Flink CDC(Change Data Capture)的实现方式主要有以下两种类型:
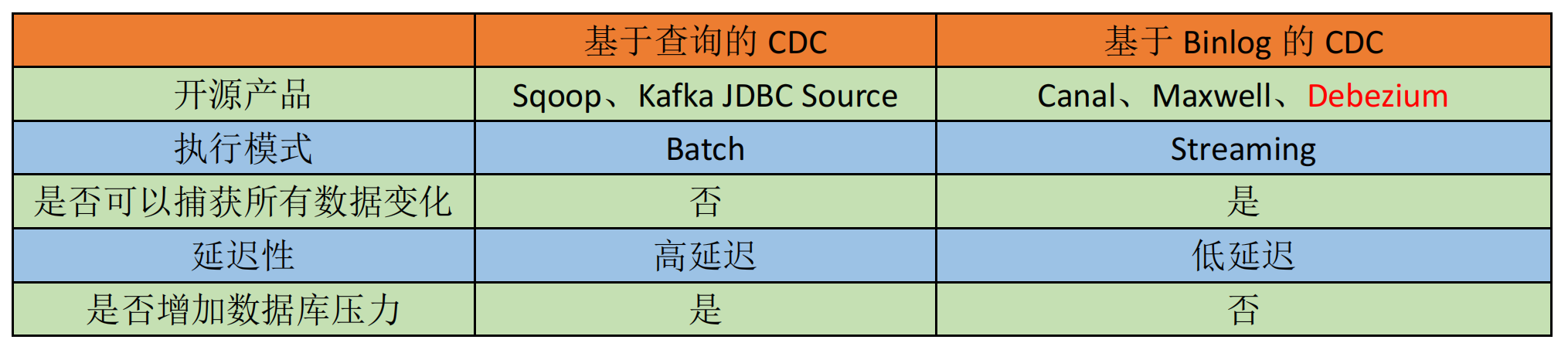
1. 基于查询的增量同步
通过定期查询源数据库的增量数据(如时间戳字段、自增ID)实现变更捕获。
- 适用场景:数据量较小、更新频率低的场景。
- 特点 :
- 实现简单,无需依赖数据库日志。
- 可能对源数据库产生查询压力。
- 无法捕获删除操作(需额外标记)。
2. 基于日志解析的实时同步
通过解析数据库的事务日志(如MySQL的binlog、PostgreSQL的WAL)捕获变更。
- 主流方案:如Debezium + Flink的组合。
- 特点 :
- 实时性强:秒级延迟捕获增删改操作。
- 低侵入性:不直接影响源数据库性能。
- 完整性高 :支持
INSERT/UPDATE/DELETE全量操作。 - 典型工具 :
- MySQL → Debezium MySQL Connector
- PostgreSQL → Debezium PG Connector
- MongoDB → Debezium MongoDB Connector
典型应用场景
- 实时数仓同步:将OLTP数据实时写入数据湖(如Iceberg)或数仓(如ClickHouse)。
- 微服务解耦:通过CDC将数据库变更推送至Kafka,供下游服务消费。
- 多源异构同步:联合Flink SQL实现多数据库到统一目标的ETL。
总结
- 日志解析模式是生产环境的首选方案,尤其在高吞吐、低延迟场景中。
- Flink CDC生态持续扩展,已支持MySQL、PostgreSQL、Oracle等主流数据库。