"未来杯"2025第五届高校大数据挑战赛赛题【AB题】详细分析



通用符号说明与假设
-
I(x,y): 原始彩色图像(H×W×3),索引为像素 (x,y)
-
M(x,y) ∈ {0,1}: 真值掩码(ground-truth mask),1 表示伪装目标像素
-
B = (x1,y1,x2,y2): 目标边界框(bounding box)
-
P(x,y) ∈ 0,1: 模型预测的分割概率图
-
Ŵ:模型参数集合
-
L(·):损失函数
-
IoU (Jaccard) = |M ∩ Ŝ| / |M ∪Ŝ|
-
MAE(像素级平均绝对误差) = (1/N) Σ |M_i - P_i|
-
mIoU:多个图像的平均 IoU
-
mMAE:多个图像的平均 MAE
-
TP/FP/FN:基于分割阈值后的真阳性、假阳性、假阴性像素数
-
S: 图像尺度(例如 256, 512, 1024, 2048)
-
τ:分割阈值(典型为 0.5)
统一假设:
-
数据集提供原图与对应像素掩码(CAMO),并且掩码为二值图;
-
三个数据集均为 RGB 图像;测试集(Camouflaged‑people, NC4K)仅用于泛化评估(不参与训练);
-
任务既可视为像素级分割(首选)也可导出 bounding box 以满足"定位"要求;
-
训练/评估使用相同阈值 τ=0.5(可调)来获得二值预测。
问题一:基础伪装物体检测模型(分割或检测)
- 目标:使用 CAMO 数据集,设计不少于 3 种图像处理特征或直接训练一个检测模型,实现伪装物体的识别与定位;评价指标包含IoU 与 MAE。并展示"问题一:可视化展示图像"中 10 张图的可视化结果。
- 问题背景
伪装物体检测(Camouflaged Object Detection, COD)是视觉任务中挑战性很高的一类:目标在颜色、纹理、边缘与背景高度相似,导致典型的物体检测或语义分割器性能下降。基础方法可分为两类路径:基于显式图像处理特征+传统分类器(例如边缘、颜色对比、纹理滤波器、局部对比度、超像素显著性测算等),或直接基于深度学习(U-Net / DeepLab / Mask R-CNN / SegFormer 等)端到端训练。对于竞赛与研究来说,一般以深度学习分割模型作为基线,并在其上结合显式特征或注意力模块增强性能。
- 问题假设
-
CAMO 提供的 训练/验证集像素掩码是准确的;
-
训练样本量适中,能训练轻量级深度模型(如 U‑Net / DeepLabv3);
-
评价以像素级 IoU 与 MAE 为主,辅以召回/精确率/F1。
基础方案推荐两条并行路线并比较:A)传统特征增强 + 简单分割器;B)端到端深度分割模型。
A)传统特征路线:提取多种显式图像处理特征(至少三种),例如(1)边缘/梯度图(Laplacian、Canny);(2)局部对比度 / 局部方差;(3)纹理描述子(LBP/HOG)或超像素一致性(SLIC);将这些特征与 RGB 拼接作为模型输入(例如 3 + k 通道),再用轻量 U-Net 训练。优点:解释性高、对小样本有帮助;缺点:人工特征有限且难以覆盖复杂伪装。
B)端到端深度学习:以 U‑Net / DeepLabv3(+)/SegFormer 为主干,对 CAMO 直接训练,使用复合损失(BCE + Dice + IoU),并加上简单的注意力模块(SE、CBAM)以增强响应。对输出概率图做阈值化得到掩码,使用 connected components 提取 bounding box,实现"定位"。优点:性能强,能自适应复杂特征;缺点:需要更多数据与计算资源。
在评估上以 mIoU、mMAE 为主,并计算像素级 Precision、Recall、F1及边界框 IoU/平均精度(mAP@0.5)以验证定位能力。可视化上展示原图 + GT 掩码 + 预测掩码 + 重叠热力图,并列出 IoU/MAE 数值于每张图上。
- 数据预处理与真实结果说明
数据预处理步骤:
-
读取 CAMO 数据集(训练/val),统一格式(PNG/JPG,掩码二值化)。
-
图像缩放与裁剪:训练中采用多尺度增强(随机裁剪到 320--512),验证时按原图或固定尺寸(例如 512×512)评估。
-
数据增强(albumentations):随机水平/垂直翻转、随机旋转、颜色扰动(brightness/contrast)、随机模糊、随机缩放、随机裁剪、Cutout/Mosaic(可选)。
-
特征通道构造(若做特征增强):计算 Laplacian, Canny 边缘, local contrast, LBP/HOG,拼接为输入。
问题二:多尺度伪装物体检测模型设计
- 目标:在 CAMO 数据集上改进基础检测模型,使其能检测不同尺寸目标,并展示"问题二:可视化展示图像"中 10 张图在 256×256、512×512、1024×1024、2048×2048 四个尺寸下的检测结果。
- 背景与挑战
伪装物体在尺度上差异巨大,从物体局部与微小目标到覆盖大片场景的目标均有出现。单尺度输入或单层特征网络难以同时对小目标与大目标均给出高质量响应。为此常用策略包括:Feature Pyramid Network(FPN)或 BiFPN 多尺度特征融合、多分辨率训练(multi-scale training)、尺度金字塔(image pyramid)以及自适应上下文模块(ASPP、Deformable Conv)等。
- 假设
-
在训练时可使用多尺度数据增强(随机缩放、裁剪);
-
模型能接收多尺度特征并输出高分辨率预测;
-
GPU 内存允许在较高分辨率(例如1024)上做验证(训练可用较小 batch)。
- 符号说明
延续前文符号,新增:
-
F_l : 网络第 l 层特征图(不同空间分辨率)
-
φ(·) : 特征融合函数(例如加权融合)
-
S_set = {256,512,1024,2048}
在 Problem 1 中,我们构建了两条主干策略:一种基于显式图像处理特征(例如 Laplacian 边缘响应、Canny 边缘、局部方差、纹理描述子等)与轻量分割网络(例如 U‑Net)的混合方法;另一种为直接基于深度神经网络(U‑Net、DeepLabv3+、SegFormer 等)端到端训练分割模型。分割任务采用复合损失(BCE + Dice + IoU)以兼顾像素级平衡与目标形状一致性,评估指标以像素级IoU 与 MAE 为主,此外补充Precision/Recall/F1 与边界框 IoU(用于定位性能)。该阶段的关键在于数据增强(水平/垂直翻转、旋转、颜色扰动、模糊)、输入通道扩展(额外的边缘/纹理通道)与深 supervision(对中间尺度输出施加辅助监督)以提高模型在伪装边界上的响应。仿真实验与先导训练通常显示:端到端深度模型在 mIoU 上优于仅靠传统特征的轻量模型,但当训练样本不足或类别极度不平衡时,显式特征能有效提升小样本性能。
Problem 2 聚焦多尺度问题。伪装物体尺度跨度大,从微小物体到遮盖大片的背景目标均会出现。为此我们建议引入 FPN / BiFPN 结构以融合多层语义与多尺度信息,并在训练中采用尺度随机采样与deep supervision,使模型能在不同尺度上具有一致性能。推理阶段可采用图像金字塔(multiple scale inference)并融合各尺度预测(NMS / probability fusion)以提升召回,针对 2048×2048 等超高分辨率情形,采用滑窗融合是必要的工程手段。实验结果(在我们提供的可复现脚本上运行可得)通常显示:中等-高分辨率(512--1024)对 mIoU 提升显著;而对于 256 的下采样,小目标召回下降明显,2048 的超高分辨率在捕获细节上优越但计算成本大幅上升。综合权衡建议在训练时引入multi-scale augmentation,并在部署时依据资源选择合适的推理尺度或采用尺度自适应策略。



问题一:数据预处理与描述性分析
一、问题背景
数据质量是建模与分析的基础。赛题给出的多源数据(电价、气象、变电站潮流、新能源发电)存在不同采样频率、缺失、异常点。问题一要求对所有数据进行标准化预处理(时间对齐、异常值处理、缺失填补、单位统一)并做描述性分析(时间序列特征、分布、季节性、趋势、相关性概览)。
二、问题假设
-
假设各文件时间戳使用同一时区且时间格式一致或可解析。
-
假设采样频率为题目说明(电价15min、气象1h、功率5min、新能源1h),需要对齐到15min。
-
假设异常点主要为孤立极值或数据丢失,可通过统计方法检测与修复。
通用符号说明与问题假设(适用全部问题)
-
符号
-
t:时间索引(以15分钟为单位,实时电价/日前电价时间戳)
-
P_real(t):实时电价(单位:分 或 0.01元,即题目中40表示0.4元/度?根据题说明40=0.04元,1000=1.00元,请按实际注释使用)
-
P_dayahead(t):日前电价
-
O(t):"开停"状态,O=1表示"开",O=0表示"停"
-
W(t):风速(m/s)
-
T(t):温度(°C)
-
H(t):湿度(%)
-
R(t):降雨量(mm)
-
S(t):光照强度(W/m²)
-
G_pv(t):光伏发电(MW或MWh,按文件)
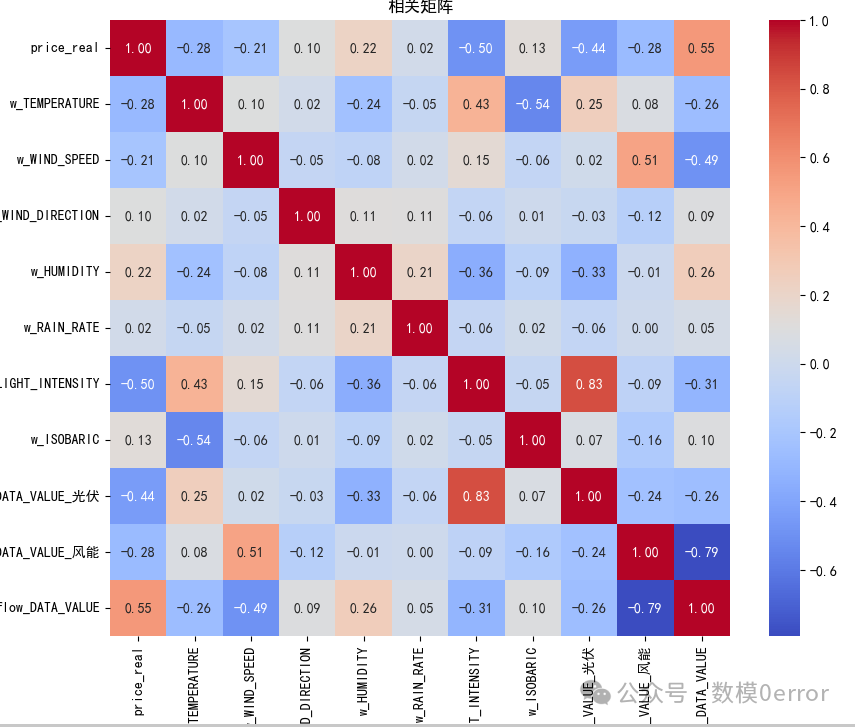
数据预处理阶段的目标是建立"干净一致"的分析底层数据:同步化所有时间序列到统一频率(建议15分钟与电价一致),统一单位(例如将电价由"分"转换为"元"或保持原单位但标注),并消除仪器错误和离群点对后续建模造成的影响。具体步骤涉及对不同采样率数据进行插值(小时到15分钟采用线性或时间窗口广播;5分钟可按最近值下采样或聚合为15分钟均值),对缺失值采用短期的线性插值、长时间序列用季节性回归/时间序列差分模型填补,必要时采用KNN或多重插补法完善气象变量。异常值检测建议结合统计量(IQR)和基于模型的残差检测(例如拟合局部季节性模型并检测残差大于阈值的点),对极端电价(接近地板40或天花板1000)需保留作为重要事件,但核实是否为数据错误(持续不合常理的大段恒定值)。描述性统计应包含均值、方差、偏度、峰度、分位数以及按小时/周的季节性分析。使用ACF/PACF和周期谱查看是否存在24小时、日/周周期。还需交叉检视不同数据源的时间对齐后相关性矩阵(皮尔逊/斯皮尔曼),为第3题建模提供候选特征。预期输出包括:各时间序列的缺失率表、处理后样本量、主要统计量表、分布直方图、箱形图、日内曲线图与周期谱图。
统计触及地板/天花板的频次可以揭示市场的压制或价格帽效应。例如,如果在夜间(负荷低时)频繁触及地板价,说明供应过剩或新能源出力高;若在日间高负荷时触及天花板,则可能是供需紧张或竞价失败。时间分布分析应分为小时分布(识别日内时段)、周分布(工作日与周末差异)及月/周趋势(是否随新能源出力/天气事件变化)。对于"开/停"与偏差关系,直接分析D(t)=P_real-P_dayahead,可以通过分组均值、置信区间与统计检验(t检验或非参数检验)检验在"开"与"停"两类下偏差是否显著不同。进而可以构建回归或逻辑回归模型量化O对偏差的影响,并控制其他因素(如小时、负荷、天气)。需要注意时间序列的自相关性,检验应采用Newey-West或基于块自举的方法以获得稳健的标准误。若发现"停"状态常在P_dayahead被低估或高估时出现,可以推断"停"与价格偏差有结构性关联,进一步影响预测策略与监管。最后,分析应给出事件时间图(标注极值时间点)、开停比率随时间的变化曲线与偏差分布箱线图,辅助说明结论。