本篇来体验一下 ComfyUI与阿里通义实验室最新开源的Z-Image的组合,看看效果如何。

1.ComfyUI简介
ComfyUI作为一款基于节点的可视化AI图像生成工具,以其高度灵活和可定制化的特性受到进阶用户喜爱。与传统WebUI不同,它允许用户通过"连线搭积木"的方式精确控制图像生成的每个环节,特别适合需要高阶控制的创作者
而阿里通义实验室在2025年11月底推出的Z-Image,则是一款仅60亿参数的高效图像生成模型。它以 "小体积、大能量" 著称,在图像质量、文本渲染、文化理解等多个维度能媲美甚至超越参数规模大一个数量级的国际主流模型
ComfyUI是一个基于节点的 GUI, 为文生图模型提供了一种更加直观、灵活的方式来操作和管理生成的过程。所以可以将Z-Image 交给 ComfyUI 来进行管理,Z-Image或者其它模型就是它的引擎。
ComfyUI 开源地址:https://github.com/comfyanonymous/ComfyUI
本节将会在本地部署安装这个套件。
2.本地部署环境
| 环境 | 版本 |
|---|---|
| ubuntu-24.04.3 Server | release 10.0 |
| Cuda | 12.8 |
| 显卡 RTX 2080 Ti 22G | 驱动 NVIDIA-Linux-x86_64-580.105.08 |
| conda | 25.9.1 |
| 内存 | 32G |
要先安装好显卡驱动和 Cuda.
shell
nvidia-smi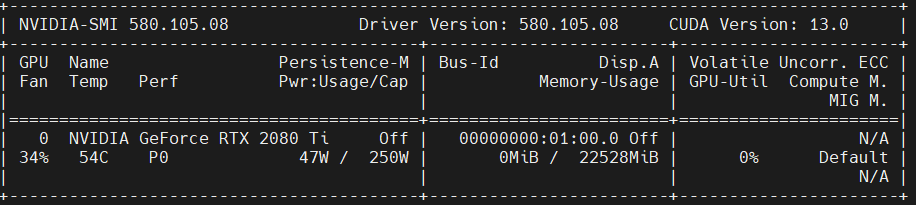
shell
nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2025 NVIDIA Corporation
Built on Fri_Feb_21_20:23:50_PST_2025
Cuda compilation tools, release 12.8, V12.8.93
Build cuda_12.8.r12.8/compiler.35583870_02.1 准备conda环境
shell
# 创建虚拟环境
conda create -n comfyui python=3.12
# 激活环境
conda activate comfyui
# 接下来会使用pip安装依赖,所以添加国内加速
(comfyui) pip config set global.index-url https://mirrors.huaweicloud.com/repository/pypi/simple/2.2 配置git代理
因为要从github clone 源代码,我配置了github加速:192.168.6.120是加速服务器
shell
# 安装git
sudo apt install git
# 设置全局代理
git config --global http.proxy http://192.168.6.120:7897
git config --global https.proxy http://192.168.6.120:7897
# 取消代理
git config --global --unset http.proxy
git config --global --unset https.proxy2.3 源码安装 ComfyUI
shell
# 克隆代码到本地
git clone https://github.com/comfyanonymous/ComfyUI.git
cd ComfyUI
# 安装 pytorch. 我本地的cuda 是 12.8 版本,所以安装对应的 torch版本
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu128
# 安装依赖
pip install -r requirements.txt官方对各种GPU要下载的 Pytorch有说明:

2.4 启动服务
指定端口号,启动服务,这里指定了8810端口
shell
python main.py --listen --port 8810访问: http://192.168.6.133:8810
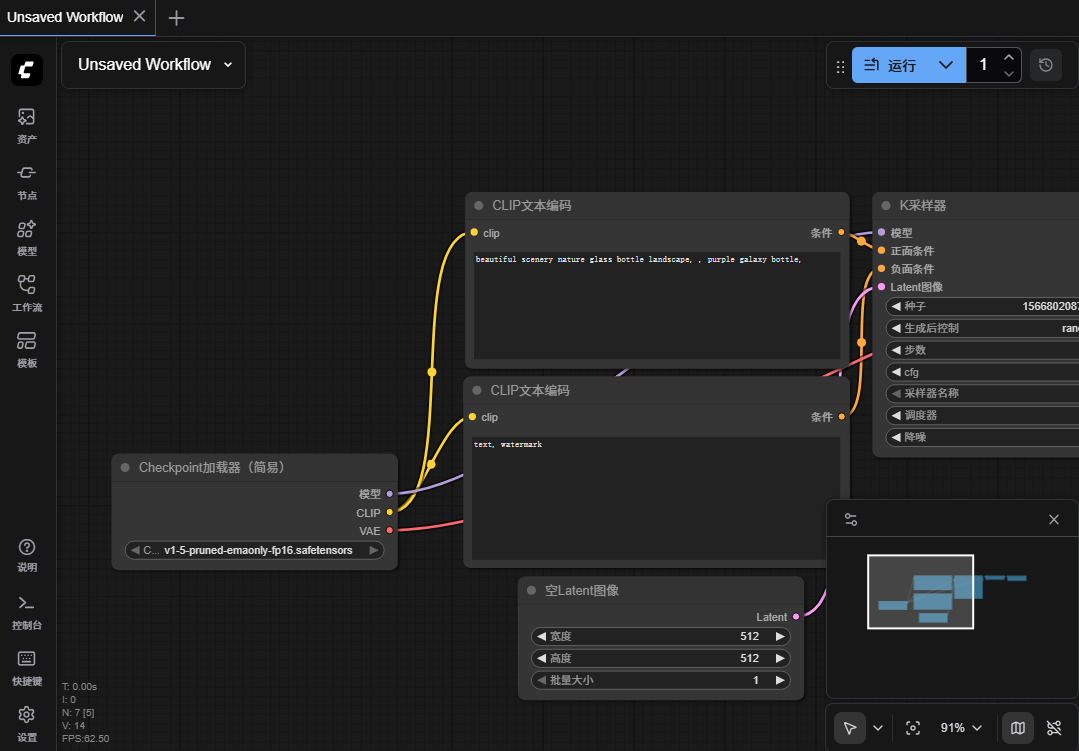
现在能看到界面,但是此时是不能正常工作的,因为默认下载的源代码中,是不包含模型文件的。
3.ComfyUI模型目录说明
plain
总之,base model + VAE 是 "基础画画能力",其余的是"插件 + 辅助模块",用于增强/定制/控制/美化/扩展生成的功能。
关于权重文件后缀:.ckpt / .safetensors / .pth / .pt / .bin
在 Stable Diffusion 及类似框架里,你会看到模型文件有不同后缀 --- 这些其实不表示模型"类别"不同,而是表示"保存格式/序列化格式"不同。常见的包括:
.ckpt"Checkpoint" --- 经典通用格式(多由 PyTorch 保存)。它可能不仅包含模型权重(weights / state_dict),还可能包含 optimizer 状态、训练轮数、超参数、元数据等。 它是用 Python 的pickle(或等价机制)完成序列化 ,可以包含任意 Python 对象。这个灵活性使它适合 "训练中断/继续训练/微调" 的场景。 但它最大的风险在于安全性 --- pickle 能执行任意代码,如果模型来源不可靠,可能存在恶意代码。.safetensors为了解决.ckpt的安全/效率问题而诞生 --- 由 Hugging Face 等支持 . 仅保存模型权重(tensor arrays),不包含 optimizer 状态、训练元数据,也不包含任意代码对象。存储结构更"干净"。 更安全 ------ 加载时不会执行任意代码,因此更适合从网络下载、共享模型。.pth /.pt/.bin这些通常是训练过程中的模型保存格式,也是基于 PyTorch 的序列化方式,类似.ckpt。是否安全 / 是否包含 metadata,依保存方式而定。
4.下载模型
官方有一个 z-image的示例:https://comfyanonymous.github.io/ComfyUI_examples/z_image/ 按照它的介绍,下载三个模型文件:

这些模型需要手动下载,通常从 haggingface下载,如果网络不可达,可以使用国内镜像 https://hf-mirros.com。
在 HuggingFace 上根据自己电脑的配置来选择不同的 Stable Diffusion 模型:https://huggingface.co/models?search=stable-diffusion
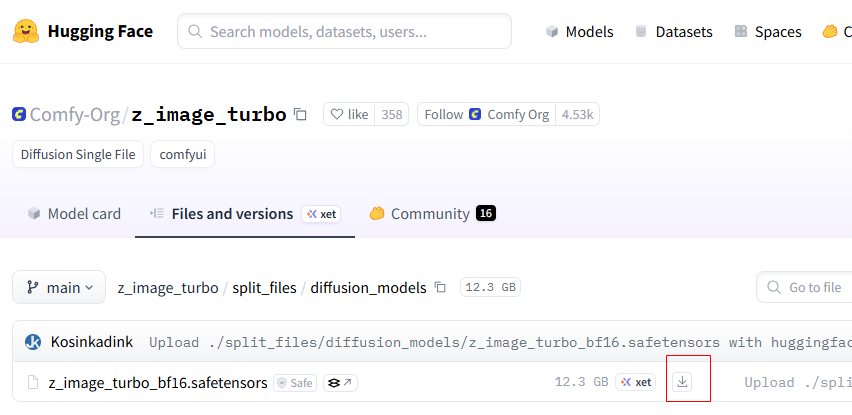
也可以手动下载:
shell
cd :~/ComfyUI
# Text Encoder ,下载到 models/text_encoders 目录中,这里使用 qwen_3_4b , 也可以使用其它模型
# 它负责将文本转换为向量
# 原地址 https://huggingface.co/Comfy-Org/z_image_turbo/resolve/main/split_files/text_encoders/qwen_3_4b.safetensors
wget -O models/text_encoders/qwen_3_4b.safetensors \
"https://hf-mirror.com/Comfy-Org/z_image_turbo/resolve/main/split_files/text_encoders/qwen_3_4b.safetensors"
# Diffusion Model 主要靠这个模型来干活,下载到了 models/diffusion_models 目录中
wget -O models/diffusion_models/z_image_turbo_bf16.safetensors \
"https://hf-mirror.com/Comfy-Org/z_image_turbo/resolve/main/split_files/diffusion_models/z_image_turbo_bf16.safetensors"
# VAE
wget -O models/vae/ae.safetensors \
"https://hf-mirror.com/Comfy-Org/z_image_turbo/resolve/main/split_files/vae/ae.safetensors"5.体验
https://comfyanonymous.github.io/ComfyUI_examples/z_image/ 上有一个图片,保存这个图片,然后将它拖拽到 ComfyUI中,可以得到它的工作流:
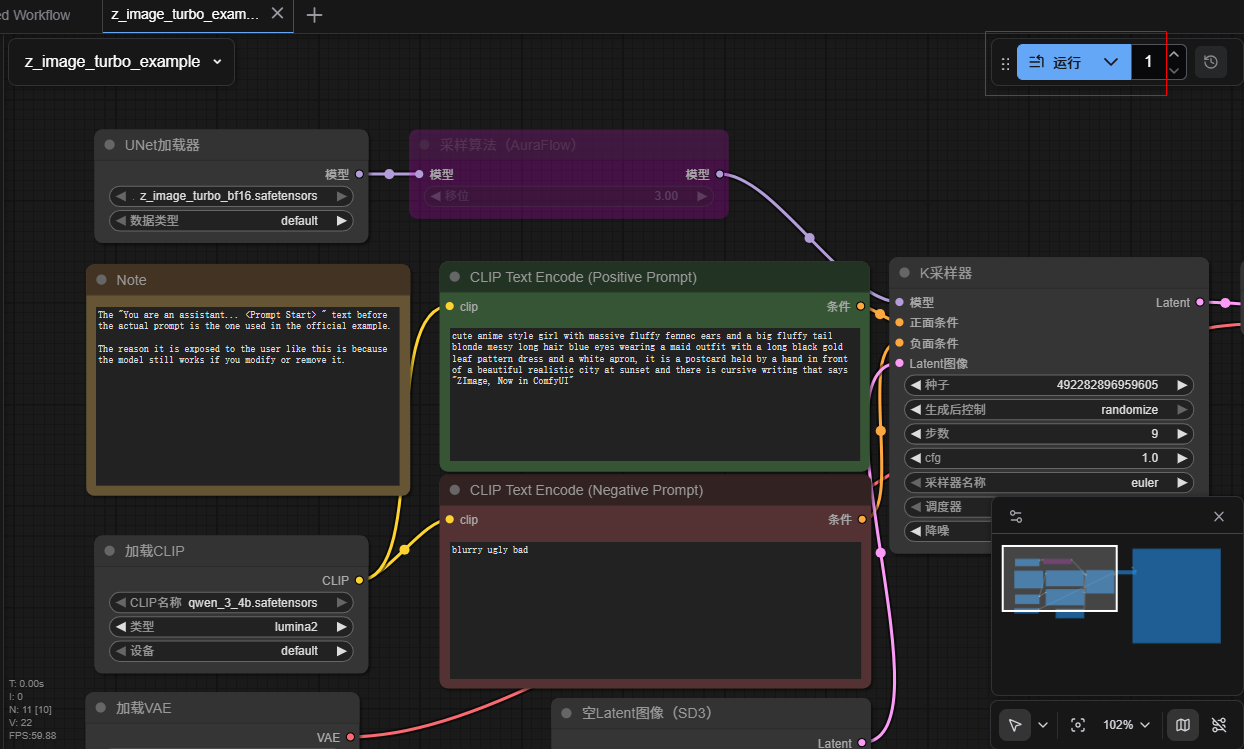
点击运行可以得到一样的图片