目录
[1. 什么是 I/O 多路复用?](#1. 什么是 I/O 多路复用?)
[2. Redis 的架构选择](#2. Redis 的架构选择)
[二、Redis 中多路复用的实现](#二、Redis 中多路复用的实现)
[1. 支持的底层机制](#1. 支持的底层机制)
[2. 核心工作流程](#2. 核心工作流程)
[1. 事件循环结构](#1. 事件循环结构)
[2. 事件注册过程](#2. 事件注册过程)
[3. 事件分发循环](#3. 事件分发循环)
[1. 为什么 Redis 能单线程处理高并发?](#1. 为什么 Redis 能单线程处理高并发?)
[2. epoll 的优势(Linux环境下)](#2. epoll 的优势(Linux环境下))
[五、多线程扩展(Redis 6.0+)](#五、多线程扩展(Redis 6.0+))
[1. 监控指标](#1. 监控指标)
[2. 性能瓶颈识别](#2. 性能瓶颈识别)
[3. 配置建议](#3. 配置建议)
前言
Redis 采用单线程 Reactor 模式 处理客户端请求,其高性能的核心就在于 I/O 多路复用 技术。
一、基础概念
1. 什么是 I/O 多路复用?
- 核心思想:使用一个进程/线程同时监听多个文件描述符(Socket),当某些描述符就绪(可读/可写)时,通知程序进行相应操作。
- 解决的问题:避免为每个连接创建线程/进程带来的资源消耗,实现高并发连接处理。
2. Redis 的架构选择
# 传统多线程模型 vs Redis单线程+多路复用
传统模型:1个连接 → 1个线程 → 高内存消耗、上下文切换开销大
Redis模型:N个连接 → 1个线程 + I/O多路复用 → 低内存、无锁、高效二、Redis 中多路复用的实现
1. 支持的底层机制
Redis 在不同操作系统下使用不同的多路复用实现:
- Linux :
epoll(最优选择) - macOS/BSD :
kqueue - Solaris :
evport - 其他 Unix :
select(性能较差,备选)
Redis 通过 ae(Async Event)抽象层统一封装这些接口。
2. 核心工作流程
-
初始化服务器,监听端口
-
将监听套接字注册到多路复用器
-
进入事件循环:
- 通过多路复用器等待事件(阻塞调用)
- 事件就绪后返回:
-
- 新连接到达 → 接受连接,注册读事件
- 数据可读 → 读取命令,解析,放入命令队列
- 可写事件 → 将响应数据发送给客户端
- c) 处理时间事件(定时任务)
- 循环执行步骤 3
三、源码级实现解析
1. 事件循环结构
typedef struct aeEventLoop {
int maxfd; // 当前最大文件描述符
int setsize; // 监听的文件描述符数量上限
long long timeEventNextId; // 下一个时间事件ID
aeFileEvent *events; // 文件事件数组
aeFiredEvent *fired; // 就绪事件数组
aeTimeEvent *timeEventHead; // 时间事件链表头
void *apidata; // 多路复用器的特定数据(epoll/kqueue等)
aeBeforeSleepProc *beforesleep;
aeBeforeSleepProc *aftersleep;
} aeEventLoop;2. 事件注册过程
// 以 epoll 为例的简化逻辑
int aeCreateFileEvent(aeEventLoop *eventLoop, int fd, int mask,
aeFileProc *proc, void *clientData) {
// 1. 在 events 数组中记录事件处理器
aeFileEvent *fe = &eventLoop->events[fd];
// 2. 调用底层 API 注册事件
if (aeApiAddEvent(eventLoop, fd, mask) == -1)
return -1;
// 3. 设置回调函数
fe->mask |= mask;
if (mask & AE_READABLE) fe->rfileProc = proc;
if (mask & AE_WRITABLE) fe->wfileProc = proc;
fe->clientData = clientData;
return 0;
}3. 事件分发循环
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
// 处理事件前执行的操作(如处理异步任务)
if (eventLoop->beforesleep != NULL)
eventLoop->beforesleep(eventLoop);
// 核心:多路复用等待事件
aeProcessEvents(eventLoop, AE_ALL_EVENTS | AE_CALL_AFTER_SLEEP);
}
}
int aeProcessEvents(aeEventLoop *eventLoop, int flags) {
// 1. 计算最近的时间事件,确定多路复用的超时时间
// 2. 调用多路复用API(epoll_wait/kevent/select等)
numevents = aeApiPoll(eventLoop, tvp);
// 3. 遍历就绪事件,调用相应的回调函数
for (j = 0; j < numevents; j++) {
aeFileEvent *fe = &eventLoop->events[eventLoop->fired[j].fd];
if (fe->mask & mask & AE_READABLE) {
fe->rfileProc(eventLoop, fd, fe->clientData, mask);
}
if (fe->mask & mask & AE_WRITABLE) {
fe->wfileProc(eventLoop, fd, fe->clientData, mask);
}
}
// 4. 处理时间事件
if (flags & AE_TIME_EVENTS)
processed += processTimeEvents(eventLoop);
return processed;
}四、性能优化细节
1. 为什么 Redis 能单线程处理高并发?
- 纯内存操作:数据操作在内存中完成,速度极快
- 非阻塞I/O:所有Socket设置为非阻塞模式
- 批量命令处理:支持管道(pipeline),减少网络往返
- 高效数据结构:精心优化的数据结构实现
2. epoll 的优势(Linux环境下)
# select/poll 的局限性
1. 每次调用都需要传递所有监听的fd(用户空间→内核空间复制)
2. 内核需要遍历所有fd检查就绪状态 O(n)
3. 支持的文件描述符数量有限(select默认1024)
# epoll 的优化
1. epoll_create: 创建epoll实例
2. epoll_ctl: 添加/修改/删除fd(仅增量更新)
3. epoll_wait: 获取就绪事件(仅返回就绪的fd)
4. 使用红黑树管理fd,哈希表存储就绪列表 O(1)复杂度五、多线程扩展(Redis 6.0+)
Redis 6.0 引入了多线程I/O,但注意:
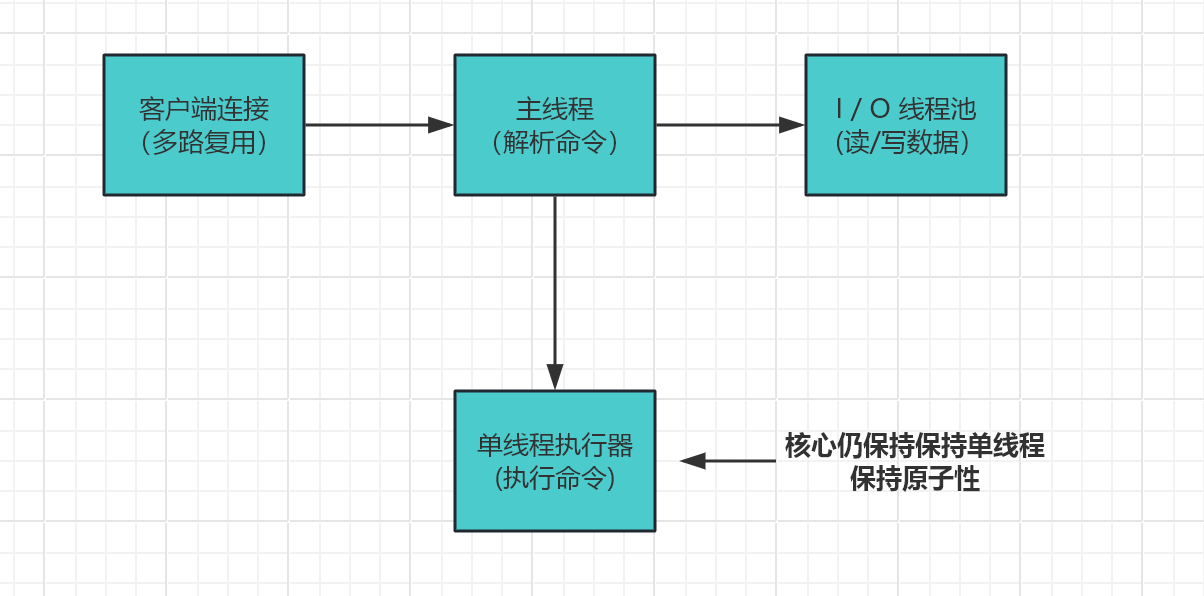
配置示例(redis.conf):
# 开启多线程I/O
io-threads 4 # 启用4个I/O线程(通常设为CPU核心数)
io-threads-do-reads yes # 启用读多线程(写默认开启)六、与其他模型的对比
|---------------|----------|------------|-----|----------------|
| 模型 | 连接管理 | 并发能力 | 复杂度 | 适用场景 |
| 阻塞I/O+多线程 | 每连接一线程 | 受限于线程数 | 高 | 传统数据库 |
| 多进程 | 每连接一进程 | 受限于进程数 | 高 | Apache prefork |
| 异步I/O | 完全异步 | 非常高 | 很高 | Nginx, Node.js |
| Redis模型 | 多路复用+单线程 | 高(10万+QPS) | 中 | 内存数据库、缓存 |
七、实际监控与调优
1. 监控指标
# 查看Redis事件循环状态
redis-cli info stats | grep -E "(total_connections_received|instantaneous_ops_per_sec|total_commands_processed)"
# 查看网络I/O
redis-cli info stats | grep -E "(total_net_input_bytes|total_net_output_bytes|rejected_connections)"2. 性能瓶颈识别
- CPU瓶颈:单核跑满,考虑分片或升级CPU
- 网络瓶颈:网络吞吐达到上限
- 内存瓶颈:OOM或频繁交换
- 阻塞操作:慢查询、大key、持久化阻塞
3. 配置建议
# 调整最大连接数(根据实际情况)
maxclients 10000
# 调整TCP backlog
tcp-backlog 511
# 调整客户端超时
timeout 0 # 永不断开,适合内网
# 合理设置内存淘汰策略
maxmemory-policy allkeys-lru八、总结
Redis 的 I/O 多路复用模型是其高性能的基石:
- 单线程事件循环避免了锁竞争和上下文切换
- 多路复用技术高效管理大量连接
- 纯内存操作保证极快的响应速度
- 渐进式演进在保持核心简单的同时引入多线程优化I/O
面试回答
Redis 之所以这么快,IO 多路复用模型是很关键的一点。我通俗地解释一下它的工作原理:
假设 Redis 是一个餐厅服务员,传统的阻塞 IO 就像是一个服务员每次只服务一桌客人,点菜、上菜都要等这一桌完事了才能服务下一桌,这样效率很低。
而 IO 多路复用呢,就像是这个服务员同时监听多个桌子的呼叫铃。服务员站在大厅里,哪一桌有需求(比如客户端发来了读写请求),他就过去处理一下,处理完马上回来继续监听。这样一个人就能同时照顾很多桌客人,效率大大提升。
在技术实现上 ,Redis 底层使用的是像 select、poll这样的系统调用。它们的作用就是帮 Redis 监听大量的网络连接,一旦某个连接有数据可读或可写,就通知 Redis 去处理,而不用为每个连接创建一个线程去阻塞等待。
这样做的好处很明显:
- 高性能:单线程就能处理大量并发连接,避免了多线程的上下文切换开销。
- 低延迟:因为事件是即时有响应就处理,不会长时间阻塞。
- 资源省:不需要为每个连接创建线程,内存和 CPU 消耗都更小。
如果小假的内容对你有帮助,请点赞,评论,收藏。创作不易,大家的支持就是我坚持下去的动力!
