文章:https://arxiv.org/abs/2511.18075
代码:暂无
单位:国防科大
引言
一、问题背景:航拍识别的"认知局限"难题
当无人机在高空拍摄时,我们希望它能识别出画面里的所有物体------比如农田里的灌溉设备、山区的通信塔,甚至灾害现场的未知障碍物。但传统的"航拍目标检测技术"有个大问题:它只能认出提前"教过"的类别(比如预设好的"飞机""桥梁"),遇到没见过的新物体就"瞎眼"了。
后来研究者们想到用"视觉-语言模型(VLM)"的零样本能力来解决这个问题,也就是让模型通过文字描述去匹配未知物体(比如用"红色屋顶的小房子"描述新类别)。但这种方法又陷入了"文字依赖"的坑:如果没有现成的文字描述,模型就没法识别;而且文字和图像的匹配常常不准,比如把"长条状的农田"误判成"公路",导致识别效果大打折扣。
简单说,现有技术要么"认死理"(只认学过的类别),要么"靠翻译"(依赖文字描述),都没法灵活应对航拍场景里的未知物体。
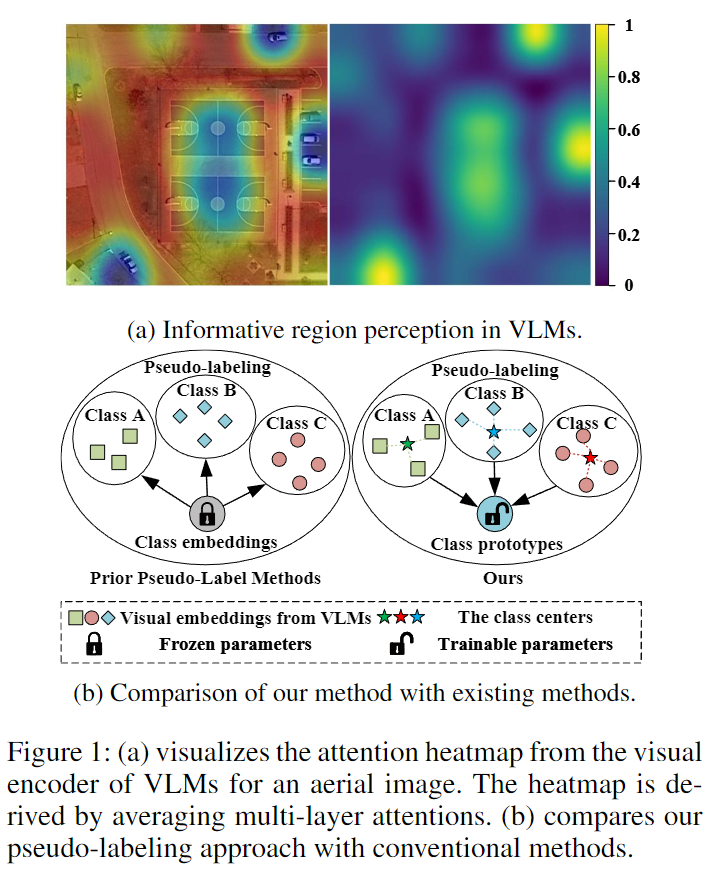
二、方法创新:靠"视觉知识"自己学,不依赖额外文字
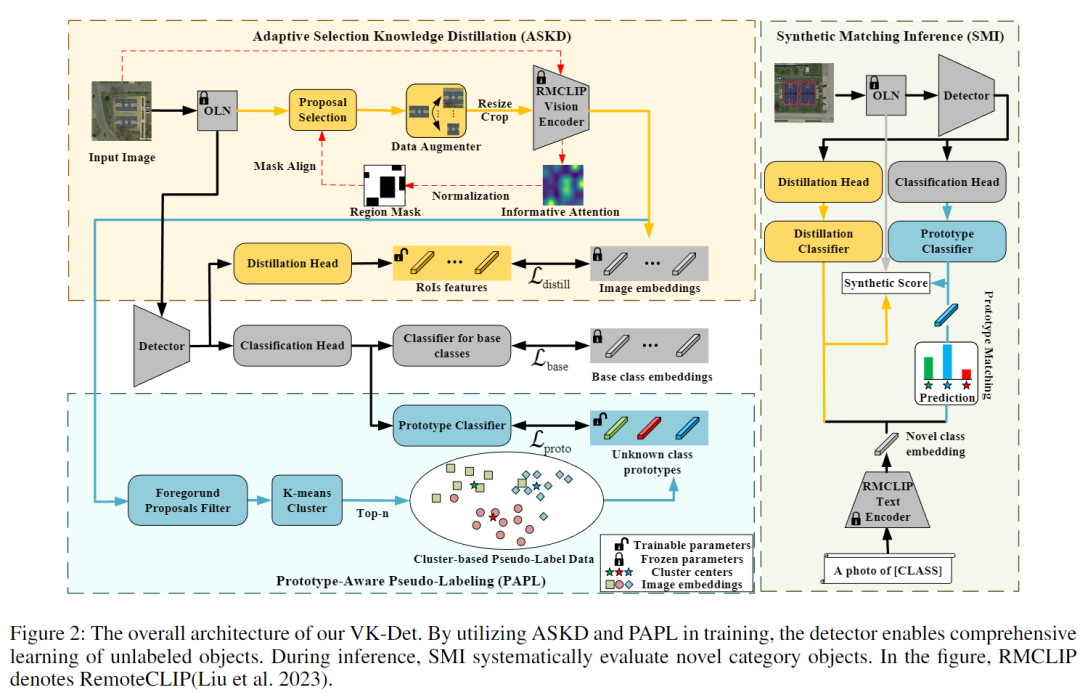
国防科技大学的团队提出了一个叫VK-Det的新框架,核心思路是:不依赖额外文字或标注,只靠VLM本身的"视觉感知能力"来识别未知物体。它主要做了三件关键创新:
1. 精准提取"有用区域":不浪费算力在背景上
航拍图里常有大片无用背景(比如蓝天、草原),VK-Det发现VLM的视觉编码器能自动"盯着"有物体的区域(比如地面的车辆、建筑)。于是它设计了一个"自适应选择蒸馏(ASKD)"模块:
-
先通过VLM的注意力热力图,找出画面里"大概率有物体"的区域;
-
对细长、小巧的航拍物体(比如电线杆、小船)做特殊的数据增强,避免裁剪时丢失关键特征;
-
只把这些"有用区域"的特征传给检测器,减少背景干扰,让学习更高效。
2. 自动生成"类别模板":不用文字也能分类别
传统方法靠文字生成"类别模板",VK-Det则用"原型学习"自己造模板,也就是"原型感知伪标签(PAPL)":
-
先把"有用区域"里的未知物体特征聚类,比如把不同形状的"未知建筑"聚成几类,每类形成一个"特征模板"(比如"圆顶模板""方盒模板");
-
用这些"模板"给未知物体贴"伪标签"(比如"未知-1""未知-2"),让检测器能学习不同未知类别的区别,不用依赖文字描述。
3. 多维度打分:综合判断更靠谱
最后,VK-Det设计了"合成匹配推理(SMI)"机制,综合三个维度判断物体类别:
-
检测器和VLM的特征匹配分(Scoreₙ);
-
"特征模板"的匹配分(Scoreₚ);
-
物体位置的准确性分(Scoreₗ);
-
三者结合算出最终得分,避免单维度判断出错,比如不会因为"形状像"就误判类别。
三、实验结果:性能碾压,还不用额外标注
团队在两个主流航拍数据集(DIOR和DOTA)上做了测试,结果很亮眼:
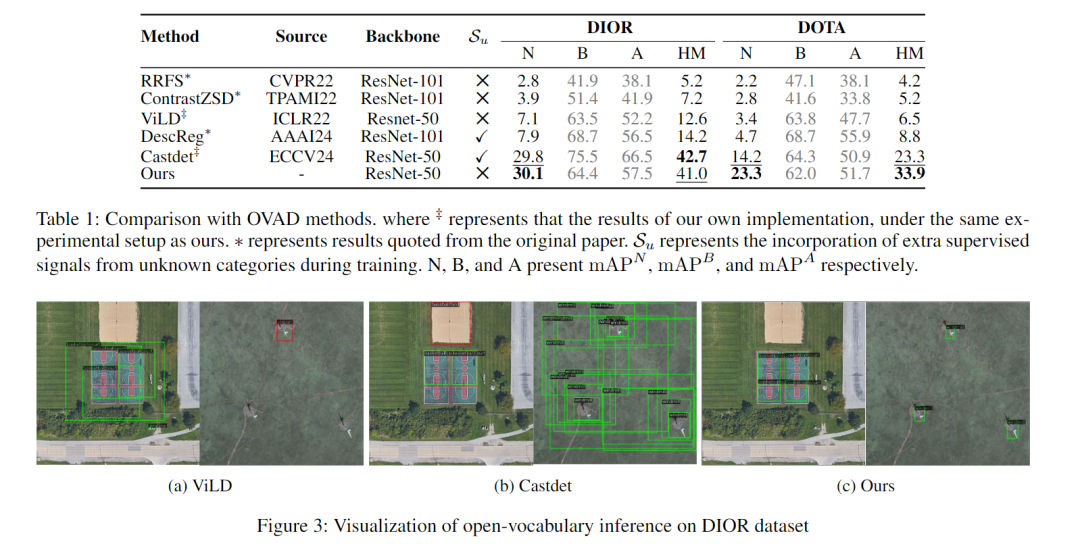
1. 未知类别识别率领先
-
在DIOR数据集上,VK-Det对未知类别的识别精度(mAPᴺ)达到30.1%,比同样"无额外标注"的ViLD模型高23个百分点,甚至比依赖额外标注的CastDet还高0.3个百分点;
-
在更复杂的DOTA数据集(有小物体、大尺寸图)上,VK-Det的未知类别精度达23.3%,比现有最好方法高9.1个百分点,而且"基础类别+未知类别"的综合表现(HM)也更均衡。
2. 关键模块缺一不可
ablation实验(去掉某个模块看效果)显示:
-
去掉"有用区域提取",未知类别精度掉至20%左右;
-
去掉"特征模板",精度只剩9.3%;
-
只有三个模块一起用,才能达到30.1%的最高精度,证明每个创新都有用。
四、优势与局限
优势:打破"依赖",适配航拍场景
-
无额外依赖:不用额外标注、不用文字描述,纯靠视觉知识就能学,落地更灵活,比如在没有文字库的偏远地区也能用;
-
适配航拍特性:针对航拍图的"小物体多、背景杂、物体形状特殊"做了优化,比通用模型更实用;
-
性能能打:能超过依赖额外标注的模型,证明"纯视觉学习"的潜力。
局限:仍有优化空间
-
聚类数量敏感:"特征模板"的数量(聚类数k)需要调参,k太少会混类别,k太多会分散特征,目前最优是k=20,还没法自动适配;
-
复杂场景挑战:面对极端天气(比如大雾、暴雨)下的航拍图,"有用区域"提取可能出错,影响后续识别;
-
速度待提升:聚类和多维度打分增加了计算量,目前还没法做到实时检测,适合离线分析,不适合无人机实时避障等场景。
五、一句话总结
VK-Det靠"只挖视觉潜力、不依赖文字标注"的思路,解决了航拍场景中未知物体识别的"文字依赖"难题,性能超过多数依赖额外标注的模型,为无人机巡检、灾害救援等场景的灵活识别提供了新方案。