.h>
int main()
{
const char* filename = "myfile.txt";
//打开文件
FILE* fp = fopen(filename, "w+"); // 读写模式,如果文件不存在则创建
if (!fp) {
printf("fopen error!\n");
return 1;
}
fclose(fp);
printf("程序正常退出\n");
return 0;
}在程序的当前路径下,那系统怎么知道程序的当前路径在哪里呢?
我们可以利用这两个命令来确定
bash
#获取进程PID
ps aux | grep firefox
#查看进程目录
ls -l /proc/1234这有一个表格帮助理解。
| 文件/目录名 | 作用说明 |
|---|---|
exe |
一个符号链接,指向进程实际执行的二进制文件路径。 |
cwd |
一个符号链接,指向进程的当前工作目录。 |
fd |
一个目录 ,包含了进程打开的所有文件描述符,每个描述符都是一个指向实际文件的符号链接。 |
status |
一个文本文件,以易读格式提供进程的状态信息,如内存使用、信号、线程数等。 |
cmdline |
一个文本文件,包含启动进程时使用的完整命令行,参数以空字符分隔。 |
environ |
一个文本文件,包含进程的环境变量,各项之间以空字符分隔。 |
打开文件,本质是进程打开,所以,进程知道自己在哪里,即便文件不带路径,进程也知道。由此OS就能知道要创建的文件放在哪里。
C语言写文件
cpp
#include <stdio.h>
#include <sys/types.h>
#include <string.h>
#include <stdlib.h>
int main()
{
const char* filename = "myfile.txt";
// 打开文件
FILE* fp = fopen(filename, "w+"); // 读写模式,如果文件不存在则创建
if (!fp) {
printf("fopen error!\n");
return 1;
}
// 写入文件
int cnt = 1;
while (cnt <= 10) {
cnt++;
const char* s = "hello world\n";
fputs(s, fp);
}
fclose(fp);
printf("程序正常退出\n");
return 0;
}C语言读文件
cpp
#include <stdio.h>
#include <sys/types.h>
#include <string.h>
#include <stdlib.h>
int main()
{
const char* filename = "myfile.txt";
// 打开文件
FILE* fp = fopen(filename, "w+"); // 读写模式,如果文件不存在则创建
if (!fp) {
printf("fopen error!\n");
return 1;
}
// 写入文件
int cnt = 1;
while (cnt <= 10) {
cnt++;
const char* s = "hello world\n";
fputs(s, fp);
}
//写入后重置文件指针到开头
rewind(fp); // 或者使用 fseek(fp, 0, SEEK_SET);
// 读文件
char buf[1024];
printf("读取文件内容:\n");
while (1)
{
// 修正3:使用sizeof(buf)-1来确保有空间添加'\0'
size_t s = fread(buf, 1, sizeof(buf) - 1, fp);
if (s > 0)
{
buf[s] = 0; // 添加字符串结束符
printf("%s", buf);
}
else
{
// 修正4:在fread返回0时检查是否到达文件末尾
if (feof(fp))
{
printf("\n已到达文件末尾\n");
break;
}
else if (ferror(fp))
{
printf("读取文件时发生错误\n");
break;
}
}
}
fclose(fp);
printf("程序正常退出\n");
return 0;
}stdin/stdout/stderr
cpp
// 在stdio.h中定义
extern FILE *stdin; // 标准输入流
extern FILE *stdout; // 标准输出流
extern FILE *stderr; // 标准错误流缓冲类型对比
| 流类型 | 缓冲策略 | 刷新时机 | 性能影响 |
|---|---|---|---|
| stdin | 行缓冲 | 遇到换行符或缓冲区满 | 中等 |
| stdout | 行缓冲(终端) 全缓冲(重定向) | 换行符、缓冲区满或程序结束 | 高 |
| stderr | 无缓冲 | 立即输出 | 低 |
完整对比
| 特性 | stdin | stdout | stderr |
|---|---|---|---|
| 文件描述符 | 0 | 1 | 2 |
| FILE指针 | stdin |
stdout |
stderr |
| 默认设备 | 键盘 | 屏幕 | 屏幕 |
| 缓冲类型 | 行缓冲 | 行缓冲/全缓冲 | 无缓冲 |
| 刷新策略 | 换行符触发 | 换行符/程序结束 | 立即刷新 |
| 重定向符号 | < 或 0< |
> 或 1> |
2> |
| 主要用途 | 程序输入 | 正常输出 | 错误/诊断信息 |
| 性能考虑 | 批量读取更高效 | 缓冲提高性能 | 实时性优先 |
| 线程安全 | 线程安全(通常) | 线程安全(通常) | 线程安全(通常) |
| 关闭影响 | 导致读取失败 | 导致写入失败 | 错误信息丢失 |
系统IO
打开文件的方式不仅仅是fopen,ifstream等流式,语言层的方案,其实系统才是打开文件最底层的方案。不过,在学习系统文件IO之前,先要了解下如何给函数传递标志位,该方法在系统文件IO接口中会使用到:
传递标志位
传递标志位 是一种在Linux系统调用中通过单个整型参数传递多个独立选项的技术。它利用整数的二进制位来表示不同的功能开关,通过位运算来组合和检查这些选项。
位操作原理
cpp
// 标志位定义(来自fcntl.h)
#define O_RDONLY 00000000 // 只读
#define O_WRONLY 00000001 // 只写
#define O_RDWR 00000002 // 读写
#define O_CREAT 00000100 // 创建文件
#define O_EXCL 00000200 // 独占创建
#define O_TRUNC 00001000 // 截断文件
#define O_APPEND 00002000 // 追加模式
#define O_NONBLOCK 00004000 // 非阻塞模式内核标志位处理
cpp
// 内核系统调用处理(简化示例)
SYSCALL_DEFINE3(open, const char __user *, filename, int, flags, umode_t, mode)
{
// 解析flags
if (flags & O_CREAT) {
// 处理文件创建逻辑
}
if (flags & O_TRUNC) {
// 处理文件截断逻辑
}
if (flags & O_APPEND) {
// 设置追加模式
}
// ...
}
cpp
#include <stdio.h>
#define ONE 0x01 // 0000 0001
#define TWO 0x02 // 0000 0010
#define THREE 0x04 // 0000 0100
void func(int flags) {
if (flags & ONE) printf("flags has ONE! ");
if (flags & TWO) printf("flags has TWO! ");
if (flags & THREE) printf("flags has THREE! ");
printf("\n");
}
int main()
{
func(ONE);
func(THREE);
func(ONE | TWO);
func(ONE | THREE | TWO);
return 0;
}open函数介绍
open函数的语法如下:
cpp
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
pathname: 要打开或创建的⽬标⽂件
flags: 打开⽂件时,可以传⼊多个参数选项,⽤下⾯的⼀个或者多个常量进⾏"或"运算,构成flags。
参数:
O_RDONLY: 只读打开
O_WRONLY: 只写打开
O_RDWR : 读,写打开
这三个常量,必须指定⼀个且只能指定⼀个
O_CREAT : 若⽂件不存在,则创建它。需要使⽤mode选项,来指明新⽂件的访问权限
O_APPEND: 追加写
返回值:
成功:新打开的⽂件描述符
失败:-1对于打开已经存在的文件两个参数的open就足够了。如果文件不存在,就创建一个文件,就需要给一个权限(mode),这就需要三个参数的open
参数介绍
pathname
pathname是指向文件路径字符串的指针,用于定位文件系统中的目标文件。
核心作用:
-
文件系统寻址:提供从根目录或当前目录到目标文件的完整导航路径
-
路径解析起点:内核以此开始遍历目录树,逐级查找目标文件
使用如下:
cpp
// 路径形式多样
int fd1 = open("/etc/passwd", O_RDONLY); // 绝对路径
int fd2 = open("data.txt", O_RDWR); // 相对路径(当前目录)
int fd3 = open("../config/settings.conf", O_RDONLY); // 相对路径(父目录)
// 内核的路径解析过程
// 1. 获取当前进程的当前工作目录(current->fs->pwd)
// 2. 按"/"分割路径字符串
// 3. 逐级查找目录项(dentry缓存)
// 4. 权限检查(对路径中每个目录需有执行权限)
// 5. 符号链接处理(默认跟随,除非使用O_NOFOLLOW)关键特性:
-
路径长度受
PATH_MAX限制(通常4096字节) -
路径解析是相对昂贵的操作,可能需要多次磁盘I/O
-
特殊路径处理:
/dev/null、/proc/self/fd/等 -
错误情况:
ENOENT(路径不存在)、EACCES(权限不足)、ENAMETOOLONG(路径过长)
flags
flags是一个整型位掩码,通过位或操作组合多个独立选项,精确控制文件的打开方式和后续操作行为。
主要内容如下:
cpp
// 基础访问模式(互斥,必须三选一)
#define O_RDONLY 00 // 只读
#define O_WRONLY 01 // 只写
#define O_RDWR 02 // 读写
// 创建与截断标志
#define O_CREAT 0000100 // 不存在则创建(需配合mode参数)
#define O_EXCL 0000200 // 独占创建(与O_CREAT配合实现原子性)
#define O_TRUNC 0001000 // 打开时截断文件为0字节
// 状态与行为标志
#define O_APPEND 0002000 // 追加模式(写操作前自动定位到文件末尾)
#define O_NONBLOCK 0004000 // 非阻塞模式
#define O_SYNC 04010000 // 同步写入(数据和元数据都落盘)
#define O_DSYNC 04000000 // 同步写入(仅数据落盘)
#define O_DIRECT 00040000 // 直接I/O(绕过页缓存)flags可以做组合
| 类别 | 标志(宏) | 数值(八进制) | 含义与作用 | 使用场景与说明 |
|---|---|---|---|---|
| 访问模式 (必选其一) | O_RDONLY |
00 |
只读打开。 | 仅读取文件内容,不可写入。 |
O_WRONLY |
01 |
只写打开。 | 仅向文件写入数据,不可读取。 | |
O_RDWR |
02 |
读写打开。 | 可读取也可写入文件。 | |
| 创建与截断 | O_CREAT |
0100 |
文件不存在则创建 。需提供mode参数。 |
实现"存在即打开,不存在则创建"的逻辑。 |
O_EXCL |
0200 |
排他性创建 。与O_CREAT同用时,若文件已存在,则open失败。 |
用于实现互斥锁、确保原子性创建,是创建锁文件的经典方式。 | |
O_TRUNC |
01000 |
打开时清空(截断为0字节)。 | 用于覆盖写,清空旧日志、配置文件等。 | |
| 状态标志 | O_APPEND |
02000 |
追加模式。每次写操作前,文件偏移量自动移动到末尾。 | 写日志、多进程并发写同一文件时,避免覆盖。 |
O_NONBLOCK |
04000 |
非阻塞模式。打开及后续I/O操作均不阻塞进程。 | 打开FIFO、字符设备等特殊文件时使用,避免 read/write 挂起。 |
|
| 同步与缓存 (影响性能与一致性) | O_SYNC |
04010000 |
同步写入 (数据与属性)。每次write都等待数据物理写入磁盘。 |
对数据一致性要求极高的场景(如数据库事务日志),但性能损耗大。 |
O_DSYNC |
04000000 |
同步写入 (仅数据)。每次write等待数据写入,但文件属性更新可延迟。 |
比O_SYNC稍高效,当只关心数据本身时使用。 |
|
O_DIRECT |
040000 |
直接I/O 。尝试绕过内核页缓存,直接与存储设备交互。 | 自缓存应用(如高性能数据库),避免双重缓存,但使用约束严格。 | |
| 文件描述符相关 | O_CLOEXEC |
02000000 |
执行时关闭 。为新文件描述符设置 close-on-exec 标志。 | 多线程安全 地避免文件描述符在fork+exec后泄漏给子进程。 |
| 特殊文件与扩展 | O_NOFOLLOW |
0400000 |
不跟随符号链接 。若pathname是符号链接,则打开失败。 |
提升安全性,防止符号链接劫持。 |
O_TMPFILE |
020000000 |
创建匿名临时文件。文件不存在于目录树中,关闭后自动删除。 | (Linux特有)创建绝对安全的临时文件,无竞态条件。 | |
| 路径解析 | O_NOCTTY |
0100000 |
若pathname指向终端设备,不将其设为控制终端。 |
后台进程打开终端设备时,避免意外获取控制终端。 |
mode
mode参数仅在flags包含O_CREAT时有效,用于指定新创建文件的访问权限。
cpp
// 常见权限模式
int fd1 = open("data.txt", O_CREAT | O_WRONLY, 0644); // -rw-r--r--
int fd2 = open("script.sh", O_CREAT | O_WRONLY, 0755); // -rwxr-xr-x
int fd3 = open("secret.key", O_CREAT | O_WRONLY, 0600); // -rw-------
// 临时修改umask
mode_t old_mask = umask(0); // 临时设置umask为0
int fd4 = open("temp.txt", O_CREAT | O_WRONLY, 0666); // 实际权限就是0666
umask(old_mask); // 恢复原umask文件最终权限=mode&~umask
-
mode:你的程序请求的权限。 -
umask:进程的用户权限掩码,用于"屏蔽"或"剔除"掉不希望赋予的权限位。 -
& ~umask:这是一个位操作,结果是移除mode中所有被umask屏蔽的位。
完整权限展示:
1. 标准权限位 (最常用)
控制基本的读、写、执行权限。
| 权限类别 | 八进制值 | 宏定义 | 含义 |
|---|---|---|---|
| 用户(Owner) | 0400 |
S_IRUSR |
文件所有者可 读 |
0200 |
S_IWUSR |
文件所有者可 写 | |
0100 |
S_IXUSR |
文件所有者可 执行 (对于目录,是可进入搜索) | |
| 组(Group) | 0040 |
S_IRGRP |
所属用户组可 读 |
0020 |
S_IWGRP |
所属用户组可 写 | |
0010 |
S_IXGRP |
所属用户组可 执行 | |
| 其他(Others) | 0004 |
S_IROTH |
其他用户可 读 |
0002 |
S_IWOTH |
其他用户可 写 | |
0001 |
S_IXOTH |
其他用户可 执行 |
组合常量:
-
S_IRWXU(0700):用户读、写、执行。 -
S_IRWXG(0070):组读、写、执行。 -
S_IRWXO(0007):其他用户读、写、执行。 -
常用组合 :
0644(S_IRUSR|S_IWUSR|S_IRGRP|S_IROTH),0755(S_IRWXU|S_IRGRP|S_IXGRP|S_IROTH|S_IXOTH)。
2. 特殊权限位 (需谨慎使用)
这些位具有特殊功能,通常用于系统程序。
| 八进制值 | 宏定义 | 含义与风险 |
|---|---|---|
04000 |
S_ISUID |
Set-User-ID :执行此文件时,进程的有效用户ID将设置为文件所有者的ID。(安全风险高) |
02000 |
S_ISGID |
Set-Group-ID:1) 对文件:执行时,进程的有效组ID设为文件所属组ID。2) 对目录:在该目录下创建的新文件将继承目录的组ID。 |
01000 |
S_ISVTX |
Sticky Bit (粘滞位):通常用于目录(如/tmp),仅文件所有者、目录所有者或root才能删除或重命名其中的文件。 |
3. 文件类型位 (由内核设置,不应在open中指定)
如 S_IFREG (普通文件)、S_IFDIR (目录) 等,它们由内核在创建文件时自动设置,不应在 open 的 mode 参数中手动指定。指定了也会被忽略。
| 权限位类型 | 符号常量 (示例) | 八进制值 | 影响对象 | 作用描述 |
|---|---|---|---|---|
| 用户权限 | S_IRUSR, S_IWUSR, S_IXUSR |
0400, 0200, 0100 |
文件所有者 | 控制所有者的读、写、执行权 |
| 组权限 | S_IRGRP, S_IWGRP, S_IXGRP |
0040, 0020, 0010 |
文件所属组 | 控制组成员的基本权限 |
| 其他用户权限 | S_IROTH, S_IWOTH, S_IXOTH |
0004, 0002, 0001 |
其他所有用户 | 控制其他用户的访问权限 |
| Set-User-ID | S_ISUID |
04000 |
可执行文件 | 运行时将进程的有效用户ID设为文件所有者 |
| Set-Group-ID | S_ISGID |
02000 |
文件/目录 | 对文件:运行时有效组ID设为文件组;对目录:新建文件继承目录组ID |
| 粘滞位 | S_ISVTX |
01000 |
目录 | 保护目录内文件,防止非所有者删除(如/tmp) |
总结
| 参数 | pathname |
flags |
mode |
|---|---|---|---|
| 类型 | const char * |
int |
mode_t(本质是unsigned int) |
| 必需性 | 必需 | 必需 | 条件必需(仅当flags含O_CREAT时需要) |
| 作用 | 标识目标文件位置 | 控制文件的打开方式和行为 | 指定新创建文件的访问权限 |
| 有效条件 | 有效文件系统路径 | 合法的标志位组合 | 当且仅当flags & O_CREAT |
| 内核处理 | 路径解析、inode查找 | 打开模式设置、文件创建/截断 | 权限位验证、umask应用 |
| 值域/格式 | 字符串(最大PATH_MAX) | 位掩码(预定义常量位或组合) | 12位权限位(9位常规+3位特殊) |
| 典型值 | "/home/user/file" "../data/log" |
O_RDONLY `O_WRONLY |
O_CREAT |
| 错误示例 | NULL指针、空字符串、不存在路径 |
互斥标志组合(如O_RDONLY|O_WRONLY) | 无效权限位(如07777) |
| 默认/忽略 | 无默认,必须显式指定 | 无默认,必须显式指定 | 当不需要时被内核忽略 |
| 影响范围 | 单次调用 | 影响本次打开及后续所有I/O操作 | 仅影响文件创建时的初始权限 |
| 性能考量 | 路径深度影响解析开销 | 某些标志(O_SYNC)显著影响性能 | 几乎无性能影响 |
| 安全考量 | 符号链接攻击、路径遍历攻击 | 竞态条件(TOCTTOU)、权限提升 | umask泄漏、过度宽松的权限 |
代码测试
cpp
#include<stdio.h>
#include<sys/types.h>
//确保只有一个比特位为1
#define ONE (1<<0)
#define TWO (1<<1)
#define THREE (1<<2)
#define FOUR (1<<3)
#define FIVE (1<<4)
#define SIX (1<<5)
#define SEVEN (1<<6)
#define EIGHT (1<<7)
#define NINE (1<<8)
//用&来检测
//用|来级联
void Print(int flags)
{
if(flags&ONE)
printf("ONE\n");
if(flags&TWO)
printf("TWO\n");
if(flags&THREE)
printf("THREE\n");
if(flags&FOUR)
printf("FOUR\n");
if(flags&FIVE)
printf("FIVE\n");
if(flags&SIX)
printf("SIX\n");
if(flags&SEVEN)
printf("SEVEN\n");
if(flags&EIGHT)
printf("EIGHT\n");
if(flags&NINE)
printf("NINE\n");
}
int main()
{
Print(ONE);
Print(ONE|TWO);
Print(ONE|TWO|FIVE);
return 0;
}结果为:

我们接下来以代码举例来展示这些底层API
cpp
#include<stdio.h>
#include<unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include<string.h>
int main()
{
umask(0);
int fd =open("log.txt",O_WRONLY|O_CREAT|O_APPEND,0666);
if(fd<0)
{
perror("failed open file");
return 1;
}
printf("fd:%d\n",fd);
const char* msg="go for a punch";
write(fd,msg,strlen(msg));//这里strlen(msg)不需要+1
//因为\0是C语言的规范,而write是Linux系统底层API,与之无关
close(fd);
return 0;
}结果为:
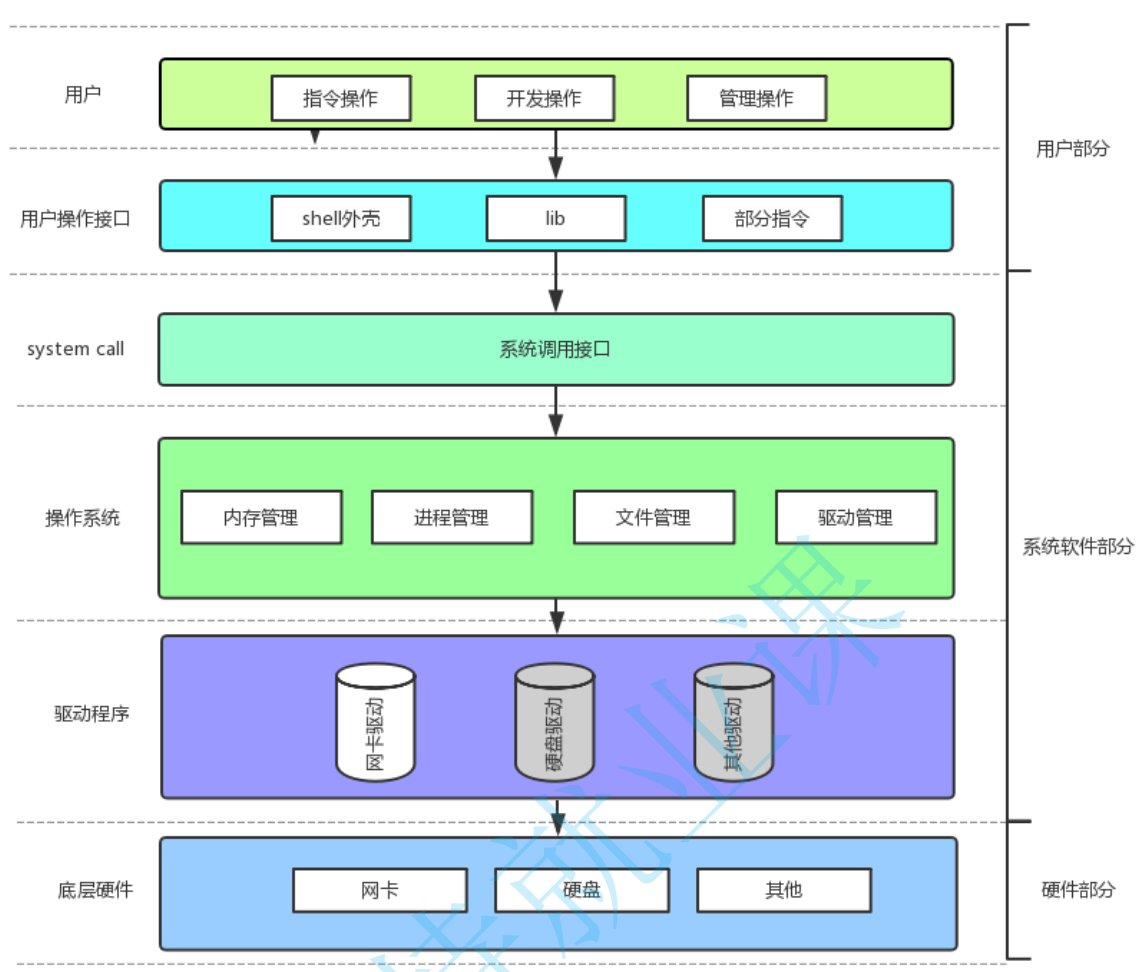
最开始我们用的 fopen fclose fread fwrite 都是C标准库当中的函数,我们称之为库函数(libc)。而 open close read write lseek 都属于系统提供的接口,称之为系统调用接口
那么两者之间有什么区别呢?我们来解析一下
库函数与系统调用接口
就像下图之间的关系
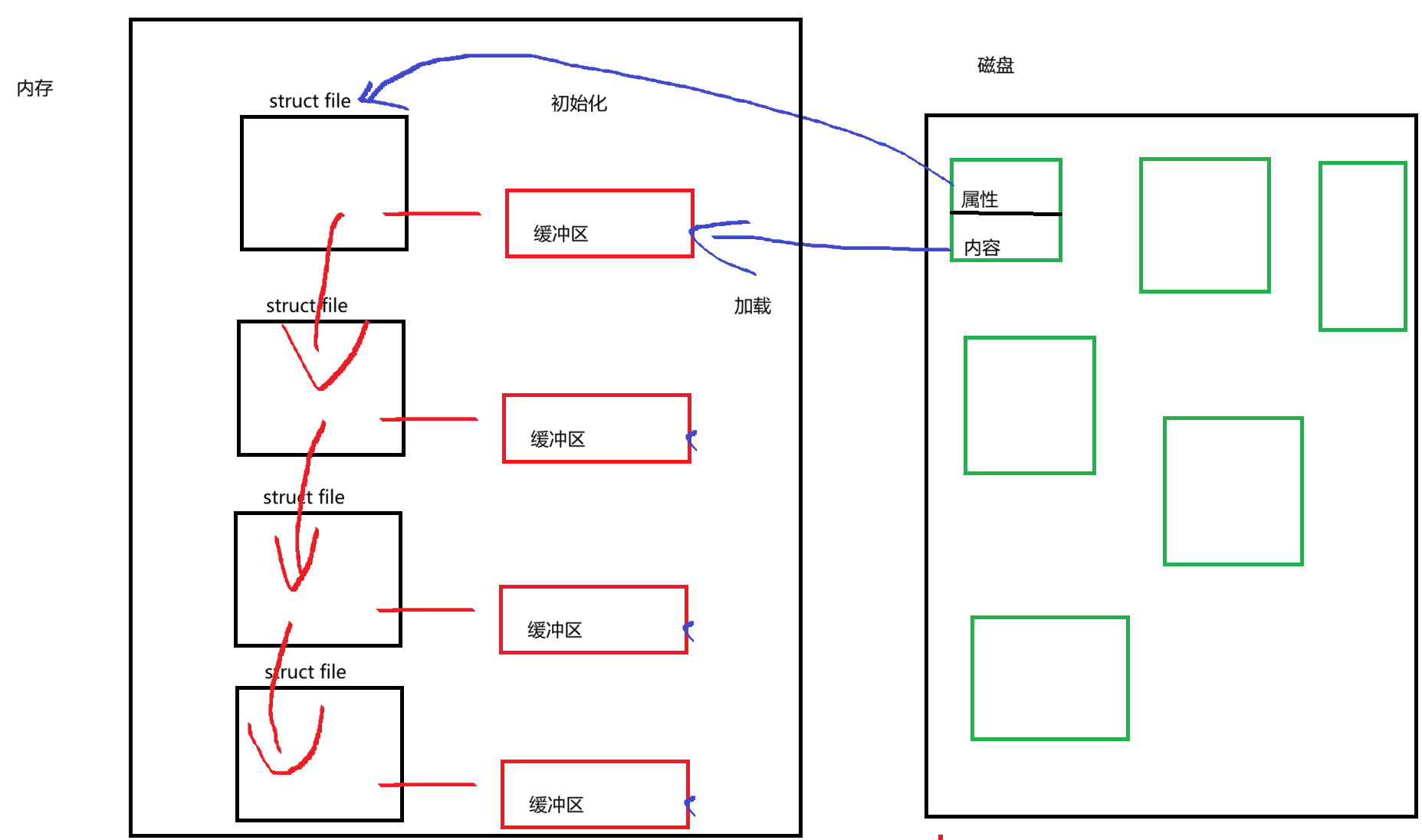
文件描述符fd
文件的本质
文件的本质上是结构体。就像这样
cpp
struct file
{
//直接或间接的包含文件的各种属性
}在OS底层,对文件的管理本质上是链表。每一个文件链表都有缓冲区。
我们知道文件=文件内容+文件属性
对于磁盘中的文件,必须加载到内存中才能对其进行各种操作。将磁盘中文件的属性初始化到链表节点中,将磁盘中文件的内容加载到对应的缓冲区
但是一个进程往往会启动的多个文件。那么进程该如何管理文件呢?OS建立了一种进程到文件的映射关系。那就是文件描述符(图中fd_array,通过对应的数组下标来控制对应的文件)
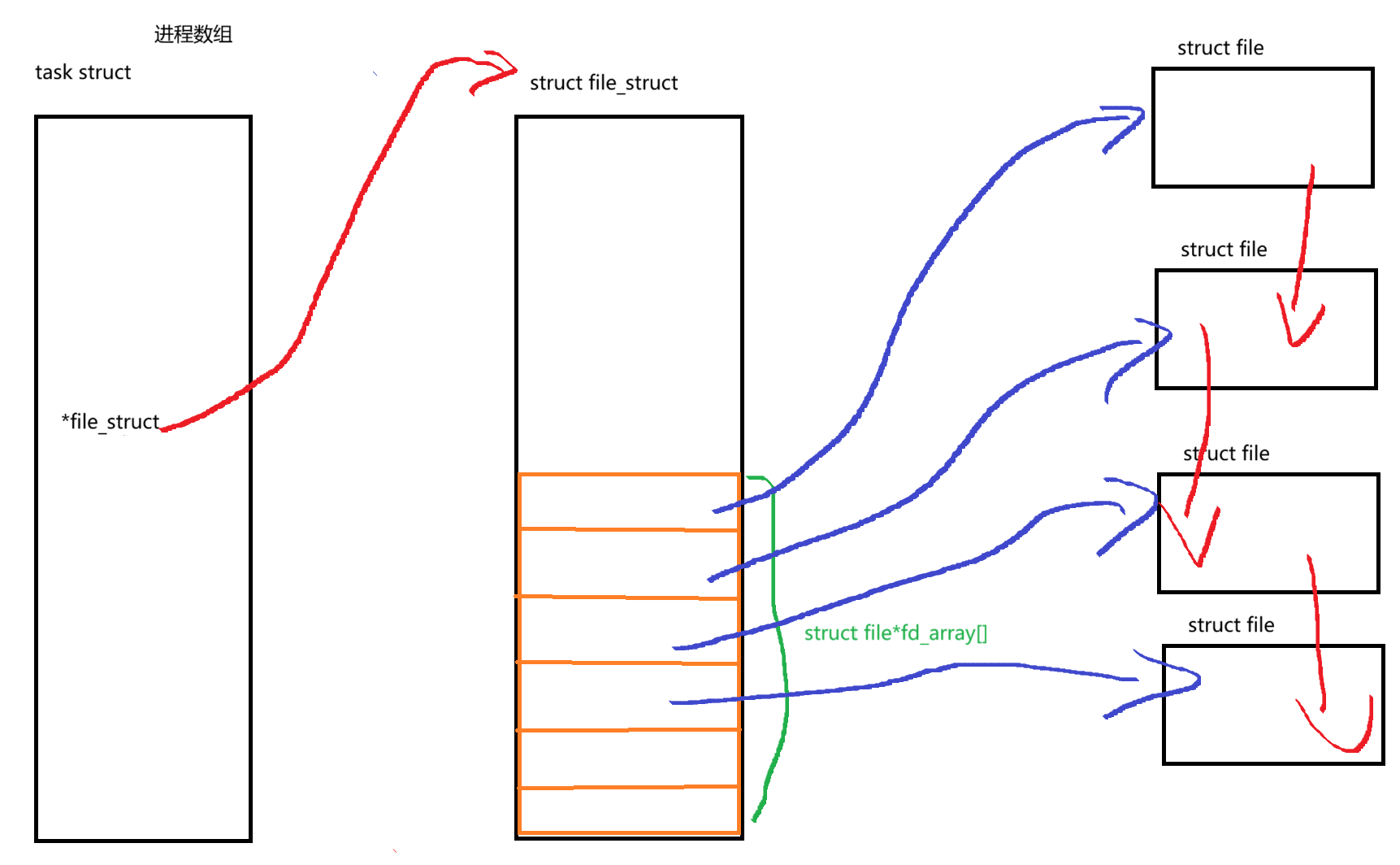
根据以上内容,我们知道文件描述符就是从0开始的小整数。当我们打开文件时,操作系统在内存中要创建相应的数据结构来描述目标文件。于是就有了file结构体。表示一个已经打开的文件对象。而进程执行open系统调用,所以必须让进程和文件关联起来。每个进程都有一个指针*files, 指向一张表files_struct,该表最重要的部分就是包含一个指针数组,每个元素都是一个指向打开文件的指针!所以,本质上,文件描述符就是该数组的下标。所以有文件描述符,就可以找到对应的文件。
标准文件描述符
Linux进程默认情况下会有3个缺省打开的文件描述符,分别是标准输入0, 标准输出1, 标准错误2.
0,1,2对应的物理设备一般是:键盘,显示器,显示器
所以输入输出还可以采用如下方式:
cpp
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>
#include <unistd.h>
int main()
{
char buf[1024];
ssize_t s = read(0, buf, sizeof(buf));
if (s > 0) {
buf[s] = 0;
write(1, buf, strlen(buf));
write(2, buf, strlen(buf));
}
return 0;
}| 文件描述符编号 | 标准POSIX宏常量 | 默认绑定设备 | 用途描述 |
|---|---|---|---|
| 0 | STDIN_FILENO |
键盘(终端输入) | 标准输入:程序读取数据的地方。 |
| 1 | STDOUT_FILENO |
屏幕(终端输出) | 标准输出:程序输出常规结果的地方。 |
| 2 | STDOUT_FILENO |
屏幕(终端输出) | 标准错误:程序输出错误信息和诊断消息的地方。 |
文件描述符的分配规则
我们以代码为例子
cpp
#include<stdio.h>
#include<unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include<string.h>
int main()
{
int fd =open("log.txt",O_WRONLY|O_CREAT|O_APPEND,0666);
if(fd<0)
{
perror("failed open file");
return 1;
}
printf("fd:%d\n",fd);
close(fd);
return 0;
}结果为:

关闭2
cpp
#include<stdio.h>
#include<unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include<string.h>
int main()
{
close(0);
//close(2);
int fd =open("log.txt",O_WRONLY|O_CREAT|O_APPEND,0666);
if(fd<0)
{
perror("failed open file");
return 1;
}
printf("fd:%d\n",fd);
close(fd);
return 0;
}结果为:

关闭0
cpp
#include<stdio.h>
#include<unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include<string.h>
int main()
{
//close(0);
close(2);
int fd =open("log.txt",O_WRONLY|O_CREAT|O_APPEND,0666);
if(fd<0)
{
perror("failed open file");
return 1;
}
printf("fd:%d\n",fd);
close(fd);
return 0;
}结果为:

文件描述符的分配规则:在files_struct数组当中,找到当前没有被使用的最小的一个下标,作为新的文件描述符
在Linux中,访问已经打开的文件,OS只认可fd
系统底层IO和编程语言IO
既然系统底层有IO函数,那么为什么各个编程语言都要自己设计一套IO函数呢?
原因如下:
- 可移植性(最重要原因)
cpp
// 系统调用(Linux特有)
int fd = open("file.txt", O_RDONLY);
// C标准库(可跨平台)
FILE* fp = fopen("file.txt", "r");
// C++标准库(可跨平台)
std::ifstream file("file.txt");-
系统调用是操作系统特定的:Linux、Windows、macOS各有不同
-
C标准库(libc)为不同平台提供统一接口,代码无需修改即可编译运行
-
编程语言的标准库是可移植的契约
- 缓冲机制提高性能
cpp
// 无缓冲的系统调用:每次read/write都是昂贵的系统调用
char buf[1];
for(int i=0; i<1000; i++) {
read(fd, &buf, 1); // 1000次系统调用!
}
// C标准库:带缓冲的流操作
FILE* fp = fopen("file.txt", "r");
for(int i=0; i<1000; i++) {
fgetc(fp); // 可能只需几次系统调用
}-
标准库实现用户空间缓冲,减少系统调用次数
-
系统调用需要从用户态切换到内核态,开销较大
- 更高级的抽象和易用性
cpp
// 原始系统调用:操作繁琐
int fd = open("file.txt", O_RDWR | O_CREAT, 0644);
char buffer[1024];
ssize_t bytes_read = read(fd, buffer, sizeof(buffer));
// C标准库:更简洁
FILE* fp = fopen("file.txt", "r+");
char buffer[1024];
fgets(buffer, sizeof(buffer), fp);
// 格式化IO(系统调用根本没有)
fprintf(fp, "Value: %d, Name: %s\n", 42, "Alice");- 错误处理的标准化
cpp
// 系统调用:需要手动检查errno
int fd = open("nonexistent.txt", O_RDONLY);
if (fd == -1) {
perror("open failed"); // 需要额外处理
}
// C标准库:更一致的错误处理
FILE* fp = fopen("nonexistent.txt", "r");
if (fp == NULL) {
// 错误信息已自动设置
}- 类型安全和接口一致性
cpp
// 系统调用:需要手动检查errno
int fd = open("nonexistent.txt", O_RDONLY);
if (fd == -1) {
perror("open failed"); // 需要额外处理
}
// C标准库:更一致的错误处理
FILE* fp = fopen("nonexistent.txt", "r");
if (fp == NULL) {
// 错误信息已自动设置
}- 功能增强和额外特性
-
格式化IO :
printf,scanf,cout,cin -
按行读写 :
fgets,getline -
二进制数据 :
fread,fwrite处理结构体 -
文件定位 :
fseek,ftell提供更高级的接口
- 安全性和边界检查
cpp
// C标准库提供相对安全的版本
char buf[10];
fgets(buf, sizeof(buf), stdin); // 防止缓冲区溢出
// 对比原始的read
char buf[10];
read(STDIN_FILENO, buf, 100); // 可能溢出!- 面向对象支持(C++)
cpp
// C++利用RAII自动管理资源
{
std::fstream file("data.txt");
// 自动管理打开/关闭
} // 文件自动关闭
// C语言需要手动管理
FILE* fp = fopen("data.txt", "r");
// ... 使用文件
fclose(fp); // 必须记住关闭!什么时候需要直接使用系统调用?
尽管标准库很强大,但有时仍需直接使用系统调用:
-
需要特定控制:如非阻塞IO、异步IO
-
性能关键:绕过缓冲以减少延迟
-
特殊文件描述符操作 :
ioctl,fcntl -
高级功能 :内存映射文件(
mmap)、事件通知(epoll)
重定向
cpp
#include<stdio.h>
#include<unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include<string.h>
int main()
{
//umask(0);
//close(0);
//close(2);
close(1);
int fd =open("log.txt",O_WRONLY|O_CREAT|O_APPEND,0666);
if(fd<0)
{
perror("failed open file");
return 1;
}
printf("fd:%d\n",fd);
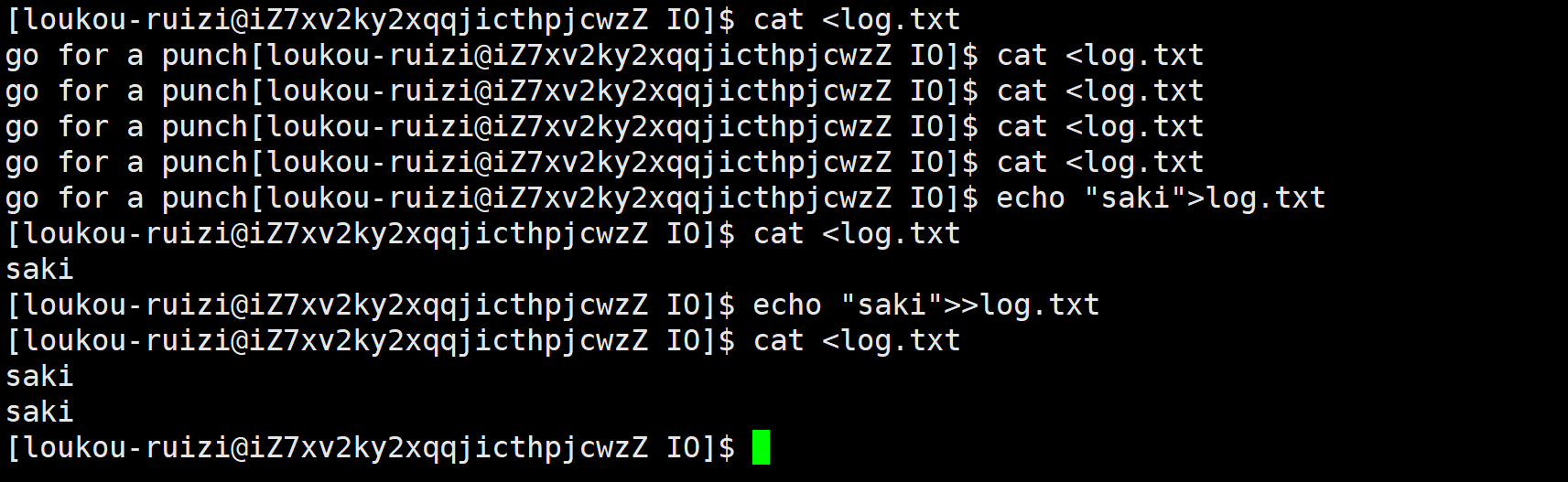
const char* msg="go for a punch";
write(fd,msg,strlen(msg));//这里strlen(msg)不需要+1
////因为\0是C语言的规范,而write是Linux系统底层API,与之无关
close(fd);
return 0;
}但是我们运行后什么都没有发生。

这是因为本来应该输出到显示器上的内容,输出到了文件log.txt当中,其中,fd=1。
关闭1后,原本向1号描述符写的内容直接写到了log.txt文件中而不再写到标准输出
我们来检验一下:

这种现象叫做输出重定向。
常见的重定向有:>,>>,<
效果如下:
同时进程替换的时候也不会影响打开的文件。
使用dup调用fd
dup函数语法如下:
cpp
#include <unistd.h>
int dup(int oldfd);
int dup2(int oldfd, int newfd);
int dup3(int oldfd, int newfd, int flags);dup函数用于复制一个现有的文件描述符 ,创建一个新的文件描述符指向同一个内核文件对象(即同一个打开文件)。这是Linux系统中实现文件描述符重定向和共享的基础机制。
将newfd拷贝覆盖oldfd
参数说明
| 参数 | 类型 | 描述 |
|---|---|---|
oldfd |
int |
要复制的现有文件描述符 |
newfd |
int |
期望的新文件描述符编号(仅dup2/dup3) |
flags |
int |
控制标志(仅dup3) |
返回值
| 返回值 | 含义 |
|---|---|
≥0 |
成功,返回新的文件描述符 |
-1 |
失败,设置errno |
错误代码
| errno值 | 宏定义 | 原因 |
|---|---|---|
9 |
EBADF |
oldfd不是有效的打开文件描述符 |
24 |
EMFILE |
进程已达到文件描述符数量限制 |
11 |
EAGAIN |
已超出RLIMIT_NOFILE资源限制 |
22 |
EINVAL |
dup3中的flags参数无效 |
函数族对比
| 特性 | dup |
dup2 |
dup3 |
|---|---|---|---|
| 新fd选择 | 自动选择最小可用fd | 指定newfd值 |
指定newfd值 |
| 原子性 | 是 | 是(关闭+复制原子操作) | 是 |
| 标志控制 | 无 | 无 | 支持O_CLOEXEC |
| 如果newfd已打开 | 不适用 | 自动关闭后复制 | 自动关闭后复制 |
| 标准化 | POSIX.1-2001 | POSIX.1-2001 | Linux特有(2.6.27+) |
这样我们就可以对之前shell项目做一点修改,添加一个重定向的功能。实现如下:
cpp
#include<stdio.h>
#include<ctype.h>
#include <unistd.h>
#include<sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include<stdlib.h>
#include<sys/wait.h>
#include<string.h>
#define MAXSIZE 128
//这两个作用等同于main函数参数
//shell自己维护的第一张表:命令行参数表
char*myargv[MAXSIZE];//将打散的命令存储于此
int myargc=0;
//分隔符
const char*sep=" ";
//我们shell自己的工作路径
char cwd[MAXSIZE];
// 最近一个命令执行完毕,退出码
int lastcode = 0;
//"ls -a >xx.txt"->"ls -a "&&"xx.txt"&&"重定向方式"
//表明重定向信息
#define NoneRedir 0
#define InputRedir 1
#define OutputRedir 2
#define AppendRedir 3
int redir_type=NoneRedir;//保存重定向的方式
char*filename=NULL; //保存重定向的目标文件
//这里我们不做系统调用,只做模拟从环境变量中获取
const char* GetUserName()
{
char*name=getenv("USER");
if(name==NULL)
return "None";
return name;
}
const char* GetHostName()
{
char*hostname=getenv("HOSTNAME");
if(hostname==NULL)
return "None";
return hostname;
}
const char* GetPwd()
{
char*pwdname=getenv("PWD");
//char*pwdname=getcwd(cwd,sizeof(cwd));
if(pwdname==NULL)
return "None";
return pwdname;
}
void PrintCommandLine()
{
printf("[%s@%s %s]#",GetUserName(),GetHostName(),GetPwd());//用户名@主机名 当前路径
fflush(stdout);
}
int GetCommand(char*command_line,int size)
{
if(fgets(command_line,size,stdin)==NULL)//不用scanf是因为它会默认以空格为分隔符,无法全部截取
return 0;
//用户在输入的时候至少按一下回车
command_line[strlen(command_line)-1]='\0';
//如果用户输入的是空串,继续输入
return strlen(command_line);
// printf("%s\n",command_line);//测试用,现在不需要了
}
//去除左半部分空格
#define TrimSpace(start) do{\
while(isspace(*start)) start++;\
}while(0)
//"ls -a >xx.txt"->"ls -a "&&"xx.txt"&&"重定向方式"
//原理阐述
//ls -a -l >>file.txt -> ls -a -l \0\0 file.txt
void ParseRedir(char*command_line)
{
int redir_type=NoneRedir;//保存重定向的方式
char*filename=NULL; //保存重定向的目标文件
char* start=command_line;
char* end=command_line+strlen(command_line);
while(start<=end)
{
if(*start=='>')
{
if(*(start+1)=='>')
{
//追加重定向
*start='\0';
start++;
*start='\0';
start++;
TrimSpace(start);
redir_type=AppendRedir;
filename=start;
break;
}
//输出重定向
*start='\0';
start++;
TrimSpace(start);
redir_type=OutputRedir;
filename=start;
break;
}
else if (*start=='<')
{
//输入重定向
*start='\0';
start++;
TrimSpace(start);
redir_type=InputRedir;
filename=start;
break;
}
else
{
//没有重定向
start++;
}
}
}
int ExecuteCommand()
{
//不能让bash自己执行命令,必须创建子进程进行替换
pid_t id=fork();
if(id<0) return -1;
else if(id==0)
{
//printf("我是子进程,我是exec启动前: %dp\n", getpid());
// 子进程: 如何执行, gargv, gargc
// ls -a -l
int fd = -1;
if(redir_type == NoneRedir)
{
// Do Nothing
}
else if(redir_type == OutputRedir)
{
// 子进程要进行输出重定向
fd = open(filename, O_WRONLY | O_CREAT | O_TRUNC, 0666);
dup2(fd, 1);
}
else if(redir_type == AppendRedir)
{
fd = open(filename, O_WRONLY | O_CREAT | O_APPEND, 0666);
dup2(fd, 1);
}
else if(redir_type == InputRedir)
{
fd = open(filename, O_RDONLY);
dup2(fd, 0);
}
else{
//bug??
}
//子进程
execvp(myargv[0],myargv);
exit(0);
}
else
{
int status=0;
//父进程
pid_t rid =waitpid(id,&status,0);
if(rid>0)
{
printf("等待成功!");
lastcode = WEXITSTATUS(status);
}
}
return 0;
}
int ParseCommand(char*command_line)
{
myargc = 0;
memset(myargv,0,sizeof(myargv));
//写法1
//while((myargv[myargc++]=strtok(command_line,sep)));
//写法2
myargv[0]=strtok(command_line,sep);
while((myargv[++myargc]=strtok(NULL,sep)));
// printf("myargc:%d\n", myargc);
// for(int i = 0; i < myargc; ++i)
// printf("myargv[%d]:%s\n", i, myargv[i]);
//
return myargc;
}
//1是内建命令或者已经执行完毕
//0不是内建命令
int CheckBuiltinExecute()
{
if(strcmp(myargv[0],"cd")==0)
{
//内建命令
if(myargc==2)
{
//新的路径为myargv[1]
chdir(myargv[1]);
char pwd[1024];
getcwd(pwd,sizeof(pwd));//获取当前路径
snprintf(cwd,sizeof(cwd),"PID:%s",pwd);
putenv(cwd);
}
return 1;
}
return 0;
}
int main()
{
char command_line[MAXSIZE]={0};
//shell本质是一个死循环
while(1)
{
//1、打印命令行
PrintCommandLine();
//2、获取用户输入
if(GetCommand(command_line,sizeof(command_line))==0)//要么输入失败要么字符串为空
continue;
printf("%s\n",command_line);
//3、解析字符串。就是比如"ls -a -l"就要转化为"ls""-a""-l"命令解析器,对用户输入的命令做处理
//重定向文件输入
//"ls -a >xx.txt"->"ls -a "&&"xx.txt"&&"重定向方式"
ParseRedir(command_line);
//测试专用
//printf("command:%s\n",command_line);
//printf("redir_type:%d\n",redir_type);
//printf("filename:%s\n",filename);
ParseCommand(command_line);
sleep(1);
//4、判断该命令由哪个进程执行
if(CheckBuiltinExecute())
continue;
//5、子进程执行该命令
ExecuteCommand();
}
return 0;
}测试结果为:

调用系统调用接口是有成本的。
缓冲区
什么是缓冲区?
缓冲区是内存空间的一部分。也就是说,在内存空间中预留了一定的存储空间,这些存储空间用来缓冲输入或输出的数据,这部分预留的空间就叫做缓冲区。缓冲区根据其对应的是输入设备还是输出设备,分为输入缓冲区和输出缓冲区
为什么引入缓冲区制度?
读写文件时,如果不会开辟对文件操作的缓冲区,直接通过系统调用对磁盘进行操作(读、写等),那么每次对文件进行一次读写操作时,都需要使用读写系统调用来处理此操作,即需要执行一次系统调用,执行一次系统调用将涉及到CPU状态的切换,即从用户空间切换到内核空间,实现进程上下文的切换,这将损耗一定的CPU时间,频繁的磁盘访问对程序的执行效率造成很大的影响 。
为了减少使用系统调用的次数,提高效率,我们就可以采用缓冲机制。比如我们从磁盘里取信息,可以在磁盘文件进行操作时,可以一次从文件中读出大量的数据到缓冲区中,以后对这部分的访问就不需要再使用系统调用了,等缓冲区的数据取完后再去磁盘中读取,这样就可以减少磁盘的读写次数,再加上计算机对缓冲区的操作大大快于对磁盘的操作,故应用缓冲区可大大提高计算机的运行速度 。
又比如,我们使用打印机打印文档,由于打印机的打印速度相对较慢,我们先把文档输出到打印机相应的缓冲区,打印机再自行逐步打印,这时我们的CPU可以处理别的事情。可以看出,缓冲区就是一块内存区,它用在输入输出设备和CPU之间,用来缓存数据。它使得低速的输入输出设备和高速的CPU能够协调工作,避免低速的输入输出设备占用CPU,解放出CPU,使其能够高效率工作。
缓冲类型
标准I/O提供了3种类型的缓冲区。
• 全缓冲区:这种缓冲方式要求填满整个缓冲区后才进行I/O系统调用操作。对于磁盘文件的操作通常使用全缓冲的方式访问。
• 行缓冲区:在行缓冲情况下,当在输入和输出中遇到换行符时,标准I/O库函数将会执行系统调用操作。当所操作的流涉及一个终端时(例如标准输入和标准输出),使用行缓冲方式。因为标准I/O库每行的缓冲区长度是固定的,所以只要填满了缓冲区,即使还没有遇到换行符,也会执行I/O系统调用操作,默认行缓冲区的大小为1024。
• 无缓冲区:无缓冲区是指标准I/O库不对字符进行缓存,直接调用系统调用。标准出错流stderr通常是不带缓冲区的,这使得出错信息能够尽快地显示出来。
除了上述列举的默认刷新方式,下列特殊情况也会引发缓冲区的刷新:
-
缓冲区满时;
-
执行flush语句;
以以下代码为例
cpp
#include<stdio.h>
#include<unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include<string.h>
int main()
{
close(1);
int fd =open("log.txt",O_WRONLY|O_CREAT|O_APPEND,0666);
if(fd<0)
{
perror("failed open file");
return 1;
}
printf("fd:%d\n",fd);
close(fd);
return 0;
}我们本来想使用重定向思维,让本应该打印在显示器上的内容写到"log.txt"文件中,但我们发现,程序运行结束后,文件中并没有被写入内容:
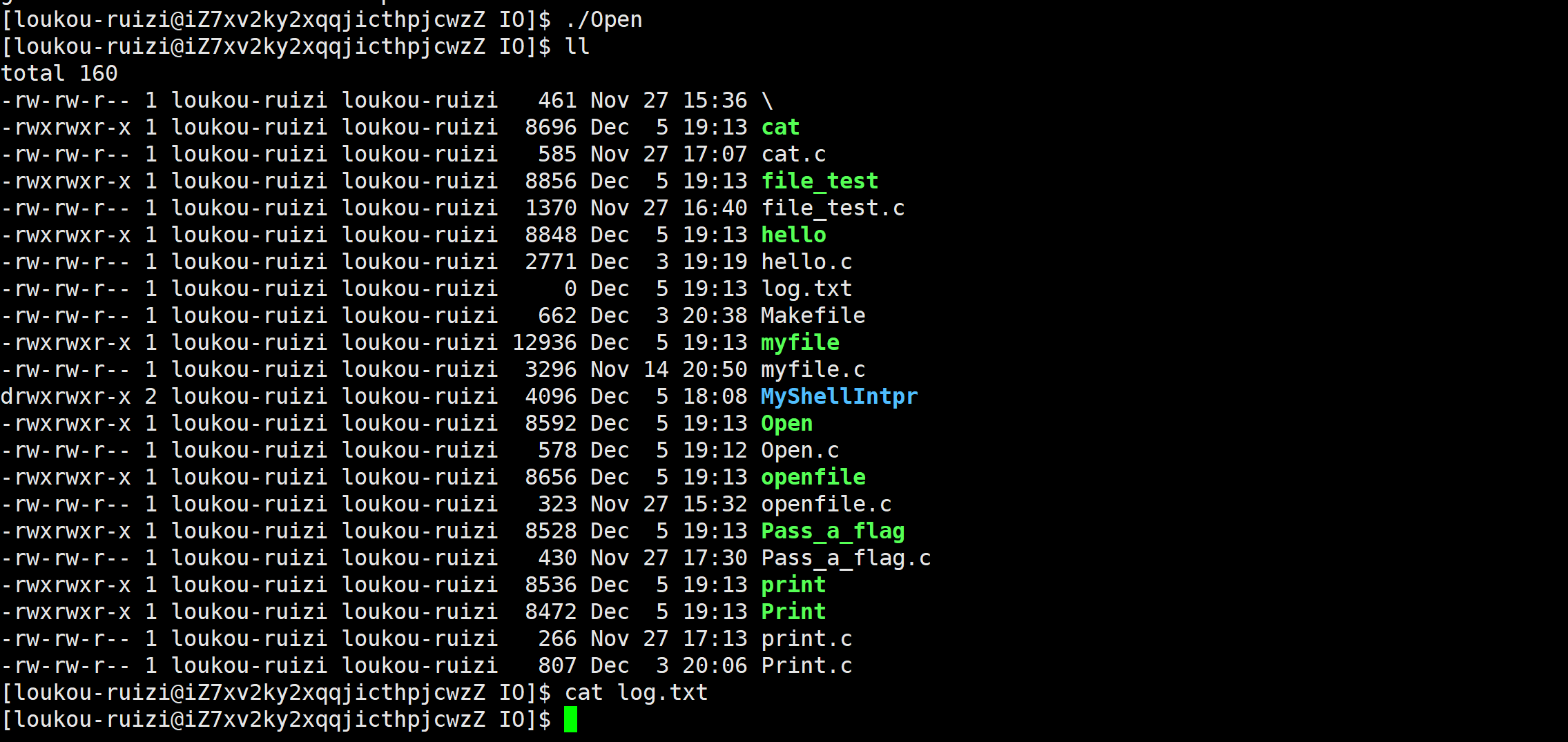
这是由于我们将1号描述符重定向到磁盘文件后,缓冲区的刷新方式成为了全缓冲。而我们写入的内容并没有填满整个缓冲区,导致并不会将缓冲区的内容刷新到磁盘文件中。怎么办呢?可以使用fflush强制刷新下缓冲区。
我们可以以以下两种方式修改:
cpp
//方式1
#include<stdio.h>
#include<unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include<string.h>
int main()
{
close(1);
int fd =open("log.txt",O_WRONLY|O_CREAT|O_APPEND,0666);
if(fd<0)
{
perror("failed open file");
return 1;
}
printf("fd:%d\n",fd);
fflush(stdout);
close(fd);
return 0;
}
//方式2
#include<stdio.h>
#include<unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include<string.h>
int main()
{
close(1);
int fd =open("log.txt",O_WRONLY|O_CREAT|O_APPEND,0666);
if(fd<0)
{
perror("failed open file");
return 1;
}
perror("fd:%d\n",fd);
close(fd);
return 0;
}stderr没有缓冲区,文件内容不用fflash就可以写入文件.
语言级缓冲区刷新与内核文件缓冲区
语言级刷新的本质就是将write(fd)的内容拷贝到内核文件缓冲区。将用户的数据交给OS(不一定写到磁盘!)
在进程结束的时候语言级缓冲区会自动刷新
如果目标文件是显示器是行缓冲
普通文件是全缓冲,即缓冲区写满了才会刷新
缓冲区一定不在OS里,在语言层之中。
我们以代码来测试
cpp
#include<stdio.h>
#include<unistd.h>
#include<string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main()
{
//语言级调用
printf("hello,printf\n");
fprintf(stdout,"hello,fprintf\n");
const char* s="hello ,fputs\n";
fputs(s,stdout);
//系统级别调用
const char* ss="hello ,write\n";
write(1,ss,strlen(ss));
return 0;
}结果为:

而对于内核文件缓冲区,只要把数据从用户缓冲区拷贝到内核文件缓冲区就相当于交给了硬件。客观上就是写给了文件对应的文件内核缓冲区,就是交给了OS自主刷新后再由OS存放到磁盘中。
FILE
因为IO相关函数与系统调用接口对应,并且库函数封装系统调用,所以本质上,访问文件都是通过fd访问的。
所以C库当中的FILE结构体内部,必定封装了fd
cpp
#include <stdio.h>
#include <string.h>
#include <unistd.h>
int main()
{
const char *msg0 = "hello printf\n";
const char *msg1 = "hello fwrite\n";
const char *msg2 = "hello write\n";
printf("%s", msg0);
fwrite(msg1, 1, strlen(msg1), stdout);
write(1, msg2, strlen(msg2));
fork();
return 0;
}结果为:

但是我们用输入重定向后市这个结果:
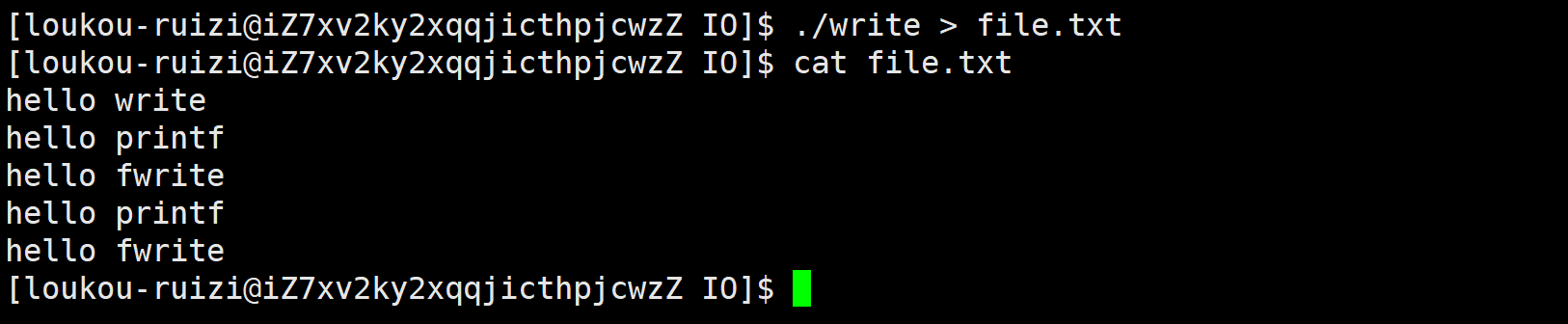
可以看到语言层(库函数)被执行了两次,系统层(系统接口调用)执行了一次。
显然我们可以发现与fork函数有关
• 一般C库函数写入文件时是全缓冲的,而写入显示器是行缓冲。
• printf和fwrite库函数会自带缓冲区(进度条例子就可以说明),当发生重定向到普通文件时,数据的缓冲方式由行缓冲变成了全缓冲。
• 而我们放在缓冲区中的数据,就不会被立即刷新,甚至fork之后
• 但是进程退出之后,会统一刷新,写入文件当中。
• 但是fork的时候,父子数据会发生写时拷贝,所以当你父进程准备刷新的时候,子进程也就有了同样的一份数据,随即产生两份数据。
• write没有变化,说明没有所谓的缓冲。
综上:printf和fwrite库函数会自带缓冲区,而write系统调用没有带缓冲区。另外,我们这里所说的缓冲区,都是用户级缓冲区。其实为了提升整机性能,OS也会提供相关内核级缓冲区,不过不在我们讨论范围之内。
那这个缓冲区谁提供呢?printf和fwrite是库函数,write是系统调用,库函数在系统调用的"上层",是对系统调用的"封装",但是write没有缓冲区,而printf和fwrite有,足以说明,该缓冲区是二次加上的,又因为是C,所以由C标准库提供。
我们可以查看一下FILE的源码中FILE的结构体。在在/usr/include/libio.h
cpp
struct _IO_FILE {
int _flags; /* High-order word is _IO_MAGIC; rest is flags. */
#define _IO_file_flags _flags
// 缓冲区相关
/* The following pointers correspond to the C++ streambuf protocol. */
/* Note: Tk uses the _IO_read_ptr and _IO_read_end fields directly. */
char* _IO_read_ptr; /* Current read pointer */
char* _IO_read_end; /* End of get area. */
char* _IO_read_base; /* Start of putback+get area. */
char* _IO_write_base; /* Start of put area. */
char* _IO_write_ptr; /* Current put pointer. */
char* _IO_write_end; /* End of put area. */
char* _IO_buf_base; /* Start of reserve area. */
char* _IO_buf_end; /* End of reserve area. */
/* The following fields are used to support backing up and undo. */
char *_IO_save_base; /* Pointer to start of non-current get area. */
char *_IO_backup_base; /* Pointer to first valid character of backup area */
char *_IO_save_end; /* Pointer to end of non-current get area. */
struct _IO_marker *_markers;
struct _IO_FILE *_chain;
int _fileno; // 封装的文件描述符
#if 0
int _blksize;
#else
int _flags2;
#endif
_IO_off_t _old_offset; /* This used to be _offset but it's too small. */
#define __HAVE_COLUMN /* temporary */
/* 1+column number of pbase(); 0 is unknown. */
unsigned short _cur_column;
signed char _vtable_offset;
char _shortbuf[1];
/* char* _save_gptr; char* _save_egptr; */
_IO_lock_t *_lock;
#ifdef _IO_USE_OLD_IO_FILE
}fseek函数技术文档
函数概述
函数原型:
cpp
#include <stdio.h>
int fseek(FILE *stream, long offset, int whence);功能描述 :
fseek函数用于设置文件位置指示器,实现对文件流的随机访问。它允许程序在文件中任意位置进行读写操作,突破了顺序访问的限制。
技术规格
参数说明
| 参数 | 类型 | 描述 |
|---|---|---|
stream |
FILE * |
指向文件对象的指针 |
offset |
long |
相对于whence参数的偏移量(字节) |
whence |
int |
基准位置,决定偏移量的计算起点 |
返回值
| 返回值 | 含义 |
|---|---|
0 |
成功设置文件位置 |
非0 |
设置失败,通常由于文件未打开或定位超出文件范围 |
基准位置常量
SEEK_SET
cpp
#define SEEK_SET 0功能 :从文件开头开始计算偏移量
数学表达式 :新位置 = offset
使用场景:绝对定位到文件的特定字节位置
SEEK_CUR
cpp
#define SEEK_CUR 1功能 :从当前位置开始计算偏移量
数学表达式 :新位置 = 当前位置 + offset
使用场景:相对当前位置的前后移动
SEEK_END
cpp
#define SEEK_END 2功能 :从文件末尾开始计算偏移量
数学表达式 :新位置 = 文件大小 + offset
使用场景:从文件末尾反向定位,通常使用负偏移量
底层机制
文件位置指示器
cpp
// FILE结构体中的位置指示器(概念性)
struct _FILE {
// ... 其他字段
long _offset; // 当前文件位置
unsigned char *_ptr; // 缓冲区当前位置
// ...
};系统调用映射
在大多数实现中,fseek最终映射到lseek系统调用:
cpp
// 底层系统调用
off_t lseek(int fd, off_t offset, int whence);应用场景与示例
1. 绝对定位
cpp
// 定位到文件第100字节处
FILE *fp = fopen("data.bin", "rb");
if (fseek(fp, 100, SEEK_SET) == 0) {
// 成功定位,可以读取或写入
fread(buffer, 1, 50, fp);
}2. 相对定位
cpp
#define RECORD_SIZE 64
// 访问第n条记录(基于0的索引)
int read_record(FILE *fp, int record_num, void *buffer) {
if (fseek(fp, record_num * RECORD_SIZE, SEEK_SET) != 0) {
return -1; // 定位失败
}
return fread(buffer, RECORD_SIZE, 1, fp);
}3. 文件末尾操作
cpp
#define RECORD_SIZE 64
// 访问第n条记录(基于0的索引)
int read_record(FILE *fp, int record_num, void *buffer) {
if (fseek(fp, record_num * RECORD_SIZE, SEEK_SET) != 0) {
return -1; // 定位失败
}
return fread(buffer, RECORD_SIZE, 1, fp);
}4. 数据库式记录访问
cpp
#define RECORD_SIZE 64
// 访问第n条记录(基于0的索引)
int read_record(FILE *fp, int record_num, void *buffer) {
if (fseek(fp, record_num * RECORD_SIZE, SEEK_SET) != 0) {
return -1; // 定位失败
}
return fread(buffer, RECORD_SIZE, 1, fp);
}C语言fopen函数权限选项表格
| 模式字符串 | 描述 | 文件必须存在 | 清空文件内容 | 读写权限 | 文件指针位置 | 备注 |
|---|---|---|---|---|---|---|
"r" |
只读模式 | ✅ 是 | ❌ 否 | 只读 | 文件开头 | 文件不存在则失败 |
"w" |
只写模式 | ❌ 否 | ✅ 是 | 只写 | 文件开头 | 创建新文件或清空现有文件 |
"a" |
追加模式 | ❌ 否 | ❌ 否 | 只写 | 文件末尾 | 创建新文件或在现有文件末尾追加 |
"r+" |
读写模式 | ✅ 是 | ❌ 否 | 读写 | 文件开头 | 文件必须存在,可读可写 |
"w+" |
读写模式 | ❌ 否 | ✅ 是 | 读写 | 文件开头 | 创建新文件或清空现有文件 |
"a+" |
读写追加模式 | ❌ 否 | ❌ 否 | 读写 | 文件末尾(写) 任意位置(读) | 创建新文件,写操作总是在末尾 |
本期内容到这里就结束了,喜欢请点个赞谢谢
封面图自取:
