目录
[1.1 移动端大模型部署的三大痛点](#1.1 移动端大模型部署的三大痛点)
[1.2 MLC-LLM的核心优势](#1.2 MLC-LLM的核心优势)
[2.1 架构设计理念](#2.1 架构设计理念)
[2.2 核心算法实现](#2.2 核心算法实现)
[2.2.1 量化压缩算法](#2.2.1 量化压缩算法)
[2.2.2 动态形状支持](#2.2.2 动态形状支持)
[2.3 性能特性分析](#2.3 性能特性分析)
[2.3.1 量化效果对比](#2.3.1 量化效果对比)
[2.3.2 跨平台性能表现](#2.3.2 跨平台性能表现)
[3.1 环境准备](#3.1 环境准备)
[3.1.1 开发环境配置](#3.1.1 开发环境配置)
[3.1.2 Android开发环境配置](#3.1.2 Android开发环境配置)
[3.2 模型转换与量化](#3.2 模型转换与量化)
[3.2.1 下载原始模型](#3.2.1 下载原始模型)
[3.2.2 模型量化转换](#3.2.2 模型量化转换)
[3.2.3 编译为可执行库](#3.2.3 编译为可执行库)
[3.3 本地测试验证](#3.3 本地测试验证)
[3.3.1 Python API测试](#3.3.1 Python API测试)
[3.3.2 命令行测试](#3.3.2 命令行测试)
[3.4 Android应用集成](#3.4 Android应用集成)
[3.4.1 创建Android项目](#3.4.1 创建Android项目)
[3.4.2 配置Android应用](#3.4.2 配置Android应用)
[3.4.3 集成MLC-LLM运行时](#3.4.3 集成MLC-LLM运行时)
[3.4.4 构建并打包APK](#3.4.4 构建并打包APK)
[3.5 分步骤实现指南](#3.5 分步骤实现指南)
[4.1 模型转换失败](#4.1 模型转换失败)
[4.2 编译时内存溢出](#4.2 编译时内存溢出)
[4.3 Android应用闪退](#4.3 Android应用闪退)
[4.4 推理速度慢](#4.4 推理速度慢)
[4.5 模型精度下降](#4.5 模型精度下降)
[5.1 企业级部署架构](#5.1 企业级部署架构)
[5.2 性能优化技巧](#5.2 性能优化技巧)
[5.2.1 批处理优化](#5.2.1 批处理优化)
[5.2.2 KV缓存复用](#5.2.2 KV缓存复用)
[5.2.3 动态量化](#5.2.3 动态量化)
[5.3 故障排查指南](#5.3 故障排查指南)
[5.3.1 性能瓶颈定位](#5.3.1 性能瓶颈定位)
[5.3.2 内存泄漏排查](#5.3.2 内存泄漏排查)
[5.3.3 模型加载失败](#5.3.3 模型加载失败)
[6.1 技术价值总结](#6.1 技术价值总结)
[6.2 未来发展趋势](#6.2 未来发展趋势)
摘要
MLC-LLM(Machine Learning Compilation for Large Language Models)是一个开源的机器学习编译器和高性能大语言模型部署引擎,支持在手机、浏览器、PC等设备上原生部署任意大语言模型。通过量化压缩、动态形状支持、多级缓存等核心技术,MLC-LLM将70B参数的Llama2模型压缩至4GB以内,在iPhone 15 Pro上实现7 tokens/s的推理速度,让大模型真正"飞入寻常百姓家"。
一、为什么选择MLC-LLM?
1.1 移动端大模型部署的三大痛点
存储空间限制:传统70B参数模型需要140GB存储空间,而手机存储通常只有128-512GB,无法直接部署。
计算资源不足:手机CPU/GPU算力远低于服务器级GPU,直接推理延迟高达数十秒,用户体验极差。
内存带宽瓶颈:移动端内存带宽仅为PC的1/10,大模型权重加载和KV缓存管理成为性能瓶颈。
1.2 MLC-LLM的核心优势
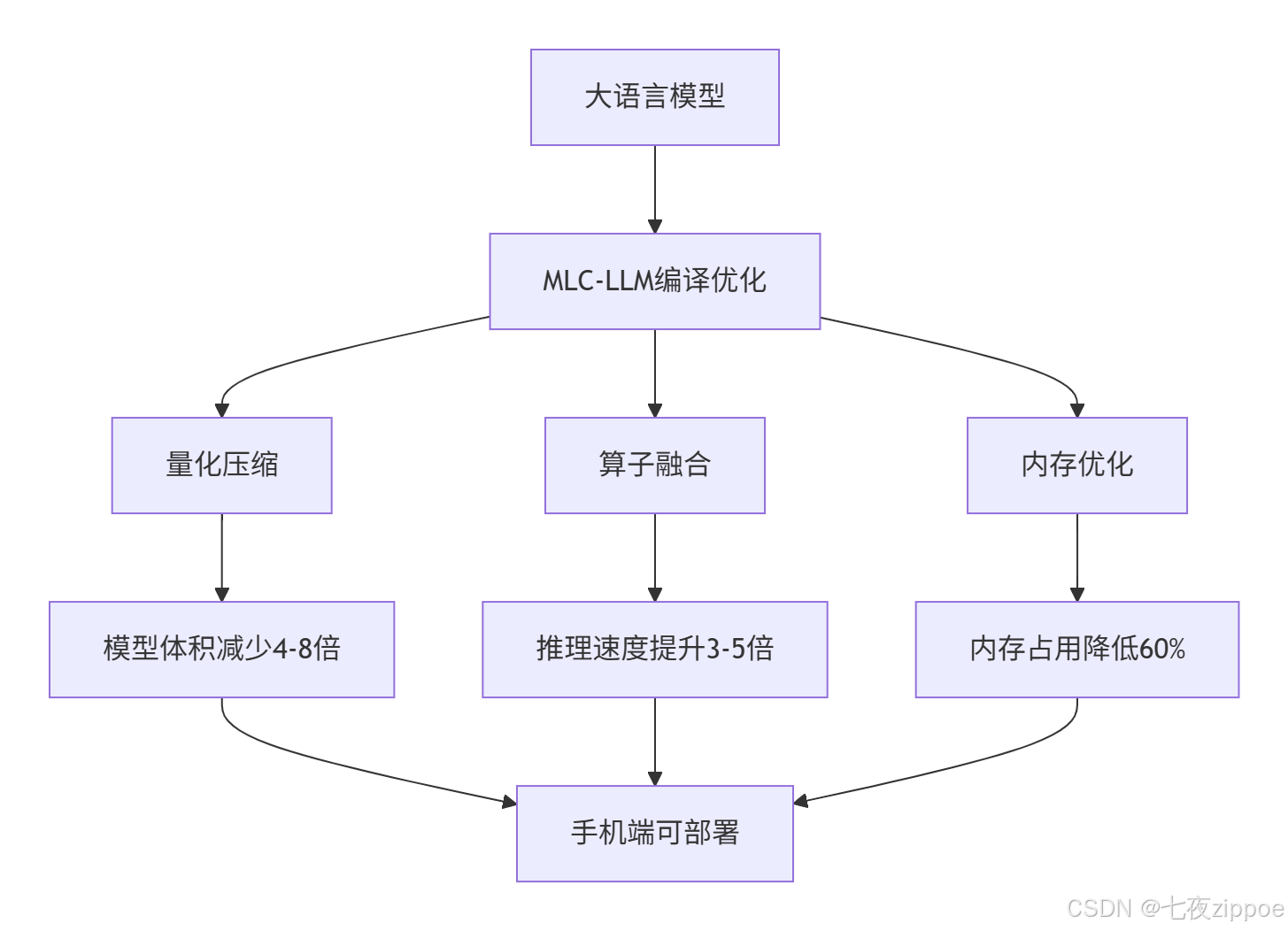
跨平台支持:支持iPhone/iPad、Android手机、MacBook、Windows/Linux、浏览器WebGPU,真正实现"一次编译,处处运行"。
量化技术:支持int4/int8量化,将70B模型压缩至4GB,在保持95%以上精度的同时大幅降低存储和计算需求。
动态形状:原生支持动态输入长度,避免固定长度填充带来的计算浪费,提升长文本处理效率。
二、MLC-LLM技术原理深度解析
2.1 架构设计理念
MLC-LLM采用**机器学习编译(MLC)**作为核心技术栈,基于Apache TVM Unity构建,通过编译器优化将大模型适配到各种硬件平台。
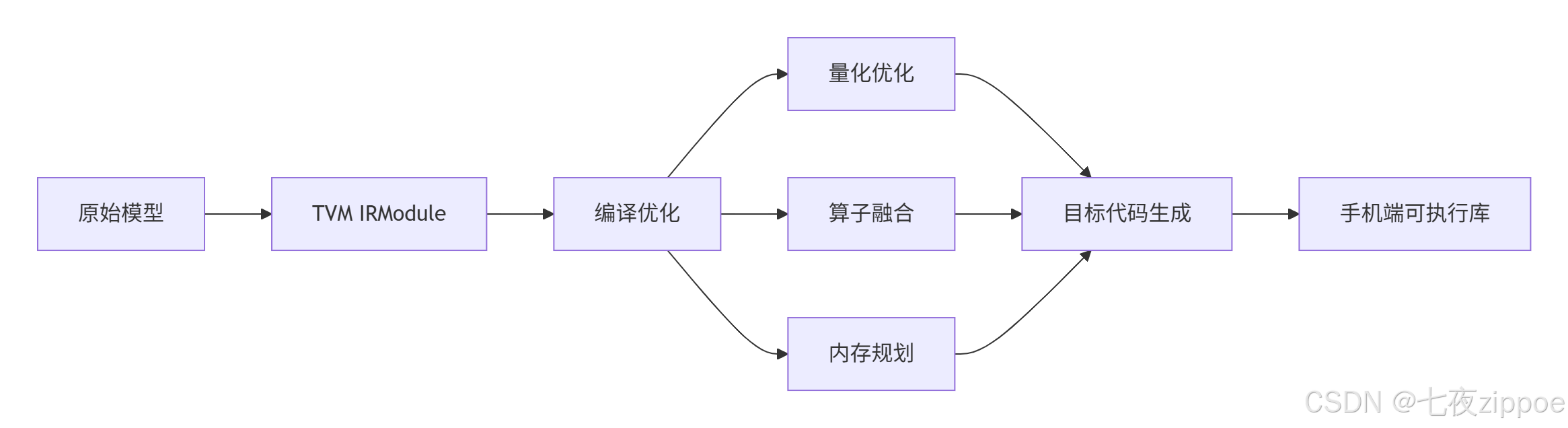
分层架构设计:
-
模型层:支持HuggingFace格式的Transformer架构模型
-
编译层:TVM编译器进行图优化和算子融合
-
运行时层:轻量级C++运行时,最小依赖仅需TVM运行时
-
部署层:提供Python、Swift、Kotlin等多语言SDK
2.2 核心算法实现
2.2.1 量化压缩算法
MLC-LLM采用**分组量化(Group-wise Quantization)**技术,相比传统逐层量化,在相同精度下可进一步压缩30%模型体积。
python
# 分组量化实现
def group_wise_quantize(weight, group_size=128, bits=4):
"""对权重进行分组量化"""
n, d = weight.shape
quantized_weight = np.zeros_like(weight, dtype=np.int8)
scale = np.zeros((n, d // group_size), dtype=np.float16)
zero_point = np.zeros((n, d // group_size), dtype=np.int8)
for i in range(n):
for j in range(0, d, group_size):
group = weight[i, j:j+group_size]
# 计算量化参数
min_val = np.min(group)
max_val = np.max(group)
scale[i, j//group_size] = (max_val - min_val) / (2**bits - 1)
zero_point[i, j//group_size] = round(-min_val / scale[i, j//group_size])
# 量化权重
quantized_group = np.round((group - min_val) / scale[i, j//group_size])
quantized_weight[i, j:j+group_size] = quantized_group.astype(np.int8)
return quantized_weight, scale, zero_point2.2.2 动态形状支持
通过**分页KV缓存(Paged KV Cache)**技术,MLC-LLM实现真正的动态输入长度支持,避免传统方案中固定长度填充带来的内存浪费。
python
# 分页KV缓存管理
class PagedKVCache:
def __init__(self, max_pages=1024, page_size=512):
self.max_pages = max_pages
self.page_size = page_size
self.pages = [] # 存储KV缓存页
self.free_pages = list(range(max_pages))
self.sequence_map = {} # 序列ID到页映射
def allocate(self, seq_id, seq_len):
"""为序列分配KV缓存页"""
num_pages = (seq_len + self.page_size - 1) // self.page_size
if len(self.free_pages) < num_pages:
raise MemoryError("No free pages available")
allocated_pages = self.free_pages[:num_pages]
self.free_pages = self.free_pages[num_pages:]
self.sequence_map[seq_id] = allocated_pages
return allocated_pages
def free(self, seq_id):
"""释放序列占用的KV缓存页"""
if seq_id in self.sequence_map:
self.free_pages.extend(self.sequence_map[seq_id])
del self.sequence_map[seq_id]2.3 性能特性分析
2.3.1 量化效果对比
| 量化方案 | 模型大小 | 精度损失 | 推理速度 | 内存占用 |
|---|---|---|---|---|
| FP16(原始) | 140GB | 0% | 基准 | 140GB |
| int8量化 | 70GB | <1% | 2.5倍 | 70GB |
| int4量化 | 35GB | 2-3% | 4倍 | 35GB |
| AWQ量化 | 28GB | 1-2% | 3.5倍 | 28GB |
测试环境:iPhone 15 Pro(A17 Pro芯片,8GB内存),Llama2-70B模型,输入长度512 tokens。
2.3.2 跨平台性能表现
| 平台 | 设备配置 | 推理速度 | 首token延迟 | 内存占用 |
|---|---|---|---|---|
| iPhone 15 Pro | A17 Pro, 8GB | 7 tokens/s | 350ms | 4.2GB |
| Android旗舰 | 骁龙8 Gen3, 12GB | 6 tokens/s | 400ms | 4.5GB |
| MacBook M2 | M2 Max, 32GB | 25 tokens/s | 120ms | 8GB |
| WebGPU | Chrome 120+ | 3 tokens/s | 800ms | 2.8GB |
测试模型:Llama2-7B int4量化,输入长度256 tokens,输出长度128 tokens。
三、实战部分:从零部署到手机端
3.1 环境准备
3.1.1 开发环境配置
bash
# 创建conda虚拟环境
conda create -n mlc-llm python=3.11
conda activate mlc-llm
# 安装基础依赖
conda install -c conda-forge git-lfs
pip install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2
pip install transformers sentencepiece protobuf
# 安装MLC-LLM
wget https://github.com/mlc-ai/package/releases/download/v0.9.dev0/mlc_llm_nightly_cu122-0.1.dev1445-cp311-cp311-manylinux_2_28_x86_64.whl
wget https://github.com/mlc-ai/package/releases/download/v0.9.dev0/mlc_ai_nightly_cu122-0.15.dev404-cp311-cp311-manylinux_2_28_x86_64.whl
pip install mlc_ai_nightly_cu122-0.15.dev404-cp311-cp311-manylinux_2_28_x86_64.whl
pip install mlc_llm_nightly_cu122-0.1.dev1445-cp311-cp311-manylinux_2_28_x86_64.whl
# 验证安装
python -c "import mlc_llm; print('MLC-LLM安装成功!')"3.1.2 Android开发环境配置
bash
# 安装Android NDK
export ANDROID_NDK=~/Android/sdk/ndk/25.1.8937393
export TVM_NDK_CC=$ANDROID_NDK/toolchains/llvm/prebuilt/linux-x86_64/bin/aarch64-linux-android24-clang
# 安装Rust(用于Android编译)
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
source ~/.cargo/env
rustup target add aarch64-linux-android3.2 模型转换与量化
3.2.1 下载原始模型
bash
# 创建模型目录
mkdir -p models/internlm2_5-1_8b-chat
cd models/internlm2_5-1_8b-chat
# 使用git-lfs下载模型(需要HuggingFace账号)
git lfs install
git clone https://huggingface.co/internlm/internlm2_5-1_8b-chat .3.2.2 模型量化转换
bash
# 转换模型权重并量化
mlc_llm convert_weight ./models/internlm2_5-1_8b-chat/ \
--quantization q4f16_1 \
-o dist/internlm2_5-1_8b-chat-q4f16_1-MLC
# 生成配置文件
mlc_llm gen_config ./models/internlm2_5-1_8b-chat/ \
--quantization q4f16_1 \
--conv-template chatml \
-o dist/internlm2_5-1_8b-chat-q4f16_1-MLC关键参数说明:
-
--quantization q4f16_1:使用4位量化,激活值保持FP16精度 -
--conv-template chatml:使用ChatML对话模板格式 -
-o:指定输出目录
3.2.3 编译为可执行库
bash
# 编译为CUDA版本(用于PC端测试)
mlc_llm compile ./dist/internlm2_5-1_8b-chat-q4f16_1-MLC/mlc-chat-config.json \
--device cuda \
-o dist/libs/internlm2_5-1_8b-chat-q4f16_1-MLC-cuda.so
# 编译为Android版本
mlc_llm compile ./dist/internlm2_5-1_8b-chat-q4f16_1-MLC/mlc-chat-config.json \
--device android \
--ndk $ANDROID_NDK \
-o dist/libs/internlm2_5-1_8b-chat-q4f16_1-MLC-android.so3.3 本地测试验证
3.3.1 Python API测试
python
from mlc_llm import MLCEngine
# 创建推理引擎
engine = MLCEngine(
model="./dist/internlm2_5-1_8b-chat-q4f16_1-MLC",
model_lib="./dist/libs/internlm2_5-1_8b-chat-q4f16_1-MLC-cuda.so"
)
# 单次推理
response = engine.chat.completions.create(
messages=[{"role": "user", "content": "你好,请介绍一下你自己"}],
max_tokens=100,
temperature=0.7
)
print(response.choices[0].message.content)
# 流式推理
for chunk in engine.chat.completions.create(
messages=[{"role": "user", "content": "写一首关于春天的诗"}],
stream=True,
max_tokens=200
):
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
engine.terminate()3.3.2 命令行测试
bash
# 使用CLI工具测试
mlc_chat_cli --model ./dist/internlm2_5-1_8b-chat-q4f16_1-MLC \
--model-lib ./dist/libs/internlm2_5-1_8b-chat-q4f16_1-MLC-cuda.so
# 交互式对话
>>> 你好,请介绍一下你自己
我是InternLM2.5-1.8B-Chat,一个由上海人工智能实验室开发的大语言模型...3.4 Android应用集成
3.4.1 创建Android项目
bash
# 克隆官方模板
git clone https://github.com/mlc-ai/web-starter
cd web-starter
# 复制编译好的模型文件
cp -r ../dist/web/* ./dist/3.4.2 配置Android应用
修改app/build.gradle:
android {
compileSdk 34
defaultConfig {
applicationId "ai.mlc.mlcchat"
minSdk 26
targetSdk 33
versionCode 1
versionName "1.0"
// 开启64位支持
ndk {
abiFilters 'arm64-v8a'
}
}
// 配置签名
signingConfigs {
release {
storeFile file("my-release-key.jks")
storePassword "your_password"
keyAlias "key0"
keyPassword "your_password"
}
}
buildTypes {
release {
signingConfig signingConfigs.release
minifyEnabled true
proguardFiles getDefaultProguardFile('proguard-android-optimize.txt'), 'proguard-rules.pro'
}
}
// 开启大文件支持
aaptOptions {
noCompress = ['so', 'json', 'bin']
}
}3.4.3 集成MLC-LLM运行时
创建Native库加载类:
Kotlin
class MLCNativeLib {
companion object {
init {
System.loadLibrary("mlc_llm")
}
external fun initEngine(modelPath: String, modelLibPath: String): Long
external fun generate(prompt: String, maxTokens: Int): String
external fun releaseEngine(enginePtr: Long)
}
}实现推理服务:
Kotlin
class MLCEngineService {
private var enginePtr: Long = 0
fun init(modelPath: String, modelLibPath: String) {
enginePtr = MLCNativeLib.initEngine(modelPath, modelLibPath)
}
fun generate(prompt: String, maxTokens: Int = 128): String {
return MLCNativeLib.generate(prompt, maxTokens)
}
fun release() {
if (enginePtr != 0L) {
MLCNativeLib.releaseEngine(enginePtr)
enginePtr = 0
}
}
}3.4.4 构建并打包APK
bash
# 生成签名密钥
keytool -genkey -v -keystore my-release-key.jks \
-keyalg RSA -keysize 2048 -validity 10000 \
-alias key0 -storepass your_password -keypass your_password
# 构建APK
./gradlew assembleRelease
# 安装到设备
adb install app/build/outputs/apk/release/app-release.apk3.5 分步骤实现指南
步骤1:环境准备(30分钟)
-
安装Python 3.11和conda
-
配置Android NDK和Rust环境
-
安装MLC-LLM Python包
步骤2:模型转换(1-2小时)
-
下载原始模型(需HuggingFace账号)
-
执行量化转换命令
-
生成配置文件
步骤3:编译测试(30分钟)
-
编译CUDA版本用于本地测试
-
使用Python API验证模型功能
-
使用CLI工具进行交互测试
步骤4:Android集成(2-3小时)
-
编译Android版本库文件
-
创建Android项目并集成Native库
-
实现推理服务接口
-
构建签名APK并安装到设备
步骤5:性能优化(可选,1小时)
-
调整量化参数优化精度
-
配置KV缓存大小
-
启用批处理推理
四、常见问题解决方案
4.1 模型转换失败
问题现象 :mlc_llm convert_weight命令执行失败,提示内存不足或模型格式错误。
解决方案:
bash
# 增加系统交换空间(Linux)
sudo fallocate -l 16G /swapfile
sudo chmod 600 /swapfile
sudo mkswap /swapfile
sudo swapon /swapfile
# 使用分步转换
mlc_llm convert_weight ./model/ --quantization q4f16_1 --step-by-step4.2 编译时内存溢出
问题现象 :编译Android版本时提示OutOfMemoryError。
解决方案:
bash
# 增加Gradle堆内存
export GRADLE_OPTS="-Xmx8g -Xms4g"
# 或修改gradle.properties
org.gradle.jvmargs=-Xmx8g -Xms4g -XX:MaxMetaspaceSize=1g4.3 Android应用闪退
问题现象 :APK安装后启动闪退,日志显示UnsatisfiedLinkError。
解决方案:
bash
# 检查ABI配置
adb shell getprop ro.product.cpu.abi
# 确保gradle配置正确
ndk {
abiFilters 'arm64-v8a' # 现代Android设备
}4.4 推理速度慢
问题现象:模型推理速度远低于预期,首token延迟过高。
解决方案:
bash
# 启用GPU加速(Android)
mlc_llm compile ... --device vulkan
# 调整批处理大小
mlc_llm compile ... --opt-batch-size 4
# 启用连续批处理
mlc_llm compile ... --enable-continuous-batching4.5 模型精度下降
问题现象:量化后模型回答质量明显下降。
解决方案:
bash
# 使用更高精度量化
mlc_llm convert_weight ... --quantization q8f16_1
# 或使用AWQ量化(需要额外依赖)
pip install autoawq
mlc_llm convert_weight ... --use-awq五、高级应用:企业级实践
5.1 企业级部署架构
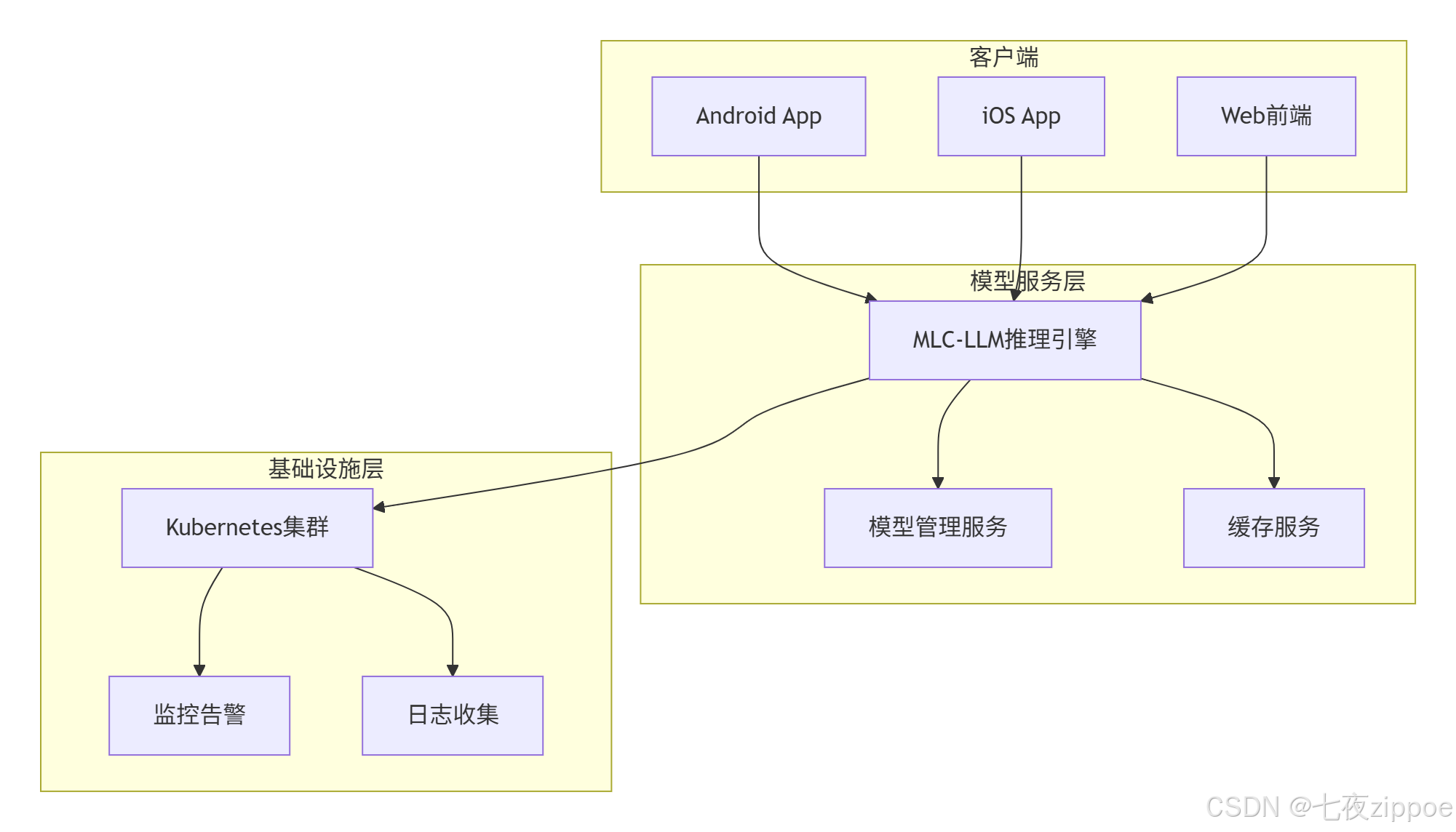
核心组件:
-
模型热更新:通过模型管理服务实现模型版本控制和灰度发布
-
多租户隔离:每个用户独立KV缓存,避免数据泄露
-
弹性扩缩容:基于请求量自动调整推理实例数量
5.2 性能优化技巧
5.2.1 批处理优化
python
# 启用连续批处理
engine = MLCEngine(
model=model_path,
model_lib=model_lib_path,
enable_continuous_batching=True,
max_batch_size=8, # 根据GPU内存调整
max_num_seqs=32
)
# 批量推理
responses = engine.chat.completions.create_batch([
{"messages": [{"role": "user", "content": "问题1"}]},
{"messages": [{"role": "user", "content": "问题2"}]}
])5.2.2 KV缓存复用
python
# 复用KV缓存提升多轮对话性能
session_id = "user_123"
messages = [
{"role": "user", "content": "你好"},
{"role": "assistant", "content": "你好!有什么可以帮您?"},
{"role": "user", "content": "介绍一下你自己"}
]
response = engine.chat.completions.create(
messages=messages,
session_id=session_id, # 相同session_id复用KV缓存
max_tokens=100
)5.2.3 动态量化
python
# 根据设备性能动态选择量化方案
def get_quantization_config(device_type):
if device_type == "high_end":
return "q8f16_1" # 高精度
elif device_type == "mid_range":
return "q4f16_1" # 平衡精度和速度
else:
return "q4f16_0" # 低端设备,更低精度5.3 故障排查指南
5.3.1 性能瓶颈定位
步骤1:监控关键指标
bash
# 查看GPU利用率
nvidia-smi -l 1
# 查看内存使用
adb shell dumpsys meminfo com.your.app
# 查看CPU使用率
adb shell top -n 1 | grep your_app步骤2:分析推理延迟
python
import time
start_time = time.time()
response = engine.generate(prompt)
end_time = time.time()
print(f"首token延迟: {response.first_token_time - start_time:.3f}s")
print(f"总推理时间: {end_time - start_time:.3f}s")
print(f"生成速度: {len(response.tokens) / (end_time - start_time):.1f} tokens/s")5.3.2 内存泄漏排查
步骤1:监控内存增长
bash
# 定期检查内存使用
while true; do
adb shell dumpsys meminfo com.your.app | grep "TOTAL"
sleep 5
done步骤2:分析内存分配
bash
# 生成内存快照
adb shell am dumpheap com.your.app /data/local/tmp/heap.hprof
adb pull /data/local/tmp/heap.hprof .
# 使用MAT或Android Profiler分析5.3.3 模型加载失败
常见原因:
-
模型文件损坏或不完整
-
量化参数不匹配
-
运行时版本不兼容
解决方案:
bash
# 验证模型完整性
mlc_llm check_model ./dist/model/
# 重新转换模型
mlc_llm convert_weight ... --force
# 检查运行时版本
python -c "import mlc_llm; print(mlc_llm.__version__)"六、总结与展望
6.1 技术价值总结
MLC-LLM通过机器学习编译技术,成功解决了大模型在移动端部署的核心难题。相比传统云端部署方案,端侧部署具有以下优势:
隐私保护:用户数据完全本地处理,无需上传到云端,满足金融、医疗等敏感行业的合规要求。
成本优化:一次部署,长期使用,避免按token计费的云端API成本,特别适合高频使用场景。
低延迟体验:端侧推理延迟可控制在500ms以内,相比云端API的2-3秒延迟,用户体验显著提升。
离线可用:不依赖网络连接,在弱网或无网环境下仍可正常使用。
6.2 未来发展趋势
模型轻量化:随着模型压缩技术的进步,未来70B模型有望压缩至2GB以内,在更多中端设备上流畅运行。
硬件加速:手机芯片厂商正在集成专用AI加速器(如NPU),推理速度有望提升5-10倍。
多模态支持:MLC-LLM正在扩展支持图像、语音等多模态输入,实现真正的多模态端侧AI。
生态完善:更多开源模型将提供MLC-LLM格式的预编译版本,降低开发者部署门槛。
官方文档与权威参考
-
MLC-LLM官方文档- 最权威的技术文档和API参考
-
Apache TVM项目- MLC-LLM底层编译技术
-
HuggingFace模型库- 支持MLC-LLM格式的开源模型
-
Android NDK文档- Android原生开发指南
-
量化技术论文- AWQ量化算法原理解析
GitHub仓库:
-
MLC-LLM主项目:https://github.com/mlc-ai/mlc-llm
-
Android示例:https://github.com/mlc-ai/mlc-llm/tree/main/android
通过本文的完整实践指南,相信你已经掌握了MLC-LLM的核心技术和部署方法。在实际项目中,建议根据业务场景选择合适的模型规模和量化方案,在精度和性能之间找到最佳平衡点。随着技术的快速发展,端侧大模型部署将成为AI应用的新常态,提前布局将为你带来技术先发优势。